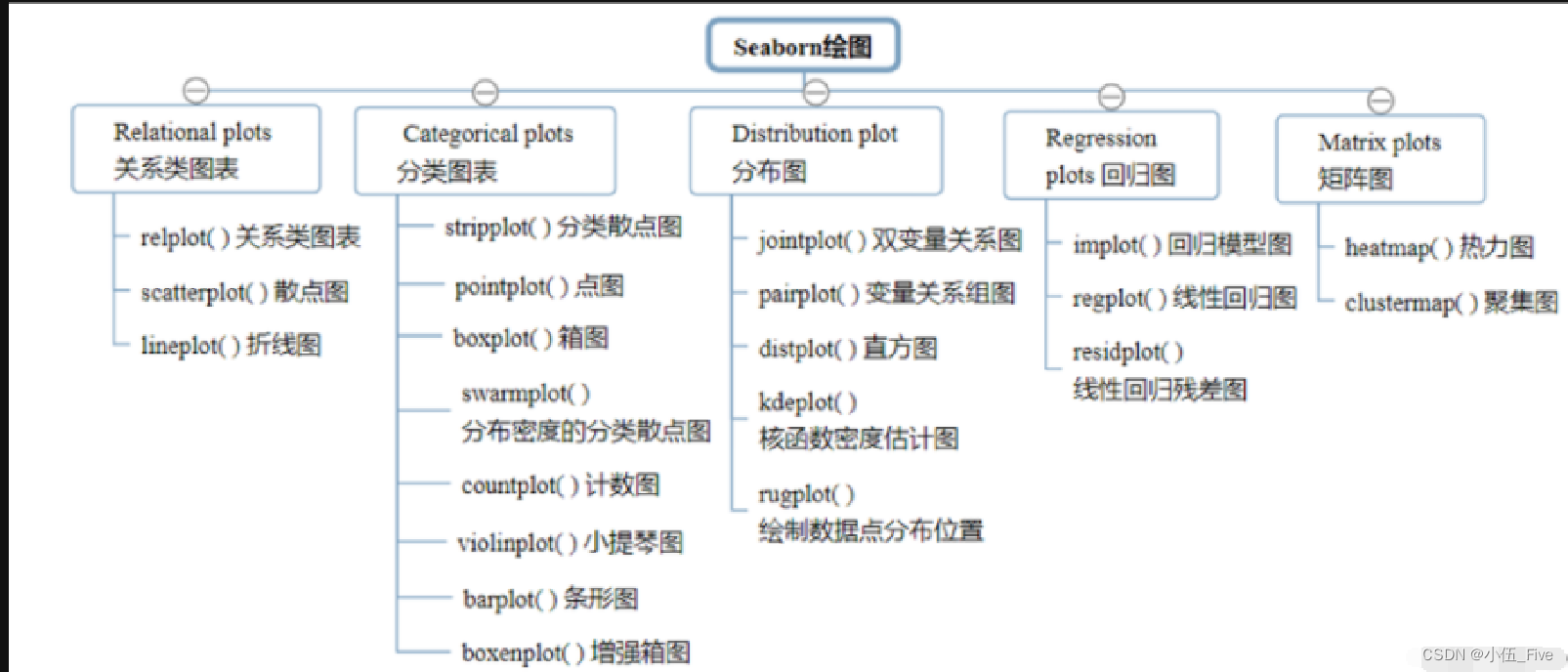
本次将对于构建有序链表,有序链表的归并,反转链表,进行一一介绍和代码分享。
首先是一些链表中的基本的函数:
Node* creatList()
{
Node* headNode = (Node*)malloc(sizeof(Node));
assert(headNode);
headNode->next = NULL;
return headNode;
}
Node* creatNode(Datatype data)
{
Node* newNode = (Node*)malloc(sizeof(Node));
assert(newNode);
newNode->data = data;
newNode->next = NULL;
return newNode;
}
void traverseList(Node* headNode)
{
Node* posNode = headNode->next;
while (posNode != NULL)
{
printf("%d ", posNode->data);
posNode = posNode->next;
}
}这里很基本,如果理解有困难,请从头学习链表。
以下是构建有序链表,也就是找到符合顺序的位置进行节点插入:
//构建有序链表:和构建顺序表一样,需要找到符合顺序的位置,然后插入元素
//核心是找到第一个比它大的节点,放到这个节点之前(双节点遍历)
void insertData(Node* headNode, Datatype data)
{
Node* newNode = creatNode(data);
Node* posNode = headNode->next;
Node* preNode = headNode;
//assert(posNode);
//当前面节点的数据小于data的时候,继续向后走
while (posNode!= NULL && posNode->data <= data)
{
posNode = posNode->next;
preNode = preNode->next;
}
//特殊的情况分析:(短路现象)
//pos在第一个节点,第一个节点为空,那么说明只有表头,连接表头和newNode
if (posNode == NULL&&posNode == headNode->next)
{
headNode->next= newNode;
}
//pos不在第一个节点,但是pos指向空,
//pos指向最后一个节点的后面一个,也就是还有没有找到大于data的:
