Spec-Gaussian: Anisotropic View-Dependent Appearance for 3D Gaussian Splatting
Spec-Gaussian:3D高斯溅射的各向异性视图相关外观
杨子怡 1,3 高新宇 1 太阳扬天 2 黄宜华 2 吕晓阳 2
Wen Zhou3 Shaohui Jiao3 Xiaojuan Qi2 Xiaogang Jin1
温州 3 邵辉娇 3 小娟齐 2 小岗金 1
1Zhejiang University 2The University of Hong Kong 3ByteDance Inc
1 浙江大学 2 香港大学 3 字节跳动公司
Abstract 摘要 Spec-Gaussian: Anisotropic View-Dependent Appearance for 3D Gaussian Splatting
The recent advancements in 3D Gaussian splatting (3D-GS) have not only facilitated real-time rendering through modern GPU rasterization pipelines but have also attained state-of-the-art rendering quality. Nevertheless, despite its exceptional rendering quality and performance on standard datasets, 3D-GS frequently encounters difficulties in accurately modeling specular and anisotropic components. This issue stems from the limited ability of spherical harmonics (SH) to represent high-frequency information. To overcome this challenge, we introduce Spec-Gaussian, an approach that utilizes an anisotropic spherical Gaussian (ASG) appearance field instead of SH for modeling the view-dependent appearance of each 3D Gaussian. Additionally, we have developed a coarse-to-fine training strategy to improve learning efficiency and eliminate floaters caused by overfitting in real-world scenes. Our experimental results demonstrate that our method surpasses existing approaches in terms of rendering quality. Thanks to ASG, we have significantly improved the ability of 3D-GS to model scenes with specular and anisotropic components without increasing the number of 3D Gaussians. This improvement extends the applicability of 3D GS to handle intricate scenarios with specular and anisotropic surfaces. Our codes and datasets will be released.
3D高斯溅射(3D-GS)的最新进展不仅促进了通过现代GPU光栅化管道的实时渲染,而且还获得了最先进的渲染质量。然而,尽管其卓越的渲染质量和性能的标准数据集,3D-GS经常遇到困难,准确建模镜面反射和各向异性组件。这个问题源于球谐函数(SH)表示高频信息的能力有限。为了克服这一挑战,我们引入Spec-Gaussian,这是一种利用各向异性球面高斯(ASG)外观场而不是SH来建模每个3D高斯的视图相关外观的方法。此外,我们还开发了一种从粗到精的训练策略,以提高学习效率,并消除真实场景中过拟合造成的漂浮物。 我们的实验结果表明,我们的方法优于现有的方法在渲染质量。由于ASG,我们已经显着提高了3D-GS的能力,在不增加3D高斯的数量的情况下,用镜面反射和各向异性组件建模场景。这种改进扩展了3D GS的适用性,以处理具有镜面反射和各向异性表面的复杂场景。我们的代码和数据集将被发布。
![[Uncaptioned image]](https://img-blog.csdnimg.cn/img_convert/d1c0cde613e59450adfa203e4476c80a.png)
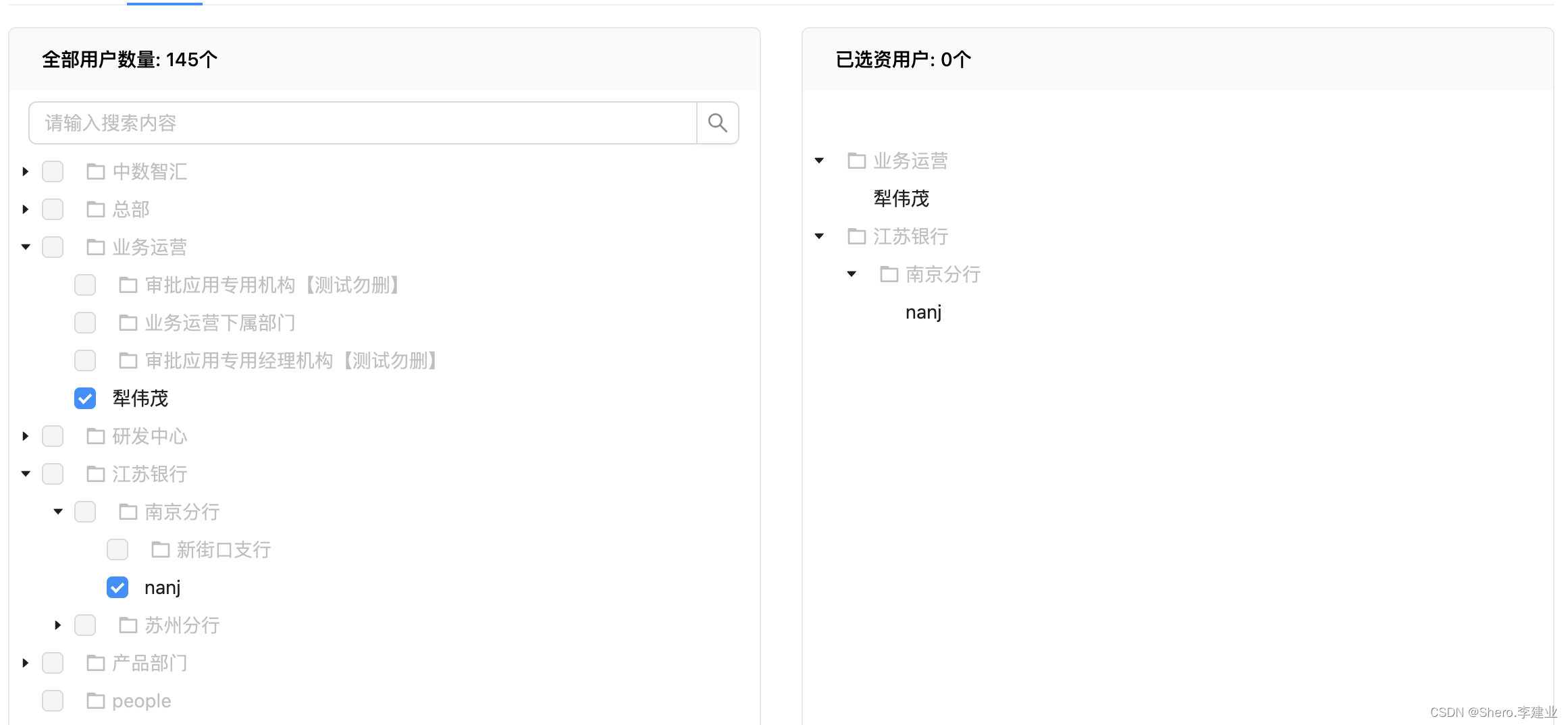
Figure 1:Our method not only achieves real-time rendering but also significantly enhances the capability of 3D-GS to model scenes with specular and anisotropic components. Key to this enhanced performance is our use of ASG appearance field to model the appearance of each 3D Gaussian, which results in substantial improvements in rendering quality for both complex and general scenes. Moreover, we employ anchor Gaussians to constrain the geometry of point-based representations, thereby improving the ability of 3D-GS to accurately model reflective parts and accelerating both training and rendering processes.
图一:我们的方法不仅实现了实时渲染,但也显着提高了3D-GS模型的能力,镜面反射和各向异性组件的场景。这种增强性能的关键是我们使用ASG外观场来模拟每个3D高斯的外观,这导致复杂和一般场景的渲染质量都有实质性的提高。此外,我们采用锚高斯约束的几何点为基础的表示,从而提高了3D-GS的能力,准确地建模反射部分和加速训练和渲染过程。
1Introduction 一、导言
High-quality reconstruction and photorealistic rendering from a collection of images are crucial for a variety of applications, such as augmented reality/virtual reality (AR/VR), 3D content production, and art creation. Classic methods employ primitive representations, like meshes [34] and points [4, 60], and take advantage of the rasterization pipeline optimized for contemporary GPUs to achieve real-time rendering. In contrast, neural radiance fields (NeRF) [32, 6, 33] utilize neural implicit representation to offer a continuous scene representation and employ volumetric rendering to produce rendering results. This approach allows for enhanced preservation of scene details and more effective reconstruction of scene geometries.
从图像集合中进行高质量的重建和真实感渲染对于各种应用至关重要,例如增强现实/虚拟现实(AR/VR),3D内容制作和艺术创作。经典方法采用图元表示,如网格[34]和点[4,60],并利用针对当代GPU优化的光栅化流水线来实现实时渲染。相比之下,神经辐射场(NeRF)[32,6,33]利用神经隐式表示来提供连续的场景表示,并采用体积渲染来产生渲染结果。这种方法允许增强场景细节的保存和更有效的场景几何重建。
Recently, 3D Gaussian Splatting (3D-GS) [21] has emerged as a leading technique, delivering state-of-the-art quality and real-time speed. This method optimizes a set of 3D Gaussians that capture the appearance and geometry of a 3D scene simultaneously, offering a continuous representation that preserves details and produces high-quality results. Besides, the CUDA-customized differentiable rasterization pipeline for 3D Gaussians enables real-time rendering even at high resolution.
最近,3D高斯溅射(3D-GS)[21]已经成为一种领先的技术,提供最先进的质量和实时速度。该方法优化了一组同时捕获3D场景的外观和几何形状的3D高斯,提供了一种连续的表示,保留了细节并产生了高质量的结果。此外,CUDA定制的3D高斯可微分光栅化管道即使在高分辨率下也能实现实时渲染。
Despite its exceptional performance, 3D-GS struggles to model specular components within scenes (see Fig. 1). This issue primarily stems from the limited ability of low-order spherical harmonics (SH) to capture the high-frequency information required in these scenarios. Consequently, this poses a challenge for 3D-GS to model scenes with reflections and specular components, as illustrated in Fig. 1 and Fig. 7.
尽管3D-GS具有出色的性能,但它仍难以对场景中的镜面反射组件进行建模(见图1)。这个问题主要源于低阶球面谐波(SH)捕获这些场景中所需的高频信息的能力有限。因此,如图1和图7所示,这对3D-GS建模具有反射和镜面反射分量的场景提出了挑战。
To address the issue, we introduce a novel approach called Spec-Gaussian, which combines anisotropic spherical Gaussian (ASG) [54] for modeling anisotropic and specular components, anchor-based geometry-aware 3D Gaussians for acceleration and storage reduction, and an effective training mechanism to eliminate floaters and improve learning efficiencies. Specifically, the method incorporates three key designs: 1) A new 3D Gaussian representation that utilizes an ASG appearance field instead of SH to model the appearance of each 3D Gaussian. ASG with a few orders can effectively model high-frequency information that low-order SH cannot. This new design enables 3D-GS to more effectively model anisotropic and specular components in static scenes. 2) A hybrid approach employing sparse anchor points to control the location and representation of its child Gaussians. This strategy results in a hierarchical and geometry-aware point-based scene representation and enables us to store only the anchor Gaussians, significantly reducing storage requirements and enhancing the geometry. 3) A coarse-to-fine training scheme specifically tailored for 3D-GS is designed to eliminate floaters and boost learning efficiency. This strategy effectively shortens learning time by optimizing low-resolution rendering in the initial stage, preventing the need to increase the number of 3D Gaussians and regularizing the learning process to avoid the generation of unnecessary geometric structures that lead to floaters.
