目录
一、容器适配器
1.1容器适配器概念的介绍
1.2stack和queue的底层结构
1.3deque容器的介绍
1.3.1deque的缺陷及为何选择他作为stack和queue的底层默认实现
二、stack的介绍和使用
2.1stack的介绍
2.2stack的使用
2.3stack的模拟实现
三、queue的介绍和使用
3.1queue的介绍
3.2queue的使用
3.3queue的模拟实现
四、priority_queue的介绍和使用
4.1priority_queue的介绍
4.2priority_queue的使用
五、priority_queue模拟实现
5.1仿函数
5.2仿函数与回调函数的共同点与差异
5.3模拟实现
回顾之前学过的容器,要学习的栈和队列已经不是作为一个容器,而是容器适配器,本章节先是学习他们的用法掌握使用,再来模拟实现接触底层,从而对适配器有更深的理解,那么接下来开启新的篇章。
一、容器适配器
1.1容器适配器概念的介绍
从概念上来说,容器适配器是一种设计模式,该种模式是将一个类的接口转换成客户希望的另外一个接口。应用到栈和队列上,就是通过某种类的接口实现出一个栈或队列这样的类接口,即通过容器的接口适配出了栈和队列。
1.2stack和queue的底层结构
由官方给的模板类可以看出,stack和queue的底层实现是采用了deque容器


1.3deque容器的介绍
从原理上来说:
deque(双端队列):是一种双开口的“连续(物理逻辑上的连续,实际底层并不一定)”空间的数据结构,理解为双开口的队列,可以进行头插头删,尾插尾删,其时间复杂度为O(1)。
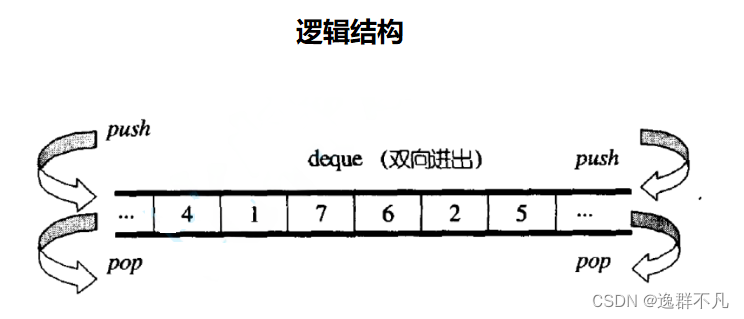
从底层上来说:
deque并不是真正连续的空间,而是由一段一段连续的小空间拼接而成的,类似于一个动态的二维数组。 这些每段段的空间由一个中控器(指针数组map)维护,当这个指针数组满了,就会发生扩容。由此可见,实际的扩容就落在了指针数组上面,而不需要对每段空间进行扩容。
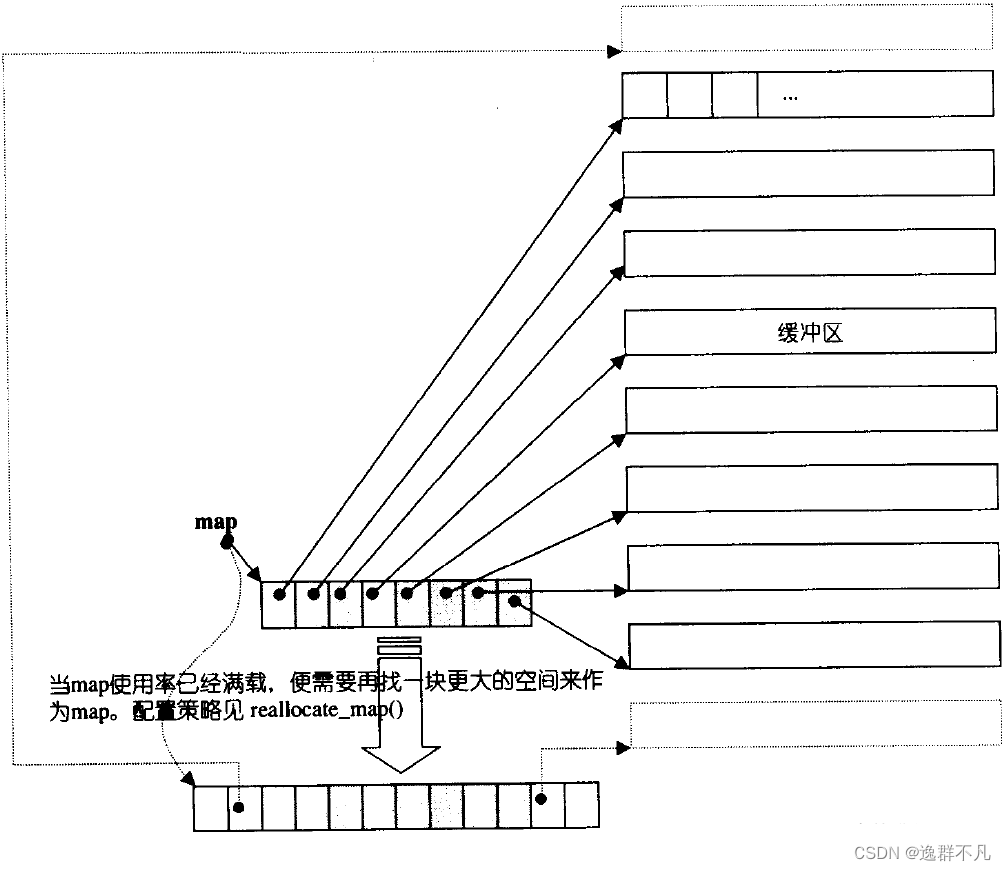
所以该双端队列连续是一种物理逻辑上的连续,而不是物理地址上的连续,进一步延伸,对于该双端队列,其迭代器又是如何来维护该结构?