// 说明没有大于data的节点,所以将data与最后连接即可
else if (posNode == NULL && posNode != headNode->next)
{
preNode->next = newNode;
}
//找到了位置,插入在pos的前面
else
{
newNode->next = posNode;
preNode->next = newNode;
}
}这个过程和顺序表的构建流程基本相同,比较简单,所以不做过多解释。
接下来是单链表的翻转:
void reverseList(Node* headNode)
{
//对于1个表头,1个节点;1个表头,2个节点的链表不需要进行翻转
if (headNode->next == NULL || headNode->next->next == NULL)
{
return;
}
Node* posNode = headNode->next;
Node* preNode = NULL;
Node* sucNode = headNode->next->next;
while (sucNode != NULL)
{
//指向改变
posNode->next = preNode;
//整体向后移动
preNode = posNode;
posNode = sucNode;
sucNode = sucNode->next;
}
//最后一步改变指向方向
posNode->next = preNode;
//将表头与完成反转的第一个节点相连接
headNode->next = posNode;
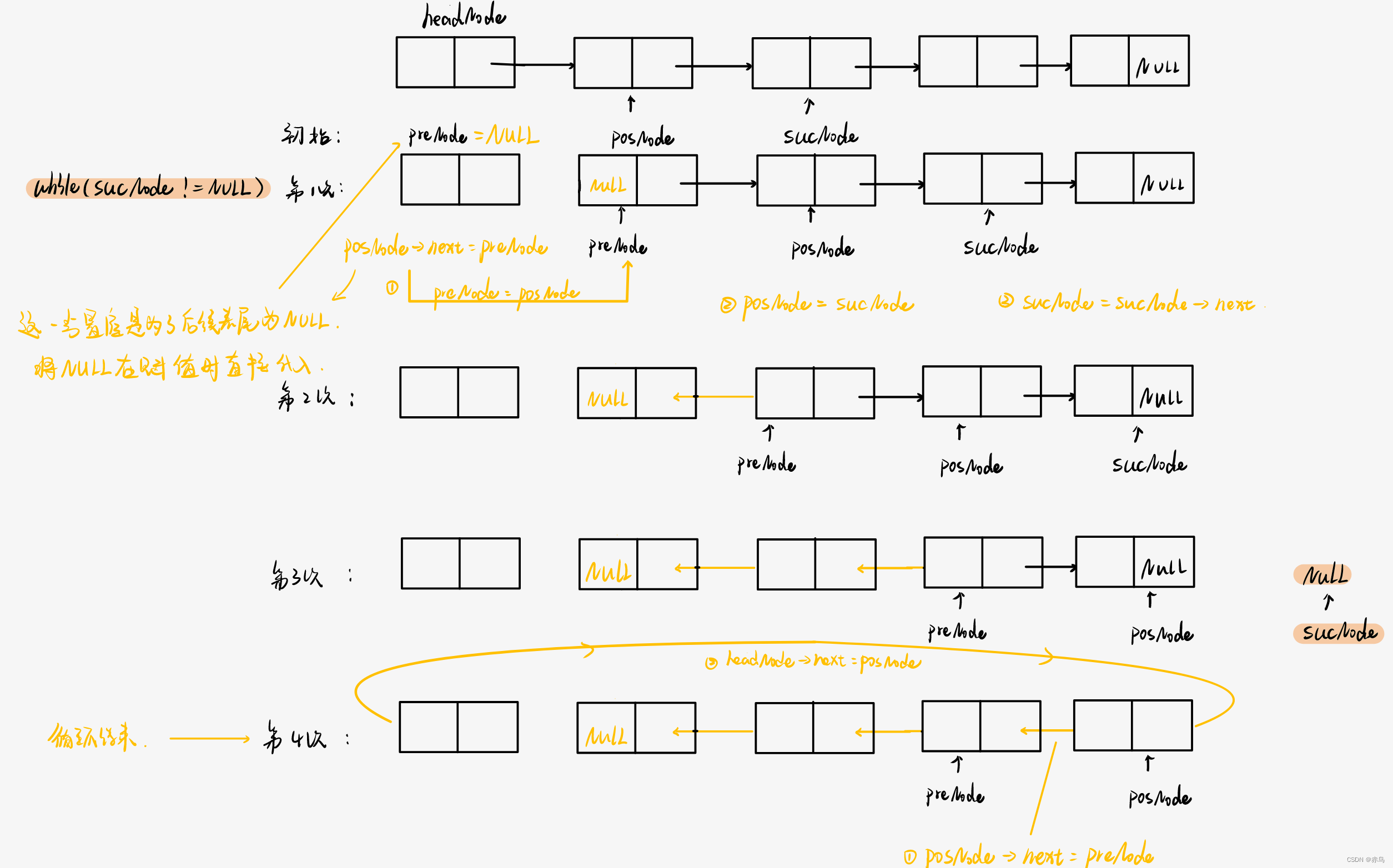
}以下是逐步的过程模拟:结合代码中的注释和过程一一对应更容易理解,其中preNode,sucNode分别是posNode的前驱和后继节点。
示例
假设我们有以下的单链表:
headNode -> 1 -> 2 -> 3 -> 4 -> NULL |
我们希望反转后得到:
headNode -> 4 -> 3 -> 2 -> 1 -> NULL |
分析执行过程
- 初始化指针:
posNode指向第一个元素(1)。preNode为NULL(因为没有前驱节点)。sucNode指向第二个元素(2)。
- 进入循环,当
sucNode不为NULL时:- 改变
posNode(当前节点)的next指针,使其指向前驱节点preNode。 - 更新
preNode为当前的posNode。 - 更新
posNode为当前的sucNode。 - 更新
sucNode为posNode的下一个节点。
- 改变
