原文:vLLM-prefix浅析(System Prompt,大模型推理加速)
简介
本文浅析了在大模型推理加速方面一个非常优秀的项目 vLLM 的一个新特性 Prefix。在 Prompt 中有相同前缀时可以提高吞吐量降低延迟,换句话说可以省去这部分相同前缀在自注意力阶段的重复计算。
更新 2024.1.18:Prefix 已经合并到主分支上了!如果你的 vLLM 不能使用也许是时候升级一下体验下新功能哩!
https://github.com/vllm-project/vllmgithub.com/vllm-project/vllm
同时安利一下我在 Prefix 方面的一点小工作:添加了 Prefix 删除功能,使用了 Trie 来维护 Prefix 以实现多级Prefix,实现 Prefix 对 Alibi 的支持,对一批含有 Prefix 的询问进行贪心调度(一个特殊场景下的 Prefix 调度)。
DouHappy 的 vllm-prefixgithub.com/DouHappy/vllm-prefix
更新 2024.1.18:已经有了更好的工作:SGLang
这篇博客中更加深入的讨论了关于 prefix sharing 的问题。他们同样采用了 Trie 的思想,使用 LRU 对 Prefix 片段进行调度。
https://lmsys.org/blog/2024-01-17-sglang/lmsys.org/blog/2024-01-17-sglang/
问题背景Fast and Expressive LLM Inference with RadixAttention and SGLang | LMSYS Org问题背景
在很多大模型的实际应用场景下需要在给出大模型具体任务信息之前给模型介绍任务,可以让大模型在这项任务上的效果有不少提升,这里推一下有 9w 多 Star 的 awesome-chatgpt-prompts,这部分内容一般放在 Prompt 的最前端,在 PagedAttention(vLLM是PagedAttention的具体实现)论文中把这一段 Prompt 称之为 System Prompt。System Prompt 往往经过人工调整之后就固定不变了,模型每次在自注意力阶段都需要进行一段相同的计算,如果把这部分的计算结果保存下来,在以后的计算中就可以省去这部分计算,从而增加大模型服务的吞吐量,降低延迟。文本中所说的 Prefix 基于这个想法实现了更加一般化的实现。
相关工作
Triton
为了更高的效率,核心的 PagedAttention 使用了 Triton 语言,一个非常易于上手同时运行高效的 GPU 并行编程语言。为了文章的易读性,这篇文章简单略过对于项目中涉及到 Triton 的部分,主要写项目的实现思路。感兴趣可以在他们的 Github 仓库里看更详细的内容。
Tritongithub.com/openai/triton
PagedAttention和vLLM
PagedAttention 最早在 Efficient Memory Management for Large Language Model Serving with PagedAttentio 这篇论文中正式提出,不过他们的项目 vLLM 很早就开始维护了。
Efficient Memory Management for Large Language Model Serving with PagedAttentionarxiv.org/abs/2309.06180
目前显卡吞吐量的瓶颈往往在于数据的传送带宽与计算速度的差距,显卡有很大部分时间是在等数据,因此如何同时塞更多的数据(增大 batchsize)来满足 GPU 的并行计算速度提高显卡吞吐量的一个重要想法。PagedAttention 是根据计算机操作系统中对内存的分页思想提出的,对大语言模型推理时的显存浪费问题提出了一种显存分页的 Attention 计算方法,能很大程度上节省在显存的浪费,从而提高 batchsize 的大小。因为显存的分页,所以 Token 不需要连续的存储在显存中,这中更灵活的存储方式给了很大的显存优化空间。

不同LLM服务系统的内存浪费百分比(绿色为利用的比例)
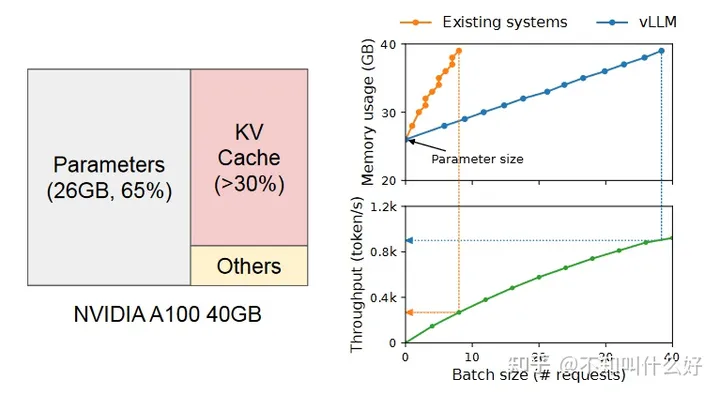
灰色是模型参数,粉色是预先申请的 KV Cache 用于之后 KV 值的存储。在相同的batchsize大小下vLLM远小于传统实现
Prefix
安装
需要下载 PR1669 中的代码并从下载的源码安装 vLLM。因为 vLLM 在 CUDA12.2 下编译的所以最好在 12.2 环境下安装。 vLLM 安装在官方的文档中有详细介绍。
Installation - vLLMdocs.vllm.ai/en/latest/getting_started/installation.html
Prefix功能使用方法Installation - vLLMPrefix功能使用方法
目前官方的实现只支持提供参数 prefix_pos 表示前多少个 token 是用户指定的 prefix。我实现了一个函数来比较方便的调用官方的接口。
import time
import datetime
import os
from vllm import LLM
from vllm import SamplingParams
def test_prefix(llm = None, sampling_params=None, prompts=None, prompt_token_ids=None, prefix_len=None, save_file=None, detile=True):
assert prompts != None or prompt_token_ids != None, f"prompt and tokens can't both be None"
