HTTP
HTTP是什么?
HTTP(全称为"超⽂本传输协议")是⼀种应⽤⾮常⼴泛的应⽤层协议.
HTTP诞⽣与1991年.⽬前已经发展为最主流使⽤的⼀种应⽤层协议.

最新的HTTP3版本也正在完善中,⽬前Google/Facebook等公司的产品已经⽀持了.
HTTP往往是基于传输层的TCP协议实现的.(HTTP1.0,HTTP1.1,HTTP2.0均为TCP,HTTP3基于
UDP实现)⽬前我们主要使⽤的还是HTTP1.1和HTTP2.0.当前课堂上讨论的HTTP以1.1版本为主.
我们平时打开⼀个⽹站,就是通过HTTP协议来传输数据的.

当我们在浏览器中输⼊⼀个搜狗搜索的"⽹址"(URL)时,浏览器就给搜狗的服务器发送了⼀个HTTP
请求,搜狗的服务器返回了⼀个HTTP响应.
这个响应结果被浏览器解析之后,就展⽰成我们看到的⻚⾯内容.(这个过程中浏览器可能会给服务器发送多个HTTP请求,服务器会对应返回多个响应,这些响应⾥就包含了⻚⾯HTML,CSS,JavaScript,图⽚,字体等信息).
所谓"超⽂本"的含义,就是传输的内容不仅仅是⽂本(⽐如html,css这个就是⽂本),还可以是⼀些其他的资源,⽐如图⽚,视频,⾳频等⼆进制的数据.
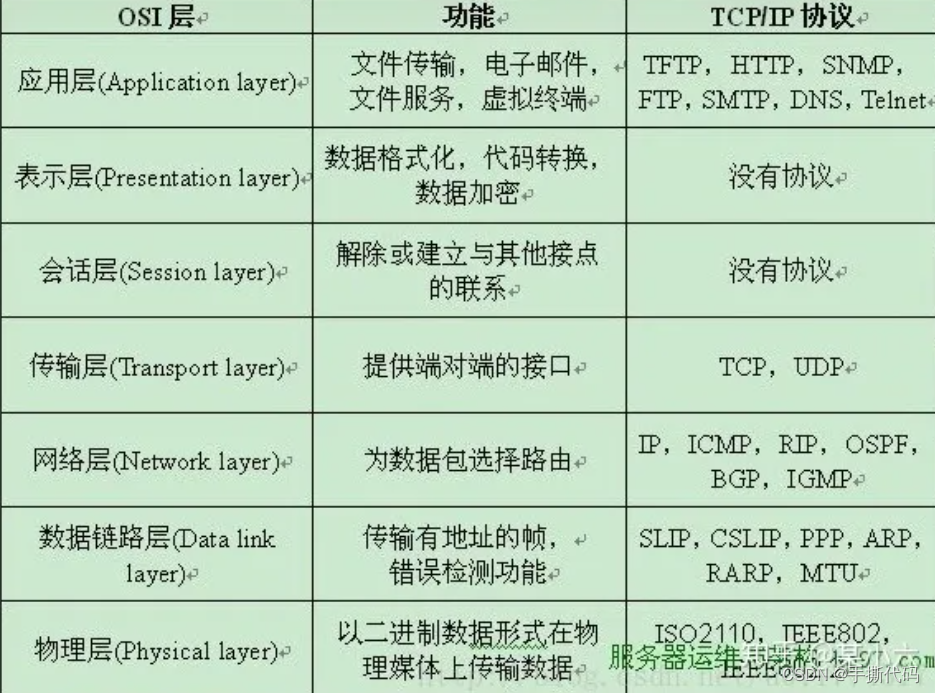
HTTP 协议是 Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网( WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。 HTTP 是一个基于 TCP/IP 通信协议来传递数据(HTML 文件、图片文件、查询结果等)。
HTML 是一种语言,而 HTTP 是一种协议,因此它们是两个不同的东西,尽管它们是相关的。 事实上,无需 HTTP 也可以交换 HTML 网页 (例如,使用 FTP 传输 HTML 页面)。 甚至,可以使用 HTTP 传输非 HTML 页面 (例如,使用 HTTP 传输 XML 页面)。
XML(Extensible Markup Language)是一种类似于 HTML,但是没有使用预定义标记的语言。因此,可以根据自己的设计需求定义专属的标记。这是一种强大将数据存储在一个可以存储、搜索和共享的格式中的方法。
理解"应⽤层协议"
我们已经学过 TCP/IP ,已经知道⽬前数据能从客⼾端进程经过路径选择跨⽹络传送到服务器端进程[ IP+Port ].
可是,仅仅把数据从A点传送到B点就完了吗.
这就好⽐,在淘宝上买了⼀部⼿机,卖家[客⼾端]把⼿机通过顺丰[传送+路径选择]?送到买家[服务器]⼿⾥就完了吗
当然不是,买家还要使⽤这款产品,还要在使⽤之后,给卖家打分评论
所以,我们把数据从A端传送到B端, TCP/IP 解决的是顺丰的功能,⽽两端还要对数据进⾏加⼯处理或者使⽤,所以我们还需要⼀层协议,不关⼼通信细节,关⼼应⽤细节!
这层协议叫做应⽤层协议。⽽应⽤是有不同的场景的,所以应⽤层协议是有不同种类的,其中经典协议之⼀的HTTP就是其中的佼佼者.
理解HTTP协议的⼯作过程