迭代器维护的示意图如下:
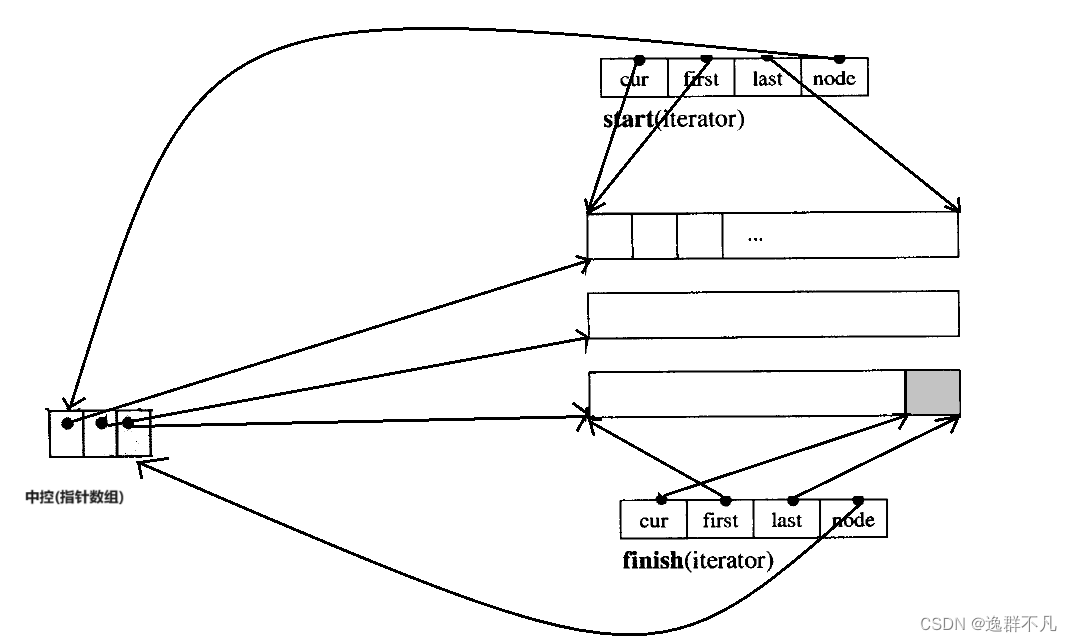

deque优点:
①有了该迭代器维护,那么在随机访问元素时,就可以先确定其在哪段空间(先计算每段空间的大小(假设是固定的大小),再通过访问元素的下标除以空间的大小取模就可找到),再确定这段空间的哪个位置 (通过下标除以空间的大小取余),从而满足了vector的功能。
②其次,进行头插、尾插、删除元素时,头插只需要将元素往第一段空间插入即可,当第一段空间满了,只需在上面再开一段空间,更新start、start->node,尾插只需要将元素往最后一段空间插入即可,当最后一段空间满了,只需在下面再开一段空间,更新finish、finish->node,删除直接释放该元素位置,两者都达到了不用移动元素,从而满足了list的功能。
1.3.1deque的缺陷及为何选择他作为stack和queue的底层默认实现
缺陷:
①虽然deque既满足了vector的功能,又满足了list的功能,但依然存在弊端,如果在一段满了的空间的中间插入和删除元素呢,那岂不是又得挪动元素了,这又导致了时间复杂度增高,
②其次,假设每段空间的大小不是固定的呢,那么就要计算每个空间的大小,如果空间有n个,大小不固定,则计算每个空间的大小的时间复杂度就变得很高,从而就不能够作为一种既满足时间复杂度又达到随机访问的容器。
③再其次,即使每个空间的大小是固定的,但是如果有大量的随机访问,那么找到对应位置就得有大量的计算,且当要遍历其中的所有元素时,那还得频繁的检测指针是否移动到每段空间的边界,从而导致效率低下。
从缺陷中可以得出结论,对于序列式的场景,需要遍历访问,且需要线性结构时,还是选择vector和list,因为他们并不需要去计算要访问的位置,直接遍历即可。
那么deque有这样的缺陷,那为何还要选择该容器作为stack和queue的底层默认容器:
其实,对于要实现的stack和queue他们的功能根本就不需要联系到deque的弊端功能。
① 由于栈和队列的访问模式通常是从顶部或头部开始,而不需要随机访问和遍历,所以栈和队列本身也就不提供迭代器。
stack是后进先出,插入、删除都只在一端,deque满足,且避开了deque的缺点
queue是先进先出,在尾部插入,头部删除,deque同样满足,也避开了deque的缺点。
②
结合以上,stack只需要在一端操作,底层可由deque实现,同样也可以由vector、list实现(即数组栈、链式栈)。
而queue在两端操作,底层可用deque实现外,也可用list实现 ,却不能用vector实现,因为vector头插和删除得挪动大量数据,例如删除队头元素,又得把剩余元素给挪过去,时间复杂度高,所以并不支持。
stack和queue需要发生扩容时,deque的效率比vector高,因为vector发生扩容是需要再开一块空间,把原有数据拷贝过来,再插入新数据,而deque是直接通过中控指针开辟一快空间,直接在新的开辟的空间插入数据,减少了数据的挪动。所以结合以上优点,stack和queue的底层实现默认采用了deque容器。
注意:deque(双端队列)并不代表它是一个真正的队列,只是名字上的叫法,正如其底层而言并不是一个队列,只是逻辑上的形式是队列。
介绍完基础内容,那么接下来就来学习栈和队列。
二、stack的介绍和使用
2.1stack的介绍

1.stack是一种容器适配器,专门用在具有后进先出操作的上下文环境中,其删除只能从容器的一端进行元素的插入与提取操作。
2.stack是作为适配器被实现的,容器适配器即是对特定类封装作为其底层的容器,并提供一组特定的成员函数来访问其元素,将特定类作为其底层的,元素特定容器的尾部(即栈顶)被压入和弹出。
3.stack的底层容器可以是任何标准的容器类模板或者一些其他特定的容器类,这些容器类应该支持以下操作:empty、back、push_back、pop_back
4.标准容器vector、deque、list均符合这些需求,默认情况下,如果没有为stack指定特定的此层容器,默认情况下使用deque适配出stack
stack作为一个模板类,与vector、list不同的是,它是一个适配器,底层由容器实现从而适配出了栈,由官方给的stack的模板类,可以看出他有两个模板参数,第一个代表要传的数据类型,第二个表示它的底层默认是由deque实现的,当然也可以指定传。
2.2stack的使用
stack作为一个栈适配器,他的接口不像容器的接口那么多,主要就是以下接口。
| 函数说明 | 接口说明 |
| stack() | 构造空栈 |
| empty() | 检测stack是否为空 |
| size() | 返回stack中元素的个数 |
| top() | 返回栈顶元素的引用 |
| push() | 将元素压入栈中 |
| pop() | 将栈顶元素弹出 |