if isinstance(prefix_len, int):
prefix_len = [prefix_len]
assert len(prompts) % len(prefix_len) == 0, f"len of prompts must be multiple of len of prefix_len"
print("------start generating------")
start_time = time.time()
# whether use Prefix
if prefix_len != None:
# start inference
if prompt_token_ids != None:
outputs = llm.generate(prompt_token_ids=prompt_token_ids,
sampling_params=sampling_params,
prefix_pos=prefix_len * (len(prompts) // len(prefix_len)))
else:
outputs = llm.generate(prompts=prompts,
sampling_params=sampling_params,
prefix_pos=prefix_len * (len(prompts) // len(prefix_len)))
else:
outputs = llm.generate(prompts, sampling_params=sampling_params)
end_time = time.time()
print(f"cost time {end_time - start_time}")
if save_file != None:
print("saving output......")
for index, output in enumerate(outputs):
if detile == True:
print(output, file=save_file)
else:
print(output.outputs[0].text, file=save_file)
print(f"output saved in {save_file.name} {datetime.datetime.now()}")
# 你需要对下面这些参数进行改变
# set gpus
os.environ['CUDA_VISIBLE_DEVICES']="0"
tensor_parallel_size = len(os.getenv('CUDA_VISIBLE_DEVICES').split(','))
# set inference model
# 这里需要换成你的模型位置
model = "/data/images/llms/models--baichuan-inc--Baichuan2-13B-Chat"
# Create an LLM.
llm = LLM(model=model, tokenizer_mode='auto', trust_remote_code=True, tensor_parallel_size=tensor_parallel_size)
# get prompts
prompts = ["这是一个 Prefix 功能使用的示例,因为 Prefix 的存储以物理块为单位,所以 Prompt 的长度需要至少大于等于一个物理块,这是第一句话",
"这是一个 Prefix 功能使用的示例,因为 Prefix 的存储以物理块为单位,所以 Prompt 的长度需要至少大于等于一个物理块,这是第二句话"]
prompt_token_ids = llm.tokenizer(prompts)
# set SamplingParams
sampling_params = SamplingParams(temperature=0,
max_tokens=100,
)
# prefix_len 是与 prompts 等长的 list,表示对应 prompts 的 prefix 长度,没有设为 None
with open("output.txt", 'w') as f:
test_prefix(llm=llm,
# prompts=prompts,
prompt_token_ids=prompt_token_ids
prefix_len=[16, 32],
save_file=f,
sampling_params=sampling_params,
detile=False,
)官方还实现了一个在线版本的API,在目录 vllm/entrypoints/api_server.py 中的 generate 函数,但是只支持一次传一个,需要自己写异步函数来处理同时进行多次访问。
注意:
- 在同一个 batch 中因为在并行计算所以并不会利用 Prefix 进行加速,需要等待一个推理 batch 结束后 Prefix 计算出的信息才会存储到 KV cache 中供后续推理使用,这种行为暂时被称之为 warmup。
- 过多无用的 Prefix 保留在 KV cache 会因占用推理所需的显存空间导致推理速度下降甚至停止推理(没有空余显存空间)。
- 因 Prefix 的存储单位是以块的形式存储的,不同模型一个物理块存储的 Token 数量不同,以 Baichuan2-13B 为例,每个物理块为 16 个,在加入 Prefix 之前会先截断为 16 的整数倍再进行计算,截断的 16 个对速度几乎没有影响。这样做的方式是为了方便后续的计算和存储。
更加详细的采样参数和模型参数可以在 SamplingParams 和 LLM中查看。这里贴一下:
SamplingParams参数:
"""Sampling parameters for text generation.