事实上,当我们访问⼀个⽹站的时候,可能涉及不⽌⼀次的HTTP请求/响应的交互过程.
HTTP协议格式
HTTP是⼀个⽂本格式的协议.可以通过Chrome开发者⼯具或者Fiddler抓包,分析HTTP请求/响应的细节.





打开一个网站, 其实浏览器和服务器之间进行的 HTTP 交互不是只有一次,而是通常有很多次!!
第一次交互是拿到这个页面的 html.
htm| 还会依赖其他的 css 和 is,图片等,htm 被浏览器加载之后,又会触发一些其他的 http 请求,获取到 CSs,is 等当执行 js 的时候,js 代码里可能又要触发很多的 http 请求, 获取到一些数据.…




HTTP请求(Request)
HTTP请求包含四个部分:
1.首行

2.请求头

3. 空行
请求头下面会有一个空行,这个空行表示结束标志.
4.正文(body) HTTP载荷部分
有点http有载荷,有些http就没有.
HTTP响应(require)
HTTP的响应格式也是分为四个部分.
1.首行

2. 响应头 键值对

3. 空行
4. 响应报文(body) 载荷

HTTP请求详解
认识URI




举个例子就好理解了:


关于URL encode
关于querystring
querystring中的内容是键值对结构.其中的key和value的取值和个数,完全都是程序猿⾃⼰约定
的.我们可以通过这样的⽅式来⾃定制传输我们需要的信息给服务器.


小总结:

方法


GET方法
GET是最常⽤的HTTP⽅法.常⽤于获取服务器上的某个资源.
在浏览器中直接输⼊URL,此时浏览器就会发送出⼀个GET请求.
另外,HTML中的link,img,script等标签,也会触发GET请求.
使⽤JavaScript中的ajax也能构造GET请求.
GET请求的特点
• ⾸⾏的第⼀部分为GET
• URL的querystring可以为空,也可以不为空.
• header部分有若⼲个键值对结构.
• body部分为空.
关于GET请求的URL⻓度问题
⽹上有些资料上描述: get请求⻓度最多1024kb 这样的说法是错误的.
HTTP协议由RFC2616标准定义,标准原⽂中明确说明:"Hypertext Transfer Protocol--HTTP/1.1,"
does not specify any requirement for URL length.
没有对URL的⻓度有任何的限制.
实际URL的⻓度取决于浏览器的实现和HTTP服务器端的实现.在浏览器端,不同的浏览器最⼤⻓度是不同的,但是现代浏览器⽀持的⻓度⼀般都很⻓;在服务器端,⼀般这个⻓度是可以配置的.
POST方法
POST⽅法也是⼀种常⻅的⽅法.多⽤于提交⽤⼾输⼊的数据给服务器(例如登陆⻚⾯).
通过HTML中的form标签可以构造POST请求,或者使⽤JavaScript的ajax也可以构造POST请求.
POST请求的特点
• ⾸⾏的第⼀部分为POST
• URL的querystring⼀般为空(也可以不为空)
• header部分有若⼲个键值对结构.
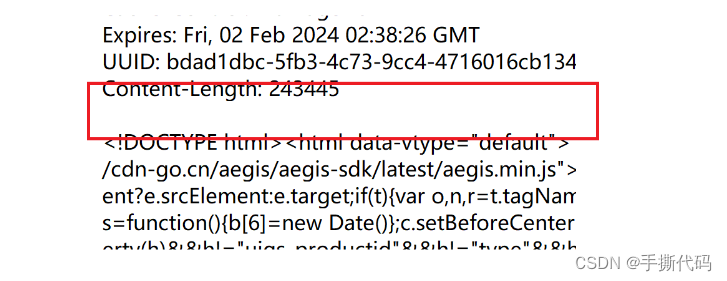
• body部分⼀般不为空.body内的数据格式通过header中的 Content-Type 指定.body的⻓度
由header中的 Content-Length 指定.
经典⾯试题:谈谈GET和POST的区别

1.语义不同:GET⼀般⽤于获取数据,POST⼀般⽤于提交数据.
2.GET的body⼀般为空,需要传递的数据通过querystring传递,POST的querystring⼀般为空,需要传递的数据通过body传递

3.GET请求⼀般是幂等的,POST请求⼀般是不幂等的.(如果多次请求得到的结果⼀样,就视为请求是幂等的).

4.GET可以被缓存,POST不能被缓存.(这⼀点也是承接幂等性).
5.GET请求是可以被浏览器收藏的,POST请求不可以.
补充说明:
• 关于语义:GET完全可以⽤于提交数据,POST也完全可以⽤于获取数据.
• 关于幂等性:标准建议GET实现为幂等的.实际开发中GET也不必完全遵守这个规则(主流⽹站都有"猜你喜欢"功能,会根据⽤⼾的历史⾏为实时更新现有的结果.
• 关于安全性:有些资料上说"POST⽐GET请安全".这样的说法是不科学的.是否安全取决于前端在传输密码等敏感信息时是否进⾏加密,和GETPOST⽆关.
• 关于传输数据量:有的资料上说"GET传输的数据量⼩,POST传输数据量⼤".这个也是不科学的,标准没有规定GET的URL的⻓度,也没有规定POST的body的⻓度.传输数据量多少,完全取决于不同浏览器和不同服务器之间的实现区别.
• 关于传输数据类型:有的资料上说"GET只能传输⽂本数据,POST可以传输⼆进制数据".这个也是不科学的.GET的query string虽然⽆法直接传输⼆进制数据,但是可以针对⼆进制数据进⾏url encode.



认识请求"报头"(header)
header的整体的格式也是"键值对"结构.
每个键值对占⼀⾏.键和值之间使⽤分号分割.
Host
表⽰服务器主机的地址和端⼝.

Content-Length
表⽰body中的数据⻓度

Content-Type
表⽰请求的body中的数据格式.