| swap | 交换两个栈的元素 |
#include <iostream>
#include <stack>
#include <vector>
using namespace std;
int main()
{
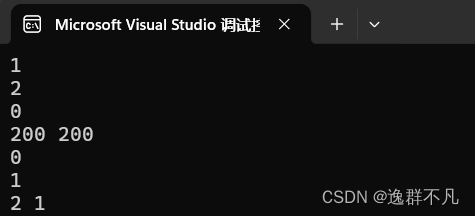
stack<int> st;//构造空栈,底层默认由deque实现
cout << st.empty() << endl;
vector<int> v(2, 200);
stack<int,vector<int>> s(v);//自己传vector,stack底层由vector实现
cout << s.size() << endl;
cout << s.empty() << endl;
while (!s.empty())
{
cout << s.top() << " ";//取栈顶元素
s.pop();//弹出栈顶元素
}
cout << endl;
stack<int, vector<int>> t;
t.push(1);//向栈中插入元素
t.push(2);
s.swap(t);//交换两个栈中的元素
cout << s.empty() << endl;
cout << t.empty() << endl;
while (!s.empty())
{
cout << s.top() << " ";
s.pop();
}
return 0;
}
2.3stack的模拟实现
//stack.h
#include <iostream>
#include <deque>
using namespace std;
namespace bite
{
template<class T, class Container = deque<T>>//底层默认由容器deque实现
class stack
{
public:
stack(const Container& con = Container())//stack的构造函数,实则构造容器对象
:_con(con)
{}
void push(const T& st)//stack的头插,实则调用容器的尾插
{
_con.push_back(st);
}
void pop()//stack的头删,实则调用容器的尾删,后进先出
{
_con.pop_back();
}
T& top()//stack获取栈顶元素,实则调用容器的获取尾部元素
{
return _con.back();
}
const T& top() const//stack获取栈顶元素,实则调用容器的获取尾部元素,获取到的栈顶元素不能修改
{
return _con.back();
}
size_t size() const
{
return _con.size();
}
bool empty() const
{
return _con.empty();
}
void swap(stack& st)//stack对象的交换,实则交换的是容器对象的值
{
std::swap(_con,st._con);
}
private:
Container _con;
};
}测试:
//test.cpp
#include "stack.h"
#include <vector>
int main()
{
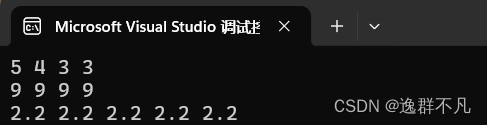
deque<int> d(2, 3);
bite::stack<int> st(d);
st.push(4);
st.push(5);
while (!st.empty())
{
cout << st.top() << " ";
st.pop();
}
cout << endl;
deque<int> dq(4, 9);
bite::stack<int> s(dq);
s.swap(st);
while (!st.empty())
{
cout << st.top() << " ";
st.pop();
}
cout << endl;
vector<double> v(5,2.2);
bite::stack<double,vector<double>> t(v);
while (!t.empty())
{
cout << t.top() << " ";
t.pop();
}
return 0;
}输出结果:
三、queue的介绍和使用
3.1queue的介绍

1.队列也是一种容器适配器,专门用于在FIFO上下文(先进先出)中操作,其中从容器一端插入元素,另一端出元素。
2.队列作为容器适配器实现,容器适配器即将特定容器类封装作为其底层容器类,queue提供一组特定的成员函数来访问其元素。元素从队尾入队列,从队头出队列。
3.底层容器可以是标准容器类模板之一,也可以是其他专门设计的容器类。该底层容器应至少支持以下操作:empty()、size()、front()、back()、push_back、pop_front