为了解决这个问题,我们引入了一种名为Spec-Gaussian的新方法,该方法结合了各向异性球面高斯(ASG)[54]用于建模各向异性和镜面反射组件,基于锚的几何感知3D高斯用于加速和减少存储,以及有效的训练机制来消除浮动和提高学习效率。具体而言,该方法结合了三个关键设计:1)新的3D高斯表示,其利用ASG外观场而不是SH来对每个3D高斯的外观进行建模。几阶的ASG可以有效地模拟低频SH不能模拟的高频信息。这种新设计使3D-GS能够更有效地在静态场景中对各向异性和镜面反射组件进行建模。2)采用稀疏锚点的混合方法来控制其子高斯的位置和表示。 这种策略的结果在一个层次和几何感知的基于点的场景表示,使我们能够存储只有锚高斯,显着降低存储要求和增强的几何形状。3)专门为3D-GS定制的由粗到精的训练方案旨在消除浮动点并提高学习效率。该策略通过在初始阶段优化低分辨率渲染,防止需要增加3D高斯的数量,并使学习过程规则化,以避免产生导致浮动的不必要的几何结构,从而有效地缩短了学习时间。
By combining these advances, our approach can render high-quality results for specular highlights and anisotropy as shown in Fig. 4 while preserving the efficiency of Gaussians. Furthermore, comprehensive experiments reveal that our method not only endows 3D-GS with the ability to model specular highlights but also achieves state-of-the-art results in general benchmarks.
通过结合这些进步,我们的方法可以为镜面高光和各向异性呈现高质量的结果,如图4所示,同时保留高斯的效率。此外,全面的实验表明,我们的方法不仅赋予3D-GS与建模镜面高光的能力,但也达到了国家的最先进的结果,在一般的基准。
In summary, the major contributions of our work are as follows:
总括而言,我们的工作主要贡献如下:
- •
A novel ASG appearance field to model the view-dependent appearance of each 3D Gaussian, which enables 3D-GS to effectively represent scenes with specular and anisotropic components without sacrificing rendering speed.
·一种新颖的ASG外观场,用于对每个3D高斯的视图相关外观进行建模,这使得3D-GS能够有效地表示具有镜面反射和各向异性分量的场景,而不会牺牲渲染速度。 - •
An anchor-based hybrid model to reduce the computational and storage overhead brought by learning the ASG appearance field.
·基于锚点的混合模型,以减少学习ASG外观字段所带来的计算和存储开销。 - •
A coarse-to-fine training scheme that effectively regularizes training to eliminate floaters and improve the learning efficiency of 3D-GS in real-world scenes.
·从粗到精的训练方案,有效地规则化训练以消除漂浮物并提高3D-GS在真实场景中的学习效率。 - •
An anisotropic dataset has been made to assess the capability of our model in representing anisotropy. Extensive experiments show the effectiveness of our method in modeling scenes with specular highlights and anisotropy.
·已经制作了一个各向异性数据集来评估我们的模型在表示各向异性方面的能力。大量的实验表明,我们的方法在建模场景的镜面高光和各向异性的有效性。
2Related Work 2相关工作
2.1Implicit Neural Radiance Fields
2.1隐式神经辐射场
Neural rendering has attracted significant interest in the academic community for its unparalleled ability to generate photorealistic images. Methods like NeRF [32] utilize Multi-Layer Perceptrons (MLPs) to model the geometry and radiance fields of a scene. Leveraging the volumetric rendering equation and the inherent continuity and smoothness of MLPs, NeRF achieves high-quality scene reconstruction from a set of posed images, establishing itself as the state-of-the-art (SOTA) method for novel view synthesis. Subsequent research has extended the utility of NeRF to various applications, including mesh reconstruction [46, 25, 52], inverse rendering [42, 63, 29, 56], optimization of camera parameters [27, 48, 47, 36], few-shot learning [12, 55, 51], and anti-aliasing [2, 1, 3].
神经绘制以其无与伦比的生成真实感图像的能力引起了学术界的极大兴趣。像NeRF [32]这样的方法利用多层感知器(MLP)对场景的几何和辐射场进行建模。利用体积渲染方程和MLP固有的连续性和平滑性,NeRF从一组姿态图像中实现了高质量的场景重建,将自己确立为最先进的(SOTA)新视图合成方法。随后的研究将NeRF的实用性扩展到各种应用,包括网格重建[46,25,52],逆渲染[42,63,29,56],相机参数优化[27,48,47,36],少拍学习[12,55,51]和抗锯齿[2,1,3]。
However, this stream of methods relies on ray casting rather than rasterization to determine the color of each pixel. Consequently, every sampling point along the ray necessitates querying the MLPs, leading to significantly slow rendering speed and prolonged training convergence. This limitation substantially impedes their application in large-scene modeling and real-time rendering.
然而,这种方法流依赖于光线投射而不是光栅化来确定每个像素的颜色。因此,沿着射线的每个采样点沿着都需要查询MLP,导致显着降低的渲染速度和延长的训练收敛。这种局限性极大地阻碍了它们在大场景建模和实时绘制中的应用。
To reduce the training time of MLP-based NeRF methods and improve rendering speed, subsequent work has enhanced NeRF’s efficiency in various ways. Structure-based techniques [61, 13, 38, 16, 8] have sought to improve inference or training efficiency by caching or distilling the implicit neural representation into more efficient data structures. Hybrid methods [28, 43] increase efficiency by incorporating explicit voxel-based data structures. Factorization methods [5, 17, 9, 15] apply a low-rank tensor assumption to decompose the scene into low-dimensional planes or vectors, achieving better geometric consistency. Compared to continuous implicit representations, the convergence of individual voxels in the grid is independent, significantly reducing training time. Additionally, Instant-NGP [33] utilizes a hash grid with a corresponding CUDA implementation for faster feature querying, enabling rapid training and interactive rendering of neural radiance fields.
为了减少基于MLP的NeRF方法的训练时间并提高渲染速度,后续工作以各种方式提高了NeRF的效率。基于结构的技术[61,13,38,16,8]试图通过缓存或提取隐式神经表示为更有效的数据结构来提高推理或训练效率。混合方法[28,43]通过合并显式的基于体素的数据结构来提高效率。因式分解方法[5,17,9,15]应用低秩张量假设将场景分解为低维平面或向量,从而实现更好的几何一致性。与连续隐式表示相比,网格中单个体素的收敛是独立的,显著减少了训练时间。此外,Instant-NGP [33]利用哈希网格和相应的CUDA实现来实现更快的特征查询,从而实现神经辐射场的快速训练和交互式渲染。
Despite achieving higher quality and faster rendering, these methods have not fundamentally overcome the substantial query overhead associated with ray casting. As a result, a notable gap remains before achieving real-time rendering. In this work, we build upon the recent 3D-GS [21], a point-based rendering method that leverages rasterization. Compared to ray casting-based methods, it significantly enhances both training and rendering speed.
