01
引言
作为后端开发人员,对Redis肯定不陌生,它是一款基于内存的数据库,读写速度非常快。在爱奇艺海外后端的项目中,我们也广泛使用Redis,主要用于缓存、消息队列和分布式锁等场景。最近在对一个老项目使用的docker镜像版本升级过程中碰到一个奇怪的问题,发现项目升级到高版本镜像后,访问Redis会出现很多超时错误,而降回之前的镜像版本后问题也随之消失。经过排查,最终定位问题元凶是一个涉及到Lettuce、Redis、Netty等多块内容的代码bug。在问题解决过程中也对相关组件的工作方式有了更深一步的理解。以下就对“捉虫”过程中的问题分析和排查过程做一个详细的介绍。
02
背景
我们的技术栈是业界常见的Spring Cloud全家桶。有问题的项目是整个微服务架构中的一个子服务,主要负责为客户端提供包括节目详情、剧集列表和播放鉴权等内容相关的web服务。由于节目、剧集、演员等大部分领域实体变更频率不高,我们使用三主三从的Redis集群进行缓存,将数据分片管理,以便保存更多内容。
项目中访问Redis的方式主要有两种,一种是直接使用Spring框架封装的RedisTemplete对象进行访问,使用场景是对redis中的数据进行手动操作。另外一种方式是通过自研的缓存框架间接访问,框架内部会对缓存内容进行管理,主要包含二级缓存,热key统计,缓存预热等高级功能。
通过RedisTemplete访问:

通过自研缓存框架访问。如下图,加上@CreateCache注解的对象被声明为缓存容器,在项目启动时框架会利用Redis的发布订阅机制,自动将远端Redis二级缓存中的热点数据同步到本地。并支持配置数据缓存的有效期、本地缓存数量等属性。另外框架本身也提供了读写接口供使用方访问缓存数据。

03
问题现象
升级了镜像版本后,应用正常启动后会出现大量访问Redis超时错误。在观察了CPU、内存和垃圾回收等方面的常规监控后,并没有发现明显异常。只是在项目启动初期会有较多的网络数据写入。这实际上是之前提到的缓存预热逻辑,因此也在预期之内。
由于项目本身存在两种访问方式,不同环境下Redis服务器架构也不同,为了固定问题场景,我们进行了一番条件测试,发现了一些端倪:
低版本镜像上RedisTemplete和缓存框架访问Redis集群均正常。
高版本镜像上RedisTemplete访问Redis集群正常,缓存框架访问Redis集群超时。项目启动一段时间后框架访问恢复正常。
低版本和高版本镜像中RedisTemplete和缓存框架访问Redis单机均正常
根据以上现象不难推断出,问题应似乎出现在缓存框架访问Redis集群的机制上。结合项目启动一段时间后会恢复正常的特点,猜测应该和缓存预热流程有关。
04
排查过程
复现case
查阅代码后发现自研的缓存框架没有通过Spring访问Redis,而是直接使用了Sping底层的Redis客户端—— Lettuce。剔除了无关的业务代码后,我们得到了一个可以复现问题的最小case,代码如下:


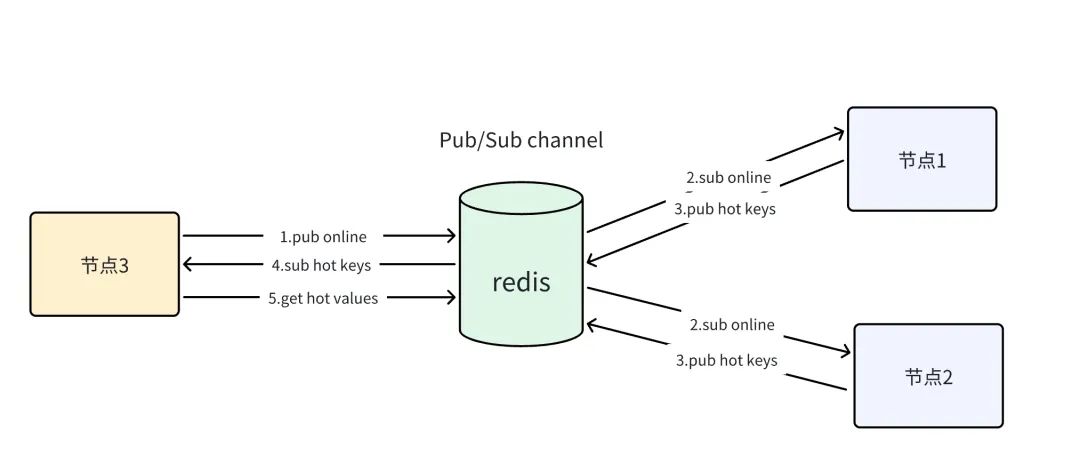
整个case模拟的就是缓存的预热场景,主要运行流程如下:
服务(节点3)启动后发送新节点上线的ONLINE消息
其他节点(节点1,2)收到ONLINE消息后,将本地缓存的热key打包
其他节点(节点1,2)发送包含本机热key的HOTKEY消息
新节点(节点3)收到包含热key的HOTKEY消息
新节点(节点3)根据收到的热key反查redis获取value值,并缓存到本地
在根据热key反查Redis的方法中也加了日志,以显示反查操作的执行时间(省略部分无关代码)。

运行上述代码后,我们看看控制台实际的输出结果:

可以看到,应用在启动后正常收到了Redis的HOTKEY消息并执行反查操作。然而,大量的反查请求在1秒后仍未获取到结果。而源码中请求future的超时时间设置也是1秒,即大量的Redis get请求都超时了。
一般情况下请求超时的原因有两个,要么是请求没有到达服务端,要么是响应没有回到客户端。为了定位原因,我们在应用宿主机上查看与Redis集群连接的通信情况,如下:

结果发现,本机与redis集群的3个分片共建立了6个连接,其中一个tcp连接的接收队列内容一直不为空,这说明该连接的响应数据已经到达本机socket缓冲区,只不过由于某种原因客户端程序没有消费。作为对比我们在低版本镜像上启动后同样观察连接情况,发现不存在数据积压的情况。

排查至此我们发现缓冲区的数据积压很可能就是造成反查请求超时的原因,明白了这一点后,我们开始思考:
连接缓冲区中的数据应该由谁来消费?
每个连接的作用是什么?
为什么只有一个连接出现了数据积压情况?
为什么积压情况只在高版本的镜像中出现?
为什么通过Spring访问Redis就不会出现超时问题?
深度分析
要回答以上问题,首先要了解Lettuce的工作原理,重点是其底层是如何访问Redis集群的。