这个过程会一直持续到 sucNode 为 NULL,即到达链表的末尾。
- 在循环结束后,执行以下操作:
- 将最后一个节点(
posNode)的next指针指向preNode。 - 将头节点的
next指针指向反转后的第一个节点(posNode)。
- 将最后一个节点(
最后,两个有序链表的归并:
//有序链表的归并:
void mergeList(Node* newHeadNode, Node* head1, Node* head2)
{
Node* up = head1->next;
Node* down = head2->next;
Node* temp = newHeadNode;
assert(up && down);
while (up != NULL && down != NULL)
{
if (up->data < down->data)
{
temp->next= up;
up = up->next;
}
else
{
temp->next = down;
down = down->next;
}
temp = temp->next;
}
//up结尾,down没结尾
if (up == NULL && down != NULL)
{
temp->next = down;
}
//down结尾,up没结尾
else if (up != NULL && down == NULL)
{
temp->next = up;
}
//没有两个同时结尾的情况
}示例和分析执行过程:
假设我们有以下两个有序链表:
head1: 1 -> 3 -> 5 | |
head2: 2 -> 4 -> 6 |
调用 mergeList(newHeadNode, head1, head2); 后,我们希望得到以下合并后的链表:
newHeadNode -> 1 -> 2 -> 3 -> 4 -> 5 -> 6 |
执行过程:
up指向1,down指向2,temp指向newHeadNode。- 因为
1 < 2,所以temp->next = up;,然后up移动到3,temp移动到1。 - 现在
up指向3,down指向2。 - 因为
2 < 3,所以temp->next = down;,然后down移动到4,temp移动到2。 - 重复这个过程,直到
up或down为NULL。 - 在本例中,当
up指向5且down指向4时,因为4 < 5,down指向的节点会被插入到新链表中。 - 当
down遍历到NULL时,up还有节点5和6。因此,将up指向的剩余链表直接连接到新链表的末尾。
对于链表的归并,代码虽然简单,但要理解其中的流程是极为关键的,本次的分享结束,希望对你有帮助。