尽管实现了更高的质量和更快的渲染,这些方法没有从根本上克服与光线投射相关联的大量查询开销。因此,在实现实时渲染之前仍然存在明显的差距。在这项工作中,我们建立在最近的3D-GS [21],一个基于点的渲染方法,利用光栅化。与基于光线投射的方法相比,它显著提高了训练和渲染速度。
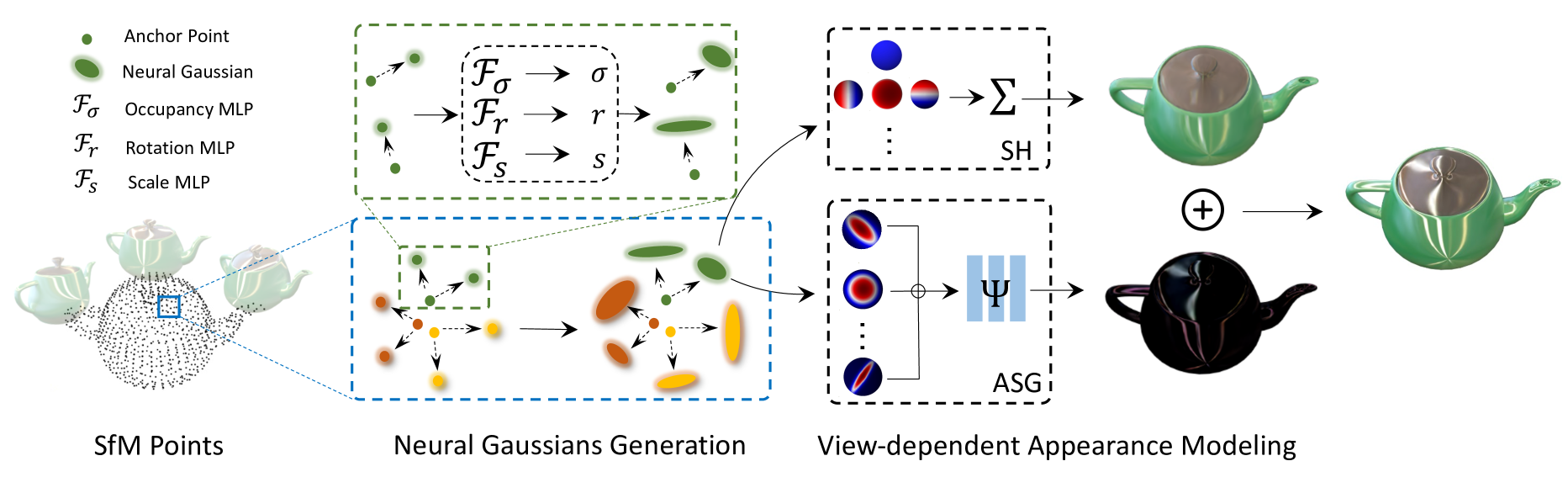
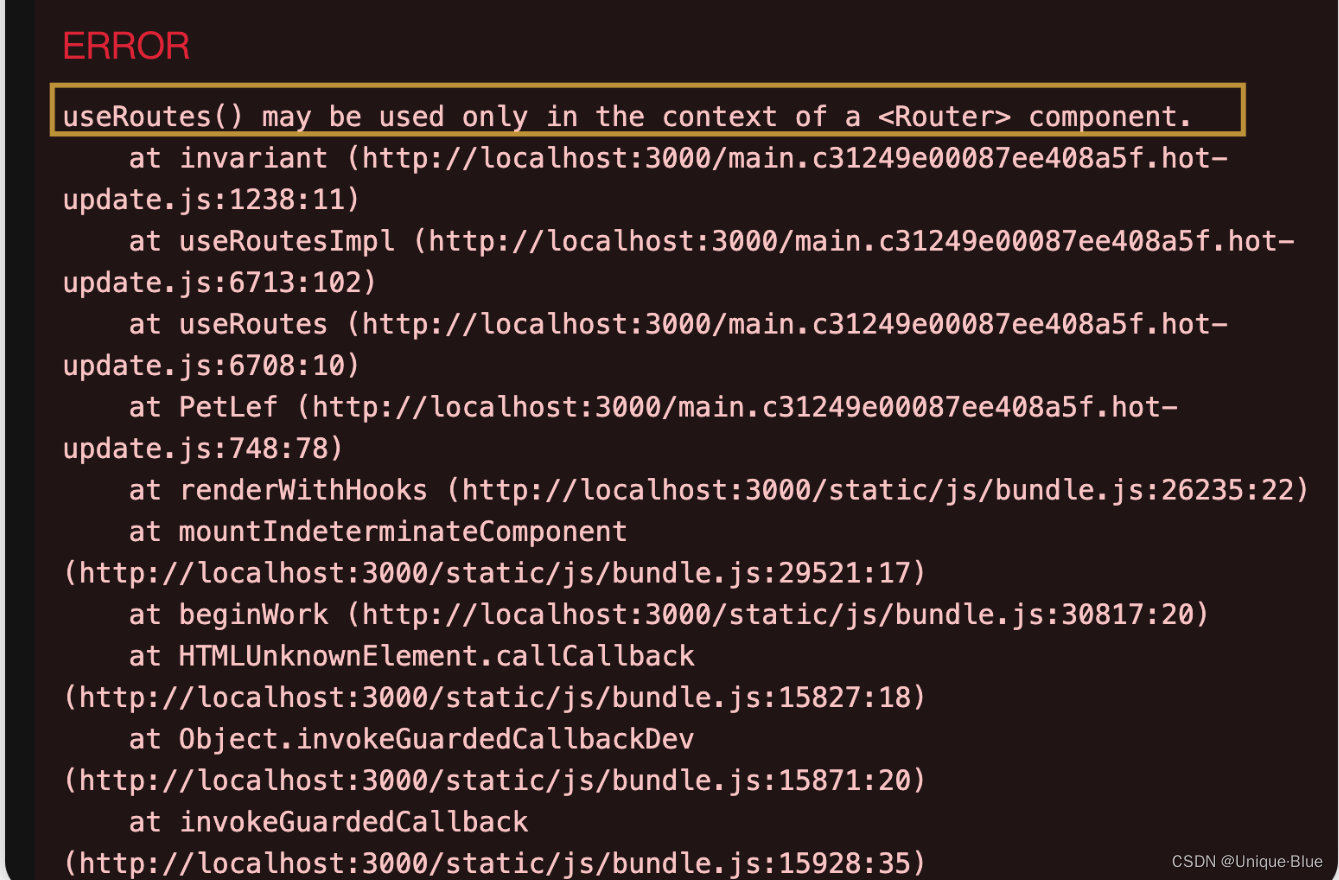
Figure 2:Pipeline of our proposed Spec-Gaussian. The optimization process begins with SfM points derived from COLMAP or generated randomly, serving as the initial state for the anchor Gaussians. Within a view frustum, � neural Gaussians are spawned from each visible anchor Gaussian, using the corresponding offsets. Their other attributes, such as opacity �, rotation �, and scaling �, are decoded through the respective tiny MLPs. To address the limitations of low-order SH and pure MLP in modeling high-frequency information, we additionally employ ASG in conjunction with a feature decoupling MLP to model the view-dependent appearance of each neural Gaussian. Subsequently, neural Gaussians with opacity �>0 are rendered through a differentiable Gaussian rasterization pipeline, effectively capturing specular highlights and anisotropy in the scene.
图2:我们提出的Spec-Gaussian的流水线。优化过程开始于从COLMAP导出或随机生成的SfM点,用作锚高斯的初始状态。在视锥体内,使用对应的偏移从每个可见的锚高斯产生 � 神经高斯。它们的其他属性,例如不透明度 � 、旋转 � 和缩放 � ,通过相应的微小MLP进行解码。为了解决低阶SH和纯MLP在建模高频信息时的局限性,我们还采用ASG结合特征解耦MLP来建模每个神经高斯的视图相关外观。随后,通过可微分高斯光栅化流水线渲染具有不透明度 �>0 的神经高斯,有效地捕获场景中的镜面高光和各向异性。
2.2Point-based Neural Radiance Fields
2.2基于点的神经辐射场
Point-based representations, similar to triangle mesh-based methods, can exploit the highly efficient rasterization pipeline of modern GPUs to achieve real-time rendering. Although these methods offer breakneck rendering speeds and are well-suited for editing tasks, they often suffer from holes and outliers, leading to artifacts in the rendered images. This issue arises from the discrete nature of point clouds, which can create gaps in the primitives and, consequently, in the rendered image.
基于点的表示类似于基于三角形网格的方法,可以利用现代GPU的高效光栅化流水线来实现实时渲染。虽然这些方法提供了极快的渲染速度,非常适合编辑任务,但它们通常会遇到漏洞和离群值,导致渲染图像中出现伪影。这个问题源于点云的离散特性,它会在图元中产生间隙,从而在渲染图像中产生间隙。
To address these discontinuity issues, differentiable point-based rendering [60, 14, 22, 23] has been extensively explored for fitting complex geometric shapes. Notably, Zhang et al. [62] employ differentiable surface splatting and utilize a radial basis function (RBF) kernel to compute the contribution of each point to each pixel.
为了解决这些不连续性问题,已经广泛探索了基于可微点的渲染[60,14,22,23]来拟合复杂的几何形状。值得注意的是,Zhang等人。[62]采用可微表面溅射并利用径向基函数(RBF)内核来计算每个点对每个像素的贡献。
Recently, 3D-GS [21] has employed anisotropic 3D Gaussians, initialized from Structure from Motion (SfM), to represent 3D scenes. The innovative densification mechanism and CUDA-customized differentiable Gaussian rasterization pipeline of 3D-GS have not only achieved state-of-the-art (SOTA) rendering quality but also significantly surpassed the threshold of real-time rendering. Many concurrent works have rapidly extended 3D-GS to a variety of downstream applications, including dynamic scenes [31, 57, 58, 18, 24, 50], text-to-3D generation [26, 44, 10, 59, 11], avatars [65, 64, 19, 39, 35], and scene editing [53, 7].
最近,3D-GS [21]采用了从运动恢复结构(SfM)初始化的各向异性3D高斯模型来表示3D场景。3D-GS创新的致密化机制和CUDA定制的可微分高斯光栅化流水线不仅实现了最先进的(SOTA)渲染质量,而且大大超过了实时渲染的门槛。许多并行工作已经将3D-GS快速扩展到各种下游应用,包括动态场景[31,57,58,18,24,50],文本到3D生成[26,44,10,59,11],化身[65,64,19,39,35]和场景编辑[53,7]。
Despite achieving SOTA results on commonly used benchmark datasets, 3D-GS still struggles to model scenes with specular and reflective components, which limits its practical application in real-time rendering at the photorealistic level. In this work, by replacing spherical harmonics (SH) with an anisotropic spherical Gaussian (ASG) appearance field, we have enabled 3D-GS to model complex specular scenes more effectively. Furthermore, this improvement enhances rendering quality in general scenes without significantly impacting rendering speed.
尽管在常用的基准数据集上实现了SOTA结果,但3D-GS仍然难以对具有镜面反射和反射组件的场景进行建模,这限制了其在真实感级别的实时渲染中的实际应用。在这项工作中,通过用各向异性球面高斯(ASG)外观场替换球面谐波(SH),我们使3D-GS能够更有效地对复杂的镜面场景进行建模。此外,这种改进提高了一般场景中的渲染质量,而不会显著影响渲染速度。
3Method 3方法
The overview of our method is illustrated in Fig. 2. The input to our model is a set of posed images of a static scene, together with a sparse point cloud obtained from SfM [40]. The core of our method is to use the ASG appearance field to replace SH in modeling the appearance of 3D Gaussians (Sec. 3.2). To reduce the storage overhead and rendering speed pressure introduced by ASG, we design a hybrid Gaussian model that employs sparse anchor Gaussians to facilitate the generation of neural Gaussians (Sec. 3.3) to model the 3D scene. Finally, we introduce a simple yet effective coarse-to-fine training strategy to reduce floaters in real-world scenes (Sec. 3.4).
我们的方法概述如图2所示。我们模型的输入是一组静态场景的姿势图像,以及从SfM [40]获得的稀疏点云。我们的方法的核心是使用ASG外观场来代替SH对3D高斯的外观进行建模(第二节)。3.2)。为了减少存储开销和绘制速度的压力引入ASG,我们设计了一个混合高斯模型,采用稀疏锚高斯,以促进神经高斯的生成(第二节)。3.3)to model模型the 3D scene场景.最后,我们介绍了一种简单而有效的从粗到精的训练策略,以减少真实场景中的漂浮物(第二节)。3.4)。
3.1Preliminaries
3.1.13D Gaussian Splatting
3.1.13D高斯溅射
3D-GS [21] is a point-based method that employs anisotropic 3D Gaussians to represent scenes. Each 3D Gaussian is defined by a center position 𝒙, opacity �, and a 3D covariance matrix Σ, which is decomposed into a quaternion 𝒓 and scaling 𝒔. The view-dependent appearance of each 3D Gaussian is represented using the first three orders of spherical harmonics (SH). This method not only retains the rendering details offered by volumetric rendering but also achieves real-time rendering through a CUDA-customized differentiable Gaussian rasterization process. Following [66], the 3D Gaussians can be projected to 2D using the 2D covariance matrix Σ′, defined as:
3D-GS [21]是一种基于点的方法,采用各向异性3D高斯来表示场景。每个3D高斯由中心位置 𝒙 、不透明度 � 和3D协方差矩阵 Σ 定义,该3D协方差矩阵被分解为四元数 𝒓 和缩放 𝒔 。每个3D高斯的视图相关外观使用前三阶球谐函数(SH)表示。该方法不仅保留了体绘制的细节,而且通过CUDA定制的可微分高斯光栅化过程实现了实时绘制。在[66]之后,可以使用2D协方差矩阵 Σ′ 将3D高斯投影到2D,定义为:
| Σ′=��Σ����, | (1) |
where � is the Jacobian of the affine approximation of the projective transformation, and � represents the view matrix, transitioning from world to camera coordinates. To facilitate learning, the 3D covariance matrix Σ is decomposed into two learnable components: the quaternion 𝒓, representing rotation, and the 3D-vector 𝒔, representing scaling. The resulting Σ is thus represented as the combination of a rotation matrix � and scaling matrix � as:
其中 � 是投影变换的仿射近似的雅可比矩阵,并且 � 表示从世界坐标转换到相机坐标的视图矩阵。为了便于学习,3D协方差矩阵 Σ 被分解为两个可学习的分量:表示旋转的四元数 𝒓 和表示缩放的3D向量 𝒔 。因此,所得到的 Σ 被表示为旋转矩阵 � 和缩放矩阵 � 的组合,如下:
| Σ=������. | (2) |
The color of each pixel on the image plane is then rendered through a point-based volumetric rendering (alpha blending) technique:
然后,通过基于点的体积渲染(alpha混合)技术渲染图像平面上每个像素的颜色:
| �(𝐩)=∑�∈�������,��=���−12(𝐩−��)�∑′(𝐩−��), | (3) |
where p denotes the pixel coordinate, �� is the transmittance defined by Π�=1�−1(1−��), �� signifies the color of the sorted Gaussians associated with the queried pixel, and �� represents the coordinates of the 3D Gaussians when projected onto the 2D image plane.