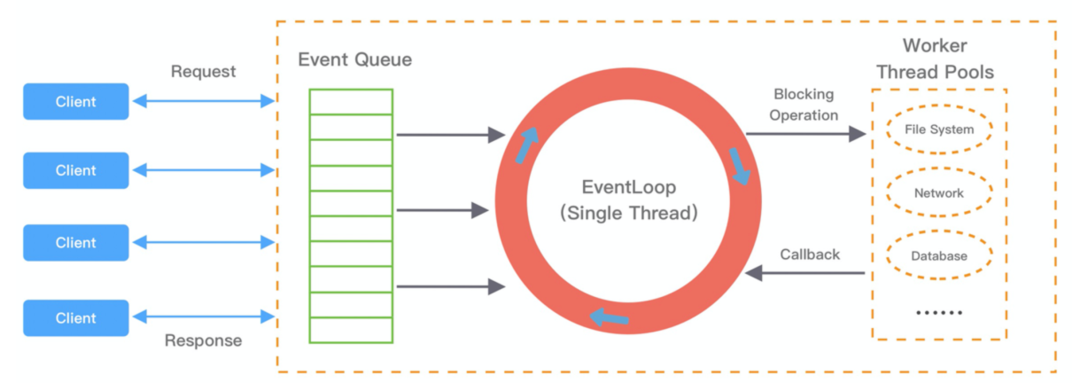
根据官网介绍,Lettuce 底层基于 Netty 的NIO模型实现,只用有限的线程支持更多的 Redis 连接,在高负载情况下能更有效地利用系统资源。
我们简要回顾一下Netty的工作机制。Netty中所有I/O操作和事件是由其内部的核心组件EventLoop负责处理的。Netty启动时会根据配置创建多个EventLoop对象,每个Netty连接会被注册到一个EventLoop上,同一个EventLoop可以管理多个连接。而每个EventLoop内部都包含一个工作线程、一个Selector选择器以及一个任务队列。
当客户端执行连接建立或注册等操作时,这些动作都会以任务的形式提交到关联EventLoop的任务队列中。每当连接上发生I/O事件或者任务队列不为空时,其内部的工作线程(单线程)会轮询地从队列中取出事件执行,或者将事件分发给相应的事件监听者执行。
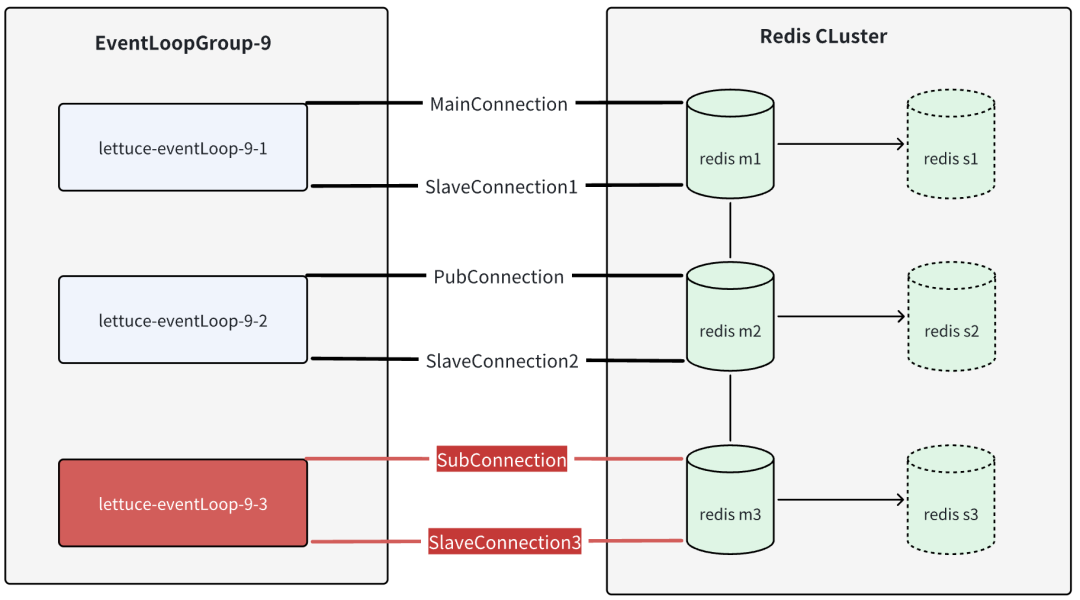
在Lettuce框架中,与Redis集群的交互由内部的RedisClusterClient对象处理。项目启动时,RedisClusterClient会根据配置获取所有主从节点信息,并尝试连接每个节点以获取节点metadata数据,然后释放连接完成初始化。随后,RedisClusterClient会按需连接各个节点。RedisClusterClient的连接分为主连接和副连接两种。由客户端显示创建的连接是主连接,用于执行无需路由的命令,如auth/select等。而由client内部根据路由规则隐式创建的连接是副连接,用于执行需要根据slot路由的命令,例如常见的get/set操作。对于Pub/Sub发布订阅机制,为了确保订阅者可以实时接收到发布者发布的消息,Lettuce会单独维护一个专用于事件监听的连接。
所以我们之前观察到的6个TCP连接,实际上包含了1个集群主连接、3个副连接、1个用于事件发布的pub连接(由TestService声明的statefulRedisPubSubConnection)以及1个用于订阅的sub连接。所有这些连接都会被注册到Netty的EventLoop上进行管理。

EventLoop机制的核心功能是多路复用,这意味着一个线程可以处理多个连接的读写事件。但是要实现这一点的前提是EventLoop线程不能被阻塞,否则注册在该线程上的各个连接的事件将得不到响应。由此我们可以推测,如果socket缓冲区出现积压,可能是某些原因导致socket连接对应的 EventLoop 线程被阻塞,使其无法正常响应可读事件并读取缓冲区数据。
为了验证猜测,我们在日志中打印线程信息做进一步观察。