4.标准容器类deque和list满足适配要求。默认情况下为deque适配出queue。
queue同样作为一种适配器,是一个模板类,第一个参数传的是类型,第二个参数传的是实现queue的方式,不传默认由deque实现,调用queue的接口,本质上调用的是deque的接口,也可自定义传但只能指定为deque和list,因为vector去实现queue的代价是很高的,例如删除队头元素,又得把剩余元素给挪过去,时间复杂度高,所以并不支持。
3.2queue的使用
| 函数声明 | 接口说明 |
| queue() | 构造空队列 |
| empty() | 检测队列是否为空,是返回true,否返回false |
| size() | 返回队列中有效元素的个数 |
| front() | 返回队头元素的引用 |
| back() | 返回队尾元素的引用 |
| push() | 在队尾将元素插入队列 |
| pop() | 将队头元素出队列 |
| swap() | 交换两个队列元素 |
#include <iostream>
#include <queue>
#include <list>
using namespace std;
int main()
{
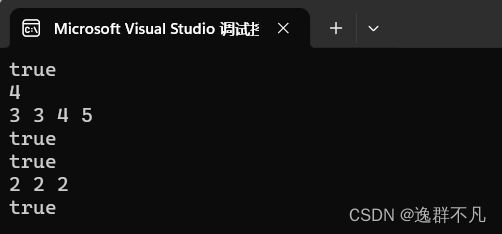
queue<int> q;//构造空栈
cout << boolalpha << q.empty() << endl;//以bool值打印
list<int> l(2, 3);
queue<int, list<int>> qt(l);//指定queue底层由list实现
qt.push(4);//队尾插入元素
qt.push(5);
cout << qt.size() << endl;
while (!qt.empty())
{
cout << qt.front() << " ";
qt.pop();//弹出队头元素
}
cout << endl;
cout << boolalpha << qt.empty() << endl;//qt为空
list<int> lt(3, 2);
queue<int, list<int>> tq(lt);
qt.swap(tq);//交换两个队列元素
cout << boolalpha << tq.empty() << endl;//tq为空
while (!qt.empty())
{
cout << qt.front() << " ";
qt.pop();
}
cout << endl;
cout << boolalpha << qt.empty() << endl;
return 0;
}
3.3queue的模拟实现
#include <iostream>
#include <deque>
using namespace std;
namespace bite
{
template<class T, class Container = deque<T>>//底层默认由容器deque实现
class queue
{
public:
queue(const Container& con = Container())//queue的构造函数,实则构造容器对象
:_con(con)
{}
void push(const T& q)//queu的尾插,实则调用容器的尾插
{
_con.push_back(q);
}
void pop()//queue的头删,实则调用容器的头删
{
_con.pop_front();
}
T& front()//queue获取队头元素,实则调用容器的获取头部元素
{
return _con.front();
}
const T& front() const//queue获取队头元素,实则调用容器的获取头部元素,不可修改
{
return _con.front();
}
T& back()//stack的头插,实则调用容器的获取尾部元素
{
return _con.back();
}
const T& back() const//stack的头插,实则调用容器的获取尾部元素,不可修改
{
return _con.back();
}
size_t size() const
{
return _con.size();
}
bool empty() const
{
return _con.empty();
}
void swap(queue& q)//queue对象的交换,实则交换的是容器对象的值
{
std::swap(_con,q._con);
}
private:
Container _con;
};
}测试:
#include "queue.h"
#include <list>
int main()
{
list<string> l(2, "apple");