其中p表示像素坐标, �� 是由 Π�=1�−1(1−��) 定义的透射率, �� 表示与查询像素相关联的排序高斯的颜色,并且 �� 表示当投影到2D图像平面上时3D高斯的坐标。
3.1.2Anisotropic Spherical Gaussian.
3.1.2各向异性球面高斯。
Anisotropic spherical Gaussian (ASG) [54] has been designed within the traditional rendering pipeline to efficiently approximate lighting and shading. Different from spherical Gaussian (SG), ASG has been demonstrated to effectively represent anisotropic scenes with a relatively small number. In addition to retaining the fundamental properties of SG, ASG also exhibits rotational invariance and can represent full-frequency signals. The ASG function is defined as:
各向异性球面高斯(ASG)[54]已在传统渲染管道中设计,以有效地近似照明和阴影。与球面高斯(SG)不同,ASG已被证明可以有效地表示各向异性的场景与相对较小的数量。除了保留SG的基本特性外,ASG还具有旋转不变性,并且可以表示全频信号。ASG功能定义为:
| ���(�|[𝐱,𝐲,𝐳],[�,�],�)=�⋅S(�;𝐳)⋅�−�(�⋅𝐱)2−�(�⋅𝐲)2, | (4) |
where � is the unit direction serving as the function input; 𝐱, 𝐲, and 𝐳 correspond to the tangent, bi-tangent, and lobe axis, respectively, and are mutually orthogonal; �∈ℝ1 and �∈ℝ1 are the sharpness parameters for the 𝐱- and 𝐲-axis, satisfying �,�>0; �∈ℝ2 is the lobe amplitude; S is the smooth term defined as S(�;𝐳)=max(�⋅𝐳,0).
其中 � 是用作函数输入的单位方向; 𝐱 、 𝐲 和 𝐳 分别对应于切线、双切线和波瓣轴,并且相互正交; �∈ℝ1 和 �∈ℝ1 是用于 𝐱 和 𝐲 轴的锐度参数,满足 �,�>0 ; �∈ℝ2 是波瓣幅度; S 是定义为 S(�;𝐳)=max(�⋅𝐳,0) 的平滑项。
Inspired by the power of ASG in modeling scenes with complex anisotropy, we propose integrating ASG into Gaussian splatting to join the forces of classic models with new rendering pipelines for higher quality. For � ASGs, we predefined orthonormal axes 𝐱, 𝐲, and 𝐳, initializing them to be uniformly distributed across a hemisphere. During training, we allow the remaining ASG parameters, �, �, and �, to be learnable. We use the reflect direction �� as the input to query ASG for modeling the view-dependent specular information. Note that we use �=32 ASGs for each 3D Gaussian.
受ASG在复杂各向异性场景建模中的强大功能的启发,我们建议将ASG集成到高斯溅射中,以将经典模型的力量与新的渲染管道结合起来,以获得更高的质量。对于 � ASG,我们预定义了正交轴 𝐱 、 𝐲 和 𝐳 ,将它们初始化为均匀分布在半球上。在训练过程中,我们允许剩余的ASG参数 � 、 � 和 � 可学习。我们使用反射方向 �� 作为输入来查询ASG以建模视图相关的镜面反射信息。请注意,我们为每个3D高斯使用 �=32 ASG。
3.2Anisotropic View-Dependent Appearance
3.2各向异性视图相关外观
3.2.1ASG Appearance Field for 3D Gaussians.
3.2.1 3D高斯的ASG外观字段。
Although SH has enabled view-dependent scene modeling, the low frequency of low-order SH makes it challenging to model scenes with complex optical phenomena such as specular highlights and anisotropic effects. Therefore, instead of using SH, we propose using an ASG appearance field based on Eq. (4) to model the appearance of each 3D Gaussian. However, the introduction of ASG increases the feature dimensions of each 3D Gaussian, raising the model’s storage overhead. To address this, we employ a compact learnable MLP Θ to predict the parameters for � ASGs, with each Gaussian carrying only additional local features 𝐟∈ℝ24 as the input to the MLP:
虽然SH已经实现了视图相关的场景建模,但低阶SH的低频率使得对具有复杂光学现象(例如镜面高光和各向异性效果)的场景建模具有挑战性。因此,而不是使用SH,我们建议使用ASG外观字段的基础上方程。(4)来模拟每个3D高斯分布的外观。然而,ASG的引入增加了每个3D高斯的特征维度,提高了模型的存储开销。为了解决这个问题,我们采用紧凑的可学习MLP Θ 来预测 � ASG的参数,每个高斯仅携带额外的局部特征 𝐟∈ℝ24 作为MLP的输入:
| Θ(𝐟)→{�,�,�}�. | (5) |
To better differentiate between high and low-frequency information and further assist ASG in fitting high-frequency specular details, we decompose color � into diffuse and specular components:
为了更好地区分高频和低频信息,并进一步帮助ASG拟合高频高光细节,我们将颜色 � 分解为漫射和高光分量:
| � | =��+��, | (6) |
where �� represents the diffuse color, modeled using the first three orders of SH, and �� is the specular color calculated through ASG. We refer to this comprehensive approach to appearance modeling as the ASG appearance field.
其中 �� 表示使用SH的前三阶建模的漫射颜色, �� 是通过ASG计算的镜面反射颜色。我们将这种全面的外观建模方法称为ASG外观字段。
Although ASG theoretically enhance the ability of SH to model anisotropy, directly using ASG to represent the specular color of each 3D Gaussian still falls short in accurately modeling anisotropic and specular components, as demonstrated in Fig. 5. Inspired by [15], we do not use ASG directly to represent color but instead employ ASG to model the latent feature of each 3D Gaussian. This latent feature, containing anisotropic information, is then fed into a tiny feature decoupling MLP Ψ to determine the final specular color:
尽管ASG理论上增强了SH对各向异性建模的能力,但直接使用ASG来表示每个3D高斯的镜面颜色在准确建模各向异性和镜面分量方面仍然福尔斯不足,如图5所示。受[15]的启发,我们不直接使用ASG来表示颜色,而是使用ASG来建模每个3D高斯的潜在特征。然后,将包含各向异性信息的该潜在特征馈送到微小特征解耦MLP Ψ 中,以确定最终的镜面反射颜色:
| Ψ(�,�(𝐝),〈�,−𝐝〉)→��, | (7) | |||
| �=⨁�=1����(��|[𝐱,𝐲,𝐳],[��,��],��) |
where � is the latent feature derived from ASG, ⨁ denotes the concatenation operation, � represents the positional encoding, 𝐝 is the unit view direction pointing from the camera to each 3D Gaussian, � is the normal of each 3D Gaussian that will be discussed in Sec. 3.2.2, and �� is the unit reflect direction. This strategy significantly enhances the ability of 3D-GS to model scenes with complex optical phenomena, whereas neither pure ASG nor pure MLP can achieve anisotropic appearance modeling as effectively as our approach.
其中 � 是从ASG导出的潜在特征, ⨁ 表示级联操作, � 表示位置编码, 𝐝 是从相机指向每个3D高斯的单位视图方向, � 是将在第2.1.1节中讨论的每个3D高斯的法线。3.2.2, �� 为单位反射方向。这种策略显着提高了3D-GS的能力,以模拟场景与复杂的光学现象,而无论是纯ASG或纯MLP可以实现各向异性的外观建模,有效地为我们的方法。
3.2.2Normal Estimation 3.2.2法线估计
Directly estimating the normals of 3D Gaussians presents a challenge, as 3D-GS comprises a collection of discrete entities, each representing a local space within a certain range, without forming a continuous surface. The calculation of normals typically necessitates a continuous surface, and the anisotropic shape of each entity in 3D-GS further complicates the determination of normals. Following [20, 41], we use the shortest axis of each Gaussian as its normal. This approach is based on the observation that 3D Gaussians tend to flatten gradually during the optimization process, allowing the shortest axis to serve as a reasonable approximation for the normal.
直接估计3D高斯的法线是一个挑战,因为3D-GS包括离散实体的集合,每个实体表示特定范围内的局部空间,而不形成连续表面。法线的计算通常需要一个连续的表面,并且3D-GS中每个实体的各向异性形状进一步使法线的确定复杂化。在[20,41]之后,我们使用每个高斯的最短轴作为其法线。这种方法是基于这样的观察,即3D高斯曲线在优化过程中趋于逐渐变平,允许最短轴作为法线的合理近似。
The reflect direction �� can then be derived using the view direction and the local normal vector � as:
反射方向 �� 然后可以使用视图方向和局部法向矢量 � 导出为:
| ��=2(��⋅�)⋅�−��, | (8) |
where ��=−𝐝 is a unit view direction pointing from each 3D Gaussian in world space to the camera. We use the reflect direction �� to query ASG, enabling better interpolation of latent features containing anisotropic information. Experimental results show that although this unsupervised normal estimation cannot generate physically accurate normals aligned with the real world, it is sufficient to produce relatively accurate reflect direction to assist ASG in fitting high-frequency information.