结果发现大部分超时都发生在同一个EventLoop线程上(Lettuce的epollEventLoop-9-3线程),那这个线程此刻的状态是什么呢?我们可以通过诊断工具查看线程堆栈,定位阻塞原因。
Arthas排障
这里我们利用阿里arthas排障工具的thread命令查看线程状态和堆栈信息。


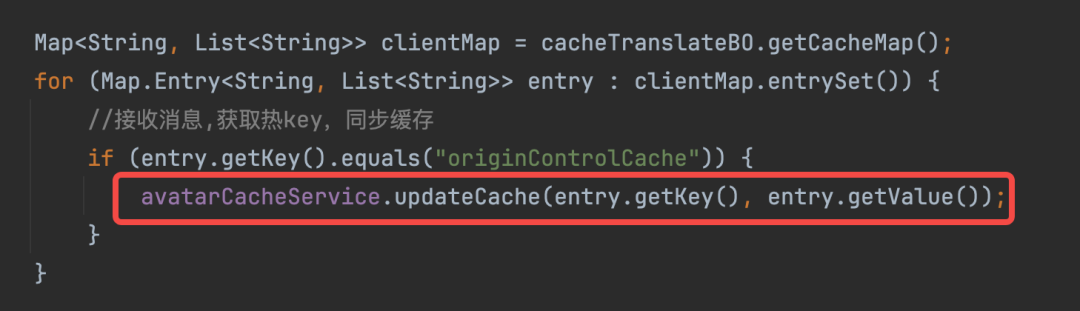
从堆栈信息可以看出,Lettuce一共创建了3个Netty EventLoop线程,其中9-3处在TIMED_WAITTING状态,该线程亦是Pub/Sub消息的的监听线程,阻塞在了RedisLettucePubSubListener对象接收消息更新热key的get方法上。
定位原因
通过Arthas排障我们了解到,原来Lettuce是在Netty的EventLoop线程中响应Pub/Sub事件的。由此我们也基本定位了缓冲区的积压原因,即在RedisLettucePubSubListener中执行了阻塞的future get方法,导致其载体EventLoop线程被阻塞,无法响应与其Selector关联连接的io事件。
为什么Pub/Sub事件会和其他连接的io事件由同一个EventLoop处理呢?通过查阅资料,发现Netty对连接进行多路复用时,只会启动有限个EventLoop线程(默认是CPU数*2)进行连接管理,每个连接是轮询注册到 EventLoop上的,所以当EventLoop数量不多时,多个连接就可能会注册到同一个io线程上。
Netty中EventLoop线程数量计算逻辑

Netty注册EventLoop时的轮训策略

结合出问题的场景进一步分析,一共有3个EventLoop线程,创建了6个连接,其中 Pub/Sub 连接的创建优先级高于负责数据路由的副连接,因此必然会出现一个副连接和 Pub/Sub 连接注册到同一个 EventLoop 线程上的情况。而我们的程序会访问大量的key,当key被路由到Pub/Sub的共享线程上时,由于此时线程被Pub/Sub的回调方法阻塞,即使缓冲区中有数据到达,也会导致与该 EventLoop 绑定的副连接上的读写事件无法被正常触发。
发布订阅回调方法阻塞导致EventLoop线程阻塞
针对这种应用场景Lettuce官网上也有专门提醒:https://lettuce.io/core/release/reference/index.html
即不要在Pub/Sub的回调函数中执行阻塞操作。