bite::queue<string, list<string>> q(l);
q.push("banana");
q.push("grep");
q.push("orange");
while (!q.empty())
{
cout << q.front() << " ";
q.pop();
}
cout << endl;
bite::queue<string, list<string>> sq;
sq.push("i");
sq.push("love");
sq.push("learning");
sq.push("C++");
sq.swap(q);
while (!q.empty())
{
cout << q.front() << " ";
q.pop();
}
cout << endl;
return 0;
}输出结果:
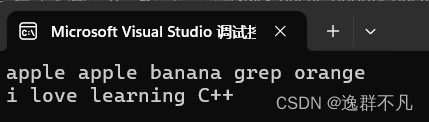
四、priority_queue的介绍和使用
priority_queue也叫优先级队列,他同样不是一个真正的队列,只是名字上的叫法,其本质上是一个堆,那么接下学习其使用。
4.1priority_queue的介绍
 1.优先级队列也是一种容器适配器,根据严格的弱排序标准,它的第一个元素总是它包含的元素中最大的。
1.优先级队列也是一种容器适配器,根据严格的弱排序标准,它的第一个元素总是它包含的元素中最大的。
严格的弱排序标准:
如果第一个元素小于第二个元素,则它们被认为是有序的,第一个元素在第二个元素之前。
如果第一个元素大于第二个元素,则它们被认为是无序的,第一个元素在第二个元素之后。
如果两个元素相等,则它们的相对顺序是不确定的,它们可以在排序后交换位置,也可以保 持原来的相对位置。
2.此上下文类似于堆,在堆中可以随时插入元素,并且只能检索最大堆元素(优先队列中位于顶部的元素)。
3.其将特定容器类封装作为其底层容器类,priority_queue提供一组特定的成员函数来访问其元素。元素从特定的容器的尾部弹出,其称为优先队列的顶部。
4.底层容器是任何标准容器类模板,也可以是其他特定设计的容器类。容器应该可以通过随机访问迭代器访问,支持以下操作:empty()、size()、front()、push_back()、pop_back()。
5.标准容器类vector和deque满足这些需求。默认情况下,如果没有为特定的priority_queue类实例化指定容器类,则使用vector。
6.内部是一个堆结构,堆的实现是需要支持随机访问,所以实现该堆的容器需要支持随机访问迭代器来维持堆的结构。容器适配器通过在需要时自动调用算法函数make_heap、push_heap和pop_heap来自动完成此操作维持堆的结构,这些都是库里面的调用,后面进行简易模拟实现会有点不一样,但功能是一样的。
priority_queue作为一种容器适配器,是一个模板类,第一个参数传的是类型,第二个参数传的是其底层实现的方式,默认由vector实现,也可指定传但只能是vector和deque,第三个参数传的是底层的数据按什么方式进行排序,默认按大堆的方式进行排序。
priority_queue本质上可以理解为一个堆,实现堆需要随机访问其中的元素,因此底层可以用到的是vector和deque,但由于vector随机访问的效率比deque高,所以默认用vector
4.2priority_queue的使用
| 函数声明 | 接口说明 |
| priority_queue()/priority_queue(first,last) | 构造空的优先级队列/容器的迭代器区间构造优先级队列 |
| empty() | 检测优先级队列是否为空,是返回true,否返回false |
| size() | 返回优先级队列中的元素个数 |
| top() | 返回优先级队列中堆顶元素,为最大或最小元素,取决堆的实现 |
| push(x) | 在优先级队列中插入元素 |
| pop() | 弹出堆顶元素 |
| swap | 交换两个优先级队列中的元素 |
#include <iostream>
#include <queue>
using namespace std;
int main()
{
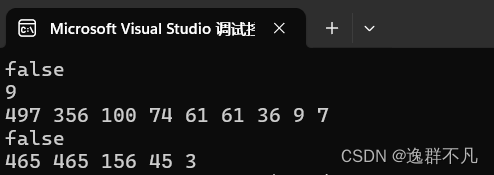
vector<int> v{ 9,61,497,61,356,74,36,7 };
priority_queue<int> q(v.begin(),v.end());//其内部是个堆结构,默认是大堆
q.push(100);//插入一个值,内部自动调整保持大堆结构
cout << boolalpha << q.empty() << endl;//以bool型输出
cout << q.size() << endl;
while (!q.empty())
{