常⻅选项:
• application/x-www-form-urlencoded:form表单提交的数据格式.此时body的格式形如:
title=test&content=hello
• multipart/form-data:form表单提交的数据格式(在form标签中加上enctyped="multipart/form-data" .通常⽤于提交图⽚/⽂件.body格式形如:
Content-Type:multipart/form-data; boundary=----WebKitFormBoundaryrGKCBY7qhFd3Trw
------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data; name="text"
title
------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data; name="file"; filename="chrome.png"
Content-Type: image/png
PNG ... content of chrome.png ...
------WebKitFormBoundaryrGKCBY7qhFd3TrwA--
• application/json:数据为json格式.body格式形如:
{"username":"123456789","password":"xxxx","code":"jw7l","uuid":"d110a05ccde64b16
User-Agent(简称UA)
表⽰浏览器/操作系统的属性.形如
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
其中 Windows NT 10.0; Win64; x64 表⽰操作系统信息
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77
Safari/537.36 表⽰浏览器信息.
UA的作用


Referer
表⽰这个⻚⾯是从哪个⻚⾯跳转过来的.形如
https://v.bitedu.vip/login
如果直接在浏览器中输⼊URL,或者直接通过收藏夹访问⻚⾯时是没有Referer的.


Cookie



这个过程和去医院看病很相似.
1. 到了医院先挂号.挂号时候需要提供⾝份证,同时得到了⼀张"就诊卡",这个就诊卡就相当于患者的"令牌".
2. 后续去各个科室进⾏检查,诊断,开药等操作,都不必再出⽰⾝份证了,只要凭就诊卡即可识别出当前患者的⾝份.
3. 看完病了之后,不想要就诊卡了,就可以注销这个卡.此时患者的⾝份和就诊卡的关联就销毁了.(类似于⽹站的注销操作)
4. ⼜来看病,可以办⼀张新的就诊卡,此时就得到了⼀个新的"令牌".
关于Cookie的重要结论:



认识请求"正⽂"(body)
正⽂中的内容格式和header中的Content-Type密切相关.上⾯也罗列了三种常⻅的情况.
1)application/x-www-form-urlencoded
POST https://gitee.com/profile/upload_portrait_with_base64 HTTP/1.1
Host: gitee.com
Connection: keep-alive
Content-Length: 107389
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"
Accept: */*
X-CSRF-Token: 6ROfZGr4Y7Qx8td1TuKCnrG8gbODLCSUqUBZSw2b+ac=
X-Requested-With: XMLHttpRequest
sec-ch-ua-mobile: ?0
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Origin: https://gitee.com
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: https://gitee.com/HGtz2222
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: oschina_new_user=false; user_locale=zh-CN; yp_riddler_id=1ce4a551-a160-4
avatar=data%3Aimage%2Fpng%3Bbase64%2CiVBORw0KGgoAAAANSUhEUgAAAPgAAAD4CAYAAADB0Ss
实际的抓包结果⽐较⻓,此处没有全部贴出
2)multipart/form-data
POST https://v.bitedu.vip/tms/oss/upload/file HTTP/1.1
Host: v.bitedu.vip
Connection: keep-alive
Content-Length: 293252
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"
Authorization: Bearer eyJhbGciOiJIUzUxMiJ9.eyJsb2dpbl91c2VyX2tleSI6IjFiYThjMDM5L
sec-ch-ua-mobile: ?0
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
Content-Type: multipart/form-data; boundary=----WebKitFormBoundary8d5Rp4eJgrUSS3
Accept: */*
Origin: https://v.bitedu.vip
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: https://v.bitedu.vip/personInf/student?userId=665
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: rememberMe=true; username=18691491410; Admin-Token=eyJhbGciOiJIUzUxMiJ9.
------WebKitFormBoundary8d5Rp4eJgrUSS3wT
Content-Disposition: form-data; name="file"; filename="李星亚 Java开发⼯程师.pdf"
Content-Type: application/pdf
%PDF-1.7
%³
1 0 obj
<</Names <</Dests 4 0 R>> /Outlines 5 0 R /Pages 2 0 R /Type /Catalog>>
endobj
3 0 obj
<</Author ( N v~N?) /Comments () /Company () /CreationDate (D:20201122145133+06'
endobj
13 0 obj
<</AIS false /BM /Normal /CA 1 /Type /ExtGState /ca 1>>
endobj
实际的抓包结果⽐较⻓,此处没有全部贴出.
3)application/json
POST https://v.bitedu.vip/tms/login HTTP/1.1
Host: v.bitedu.vip
Connection: keep-alive
Content-Length: 105
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"
sec-ch-ua-mobile: ?0
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
Access-Control-Allow-Methods: PUT,POST,GET,DELETE,OPTIONS
Content-Type: application/json;charset=UTF-8
Access-Control-Allow-Origin: *
Accept: application/json, text/plain, */*
Access-Control-Allow-Headers: Content-Type, Content-Length, Authorization, Accep
Origin: https://v.bitedu.vip
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: https://v.bitedu.vip/login
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: rememberMe=true; username=123456789
{"username":"123456789","password":"xxxx","code":"u58u","uuid":"9bd8e09ea27b48cd
HTTP响应详解
认识"状态码"(status code).
状态码表⽰访问⼀个⻚⾯的结果.(是访问成功,还是失败,还是其他的⼀些情况...).
以下为常⻅的状态码.