Overall, we follow the sampling parameters from the OpenAI text completion
API (https://platform.openai.com/docs/api-reference/completions/create).
In addition, we support beam search, which is not supported by OpenAI.
Args:
n: Number of output sequences to return for the given prompt.
best_of: Number of output sequences that are generated from the prompt.
From these `best_of` sequences, the top `n` sequences are returned.
`best_of` must be greater than or equal to `n`. This is treated as
the beam width when `use_beam_search` is True. By default, `best_of`
is set to `n`.
presence_penalty: Float that penalizes new tokens based on whether they
appear in the generated text so far. Values > 0 encourage the model
to use new tokens, while values < 0 encourage the model to repeat
tokens.
frequency_penalty: Float that penalizes new tokens based on their
frequency in the generated text so far. Values > 0 encourage the
model to use new tokens, while values < 0 encourage the model to
repeat tokens.
repetition_penalty: Float that penalizes new tokens based on whether
they appear in the generated text so far. Values > 1 encourage the
model to use new tokens, while values < 1 encourage the model to
repeat tokens.
temperature: Float that controls the randomness of the sampling. Lower
values make the model more deterministic, while higher values make
the model more random. Zero means greedy sampling.
top_p: Float that controls the cumulative probability of the top tokens
to consider. Must be in (0, 1]. Set to 1 to consider all tokens.
top_k: Integer that controls the number of top tokens to consider. Set
to -1 to consider all tokens.
use_beam_search: Whether to use beam search instead of sampling.
length_penalty: Float that penalizes sequences based on their length.
Used in beam search.
early_stopping: Controls the stopping condition for beam search. It
accepts the following values: `True`, where the generation stops as
soon as there are `best_of` complete candidates; `False`, where an
heuristic is applied and the generation stops when is it very
unlikely to find better candidates; `"never"`, where the beam search
procedure only stops when there cannot be better candidates
(canonical beam search algorithm).
stop: List of strings that stop the generation when they are generated.
The returned output will not contain the stop strings.
stop_token_ids: List of tokens that stop the generation when they are
generated. The returned output will contain the stop tokens unless
the stop tokens are sepcial tokens.
ignore_eos: Whether to ignore the EOS token and continue generating
tokens after the EOS token is generated.
max_tokens: Maximum number of tokens to generate per output sequence.
logprobs: Number of log probabilities to return per output token.
Note that the implementation follows the OpenAI API: The return
result includes the log probabilities on the `logprobs` most likely
tokens, as well the chosen tokens. The API will always return the
log probability of the sampled token, so there may be up to
`logprobs+1` elements in the response.
prompt_logprobs: Number of log probabilities to return per prompt token.
skip_special_tokens: Whether to skip special tokens in the output.
spaces_between_special_tokens: Whether to add spaces between special
tokens in the output. Defaults to True.
logits_processors: List of functions that modify logits based on
previously generated tokens.
"""LLM加载参数:
"""An LLM for generating texts from given prompts and sampling parameters.
This class includes a tokenizer, a language model (possibly distributed
across multiple GPUs), and GPU memory space allocated for intermediate
states (aka KV cache). Given a batch of prompts and sampling parameters,
this class generates texts from the model, using an intelligent batching
mechanism and efficient memory management.
NOTE: This class is intended to be used for offline inference. For online
serving, use the `AsyncLLMEngine` class instead.
NOTE: For the comprehensive list of arguments, see `EngineArgs`.
Args:
model: The name or path of a HuggingFace Transformers model.
tokenizer: The name or path of a HuggingFace Transformers tokenizer.
tokenizer_mode: The tokenizer mode. "auto" will use the fast tokenizer
if available, and "slow" will always use the slow tokenizer.
trust_remote_code: Trust remote code (e.g., from HuggingFace) when
downloading the model and tokenizer.
tensor_parallel_size: The number of GPUs to use for distributed
execution with tensor parallelism.
dtype: The data type for the model weights and activations. Currently,
we support `float32`, `float16`, and `bfloat16`. If `auto`, we use
the `torch_dtype` attribute specified in the model config file.