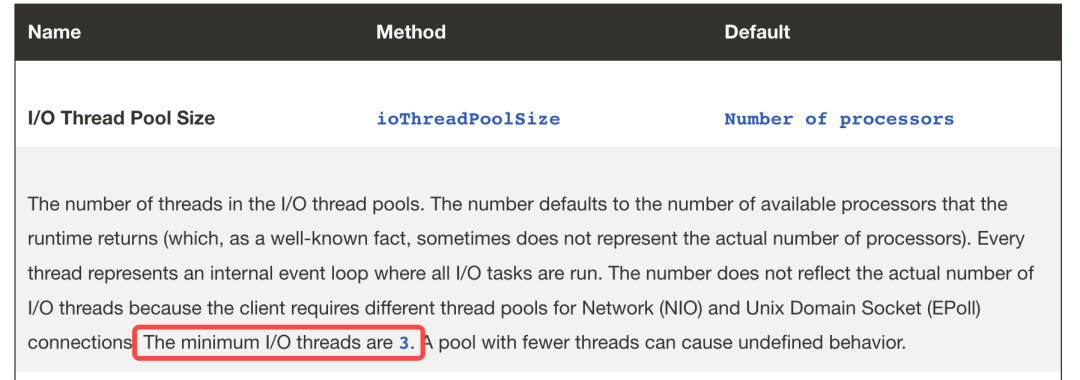
另外还有一点需要额外说明,就是关于 EventLoop 的数量。由于我们并没有主动配置,一般情况下Netty 会创建 CPU 数量的两倍的 EventLoop。在我们的测试程序中,宿主环境是双核,理论上应该创建4个 EventLoop。但观察到实际的 EventLoop 数量却只有3个。这是因为 Lettuce 框架对 Netty 的逻辑进行了调整,要求创建的 EventLoop 数量等于 CPU 核数,且不少于3个。
Lettuce中的io线程数量计算逻辑。

这点在官方文档中也有说明。
解决方案
原因定位后,解决方案也呼之欲出。有两种方法:
增加io线程
增加Lettuce io线程数量,使Pub/Sub连接和其他连接可以注册到不同的EventLoop中。具体设置方式也有两种:
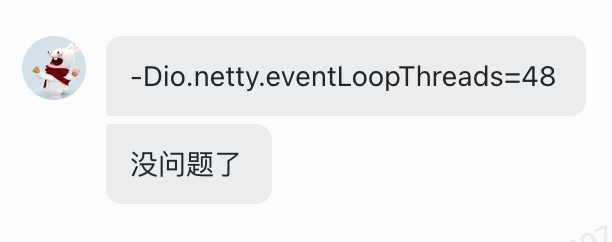
在lettuce提供的ClientResources接口中指定io线程数量

由于Lettuce底层用的Netty,也可以通过配置io.netty.eventLoopThreads参数来指定Netty中EventLoop的数量。为了快速验证效果,我们在超时实例上配置该参数后重启,发现问题果然消失,也进一步证明了的确是该原因导致了访问超时。
异步化
比较优雅的方式是不要在nio线程中执行阻塞操作,即将处理Pub/Sub消息的过程异步化,最好放到独立的线程中执行,以尽早释放Netty的EventLoop资源。我们熟悉的Spring-data-redis框架就是这么做的。
Spring-data-redis的做法是每次收到消息时都新启动新线程处理。

思考
尽管问题已经解决,但之前还有几个遗留的疑问没有解答。经过一番研究,我们也找到了答案。
为什么低版本镜像没问题?
在之前的分析中,我们提到了因为 EventLoop 线程数量过少导致线程阻塞。高版本的实例中 EventLoop 线程数量为 3,那么低版本的情况呢?通过Arthas 查看,发现低版本 Lettuce 的 EventLoop 数量是 13,远远超过了高版本的数量。这表示在低版本环境中,Pub/Sub 连接和其他连接会注册到不同的 EventLoop 上,即使 Pub/Sub 处理线程被阻塞,也不会影响到其他连接读写事件的处理。
高版本镜像最大线程编号9-3
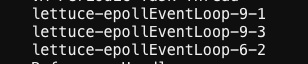
低版本镜像最大线程编号9-13

