深搜广搜的标准模版在图论1已经整理过了,也整理了几个标准的套模板的题目,这一小节整理一下较为复杂的DFS&BFS应用类问题。
417 太平洋大西洋水流问题(medium)
有一个 m × n 的矩形岛屿,与 太平洋 和 大西洋 相邻。 “太平洋” 处于大陆的左边界和上边界,而 “大西洋” 处于大陆的右边界和下边界。
这个岛被分割成一个由若干方形单元格组成的网格。给定一个 m x n 的整数矩阵 heights , heights[r][c] 表示坐标 (r, c) 上单元格 高于海平面的高度 。
岛上雨水较多,如果相邻单元格的高度 小于或等于 当前单元格的高度,雨水可以直接向北、南、东、西流向相邻单元格。水可以从海洋附近的任何单元格流入海洋。
返回网格坐标 result 的 2D 列表 ,其中 result[i] = [ri, ci] 表示雨水从单元格 (ri, ci) 流动 既可流向太平洋也可流向大西洋 。
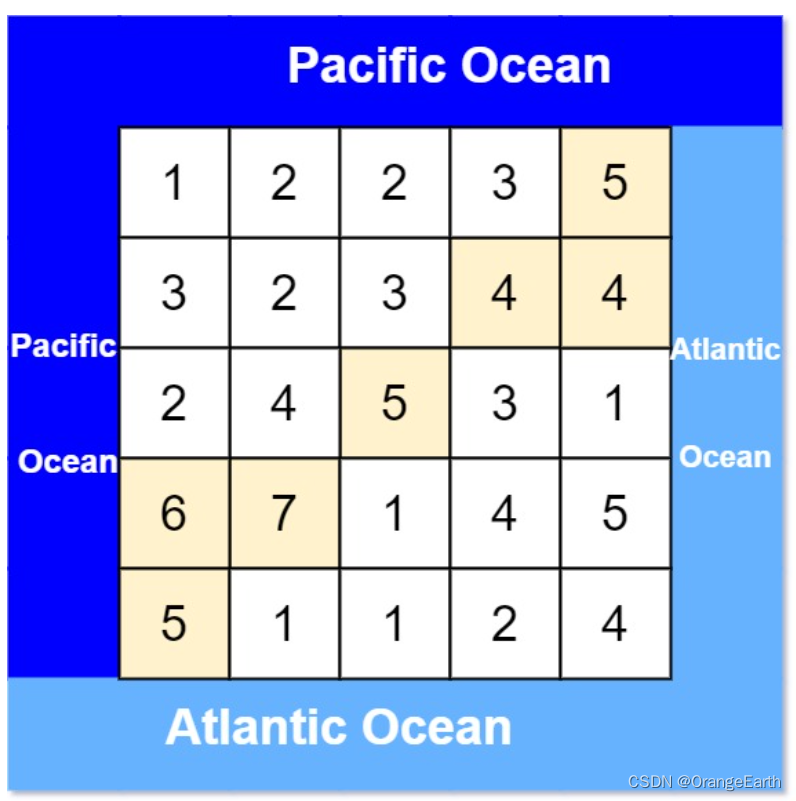
思路:这道题本身不难,关键是理解题意。简单来说就是:雨水只能从高的地方流向低的地方,求二维表格中哪些坐标的雨水既可以流入太平洋又可以流入大西洋。详细解析
那么一个比较直白的想法,其实就是 遍历每个点,然后看这个点 能不能同时到达太平洋和大西洋。遍历每一个节点,是 m ∗ n m * n m∗n,遍历每一个节点的时候,都要做深搜,深搜的时间复杂度是: m ∗ n m * n m∗n,那么整体时间复杂度 就是$ O(m^2 * n^2) $,这是一个四次方的时间复杂度,显然没有进行任何优化,大概率会超时。
那么我们可以 反过来想,从太平洋边上的节点 逆流而上,将遍历过的节点都标记上。 从大西洋的边上节点 逆流而长,将遍历过的节点也标记上。 然后两方都标记过的节点就是既可以流太平洋也可以流大西洋的节点。
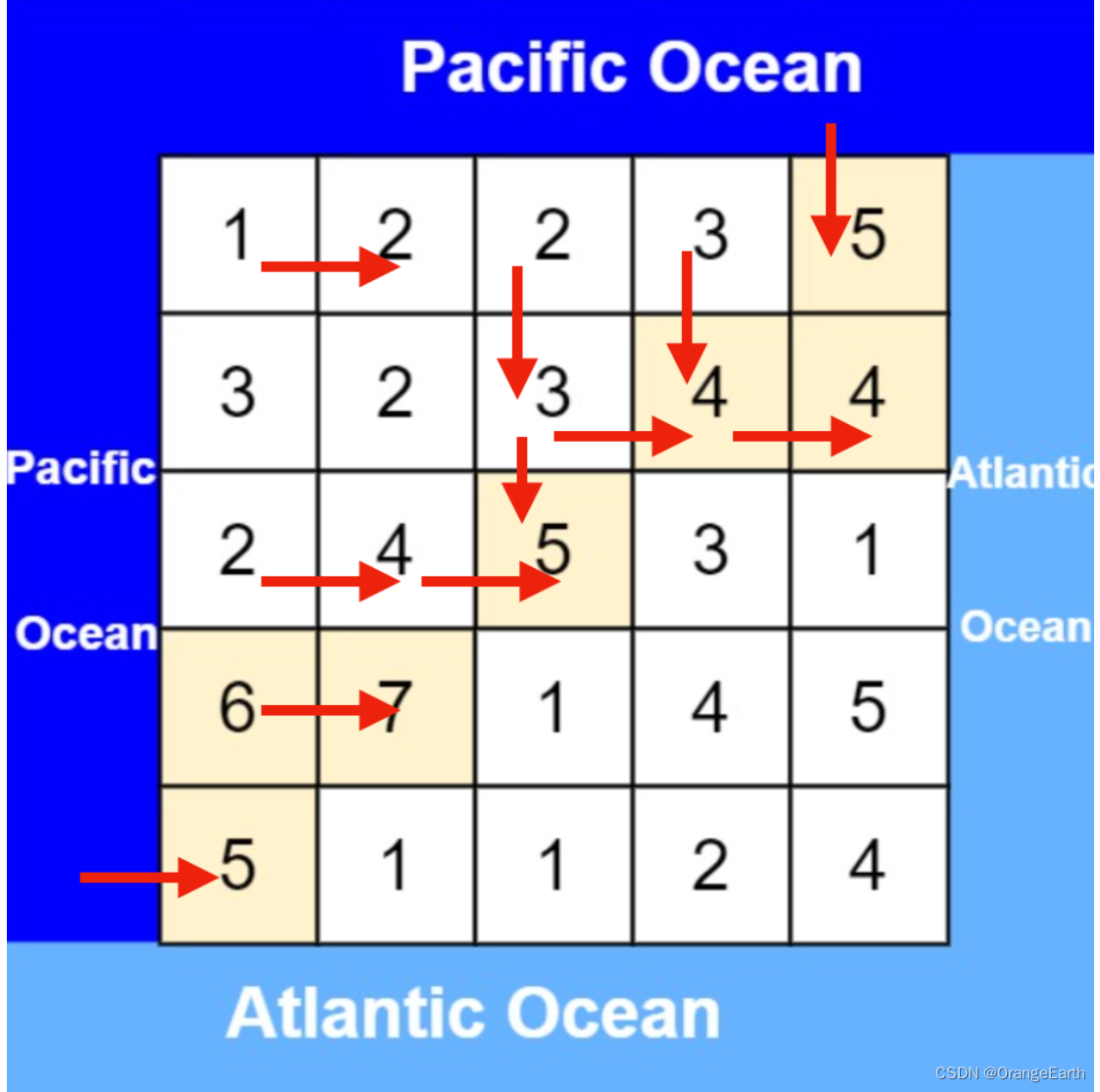
从太平洋边上节点出发,如图:
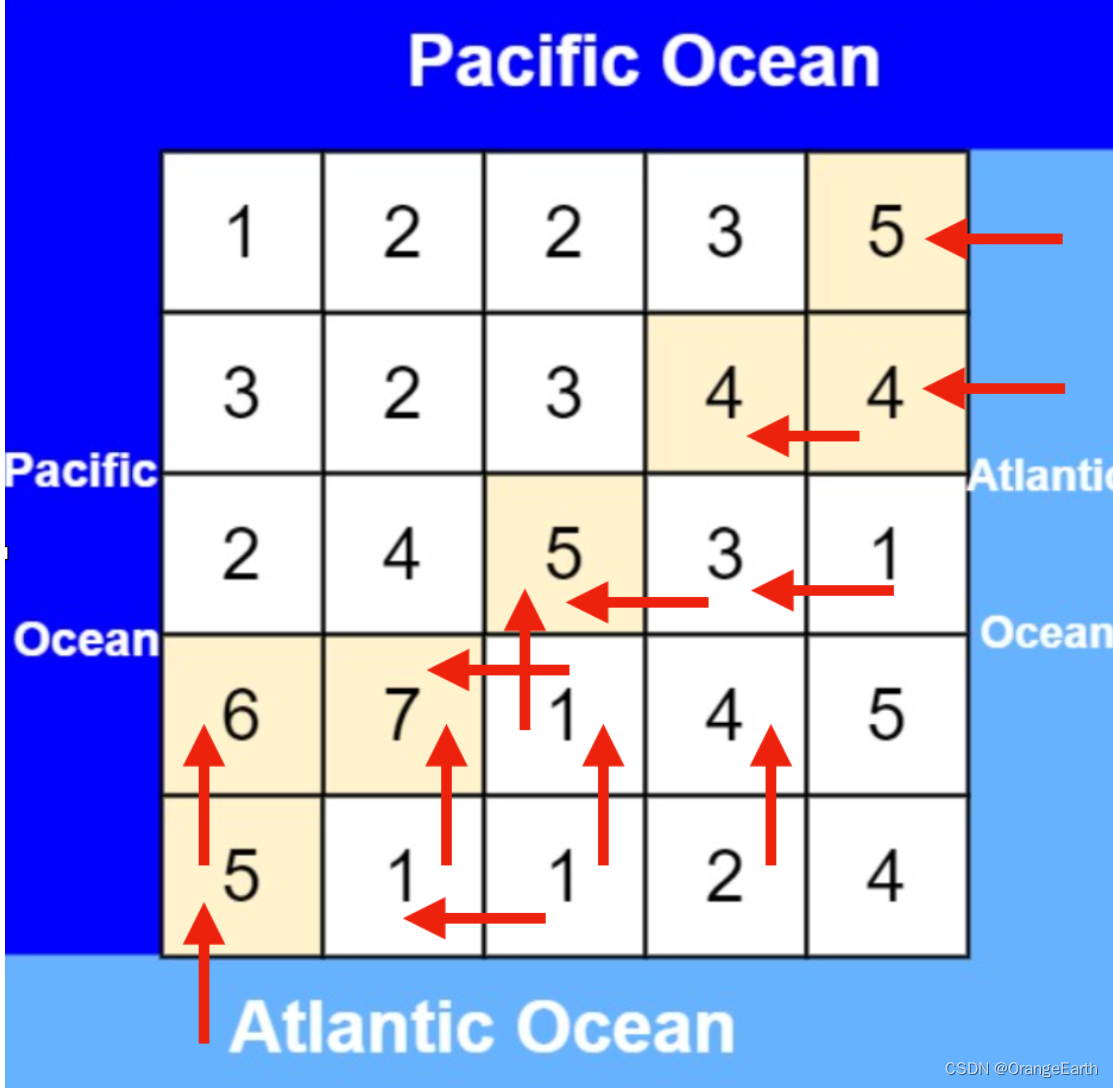
从大西洋边上节点出发,如图:
代码实现:
class Solution {
private:
int dir[4][2] = {-1, 0, 0, -1, 1, 0, 0, 1}; // 保存四个方向
// 从低向高遍历,注意这里visited是引用,即可以改变传入的pacific和atlantic的值
void dfs(vector<vector<int>>& heights, vector<vector<bool>>& visited, int x, int y) {
if (visited[x][y]) return;
visited[x][y] = true;
for (int i = 0; i < 4; i++) { // 向四个方向遍历
int nextx = x + dir[i][0];
int nexty = y + dir[i][1];
// 超过边界
if (nextx < 0 || nextx >= heights.size() || nexty < 0 || nexty >= heights[0].size()) continue;
// 高度不合适,注意这里是从低向高判断
if (heights[x][y] > heights[nextx][nexty]) continue;
dfs (heights, visited, nextx, nexty);
}
return;
}
public:
vector<vector<int>> pacificAtlantic(vector<vector<int>>& heights) {
vector<vector<int>> result;
int n = heights.size();
int m = heights[0].size(); // 这里不用担心空指针,题目要求说了长宽都大于1
// 记录从太平洋边出发,可以遍历的节点