However, if the `torch_dtype` in the config is `float32`, we will
use `float16` instead.
quantization: The method used to quantize the model weights. Currently,
we support "awq". If None, we assume the model weights are not
quantized and use `dtype` to determine the data type of the weights.
revision: The specific model version to use. It can be a branch name,
a tag name, or a commit id.
tokenizer_revision: The specific tokenizer version to use. It can be a
branch name, a tag name, or a commit id.
seed: The seed to initialize the random number generator for sampling.
gpu_memory_utilization: The ratio (between 0 and 1) of GPU memory to
reserve for the model weights, activations, and KV cache. Higher
values will increase the KV cache size and thus improve the model's
throughput. However, if the value is too high, it may cause out-of-
memory (OOM) errors.
swap_space: The size (GiB) of CPU memory per GPU to use as swap space.
This can be used for temporarily storing the states of the requests
when their `best_of` sampling parameters are larger than 1. If all
requests will have `best_of=1`, you can safely set this to 0.
Otherwise, too small values may cause out-of-memory (OOM) errors.
"""
PrefixPool和Prefix
目前 vLLM 中对于 Prefix 功能的实现主要是通过两个类 Prefix 和 PrefixPool 来进行管理
Prefix的主要运行逻辑如下:
- add_request。检查用户每个请求中的 Prefix 是否已经存在,若不存在则加入 PrefixPool 中(此时未分配物理块)
- schedule。vLLM选择一部分未结束的用户请求放入Running队列准备进行推理,此时进行物理块的分配。若 Prefix 未被分配物理块则为 Prefix 分配。
- step。进行一步推理,一步推理,定义为一次 Self-Attention 或一次 Cross-Attention,具体取决为用户的请求出于哪一个状态。
- 将推理结果中需要存储的部分存储到指定物理块中。
- 回到步骤2
PrefixTrie
PrefixPool 以 token 的 hash 值作为关键字形成一个字典,来保存对应的 Prefix。PrefixTrie 基于 Trie 的思想以Token 为关键字来维护 Prefix,这样能够在多个 Prefix 之间有相同前缀时实现物理块的共享,进一步减小了对显存的占用,还可以快速搜索最长匹配的 Prefix,对一些特殊场景下可能有较大的帮助。
若对 PrefixTrie 的实现感兴趣可以看我的仓库,欢迎提出意见。
Prefix调度策略
目前官方没有实现 Prefix 的删除功能,但已经有佬实现了一种基于 FIFO 的 Prefix 调度策略,即限制 Prefix 占用的显存大小,超过限制时删除最早加入的Prefix,这种调度策略最直接,对于各种场景下都有一定的优化。
因为应用场景的原因,我遇到的应用场景知道所有询问和对应的Prefix,这种场景下我实现了一个基于贪心的调度策略,对于 Prefix 的 warmup 过程进行了优化。主要逻辑如下:
- 根据使用的 Prefix 不同对用户请求进行分配将信息存储在 PrefixGroup 这个类中
- 计算每种 Prefix 相关的所有请求预估需要多少显存(物理块数量)
- 根据所需的物理块数量对 PrefixGroup 进行降序排序
- 根据排序的顺序依次贪心判断预估下一个 batch 剩余空间能否完成对该 Group 的所有请求,能完成则加入推理队列
- 将加入推理队列中的所有 Prefix 进行 Warmup(只进行 Self-Attention 不进行 Cross-Attention)
- 对所有加入推理队列中的请求进行推理并收集推理结果,然后删除对应 Prefix。
- 回到步骤 4 直到没有 Group 能加入推理队列
- 对于剩余请求依次进行 Warmup 和推理
Self-Attention 和 Prefix
对于一般的 Self-Attention 计算,qkv 三者的长度都是相同的即序列的长度,但是在 Prefix 的情况下因为属于 Prefix 部分的 q 是不需要参与 Self-Attention 计算的即我们希望优化掉的重复计算,所以 q 的长度会少 Prefix 的部分。一般来说qkv形状都为[batchsize, 序列最大长度,注意力头数量,注意力头大小],使用 Prefix 情况下kv长度不变,q的第二维长度变为除去 Prefix 之后的 Token 长度。传统方法中对每个询问都需要填充到最长长度以进行并行计算,但是这样会造成较大的内存浪费,vLLM 将第一维和第二维即 “batchsize”和“序列最大长度”这两维压缩到一维,不采用填充的方式形成 batch,而采用拼接的方式。这样能节省需要的显存空间。