cout << q.top() << " ";//由于其内部是个大堆,每次取到的队头就是最大的元素
q.pop();
}
cout << endl;
vector<int> vq{ 3,156,465,465,45 };
priority_queue<int> pq(vq.begin(),vq.end());
pq.swap(q);//交换两个队列中的元素
cout << boolalpha << q.empty() << endl;//pq为空,q不为空
while (!q.empty())
{
cout << q.top() << " ";
q.pop();
}
return 0;
} 
五、priority_queue模拟实现
在模拟实现priority_queu之前,先得了解仿函数的概念使用,因为实现需要用到仿函数
5.1仿函数
仿函数(Function Object)是一种行为类似函数的对象,它实际上是一个类的实例,但可以像函数一样被调用。仿函数类重载了函数调用运算符 operator(),使得类的对象调用该运算符时看起来像调用函数一样。在C++中,仿函数通常被用作算法的参数,例如STL(标准模板库)中的各种算法,如排序、查找等,都可以接受仿函数作为参数,以实现不同的比较、操作等功能。通过传递不同的仿函数,可以使算法具有更大的灵活性,从而适应不同的需求。
例子:
#include <iostream>
using namespace std;
template<class T>
class Funtor
{
public:
bool operator()(const T& x, const T& y)//常量引用
{
return x < y;
}
int operator()(T& x, T& y)
{
return x + y;
}
};
int main()
{
Funtor<int> fun;
cout << boolalpha << fun(3, 4) << endl;//传的常量,调用第一个重载函数
int a = 5, b = 6;
cout << fun(a,b)<< endl;//传的变量,调用第二个重载函数
return 0;
}输出结果:

如上所示,实现了一个仿函数,该仿函数是一个类,类中重载了operator(),该重载实现了函数的功能,当类创建对象fun,对象调用该重载运算符(),看起来就像是一个函数调用。这种行为是类实例化的对象调用,但又类似函数调用,所以称之为仿函数。
在了解完仿函数,不禁想起了c语言中的回调函数, 他们似乎存在着古老的联系,但又令人淡忘,让我们一探究竟。
5.2仿函数与回调函数的共同点与差异
回调函数:
就是一个通过函数指针调用的函数。如果你把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,我们就说这是回调函数。回调函数不是由该函数的实现方直接调用,而是在特定的事件或条件发生时由另外的一方调用的,用于对该事件或条件进行响应。
例子:
template<class T>
class FUN
{
//若类中出现重载函数,且有函数指针指向重载函数。
//将重载函数实现成模板函数,那么函数指针指向重载函数时,函数模板就能够识别函数指针的类型,从而指向对应的函数
//否则,未实现成模板函数,那么函数指针就不知道该指向谁
template<class T>
static bool fun(const T x, const T y)
{
return x < y;
}
template<class T>
static int fun(T x, T y)
{
return x + y;
}
public:
void test()
{
_pf = &fun;//注意:在类中,不能直接将普通函数名赋给函数指针,因为该普通函数是this指针调用
//所以该普通函数多了一个this指针,而函数指针并没有this指针,这就导致了参数不匹配问题,那么解决方案就是将普通函数改成静态成员函数
//因为静态成员函数是没有this指针。
_fp = fun; //当没有加取地址,函数名本身也是一个函数指针,这是一种特性,也算是规定
//当加了取地址,就是明确的来获取函数的地址,此时函数名就没有当作指针
cout << _pf(3, 5) << endl;
cout << boolalpha << _fp(30, 5) << endl;
}
private:
int(*_pf)(const T, const T);//函数指针成员
bool(*_fp)(T, T);
};
int main()
{
FUN<int> Fun;
Fun.test();
return 0;
}输出结果:

通过以上例子,仿函数和回调函数存在一定的共同点:
- 都是一种函数的抽象表示,并不是直接调用函数,而是通过另一种形式来达到调用函数的功能。
- 都可以作为参数传递给其他函数,仿函数中传递对应的类型,回调函数则是传递函数地址。