上述状态码不需要记住,只需要记住几个就好








在重定向的报文中,header就会多一个Location来标志.


注意418是个彩蛋,没啥用.好玩的
认识响应"报头"(header)
响应报头的基本格式和请求报头的格式基本⼀致.
类似于 Content-Type , Content-Length 等属性的含义也和请求中的含义⼀致.
Content-Type
响应中的Content-Type常⻅取值有以下⼏种:
• text/html :body数据格式是HTML
• text/css :body数据格式是CSS
• application/javascript :body数据格式是JavaScript
• application/json :body数据格式是JSON
认识响应"正⽂"(body)
正⽂的具体格式取决于Content-Type.观察上⾯⼏个抓包结果中的响应部分.
1)text/html
Server: nginx/1.17.3
Date: Thu, 10 Jun 2021 07:25:09 GMT
Content-Type: text/html; charset=utf-8
Last-Modified: Thu, 13 May 2021 09:01:26 GMT
Connection: keep-alive
ETag: W/"609ceae6-3206"
Content-Length: 12806
<!DOCTYPE html><html><head><meta charset=utf-8><meta http-equiv=X-UA-Compatible
body,
#app {
height: 100%;
margin: 0px;
padding: 0px;
}
.chromeframe {
margin: 0.2em 0;
background: #ccc;
color: #000;
padding: 0.2em 0;
}
#loader-wrapper {
position: fixed;
top: 0;
left: 0;
width: 100%;
height: 100%;
z-index: 999999;
}
2)text/css
HTTP/1.1 200 OK
Server: nginx/1.17.3
Date: Thu, 10 Jun 2021 07:25:09 GMT
Content-Type: text/css
Last-Modified: Thu, 13 May 2021 09:01:26 GMT
Connection: keep-alive
ETag: W/"609ceae6-3cfbe"
Content-Length: 249790
@font-face{font-family:element-icons;src:url(../../static/fonts/element-icons.53
3)application/javascript
HTTP/1.1 200 OK
Server: nginx/1.17.3
Date: Thu, 10 Jun 2021 07:25:09 GMT
Content-Type: application/javascript; charset=utf-8
Last-Modified: Thu, 13 May 2021 09:01:26 GMT
Connection: keep-alive
ETag: W/"609ceae6-427d4"
Content-Length: 272340
(window["webpackJsonp"]=window["webpackJsonp"]||[]).push([["app"],{0:function
4)application/json
HTTP/1.1 200
Server: nginx/1.17.3
Date: Thu, 10 Jun 2021 07:25:10 GMT
Content-Type: application/json;charset=UTF-8
Connection: keep-alive
X-Content-Type-Options: nosniff
X-XSS-Protection: 1; mode=block
Cache-Control: no-cache, no-store, max-age=0, must-revalidate
Pragma: no-cache
Expires: 0
vary: accept-encoding
Content-Length: 12268
{"msg":"操作成功","code":200,"permissions":[] }
如何构造出HTTP请求
1.通过代码构造
任何一门编程语言,只要能够操作网络,都可以构造HTTP请求.对于Java来说就需要SeverScock和Scock(Tcp的scock api来编程).
2.通过第三方工具构造(例如PostMan等)
3.日常中,我们还会用网页来创建HTTP请求,特别常见的情况.
需要通过HTML/JS来构造请求.
HTTPS加密
HTTPS是在HTTP的基础上加入了一个加密层(SSL).
HTTP是明文传输的不安全.