拼接后使用 PagedAttention 算子进行计算,PagedAttention 具体实现中利用 Triton 语言并融合了 FlashAttention 的思想进行了优化。
这里有一个位置编码问题:对于 Rope 或者传统的位置编码都是在算子外部添加偏移,但是 Alibi 需要在计算 qk 后添加偏移,因此 vLLM 中有两个算子,其中一个算子在计算中加入Alibi,这也是这两个算子的唯一区别。
Prefix 的删除
Prefix的删除涉及两个方面,一个是逻辑块的释放,一个是存储 Prefix 的数据结构的删除。
- 逻辑块的删除可以直接调用 BlockManager 接口。
- 存储数据结构的删除涉及到具体数据结构的实现
PrefixPool 中的删除:
对于原 PrefixPool 的实现只需要删除列表和字典中对 Prefix 的记录即可,这里给出一种实现:
def delete_prefix(self, prefix_hash: int) -> Optional[int]:
if prefix_hash not in self.prefixes_hash:
return None
prefix_id = self.prefixes_hash[prefix_hash]
# physics block will be deleted in block_manager outside this function
# del prefix
self.prefixes_hash.pop(prefix_hash)
for key, value in self.prefixes_hash.items():
if value > prefix_id:
self.prefixes_hash[key] -= 1
del self.prefixes[prefix_id]
return prefix_id现在(2024.1.17)的存储方式是使用字典记录 Prefix 在列表中的编号,Prefix实际存储在列表中。之后的存储方式将直接采用 hash 值到 Prefix 的映射,因此这种实现方式后续应该会被简化。
供外部使用的接口实现:
def delete_prefix(self, prefix_tokens:List[int]) -> int:
'''
Input:
prefix: the token_ids of prefix
Output:
deleted_id: the prefix_id of deleted prefix if successfully deleted
or None
'''
block_size = self.cache_config.block_size
prefix_pos = len(prefix_tokens) // block_size * block_size
truncated_prefix_token_ids = prefix_tokens[:prefix_pos]
prefix_hash = hash(tuple(truncated_prefix_token_ids))
prefix = self.scheduler.prefix_pool.fixed_search(prefix_hash)
deleted_id = self.scheduler.prefix_trie.delete_prefix(truncated_prefix_token_ids)
return deleted_id实验效果
在 Baichuan2-13B-chat 上,约长 700 的 Prompt,其中前 596 为 Prefix,能提速 2-3 倍。
后序对于其他模型,其他常用 Prompt,其他数据(吞吐量,延迟)会做一些实验继续更新。
更新于 [UTC-8] 2024.1.18-18:26
| 总时间 | Warmup时间 | 推理时间 | 数据 | 推理框架 | |
| llama-7b | 7.79 | 0.13 | 7.24 | 107组 prompt:约550 perfix:530 output:30 | vLLM-prefix |
| llama-7b | 2.70 | - | - | SGLang | |
| llama-7b | 3.52 | - | - | vLLM-genreate | |
| llama-7b | 31.00 | 0.12 | 29.12 | 500组 prompt:约780 perfix:752 output:30 | vLLM-prefix |
| llama-7b | 12.52 | - | - | SGLang | |
| llama-7b | 12.91 | - | - | vllm-generate |
vLLM-prefix 使用我实现的 PrefixGroup 贪心调度,vLLM-generate 使用 vLLM 的 generate 函数,通过指定prefix长度进行推理, SGLang 使用 run_batch
- SGLang 对全流程的算子都进行了一定的优化(Triton/CUDA),速度上略快与generate。SGLang目前还不是很稳定,有一定概率崩溃
- 为何 vLLM-prefix 需要花费这么长时间进行推理可能有待进一步思考,正常来说推理时间应该与 generate 相近
挖坑
后面可能会对一些后续工作,比如Prefix的手动删除,Prefix调度,关于Prefix和Alibi等写点东西。
有不少文章对vLLM的实现做了详解,比自己干看代码能理解快不少,但是因为vLLM版本在不断地更新,有些文章中的实现可能与现在的项目有些出入,有些实现可能后面会被启用优化掉,但是大致的框架应该不会有很大的改动,如果有比较大的更新,后面可能做一期最新版vLLM的实现解析。
F&Q
放点大家问的问题,如果我有能力解答的话。
参考
编辑于 2024-01-26 14:25・IP 属地北京