- 都可以在特定的场景中被调用,正如上述两者例子。
但是,在实践中,还是会选择仿函数,因为回调函数具有一定的缺陷:
1.函数指针的定义形式复杂,可读性差,难以理解,对新手不友好。
2.只能通过函数参数传递,即只能传递函数地址,相对于仿函数来说太单一。
3.难以维护,函数参数由外部给定,若参数出现错误,可能会导致内存泄漏等问题
仿函数的优点:
1.仿函数类型定义简单,很友好
2.仿函数中可以传递任意类型,不局限于某种类型,是一个泛型。
3.仿函数可以在不同的上下文中被重复使用,从而提高了代码的可复用性。
5.3模拟实现
优先级队列本质上是一个堆,其模拟实现可以分为三大部分,仿函数的实现,堆的实现,优先级队列类的实现
①仿函数的实现:
template<class T>
class less
{
public:
bool operator()(const T& a, const T& b)
{
return a < b;
}
};
template<class T>
class greater
{
public:
bool operator()(const T& a, const T& b)
{
return a > b;
}
};②堆的实现(默认建大堆):
向上调整建大堆:
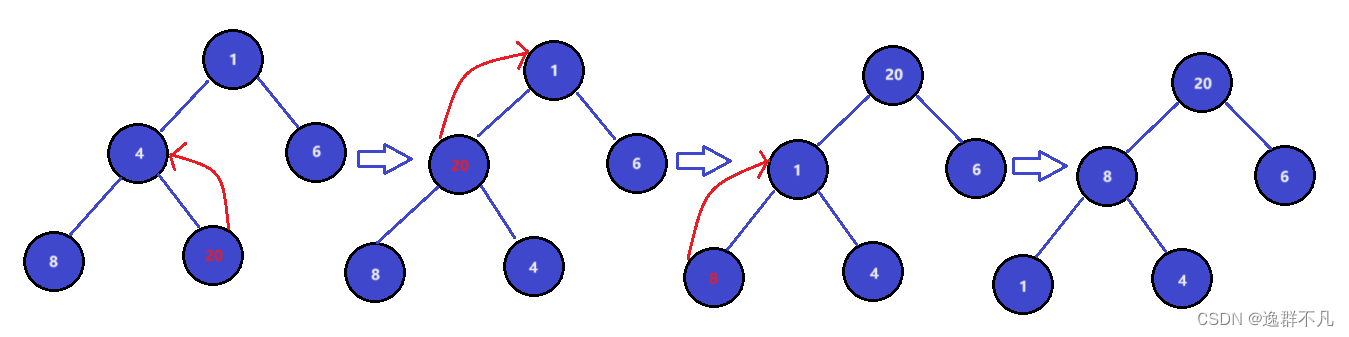
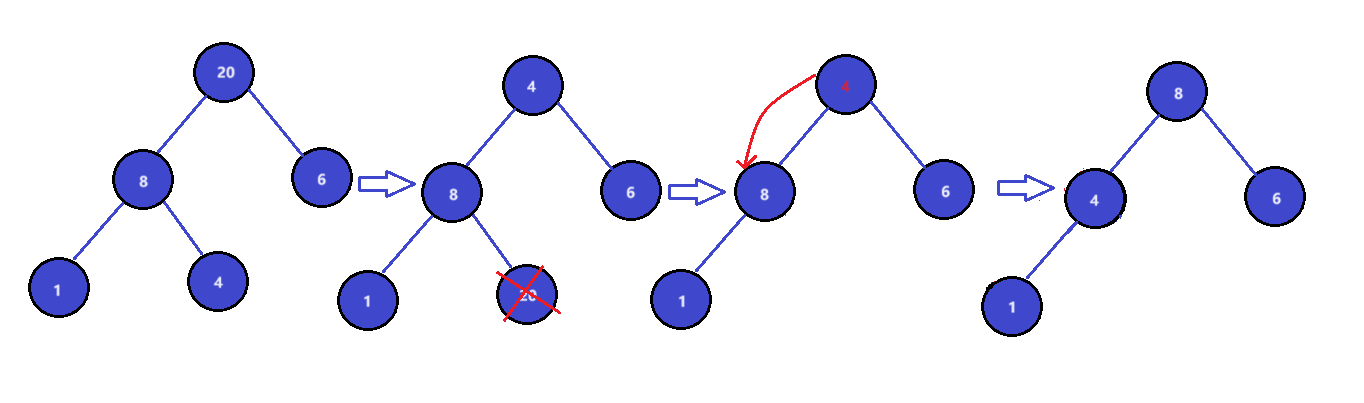
向下调整建大堆:(当删除队头元素时,由于底层是由vector实现,不能直接删除头部元素,可以通过需交换头尾,在对尾进行删除,但此时头部是较小元素,因此进行向下调整。
void adjust_up(int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
/*if (_con[child] > _con[parent])*/ //传统写法
if (_com(_con[parent] , _con[child]))//调用仿函数
{
std::swap(_con[child], _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
break;
}
}
void adjust_down(int parent)
{
int child = parent * 2 + 1;
while (child < _con.size())
{
//if (child + 1 < _con.size() && _con[child] < _con[child + 1])
if (child + 1 < _con.size() && _com(_con[child] , _con[child + 1]))
{
child = child + 1;
}
//if (_con[child] > _con[parent])
if (_com(_con[parent] , _con[child])
{
std::swap(_con[child], _con[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}③优先级队列类的实现(总版本):当插入元素,其内部就要调用堆对该元素进行调整,所以堆的实现是放在类中,而仿函数是一个类,放于优先级队列类外,当要调用仿函数时,直接调用即可,因为对于自定义类型,编译器会去调用其成员函数。
#include <iostream>
#include <vector>
using namespace std;
namespace bite
{
template<class T>
class less
{
public:
bool operator()(const T& a, const T& b)
{
return a < b;
}
};
template<class T>
class greater
{
public:
bool operator()(const T& a, const T& b)
{
return a > b;
}
};
template<class T, class Container = vector<T>, class Compare = less<T>>//仿函数默认采用
class priority_queue
{
void adjust_up(int child)//向上调整,建堆
{
int parent = (child - 1) / 2;
while (child > 0)
{
/*if (_con[child] > _con[parent])*/ //传统写法
if (_com(_con[parent] , _con[child]))//调用仿函数
{
std::swap(_con[child], _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