vector<vector<bool>> pacific = vector<vector<bool>>(n, vector<bool>(m, false));
// 记录从大西洋出发,可以遍历的节点
vector<vector<bool>> atlantic = vector<vector<bool>>(n, vector<bool>(m, false));
// 从最上最下行的节点出发,向高处遍历
for (int i = 0; i < n; i++) {
dfs (heights, pacific, i, 0); // 遍历最左列,接触太平洋
dfs (heights, atlantic, i, m - 1); // 遍历最右列,接触大西
}
// 从最左最右列的节点出发,向高处遍历
for (int j = 0; j < m; j++) {
dfs (heights, pacific, 0, j); // 遍历最上行,接触太平洋
dfs (heights, atlantic, n - 1, j); // 遍历最下行,接触大西洋
}
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
// 如果这个节点,从太平洋和大西洋出发都遍历过,就是结果
if (pacific[i][j] && atlantic[i][j]) result.push_back({i, j});
}
}
return result;
}
};
- 时间复杂度:O(n * m)
关于dfs函数搜索的过程 时间复杂度是 O(n * m)。
关键看主函数,那么每次dfs的时候,上面还是有for循环的。
第一个for循环,时间复杂度是: n ∗ ( n ∗ m ) n * (n * m) n∗(n∗m)。
第二个for循环,时间复杂度是: m ∗ ( n ∗ m ) m * (n * m) m∗(n∗m)。