其中 ��=−𝐝 是从世界空间中的每个3D高斯指向相机的单位视图方向。我们使用反射方向 �� 来查询ASG,从而能够更好地插值包含各向异性信息的潜在特征。实验结果表明,虽然这种无监督的法线估计不能产生物理上准确的法线对齐的真实的世界,它是足够的产生相对准确的反射方向,以协助ASG在拟合高频信息。
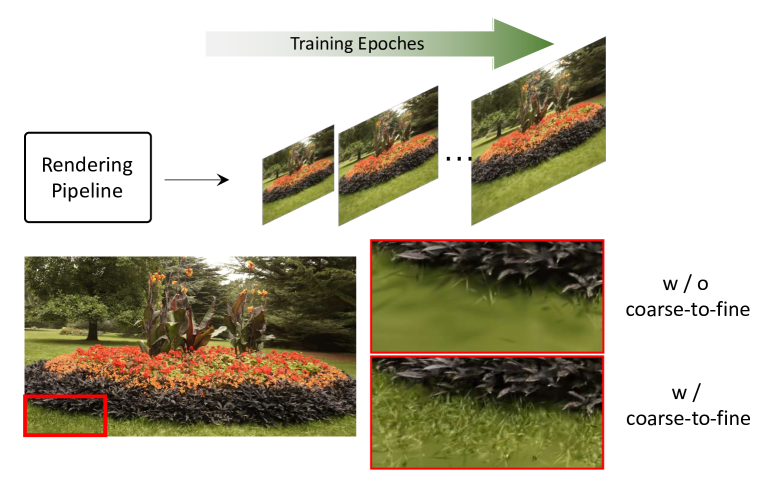
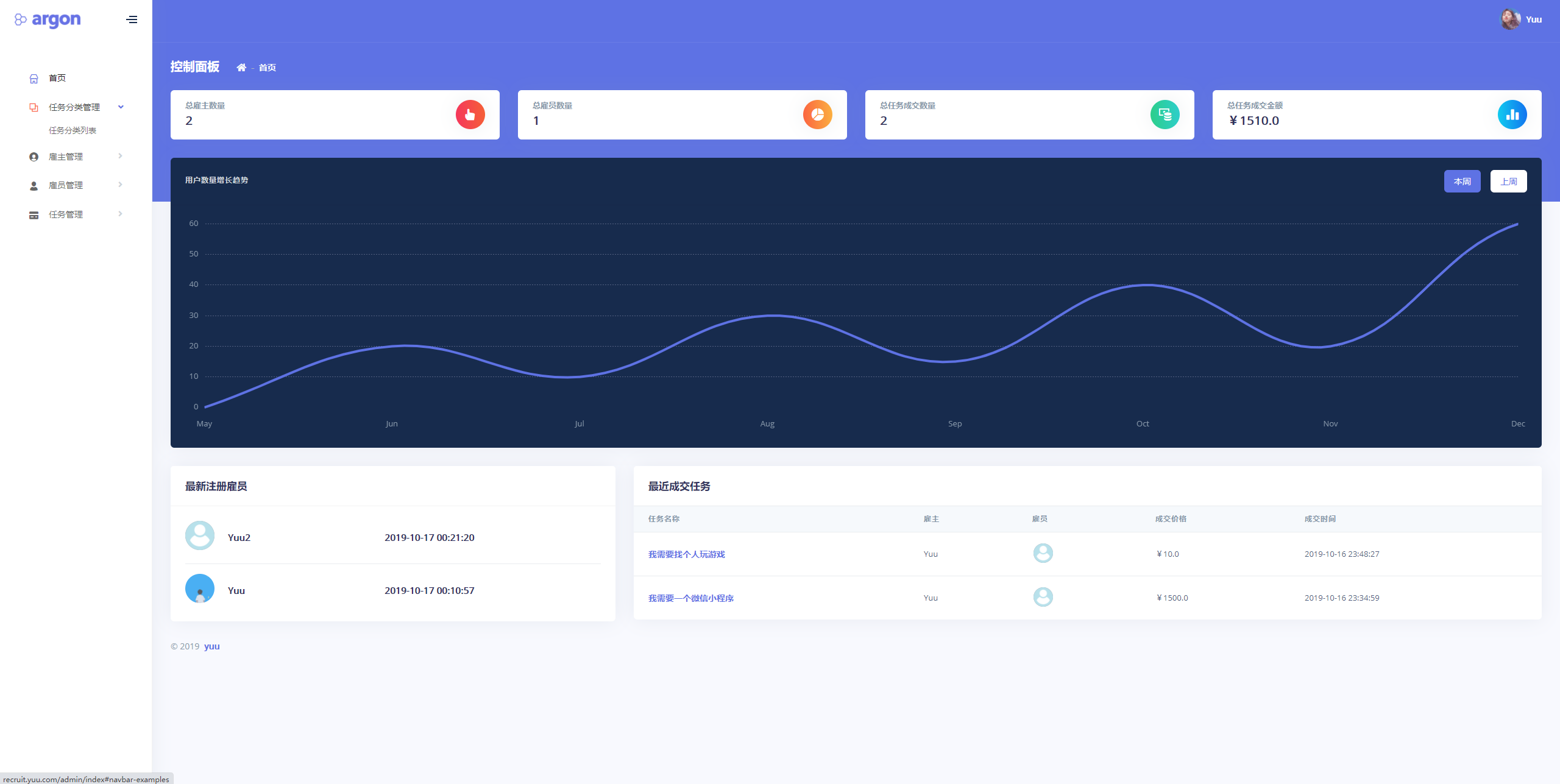
Figure 3:Using a coarse-to-fine strategy, our approach is able to optimize the scene in a progressive manner and eliminate the floaters efficiently.
图3:使用从粗到精的策略,我们的方法能够以渐进的方式优化场景,并有效地消除漂浮物。
3.3Anchor-Based Gaussian Splatting
3.3基于锚点的高斯溅射
3.3.1Neural Gaussian Derivation with ASG Appearance Field.
3.3.1具有ASG外观场的神经高斯推导。
While the ASG appearance field significantly improves the ability of 3D-GS to model specular and anisotropic features, it introduces additional storage and computational overhead compared to using pure SH due to the additional local features 𝐟 associated with each Gaussian. Although real-time rendering at over 100 FPS is still achievable in bounded scenes, the substantial increase in storage overhead and reduction in rendering speed caused by ASG in real-world unbounded scenes is unacceptable. Inspired by [30], we employ anchor-based Gaussian splatting to reduce storage overhead and the number of 3D Gaussians required for rendering, thereby accelerating the rendering.
虽然ASG外观场显著提高了3D-GS对镜面反射和各向异性特征进行建模的能力,但与使用纯SH相比,由于与每个高斯相关联的附加局部特征 𝐟 ,它引入了额外的存储和计算开销。虽然在有界场景中仍然可以实现超过100 FPS的实时渲染,但在现实世界的无界场景中,ASG导致的存储开销的大幅增加和渲染速度的降低是不可接受的。受[30]的启发,我们采用基于锚点的高斯溅射来减少存储开销和渲染所需的3D高斯数,从而加速渲染。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Tri-MipRF | 3D-GS | Scaffold-GS | GS-Shader | Ours | GT |











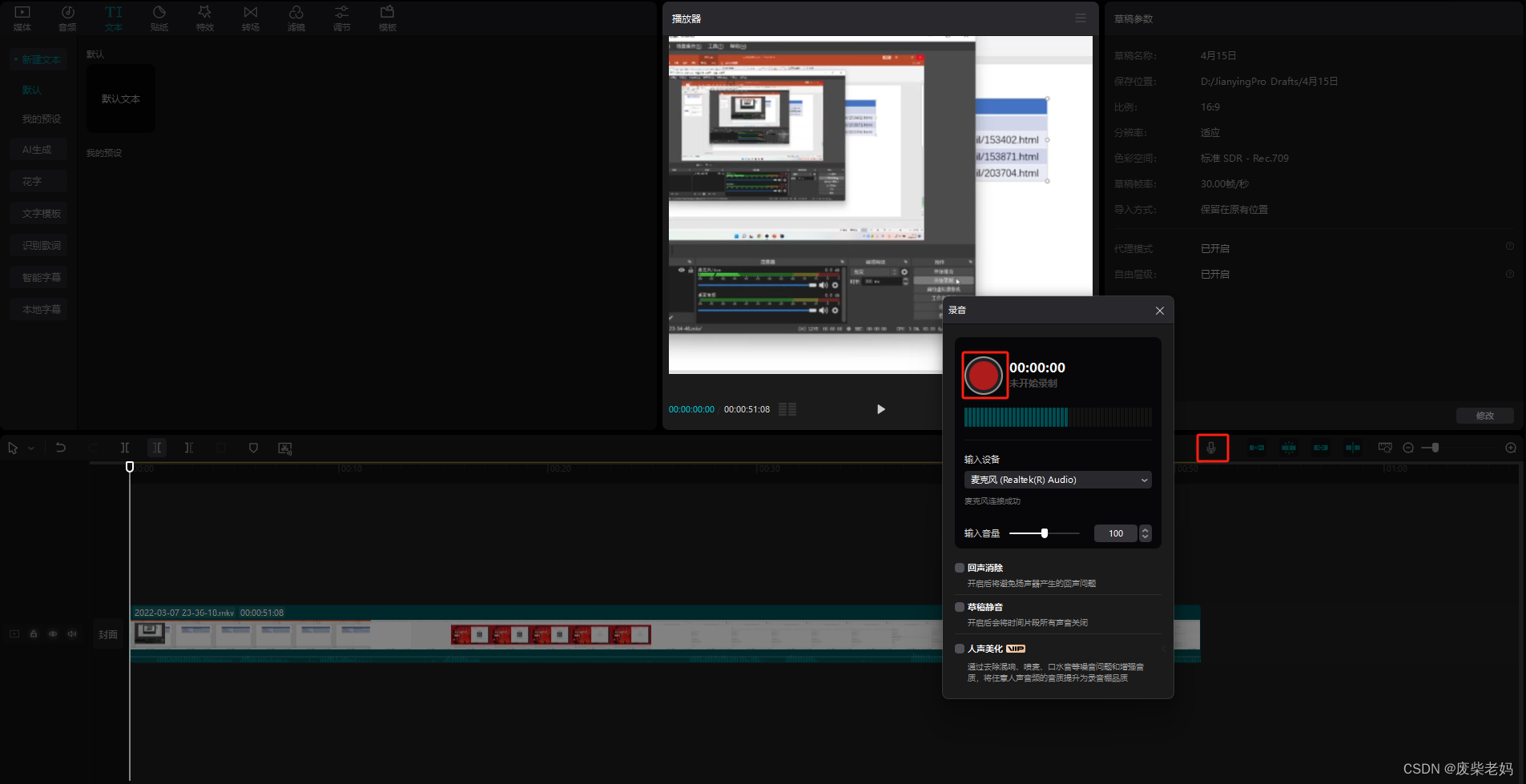
Figure 4:Visualization on NeRF dataset. Our method has successfully achieved local specular highlights modeling, a capability that other 3D-GS-based methods fail to accomplish, while maintaining fast rendering speed. Compared to Tri-MipRF, a NeRF-based method, we have significantly enhanced the ability to model anisotropic materials.