break;
}
}
void adjust_down(int parent)//向下调整,建堆
{
int child = parent * 2 + 1;
while (child < _con.size())
{
//if (child + 1 < _con.size() && _con[child] < _con[child + 1])
if (child + 1 < _con.size() && _com(_con[child] , _con[child + 1]))
{
child = child + 1;
}
//if (_con[child] > _con[parent])
if (_com(_con[parent] , _con[child]))
{
std::swap(_con[child], _con[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
public:
priority_queue(const Container con = Container(), const Compare com = Compare())//构造函数,初始化容器对象(默认为vector),和仿函数对象(默认为less)
:_con(con)
,_com(com)
{
adjust_up(size() - 1);//初始化容器对象后,进行建堆,由于仿函数为less,则建的是大堆
}
//通过迭代器区间构造优先级队列,实则初始化容器对象
template<class InputIterator>
priority_queue(InputIterator first, InputIterator last,
const Container& con = Container(),const Compare& com = Compare())
:_con(con)//这里的初始化,容器中不具有任何值
,_com(com)
{
_con.insert(_con.end(),first, last);//将迭代器区间的值插入到容器对象,真正初始化容器对象
adjust_up(size()-1);//初始化容器对象后,进行建堆,为大堆
}
size_t size() const
{
return _con.size();
}
bool empty() const
{
return _con.empty();
}
const T& top() const
{
return _con[0];
}
void push(const T& pq)
{
_con.push_back(pq);//插入值
adjust_up(size()-1);//插入值后进行调整堆,重新建大堆
}
void pop()
{
std::swap(_con[0],_con[size()-1]);//由于是大堆,容器首元素为最大值,而删除又是删除首元素,故此交换首元素与最后一个元素,
//那么最后一个元素就是最大值
_con.pop_back();//再把最后一个元素pop掉
adjust_down(0);//首元素现在是较小值,所以需向下调整堆,重新建大堆
}
void swap(priority_queue& pq)//交换队列的对象,实则交换容器对象中的值
{
std::swap(_con,pq._con);
std::swap(_com, pq._com);
}
private:
Container _con;
Compare _com;
};
}测试:
#include "priority_queue.h"
#include <vector>
int main()
{
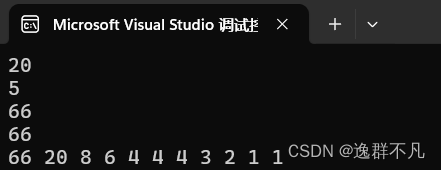
vector<int> v(1, 1);
v.push_back(4);
v.push_back(6);
v.push_back(8);
v.push_back(20);
bite::priority_queue<int> p_q(v);
cout << p_q.top() << endl;
cout << p_q.size() << endl;
bite::priority_queue<int> pq(v.begin(),v.end());
pq.push(1);
pq.push(2);
pq.push(3);
pq.push(4);
pq.push(4);
pq.push(66);
cout << pq.top() << endl;
bite::priority_queue<int> q;
q.swap(pq);
cout << q.top() << endl;
while (!q.empty())
{
cout << q.top() << " ";
q.pop();
}
return 0;
}输出结果:
end~