所以本题看起来 时间复杂度好像是 : n ∗ ( n ∗ m ) + m ∗ ( n ∗ m ) = ( m ∗ n ) ∗ ( m + n ) n * (n * m) + m * (n * m) = (m * n) * (m + n) n∗(n∗m)+m∗(n∗m)=(m∗n)∗(m+n) 。
其实这是一个误区,大家再自己看 dfs函数的实现,其实 有visited函数记录 走过的节点,而走过的节点是不会再走第二次的。
所以 调用dfs函数,只要参数传入的是数组pacific,那么地图中 每一个节点其实就遍历一次,无论你调用多少次。
同理,调用 dfs函数,只要 参数传入的是 数组atlantic,地图中每个节点也只会遍历一次。
所以,以下这段代码的时间复杂度是 2 ∗ n ∗ m 2 * n * m 2∗n∗m。 地图用每个节点就遍历了两次,参数传入pacific的时候遍历一次,参数传入atlantic的时候遍历一次。
// 从最上最下行的节点出发,向高处遍历
for (int i = 0; i < n; i++) {
dfs (heights, pacific, i, 0); // 遍历最上行,接触太平洋
dfs (heights, atlantic, i, m - 1); // 遍历最下行,接触大西洋
}
// 从最左最右列的节点出发,向高处遍历
for (int j = 0; j < m; j++) {
dfs (heights, pacific, 0, j); // 遍历最左列,接触太平洋
dfs (heights, atlantic, n - 1, j); // 遍历最右列,接触大西洋
}
那么本题整体的时间复杂度其实是: 2 ∗ n ∗ m + n ∗ m 2 * n * m + n * m 2∗n∗m+n∗m,所以最终时间复杂度为 O(n * m) 。
- 空间复杂度为:O(n * m)
827 最大人工岛(hard)
给你一个大小为 n x n 二进制矩阵 grid 。最多 只能将一格 0 变成 1 。
返回执行此操作后,grid 中最大的岛屿面积是多少?