图4:NeRF数据集上的可视化。我们的方法已经成功地实现了局部镜面高光建模,其他基于3D—GS的方法无法实现的能力,同时保持快速渲染速度。与基于NeRF的方法Tri—MipRF相比,我们显着增强了对各向异性材料建模的能力。
Unlike the attributes carried by each entity in 3D-GS, each anchor Gaussian carries a position coordinate 𝐏�∈ℝ3, a local feature 𝐟�∈ℝ32, a displacement factor ��∈ℝ3, and � learnable offsets 𝐎�∈ℝ�×3. We use the sparse point cloud obtained from COLMAP [40] to initialize each anchor 3D Gaussian, serving as the voxel centers to guide the generation of neural Gaussians. The position 𝐏� of the anchor Gaussian is initialized as:
与3D-GS中的每个实体携带的属性不同,每个锚高斯携带位置坐标 𝐏�∈ℝ3 、局部特征 𝐟�∈ℝ32 、位移因子 ��∈ℝ3 和可学习偏移 � 。我们使用从COLMAP [40]获得的稀疏点云来初始化每个锚3D高斯,作为体素中心来指导神经高斯的生成。锚高斯的位置 𝐏� 被初始化为:
| 𝐏�={⌊𝐏�+0.5⌋}⋅�, | (9) |
where 𝐏 is the position of point cloud, � denotes the voxel size, and {⋅} denotes removing duplicated anchors.
其中 𝐏 是点云的位置, � 表示体素大小,并且 {⋅} 表示移除重复的锚点。
We then use the anchor Gaussians to guide the generation of neural Gaussians, which have the same attributes as vanilla 3D-GS. For each visible anchor Gaussian within the viewing frustum, we spawn � neural Gaussians and predict their attributes (see Fig. 2). The positions 𝐱 of neural Gaussians are calculated as:
然后,我们使用锚高斯来指导神经高斯的生成,其具有与vanilla 3D-GS相同的属性。对于视锥体内的每个可见锚高斯,我们生成 � 神经高斯并预测其属性(见图2)。神经高斯的位置 𝐱 计算为:
| {𝐱0,…,𝐱�−1}=𝐏�+{𝐎0,…,𝐎�−1}⋅��, | (10) |
where 𝐏� represents the position of the anchor Gaussian corresponding to � neural Gaussians. The opacity � is calculated through a tiny MLP:
其中 𝐏� 表示对应于 � 神经高斯的锚高斯的位置。不透明度 � 是通过一个微小的MLP计算的:
| {�0,…,��−1}=ℱ�(𝐟�,���,𝐝��), | (11) |
where ��� denotes the distance between the anchor Gaussian and the camera, and 𝐝�� is the unit direction pointing from the camera to the anchor Gaussian. The rotation � and scaling � of each neural Gaussian are derived similarly using the corresponding tiny MLP ℱ� and ℱ�.
其中, ��� 表示锚高斯与相机之间的距离,并且 𝐝�� 是从相机指向锚高斯的单位方向。每个神经高斯的旋转 � 和缩放 � 使用对应的微小MLP ℱ� 和 ℱ� 类似地导出。
Since the anisotropy modeled by ASG is continuous in space, it can be compressed into a lower-dimensional space. Thanks to the guidance of the anchor Gaussian, the anchor feature 𝐟� can be used directly to compress � ASGs, further reducing storage pressure. To make the ASG of neural Gaussians position-aware, we introduce the unit view direction to decompress ASG parameters. Consequently, the ASG parameters prediction in Eq. (5) is revised as follows:
由于ASG所模拟的各向异性在空间上是连续的,因此可以将其压缩到低维空间中。由于锚高斯的引导,锚特征 𝐟� 可以直接用于压缩 � ASG,进一步降低存储压力。为了使神经高斯ASG的位置感知,我们引入了单位视图方向的ASG参数。因此,方程中的ASG参数预测。(5)修订如下:
| Θ(𝐟�,𝐝��)→{�,�,�}�, | (12) |
where 𝐝�� denotes the unit view direction from the camera to each neural Gaussian. Additionally, we set the diffuse part of the neural Gaussian ��=�(𝐟�), directly predicted through an MLP �, to ensure the smoothness of the diffuse component and reduce the difficulty of convergence.
其中 𝐝�� 表示从相机到每个神经高斯的单位视角方向。此外,我们设置了神经高斯 ��=�(𝐟�) 的漫射部分,直接通过MLP � 预测,以确保漫射分量的平滑性并降低收敛难度。
3.3.2Adaptive Control of Anchor Gaussians.
3.3.2锚高斯自适应控制。
To enable 3D-GS to represent scene details while removing redundant entities, we adaptively adjust the number of anchor Gaussians based on the gradient and opacity of the neural Gaussians. Following [21, 30], we compute the averaged gradients of the � spawned neural Gaussians every 100 training iterations for each anchor Gaussian, denoted as ∇�. Anchor Gaussians with ∇�>�� will be densified. In practice, we follow [30] to quantize the space into multi-resolution voxels to allow new anchor Gaussians to be added at different granularities:
为了使3D-GS能够在去除冗余实体的同时表示场景细节,我们根据神经高斯的梯度和不透明度自适应地调整锚高斯的数量。在[21,30]之后,我们每100次训练迭代计算每个锚高斯的 � 产生的神经高斯的平均梯度,表示为 ∇� 。将使用 ∇�>�� 对锚高斯进行加密。在实践中,我们遵循[30]将空间转换为多分辨率体素,以允许以不同粒度添加新的锚高斯:
| �(�)=�⋅�/4�,��(�)=��⋅2�, | (13) |
where � denotes the level of new anchor Gaussians, �(�) is the voxel size at the �-th level for newly grown anchor Gaussians, and � represents a growth factor. Different from [30], to reduce overfitting caused by excessive densification of anchors, we introduced a hierarchical selection. Only anchor Gaussians with ∇�>Quantile(∇�,2−(�+1)) will be densified at the corresponding voxel center at the �-th level.
其中 � 表示新的锚高斯的级别, �(�) 是新生长的锚高斯的第 � 级别处的体素大小,并且 � 表示生长因子。与[30]不同,为了减少锚点过度致密化导致的过拟合,我们引入了分层选择。只有具有 ∇�>Quantile(∇�,2−(�+1)) 的锚高斯将在第5 #级的相应体素中心处被加密。
To eliminate trivial anchors, we accumulate the opacity values of their associated neural Gaussians for every 100 training iteration, denoted as �¯. If an anchor Gaussian fails to produce neural Gaussians with a satisfactory level of opacity, with �¯<��, we remove it.
为了消除琐碎的锚点,我们为每100次训练迭代累积其相关神经高斯的不透明度值,表示为 �¯ 。如果一个锚高斯无法产生具有令人满意的不透明度水平的神经高斯,则使用 �¯<�� ,我们将其删除。
| Dataset | Mip-NeRF360 | Tanks&Temples 坦克和寺庙 | Deep Blending 深度交融 | ||||||||||||
| Method — Metrics 方法-- | PSNR ↑ PSNR ↑ 的问题 | SSIM ↑ 阿信 ↑ | LPIPS ↓ LPIPPS ↓ 的问题 | FPS | Mem | PSNR ↑ PSNR ↑ 的问题 | SSIM ↑ 阿信 ↑ | LPIPS ↓ LPIPPS ↓ 的问题 | FPS | Mem | PSNR ↑ PSNR ↑ 的问题 | SSIM ↑ 阿信 ↑ | LPIPS ↓ LPIPPS ↓ 的问题 | FPS | Mem |
| Mip-NeRF360 | 27.69 | 0.792 | 0.237 | 0.06 | 8.6MB | 22.22 | 0.759 | 0.257 | 0.14 | 8.6MB | 29.40 | 0.901 | 0.245 | 0.09 | 8.6MB |
| iNGP | 25.59 | 0.699 | 0.331 | 9.43 | 48MB | 21.72 | 0.723 | 0.330 | 14.4 | 48MB | 23.62 | 0.797 | 0.423 | 2.79 | 48MB |
| Plenoxels | 23.08 | 0.626 | 0.463 | 6.79 | 2.1GB | 21.08 | 0.719 | 0.379 | 13.0 | 2.3GB | 23.06 | 0.795 | 0.510 | 11.2 | 2.7GB |
| 3D-GS | 27.47 | 0.812 | 0.222 | 115 | 748MB | 23.71 | 0.844 | 0.178 | 169 | 432MB | 29.65 | 0.899 | 0.247 | 130 | 662MB |
| Scaffold-GS | 27.66 | 0.807 | 0.236 | 96 | 203MB | 23.96 | 0.853 | 0.177 | 143 | 89.5MB | 30.21 | 0.906 | 0.254 | 179 | 63.5MB |
| Ours-w/o anchor 我们的—不带锚 | 27.81 | 0.810 | 0.223 | 25 | 1.02GB | 23.94 | 0.846 | 0.181 | 37 | 563MB | 29.71 | 0.901 | 0.250 | 32 | 793MB |
| Ours | 28.01 | 0.812 | 0.222 | 70 | 245MB | 24.58 | 0.855 | 0.174 | 111 | 96.5MB | 30.45 | 0.906 | 0.252 | 132 | 68MB |
Table 1:Quantitative evaluation of our method compared to previous work on real-world datasets. We report PSNR, SSIM, LPIPS(VGG) and color each cell as best, second best and third best. Our method has overall achieved the best rendering quality, while also striking a good balance between FPS and the storage memory of 3D Gaussians.
表1:我们的方法与以前在真实世界数据集上的工作相比的定量评估。我们报告PSNR,SSIM,LPIPS(VGG)和颜色每个细胞为最好的,第二好的和第三好的。我们的方法总体上达到了最好的渲染质量,同时也在FPS和3D高斯的存储内存之间取得了很好的平衡。
3.4Coarse-to-fine Training
3.4由粗到精的培训
We observed that in many real-world scenarios, 3D-GS tends to overfit the training data, leading to the emergence of numerous floaters when rendering images from novel viewpoints. A common challenge in real-world datasets is inaccuracies in camera pose estimation, particularly evident in large scenes. Scaffold-GS [30], by anchoring 3D-GS, imposes a sparse voxel constraint on the geometry, creating a hierarchical 3D-GS representation. While this hierarchical approach improves the ability of 3D-GS to model complex geometries, it does not address the overfitting issue and, in many cases, exacerbates the presence of floaters in scene backgrounds.