比如就会发生以上事件.这种叫运营商劫持.即使运营商不劫持.黑客盯上了,也会有危险.
解决安全问题,最重要的就是"加密".

密码学本质上是数学的一个分支(数论,概率论)...实际工作中用到的只会让你调用一个第三方库,不会让你真的写一个加密算法.
密码学中几个重要的概念:
明文:要传输的数据,要表达的实际意思.
密文:针对明文加密后,得到的结果,往往是不直观的,不容易理解的.

例如:古代,写了一封密文,需要带有窟窿的纸才可以解读.这种称为"密钥".
这种叫对称加密:加密和解密使用的是同一个密钥.
非对称加密:加密和解密,用的是两个密钥.这两个密钥K1,K2 是成对的.
可以用K1来加密,K2就是解密.
也可以用K2来加密,K1就是解密.
两个密钥就可以一个公开出去,一个留在自己手里.

1.引入对称加密

1.对称加密的时候, 客户端和服务器需要使用同一个密钥.
2.不同的客户端, 需要使用不同的密钥.
(如果所有的客户端密钥都相同,加密形同虚设,黑客很容易拿到密钥)
这就意味着,每个客户端连接到服务器的时候, 都需要自己生成一个随机的密钥,并且把这个密钥告知服务器(也不一定非得是客户端生成,服务器生成也行,也是需要告诉给客户端的)
这就是问题的关键!!! 密钥需要传输给对方的..一旦黑客拿到了这个密钥,意味着加密操作就无意义了


2.引入非对称加密
使用非对称加密,为的就是对对称密钥进行加密,确保对称密匙的安全性.


这样,因为对888888密钥进行了非对称加密,所以就算黑客拿到了888888这个密钥,他也不知道是888888这个密钥,只有持有非对称加密的解密钥匙才可以打开这个加密的密钥,从而知道是888888密钥.然后知道了是888888密钥以后,就可以用888888密钥的对称解密钥匙读取内容.
为什么不直接用非对称加密内容传输??
虽然这种传输很安全,但是解密需要的资源太多,不适合.

上述操作下,仍然存在重大的安全漏洞,黑客仍然是有办法获取到对称密钥 key 的~~中间人攻击!!

针对上述问题,如何解决?
最关键的一点,客户端拿到公钥的时候,要能有办法验证,这个公钥是否是真的,而不是黑客伪造的.
要求服务器这边要提供一个"证书"
证书是一个结构化的数据(里面包含很多属性,最终以字符串的形式提供)证书中会包含一系列的信息.
比如,服务器的主域名,公钥, 证书有效期.….
证书是搭建服务器的人,要从第三方的公正机构进行申请的~~(申请的时候当然要提交材料,人家要审核)

此处所谓的"签名"本质上是一个经过加密的校验和!!
把证书中其他的字段通过一系列的算法(CRC, MD5 等),得到一个较短的字符串.=>校验和如果两份数据内容一样,此时校验和,就一定是相同的.如果校验和不同,两份数据的内容则一定不同.(逆否命题).

防止黑客篡改, 而不是防止黑客知道~~黑客的系统也内置了公证机构的公钥
黑客也能解密~~
但是黑客无法修改证书的内容!!!