岛屿 由一组上、下、左、右四个方向相连的 1 形成。
思路:和图论1中的模板题相比,这道题的思维难度的确比较大。详细解析
如果使用暴力解法的话,应该是遍历地图尝试将每一个 0 改成1,然后去搜索地图中的最大的岛屿面积。
计算地图的最大面积:遍历地图 + 深搜岛屿,时间复杂度为 n * n。(其实使用深搜还是广搜都是可以的,其目的就是遍历岛屿做一个标记,相当于染色,那么使用哪个遍历方式都行,以下我用深搜来讲解)
每改变一个0的方格,都需要重新计算一个地图的最大面积,所以 整体时间复杂度为: n 4 n^4 n4,没有进行任何优化显然不是一个比较好的选择。
其实每次深搜遍历计算最大岛屿面积,我们都做了很多重复的工作。
只要用一次深搜把每个岛屿的面积记录下来就好。
- 第一步:一次遍历地图,得出各个岛屿的面积,并做编号记录。可以使用map记录,key为岛屿编号,value为岛屿面积
- 第二步:遍历地图,遍历0的方格(因为要将0变成1),并统计该1(由0变成的1)周边岛屿面积,将其相邻面积相加在一起,遍历所有 0 之后,就可以得出 选一个0变成1 之后的最大面积。
下面的代码均适用于grid的长宽不等的情形!
代码实现1:
class Solution {
private:
int count;
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 四个方向
void dfs(vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y, int mark) {
if (visited[x][y] || grid[x][y] == 0) return; // 终止条件:访问过的节点 或者 遇到海水
visited[x][y] = true; // 标记访问过
grid[x][y] = mark; // 给陆地标记新标签
count++;
for (int i = 0; i < 4; i++) {
int nextx = x + dir[i][0];
int nexty = y + dir[i][1];
if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 越界了,直接跳过
dfs(grid, visited, nextx, nexty, mark);
}
}
public:
int largestIsland(vector<vector<int>>& grid) {
int n = grid.size(), m = grid[0].size();
vector<vector<bool>> visited = vector<vector<bool>>(n, vector<bool>(m, false)); // 标记访问过的点
unordered_map<int ,int> gridNum;
int mark = 2; // 记录每个岛屿的编号
bool isAllGrid = true; // 标记是否整个地图都是陆地
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
if (grid[i][j] == 0) isAllGrid = false;
if (!visited[i][j] && grid[i][j] == 1) {
count = 0;
dfs(grid, visited, i, j, mark); // 将与其链接的陆地都标记上 true
gridNum[mark] = count; // 记录每一个岛屿的面积
mark++; // 记录下一个岛屿编号
}
}
}
if (isAllGrid) return n * m; // 如果都是陆地,返回全面积
// 以下逻辑是根据添加陆地的位置,计算周边岛屿面积之和
int result = 0; // 记录最后结果
unordered_set<int> visitedGrid; // 标记访问过的岛屿
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
int count = 1; // 记录连接之后的岛屿数量
visitedGrid.clear(); // 每次使用时,清空
if (grid[i][j] == 0) {
for (int k = 0; k < 4; k++) {
int neari = i + dir[k][1]; // 计算相邻坐标
int nearj = j + dir[k][0];
if (neari < 0 || neari >= grid.size() || nearj < 0 || nearj >= grid[0].size()) continue;
if (visitedGrid.count(grid[neari][nearj])) continue; // 添加过的岛屿不要重复添加
// 把相邻四面的岛屿数量加起来
count += gridNum[grid[neari][nearj]];
visitedGrid.insert(grid[neari][nearj]); // 标记该岛屿已经添加过
}
}
result = max(result, count);
}
}
return result;
}
};
- 时间复杂度:类似于上一题的分析为O(n * n)
- 空间复杂度:O(n * n)
当然这里还有一个优化的点,就是 可以不用 visited数组,因为有mark来标记,所以遍历过的grid[i][j]是不等于1的。
代码实现2:
class Solution {
public:
int dir[4][2] = {{0, 1}, {0, -1}, {1, 0}, {-1, 0}};
int count;
void dfs(vector<vector<int>>& grid, int x, int y, int mark) {
grid[x][y] = mark;
count++;
for (int i = 0; i < 4; ++i) {
int nextx = x + dir[i][0];
int nexty = y + dir[i][1];
if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue;
if (grid[nextx][nexty] == 1) {
dfs(grid, nextx, nexty, mark);
}
}
}