为什么低版本的镜像会创建更多的 EventLoop 呢?这其实是 JDK 的一个坑。早期的 JDK 8 版本(8u131 之前)存在docker环境下Java获取cpu核心数不准确的问题,会导致程序拿到的是宿主机的核数。
(https://blogs.oracle.com/java/post/java-se-support-for-docker-cpu-and-memory-limits)
查看低版本镜像的jdk版本是8u101,应用宿主机的核数是16,也就是说,低版本应用误拿到了宿主机的核数16,因此会将每个连接注册到一个独立的EventLoop上,从而避免了阻塞的发生。换句话说,之所以低版本镜像没问题,其实是程序在错误的环境下获取到错误的数值,却得到了正确的结果,负负得正了。至于为什么最大线程号是 13 ,这是由于我们的 Redis 集群配置了两个域名,如下图所示。
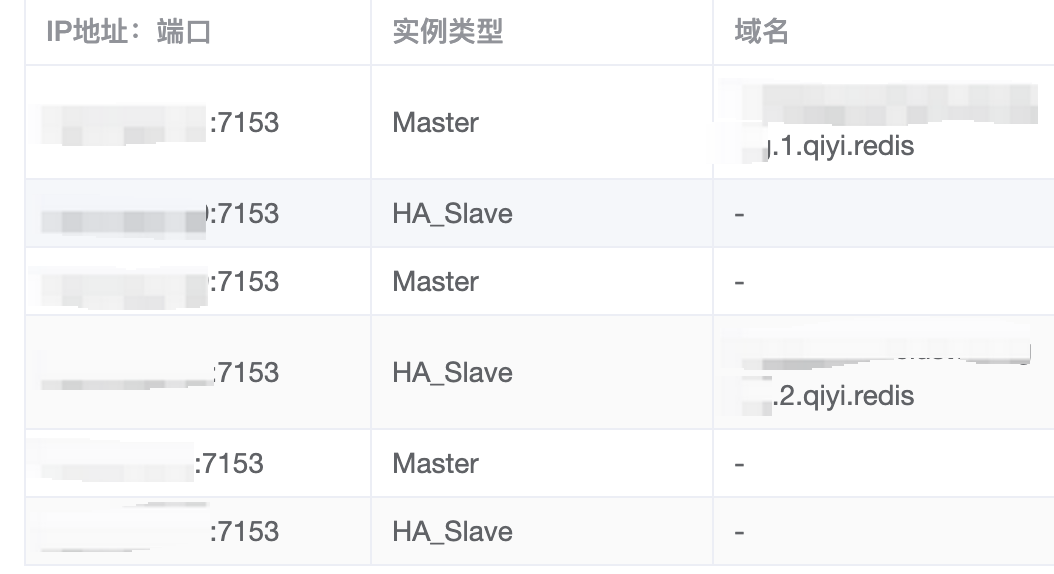
在 RedisClusterClient 初始化时,会分别对域名(2)、所有集群节点(6)、Pub/Sub 通道(1)、集群主连接(1)、副连接(3)进行连接创建,加起来一共正好是 13 个。
为什么高版本通过Spring访问Redis为什么不会出现超时问题?
原始项目访问Redis有Spring和缓存框架两种方式。前文中提到的所有 EventLoop 都是由自研缓存框架维护的 RedisClusterClient 对象创建的。而Spring 容器会使用单独的 RedisClusterClient 对象来创建Redis连接。在 Lettuce 中,每个 RedisClusterClient 对象底层都对应着不同的 EventLoopGroup。也就是说,Spring 创建的Redis连接一定不会和缓存框架的连接共用同一个 EventLoop。因此即使缓存框架所在的 EventLoop 线程被阻塞,也不会影响到 Spring 连接的事件响应。
为什么高版本镜像访问单机Redis没问题?
与RedisClusterClient访问Redis集群时会创建多个主副连接不同,访问单机Redis时Lettuce使用的RedisClient只会创建1个连接。再加上独立的Pub/Sub连接,相当于是2个连接注册到3个EventLoop上,避免了冲突。
05
总结
本文从实际工作中遇到的一个Redis访问超时问题出发,探究背后Spring、Lettuce和Netty的工作原理,并利用Arthas等调试工具,分析了EventLoop线程对连接处理的重要性,以及在处理Pub/Sub事件时避免阻塞操作的必要性。通过观察不同版本环境下的行为差异,加深了对JDK版本和程序环境适配的理解,为今后排查类似问题积累了宝贵经验。
06
参考资料
[1]https://lettuce.io/core/5.3.7.RELEASE/reference/index.html
[2]https://docs.spring.io/spring-data/redis/reference/redis/pubsub.html
[3]https://github.com/TFdream/netty-learning/issues/22
[4]https://github.com/alibaba/jetcache/blob/master/docs/CN/RedisWithLettuce.md
[5]https://arthas.aliyun.com/doc/thread.html
[6]https://blogs.oracle.com/java/post/java-se-support-for-docker-cpu-and-memory-limits