我们观察到,在许多现实场景中,3D-GS往往会过度拟合训练数据,导致从新视点渲染图像时出现大量浮动。现实世界数据集中的一个常见挑战是相机姿态估计的不准确性,在大型场景中尤其明显。Scaffold-GS [30]通过锚定3D-GS,对几何结构施加稀疏体素约束,创建分层3D-GS表示。虽然这种分层方法提高了3D-GS对复杂几何体建模的能力,但它并没有解决过拟合问题,并且在许多情况下,加剧了场景背景中漂浮物的存在。
To mitigate the occurrence of floaters in real-world scenes, we propose a coarse-to-fine training mechanism. We believe that the tendency of 3D-GS to overfit stems from an excessive focus on each 3D Gaussian’s contribution to a specific pixel and its immediate neighbors, rather than considering broader global information. Therefore, we decide to train 3D-GS progressively from low to high resolution:
为了减少真实场景中漂浮物的发生,我们提出了一种由粗到细的训练机制。我们认为,3D-GS过度拟合的趋势源于过度关注每个3D高斯对特定像素及其近邻的贡献,而不是考虑更广泛的全局信息。因此,我们决定从低分辨率到高分辨率逐步训练3D-GS:
| �(�)=min(⌊��+(��−��)⋅�/�⌉,��), | (14) |
where �(�) is the image resolution at the �-th training iteration, �� is the starting image resolution, �� is the ending image resolution (the full resolution we aim to render), and � is the threshold iteration, empirically set to 20k.
其中 �(�) 是第#1次训练迭代时的图像分辨率, �� 是起始图像分辨率, �� 是结束图像分辨率(我们旨在渲染的全分辨率), � 是阈值迭代,根据经验设置为20 k。
This training approach enables 3D-GS to learn global information from the images in the early stages of training, thereby reducing overfitting to local areas of the training images and eliminating a significant number of floaters in novel view rendering. Additionally, due to the lower resolution training in the initial phase, this mechanism reduces training time by approximately 20%.
这种训练方法使3D-GS能够在训练的早期阶段从图像中学习全局信息,从而减少对训练图像的局部区域的过拟合,并消除新视图渲染中的大量漂浮物。此外,由于初始阶段的训练分辨率较低,该机制将训练时间减少了约20%。
3.5Losses
In addition to the color loss in 3D-GS [21], we also incorporate a regularization loss to encourage the neural Gaussians to remain small and minimally overlapping. Consequently, the total loss function for all learnable parameters and MLPs is formulated as:
除了3D-GS [21]中的颜色损失之外,我们还引入了正则化损失,以鼓励神经高斯保持较小和最小重叠。因此,所有可学习参数和MLP的总损失函数被公式化为:
| ℒ=(1−�D-SSIM)ℒ1 | +�D-SSIMℒD-SSIM+�regℒreg, | (15) | ||
| ℒreg | =1�∑�=1�nProd(��), |
where �� is the number of neural Gaussians and Prod(⋅) calculates the product of the scale �� of each neural Gaussian. The �D-SSIM=0.2 and �reg=0.01 are consistently used in our experiments.
其中 �� 是神经高斯的数量, Prod(⋅) 计算每个神经高斯的尺度 �� 的乘积。 �D-SSIM=0.2 和 �reg=0.01 在我们的实验中一直使用。
| Dataset | NeRF Synthetic NeRF合成 | ||||
| Method — Metrics 方法-- | PSNR ↑ PSNR ↑ 的问题 | SSIM ↑ 阿信 ↑ | LPIPS ↓ LPIPPS ↓ 的问题 | FPS | Mem |
| iNGP-Base | 33.18 | 0.963 | 0.045 | ∼10 | ∼13MB ∼ 13MB |
| Mip-NeRF | 33.09 | 0.961 | 0.043 | ¡1 | ∼10MB |
| Tri-MipRF | 33.65 | 0.963 | 0.042 | ∼5 | ∼60MB ∼ 60MB |
| 3D-GS | 33.32 | 0.970 | 0.031 | 415 | 69MB |
| GS-Shader | 33.38 | 0.968 | 0.029 | 97 | 29MB |
| Scaffold-GS | 33.68 | 0.967 | 0.034 | 240 | 19MB |
| Ours-w anchor 我们的-W锚 | 33.96 | 0.969 | 0.032 | 162 | 20MB |
| Ours | 34.12 | 0.971 | 0.028 | 105 | 79MB |
Table 2:Quantitative results on NeRF synthetic dataset. Our method achieves a rendering quality that surpasses NeRF-based methods, without excessively reducing FPS.
表2:NeRF合成数据集的定量结果。我们的方法实现了渲染质量,超越NeRF为基础的方法,而不会过度降低FPS。
4Experiments 4实验
In this section, we present both quantitative and qualitative results of our method. To evaluate its effectiveness, we compared it to several state-of-the-art methods across various datasets. We color each cell as best, second best and third best. Our method demonstrates superior performance in modeling complex specular and anisotropic features, as evidenced by comparisons on the NeRF, NSVF, and our ”Anisotropic Synthetic” datasets. Additionally, we showcase its versatility by comparing its performance across all scenarios in 3D-GS, further proving the robustness of our approach.
在本节中,我们提出了我们的方法的定量和定性结果。为了评估其有效性,我们将其与各种数据集上的几种最先进的方法进行了比较。我们将每个单元格着色为最佳、第二佳和第三佳。我们的方法在模拟复杂的镜面反射和各向异性特征方面表现出上级性能,这一点在NeRF,NSVF和我们的“各向异性合成”数据集上进行了比较。此外,我们通过比较3D-GS中所有场景的性能来展示其多功能性,进一步证明了我们方法的鲁棒性。
| Dataset | NSVF Synthetic NSVF合成 | ||||
| Method — Metrics 方法-- | PSNR ↑ PSNR ↑ 的问题 | SSIM ↑ 阿信 ↑ | LPIPS ↓ LPIPPS ↓ 的问题 | FPS | Mem |
| TensoRF | 36.52 | 0.982 | 0.026 | ∼1.5 | ∼65MB ∼ 65MB |
| Tri-MipRF | 34.58 | 0.973 | 0.030 | ∼5 | ∼60MB ∼ 60MB |
| NeuRBF | 37.80 | 0.986 | 0.019 | ∼1 | ∼580MB ∼ 580MB |
| 3D-GS | 37.07 | 0.987 | 0.015 | 403 | 66MB |
| GS-Shader | 33.85 | 0.981 | 0.020 | 68 | 33MB |
| Scaffold-GS | 36.43 | 0.984 | 0.017 | 218 | 17MB |
| Ours-w anchor 我们的-W锚 | 37.71 | 0.987 | 0.015 | 142 | 18MB |
| Ours | 38.35 | 0.988 | 0.013 | 91 | 99MB |
Table 3:Quantitative results on NSVF synthetic dataset. Our method achieved significantly higher rendering quality than 3D-GS, and it also surpassed NeRF-based methods.
表3:NSVF合成数据集的定量结果。我们的方法实现了比3D-GS更高的渲染质量,也超过了基于NeRF的方法。
4.1Implementation Details
4.1实现细节
We implemented our framework using PyTorch [37] and modified the differentiable Gaussian rasterization to include depth visualization. For the ASG appearance field, the feature decoupling MLP Ψ consists of 3 layers, each with 64 hidden units, and the positional encoding for the view direction is of order 2. In terms of anchor-based Gaussian splatting, we established three levels for anchor Gaussian densification, setting the densification threshold �� to 0.0002, the pruning threshold �� to 0.005, and the number of neural Gaussians of each anchor � to 10. In bounded scenes, our voxel size � is set to 0.001 with a growth factor � of 4. For the Mip-360 scenes, the voxel size remains 0.001, but the growth factor � is increased to 16. Regarding coarse-to-fine training, we start with a resolution �� that is 8x downsampled. To further accelerate rendering speed, we prefilter the visible anchor Gaussians and allow only those neural Gaussians with opacity ��>0 to pass through the ASG appearance field and Gaussian rasterization pipelines. All experiments were conducted on a Tesla V100, and FPS measurements were performed on an NVIDIA RTX 3090 with 24GB of memory.
我们使用PyTorch [37]实现了我们的框架,并修改了可微高斯光栅化以包括深度可视化。对于ASG外观场,特征解耦MLP Ψ 由3个层组成,每个层具有64个隐藏单元,并且用于视图方向的位置编码是2阶的。在基于锚点的高斯溅射方面,我们为锚点高斯致密化建立了三个级别,将致密化阈值 �� 设置为0.0002,修剪阈值 �� 设置为0.005,每个锚点的神经高斯数 � 设置为10。在有界场景中,我们的体素大小 � 设置为0.001,增长因子 � 为4。对于Mip—360场景,体素大小保持0.001,但增长因子 � 增加到16。关于从粗到精的训练,我们从分辨率 �� 开始,即8倍下采样。 为了进一步加快渲染速度,我们对可见的锚高斯进行预过滤,只允许那些不透明度为 ��>0 的神经高斯通过ASG外观场和高斯光栅化管道。所有实验均在Tesla V100上进行,FPS测量在具有24 GB内存的NVIDIA RTX 3090上进行。
| Dataset | Anisotropic Synthetic 各向异性合成 | ||||
|---|---|---|---|---|---|
| Method — Metrics 方法-- | PSNR ↑ PSNR ↑ 的问题 | SSIM ↑ 阿信 ↑ | LPIPS ↓ LPIPPS ↓ 的问题 | FPS | Mem |
| 3D-GS | 33.82 | 0.966 | 0.062 | 345 | 47MB |
| Scaffold-GS | 35.34 | 0.972 | 0.052 | 234 | 27MB |
| Ours-w anchor 我们的-W锚 | 36.76 | 0.976 | 0.046 | 180 | 28MB |
| Ours | 37.42 | 0.977 | 0.047 | 119 | 59MB |
Table 4:Quantitative results on our ”Anisotropic Synthetic” dataset.
表4:我们的“各向异性合成”数据集的定量结果。
|
|
|
|
|
| Scaffold-GS | ASG color | Ours | GT |

Figure 5:Ablation on ASG feature decoupling MLP. We show that directly using ASG to model color leads to the failure in modeling anisotropy and specular highlights. By decoupling the ASG features through MLP, we can realistically model complex optical phenomena.