int largestIsland(vector<vector<int>>& grid) {
int n = grid.size(), m = grid[0].size();
bool isAllGrid = true;
int mark = 2;
unordered_map<int, int> gridNum;
for (int i = 0; i < n; ++i) {
for (int j = 0; j < m; ++j) {
if (grid[i][j] == 0) isAllGrid = false;
if (grid[i][j] == 1) {
count = 0;
dfs(grid, i, j, mark);
gridNum[mark] = count;
mark++;
}
}
}
if (isAllGrid) return n * m;
int result = 0;
unordered_set<int> visitedGrid;
for (int i = 0; i < n; ++i) {
for (int j = 0; j < m; ++j) {
if (grid[i][j] == 0) {
count = 1;
visitedGrid.clear();
for (int k = 0; k < 4; ++k) {
int neari = i + dir[k][0];
int nearj = j + dir[k][1];
if (neari < 0 || neari >= n || nearj < 0 || nearj >= m) continue;
if (visitedGrid.count(grid[neari][nearj])) continue;
else {
count += gridNum[grid[neari][nearj]];
visitedGrid.insert(grid[neari][nearj]);
}
}
result = max(result, count);
}
}
}
return result;
}
};
127 单词接龙(medium)
字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列 beginWord -> s1 -> s2 -> … -> sk:
- 每一对相邻的单词只差一个字母。
- 对于 1 <= i <= k 时,每个 si 都在 wordList 中。注意, beginWord 不需要在 wordList 中。
- sk == endWord
给你两个单词 beginWord 和 endWord 和一个字典 wordList ,返回 从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0 。
思路:因为我们要求最短转换序列,所以使用广搜,这里仅介绍最朴素的广搜,关于双向BFS(就是从头尾两端进行搜索)的优化不做详细讲解。
用队列来实现广度优先搜索,那么我们首先初始化队列然后从beginWord开始进行搜索,搜索空间为遍历当前搜索的word的每一个字母然后穷尽26个字母的组合,也就是m * 26。
// 初始化队列
queue<string> que;
que.push(beginWord);
while(!que.empty()) {
string word = que.front();
que.pop();
for (int i = 0; i < word.size(); i++) {
string newWord = word; // 用一个新单词替换word,因为每次置换一个字母
for (int j = 0 ; j < 26; j++) {
newWord[i] = j + 'a';
//处理逻辑(包含了向que中插入可行的单词)
}
}
}
}
但是搜索空间中的newWord只有在wordList中出现过我们才是有可能的选择,因为要不断对wordList进行搜索,所以在最开始我们将wordList转化为wordSet。有了wordSet我们可以先进行endWord是都否在词典中的检测。
unordered_set<string> wordSet(wordList.begin(), wordList.end());
// 如果endWord没有在wordSet出现,直接返回0
if (wordSet.find(endWord) == wordSet.end()) return 0;
同时我们要设置截止到每个可行单词的path的长度,这个可以用map来实现。
unordered_map<string, int> visitMap; // <word, 查询到这个word路径长度>
visitMap.insert(pair<string, int>(beginWord, 1));
有了上面这些准备,我们就可以书写循环中的处理逻辑这一部分了,注意在处理逻辑里面需要用标记位,标记着节点是否走过。
比如:如果我们搜索过A->B, 那么我们就将B放入visitMap,下次就不会出现A->B->C的情形了(这种情形既不可能是最短路径而且可能陷入死循环)
则处理逻辑的代码实现:
while(!que.empty()) {
string word = que.front();
que.pop();
int path = visitMap[word]; // 这个word的路径长度
for (int i = 0; i < word.size(); i++) {
string newWord = word; // 用一个新单词替换word,因为每次置换一个字母
for (int j = 0 ; j < 26; j++) {
newWord[i] = j + 'a';
if (newWord == endWord) return path + 1; // 找到了end,返回path+1
// wordSet出现了newWord,并且newWord没有被访问过
if (wordSet.find(newWord) != wordSet.end()
&& visitMap.find(newWord) == visitMap.end()) {
// 添加访问信息
visitMap.insert(pair<string, int>(newWord, path + 1));
que.push(newWord);
}
}
}
注意事项:
- 本题是一个无向图,需要用标记位,标记着节点是否走过,否则就会死循环!
- 本题给出集合是数组型的,可以转成set结构,查找更快一些
代码实现:
class Solution {
public:
int ladderLength(string beginWord, string endWord, vector<string>& wordList) {
// 将vector转成unordered_set,提高查询速度
unordered_set<string> wordSet(wordList.begin(), wordList.end());
// 如果endWord没有在wordSet出现,直接返回0
if (wordSet.find(endWord) == wordSet.end()) return 0;
// 记录word是否访问过
unordered_map<string, int> visitMap; // <word, 查询到这个word路径长度>
// 初始化队列
queue<string> que;
que.push(beginWord);
// 初始化visitMap
visitMap.insert(pair<string, int>(beginWord, 1));
while(!que.empty()) {
string word = que.front();
que.pop();
int path = visitMap[word]; // 这个word的路径长度
for (int i = 0; i < word.size(); i++) {
string newWord = word; // 用一个新单词替换word,因为每次置换一个字母
for (int j = 0 ; j < 26; j++) {
newWord[i] = j + 'a';
if (newWord == endWord) return path + 1; // 找到了end,返回path+1
// wordSet出现了newWord,并且newWord没有被访问过
if (wordSet.find(newWord) != wordSet.end()
&& visitMap.find(newWord) == visitMap.end()) {
// 添加访问信息
visitMap.insert(pair<string, int>(newWord, path + 1));
que.push(newWord);
}
}
}
}
return 0;
}
};
841 钥匙和房间(medium)
有 n 个房间,房间按从 0 到 n - 1 编号。最初,除 0 号房间外的其余所有房间都被锁住。你的目标是进入所有的房间。然而,你不能在没有获得钥匙的时候进入锁住的房间。
当你进入一个房间,你可能会在里面找到一套不同的钥匙,每把钥匙上都有对应的房间号,即表示钥匙可以打开的房间。你可以拿上所有钥匙去解锁其他房间。
给你一个数组 rooms 其中 rooms[i] 是你进入 i 号房间可以获得的钥匙集合。如果能进入 所有 房间返回 true,否则返回 false。
思路:整理时候的漏网之鱼,这个还是深搜广搜的模板题,可以回去图论1再回顾一下模板
代码实现1(深搜):
// 写法一:处理当前访问的节点
class Solution {
private:
void dfs(const vector<vector<int>>& rooms, int key, vector<bool>& visited) {
if (visited[key]) {
return;
}
visited[key] = true;
vector<int> keys = rooms[key];
for (int key : keys) {
// 深度优先搜索遍历
dfs(rooms, key, visited);
}
}
public:
bool canVisitAllRooms(vector<vector<int>>& rooms) {
vector<bool> visited(rooms.size(), false);
dfs(rooms, 0, visited);
//检查是否都访问到了
for (int i : visited) {
if (i == false) return false;
}
return true;
}
};
代码实现2(深搜):
写法二:处理下一个要访问的节点
class Solution {
private:
void dfs(const vector<vector<int>>& rooms, int key, vector<bool>& visited) {
vector<int> keys = rooms[key];
for (int key : keys) {
if (visited[key] == false) {
visited[key] = true;
dfs(rooms, key, visited);
}
}
}
public:
bool canVisitAllRooms(vector<vector<int>>& rooms) {