图5:ASG消融功能解耦MLP。我们发现,直接使用ASG模型的颜色导致建模各向异性和镜面高光失败。通过MLP解耦ASG特征,我们可以逼真地模拟复杂的光学现象。
4.2Results and Comparisons
4.2结果和比较
Synthetic Bounded Scenes.
合成有界场景。
We used the NeRF, NSVF, and our ”Anisotropic Synthetic” datasets as the experimental datasets for synthetic scenes. Our comparisons were made with the most relevant state-of-the-art methods, including 3D-GS [21], Scaffold-GS [30], GaussianShader [20], and several NeRF-based methods such as NSVF [28], TensoRF [6], NeuRBF [9], and Tri-MipRF [17]. To ensure a fair comparison, we used the rendering metrics of the NeRF and NSVF datasets as reported in the baseline papers. For scenes not reported in the baseline papers, we trained the baselines from scratch using the released codes and their default configurations.
我们使用NeRF,NSVF和我们的“各向异性合成”数据集作为合成场景的实验数据集。我们与最相关的最先进的方法进行了比较,包括3D-GS [21],Scaffold-GS [30],GaussianShader [20]和几种基于NeRF的方法,如NSVF [28],TensoRF [6],NeuRBF [9]和Tri-MipRF [17]。为了确保公平的比较,我们使用了基线论文中报告的NeRF和NSVF数据集的渲染指标。对于基线论文中没有报告的场景,我们使用发布的代码及其默认配置从头开始训练基线。
As shown in Fig. 4, Figs. 7-8. and Tabs. 2-4, our method achieved the highest performance in terms of PSNR, SSIM, and LPIPS. It also significantly improved upon the issues that 3D-GS faced in modeling high-frequency specular highlights and complex anisotropy. See per-scene results in the supplementary materials.
如图4所示,图1和图2示出了一个实施例。7-8.和Tabs。2-4,我们的方法在PSNR、SSIM和LPIPS方面实现了最高性能。它还显著改善了3D-GS在建模高频镜面高光和复杂各向异性时面临的问题。请参见补充材质中的每个场景结果。
Real-world Unbounded Scenes.
真实世界的无限场景。
To verify the versatility of our method in real-world scenarios, we used the same real-world dataset as in 3D-GS [21]. As shown in Tab. 1, our method achieves rendering results comparable to state-of-the-art methods on the Deep Blending dataset and surpasses them on Mip-NeRF 360 and Tanks&Temples. Furthermore, our method effectively balances FPS, storage overhead, and rendering quality. It enhances rendering quality without excessively increasing storage requirements or significantly reducing FPS. As illustrated in Fig. 6, our method has also significantly improved the visual effect. It removes a large number of floaters in outdoor scenes and successfully models the high-frequency specular highlights in indoor scenes. This demonstrates that our approach is not only adept at modeling complex specular scenes but also effectively improves rendering quality in general scenarios.
为了验证我们的方法在现实世界场景中的多功能性,我们使用了与3D-GS相同的现实世界数据集[21]。如Tab中所示。1,我们的方法在Deep Blending数据集上实现了与最先进方法相当的渲染结果,并在Mip-NeRF 360和Tanks&Temples上超过了它们。此外,我们的方法有效地平衡FPS,存储开销和渲染质量。它提高了渲染质量,而不会过度增加存储需求或显着降低FPS。如图6所示,我们的方法也显著改善了视觉效果。它去除了室外场景中大量的漂浮物,并成功地模拟了室内场景中的高频镜面高光。这表明,我们的方法不仅是善于建模复杂的镜面场景,但也有效地提高了渲染质量,在一般情况下。
4.3Ablation Study 4.3消融研究
4.3.1ASG feature decoupling MLP
4.3.1 ASG特征解耦MLP
We conducted an ablation study to evaluate the effectiveness of using ASG to output features, which are then decoupled through an MLP Ψ to derive the final specular color. As demonstrated in Fig. 5, directly using ASG to output color results in the inability to model specular and anisotropic components. In contrast to directly using an MLP for color modeling, as in Scaffold-GS [30], ASG can encode higher-frequency anisotropic features. This capability aids the MLP in learning complex optical phenomena, leading to more accurate and detailed rendering results.
我们进行了一项消融研究,以评估使用ASG输出特征的有效性,然后通过MLP Ψ 解耦以获得最终的镜面反射颜色。如图5所示,直接使用ASG来输出颜色导致无法对镜面反射和各向异性分量进行建模。与直接使用MLP进行颜色建模相反,如Scaffold-GS [30],ASG可以编码更高频率的各向异性特征。这种能力有助于MLP学习复杂的光学现象,从而获得更准确和详细的渲染结果。
4.3.2Coarse-to-fine training
4.3.2由粗到精的培训
We conducted an ablation study to assess the impact of coarse-to-fine (c2f) training. As illustrated in Fig. 10, both 3D-GS and Scaffold-GS exhibit a large number of floaters in the novel view synthesis. Coarse-to-fine training effectively reduces the number of floaters, alleviating the overfitting issue commonly encountered by 3D-GS in real-world scenarios.
我们进行了一项消融研究,以评估粗到细(c2f)训练的影响。如图10所示,3D-GS和Scaffold-GS都在新视图合成中表现出大量的浮动点。从粗到精的训练有效地减少了漂浮物的数量,缓解了3D-GS在现实世界场景中经常遇到的过拟合问题。
5Conclusion 5结论
In this work, we introduce Spec-Gaussian, a novel approach to 3D Gaussian splitting that features an anisotropic view-dependent appearance. Leveraging the powerful capabilities of ASG, our method effectively overcomes the challenges encountered by vanilla 3D-GS in rendering scenes with specular highlights and anisotropy. Additionally, we innovatively implement a coarse-to-fine training mechanism to eliminate floaters in real-world scenes. Both quantitative and qualitative experiments demonstrate that our method not only equips 3D-GS with the ability to model specular highlights and anisotropy but also enhances the overall rendering quality of 3D-GS in general scenes, without significantly compromising FPS and storage overhead.
在这项工作中,我们介绍Spec-Gaussian,一种新的方法来3D高斯分裂,具有各向异性的视图相关的外观。利用ASG的强大功能,我们的方法有效地克服了香草3D-GS在渲染具有镜面高光和各向异性的场景时遇到的挑战。此外,我们创新性地实现了从粗到精的训练机制,以消除真实场景中的漂浮物。定量和定性的实验表明,我们的方法不仅配备了3D-GS与建模镜面高光和各向异性的能力,但也提高了3D-GS在一般场景的整体渲染质量,而不会显着损害FPS和存储开销。
Limitations 限制
Although our method enables 3D-GS to model complex specular and anisotropic features, it still faces challenges in handling reflections. Specular and anisotropic effects are primarily influenced by material properties, whereas reflections are closely related to the environment and geometry. Due to the lack of explicit geometry in 3D-GS, we cannot differentiate between reflections and material textures using constraints like normals, as employed in Ref-NeRF [45] and NeRO [29]. In our experiments, we also observed that when ground truth geometric information is provided, 3D-GS becomes more consistent with expectations under strict constraints, but this comes at the cost of a certain decline in rendering quality. We plan to explore solutions for modeling reflections with 3D-GS in future work.
尽管我们的方法使3D-GS能够对复杂的镜面反射和各向异性特征进行建模,但在处理反射方面仍然面临挑战。镜面反射和各向异性效果主要受材质属性的影响,而反射则与环境和几何体密切相关。由于3D-GS中缺乏显式几何结构,我们无法使用Ref-NeRF [45]和NeRO [29]中采用的法线等约束来区分反射和材质纹理。在我们的实验中,我们还观察到,当提供地面真实几何信息时,3D-GS在严格的约束下变得与预期更加一致,但这是以渲染质量下降为代价的。我们计划在未来的工作中探索使用3D-GS建模反射的解决方案。
References
- Barron et al. [2021] 巴伦等人[2021]↑Jonathan T. Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P. Srinivasan.Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields.ICCV, 2021.
乔纳森·T巴伦、本·米尔登霍尔、马修·坦西克、彼得·海德曼、里卡多·马丁-布鲁阿拉和普拉托·P·斯里尼瓦桑。Mip-nerf:抗混叠神经辐射场的多尺度表示。ICCV,2021年。 - Barron et al. [2022] 巴伦等人[2022]↑Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman.Mip-nerf 360: Unbounded anti-aliased neural radiance fields.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5470–5479, 2022.
乔纳森T巴伦,本Mildenhall,Dor Verbin,Pratul P Srinivasan,和彼得Hedman。Mip—nerf 360:未结合的抗锯齿神经辐射场。In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,第5470—5479页,2022年。 - Barron et al. [2023] 巴伦等人[2023]↑Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, and Peter Hedman.Zip-nerf: Anti-aliased grid-based neural radiance fields.ICCV, 2023.
乔纳森·T巴伦、本·米尔登霍尔、多尔·维宾、普拉图尔·斯里尼瓦桑和彼得·海德曼。Zip-nerf:基于网格的抗锯齿神经辐射场。ICCV,2023年。 - Botsch et al. [2005] Botsch等人[2005年]↑Mario Botsch, Alexander Hornung, Matthias Zwicker, and Leif Kobbelt.High-quality surface splatting on today’s gpus.In Proceedings Eurographics/IEEE VGTC Symposium Point-Based Graphics, 2005., pages 17–141. IEEE, 2005.
马里奥·博奇、亚历山大·霍农、马蒂亚斯·兹威克和莱夫·科贝尔特。高品质的表面飞溅在今天的gpu。在2005年欧洲图形/IEEE VGTC研讨会点基图形会议录中,第17-141页。IEEE,2005年。 - Chen et al. [2022a] Chen等人[2022 a]↑Anpei Chen, Zexiang Xu, Andreas Geiger, Jingyi Yu, and Hao Su.Tensorf: Tensorial radiance fields.In European Conference on Computer Vision (ECCV), 2022a.
Anpei Chen,Zexiang Xu,Andreas盖革,Jingyi Yu,Hao Su. Tensorf:张量辐射场。欧洲计算机视觉会议(ECCV),2022年。 - Chen et al. [2022b] Chen等人[2022 b]↑Anpei Chen, Zexiang Xu, Andreas Geiger, Jingyi Yu, and Hao Su.Tensorf: Tensorial radiance fields.In European Conference on Computer Vision, pages 333–350. Springer, 2022b.
Anpei Chen,Zexiang Xu,Andreas盖革,Jingyi Yu,Hao Su. Tensorf:张量辐射场。欧洲计算机视觉会议,第333-350页。斯普林格,2022 b。