vector<bool> visited(rooms.size(), false);
visited[0] = true; // 0 节点是出发节点,一定被访问过
dfs(rooms, 0, visited);
//检查是否都访问到了
for (int i : visited) {
if (i == false) return false;
}
return true;
}
};
代码实现3(广搜):
class Solution {
bool bfs(const vector<vector<int>>& rooms) {
vector<int> visited(rooms.size(), 0); // 标记房间是否被访问过
visited[0] = 1; // 0 号房间开始
queue<int> que;
que.push(0); // 0 号房间开始
// 广度优先搜索的过程
while (!que.empty()) {
int key = que.front(); que.pop();
vector<int> keys = rooms[key];
for (int key : keys) {
if (!visited[key]) {
que.push(key);
visited[key] = 1;
}
}
}
// 检查房间是不是都遍历过了
for (int i : visited) {
if (i == 0) return false;
}
return true;
}
public:
bool canVisitAllRooms(vector<vector<int>>& rooms) {
return bfs(rooms);
}
};
463 岛屿的周长(easy)
给定一个 row x col 的二维网格地图 grid ,其中:grid[i][j] = 1 表示陆地, grid[i][j] = 0 表示水域。
网格中的格子 水平和垂直 方向相连(对角线方向不相连)。整个网格被水完全包围,但其中恰好有一个岛屿(或者说,一个或多个表示陆地的格子相连组成的岛屿)。
岛屿中没有“湖”(“湖” 指水域在岛屿内部且不和岛屿周围的水相连)。格子是边长为 1 的正方形。网格为长方形,且宽度和高度均不超过 100 。计算这个岛屿的周长。
思路:这道题出现在这里只是因为要破除一下思路上的误区。岛屿问题最容易让人想到BFS或者DFS,但是这道题还真的没有必要,别把简单问题搞复杂了。
解法1:遍历每一个空格,遇到岛屿,计算其上下左右的情况,遇到水域或者出界的情况,就可以计算边了。
解法2:计算出总的岛屿数量,因为有一对相邻两个陆地,边的总数就减2,那么再计算出相邻岛屿的数量就可以了。result = 岛屿数量 * 4 - cover * 2
代码实现1:
class Solution {
public:
int direction[4][2] = {0, 1, 1, 0, -1, 0, 0, -1};
int islandPerimeter(vector<vector<int>>& grid) {
int result = 0;
for (int i = 0; i < grid.size(); i++) {
for (int j = 0; j < grid[0].size(); j++) {
if (grid[i][j] == 1) {
for (int k = 0; k < 4; k++) { // 上下左右四个方向
int x = i + direction[k][0];
int y = j + direction[k][1]; // 计算周边坐标x,y
if (x < 0 // i在边界上
|| x >= grid.size() // i在边界上
|| y < 0 // j在边界上
|| y >= grid[0].size() // j在边界上
|| grid[x][y] == 0) { // x,y位置是水域
result++;
}
}
}
}
}
return result;
}
};
代码实现2:
class Solution {
public:
int islandPerimeter(vector<vector<int>>& grid) {
int sum = 0; // 陆地数量
int cover = 0; // 相邻数量
for (int i = 0; i < grid.size(); i++) {
for (int j = 0; j < grid[0].size(); j++) {
if (grid[i][j] == 1) {
sum++;
// 统计上边相邻陆地
if(i - 1 >= 0 && grid[i - 1][j] == 1) cover++;
// 统计左边相邻陆地
if(j - 1 >= 0 && grid[i][j - 1] == 1) cover++;
// 为什么没统计下边和右边? 因为避免重复计算
}
}
}
return sum * 4 - cover * 2;
}
};