分布式共识算法目标
分布式主要就是为了解决单点故障。一开始只有一个服务节点提供服务,如下图所示。那么如果服务节点挂了,对不起等着吧。
为了服务的高可用性,我们一般都会多引入几个副节点当备份,当服务节点挂了,就把其中一个副节点升级为主节点。如下图所示。

可是这样就出现了新的问题。当主节点宕机了,让谁来当新的主节点呢?如果新任的主节点本身就也是不可用的,那怎么办呢?为了解决这个问题。我们又会将节点分成数据节点和管理节点,由管理节点来统一管理数据节点。

现在服务节点高可用了,但是管理节点呢,又出现单点问题了,怎么办,好办,管理节点也做高可用,可是难道要给管理节点再增加管理管理节点吗?那就不成了俄罗斯套娃。

所以就要想一个新的办法。不引入新的管理节点,就能自动完成主节点的选举呢?这就是共识算法。简单来说共识算法就是投票,主节点或者说处理客户端请求的节点由集群中所有的服务器投票得出(更准确的说有投票权的服务器投票得出)。如果得票得到了半数以上,就可以成为主服务节点。这样就有一个保证,如果集群中有半数以上的服务器是可用的,那么我的服务就可用。

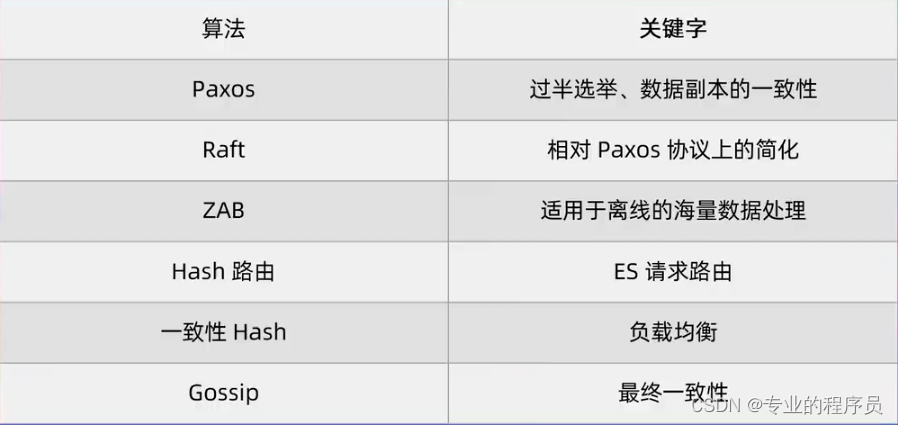
主要算法
Paxos算法:1990Lamport提出,由于晦涩难懂,一直到1998年其论文才得以发表。但是目前常见的三种共识算法核心依然是Paxos。这三种算法分别是:
1、Multi Paxos:常见于工业领域;
2、ZAB:由开源社区提出Paxos算法变种,使用代表Zookeeper;
3、Raft:2014年发表的Paxos更容易理解的一个算法;代表应用Redis;
以上这三种与最原始的Paxos算法有一个一致的改造点,就是设计了一个具有较长生命周期的leader。通俗一点就是原版的Paxos算法每次遇到问题都要进行一次选举而三个变种在一次选举之后就会固定一个leader,直到这个leader挂了。
除此以外,还有其他的分布式共识算法,比如ES中的Hash路由算法,HaProxy中的一致性Hash算法等等。
Paxos算法
主要角色
- Proposer : 提议者,在整个流程中提出一个序号和value,供Acceptor来决定
- Acceptor:对提议者提出的序号与value进行投票,只有在达到多数派时提议才会最终被接受
- Learners:提议接受者,对集群一致性没有影响,主要是记录结果
- 在具体的实现中,一个进程可能同时充当多种角色。比如一个进程可能既是Proposer又是Acceptor又是Learner。
选举流程
主要分成两个阶段,但是要注意的是并不是两个阶段就结束了,可能反复进行这两个阶段直到达成一致。
prepare阶段:这里又分成两个小部分
1、prepared :由proposer,也就是提议者提出一个proposal,就是一个提议,编号为N(数字,递增的,大于等于之前所有已经提出的编号)。将这个提议向所有的Acceptor广播。注意,此时只会有一个编号传递;
2、promise: acceptor 接收到了提议之后,如果N大于其之前接受的所有提案编号就接收否则拒绝。如果自身存在已经同意的提案就返回这个提案的编号和内容否则返回空值表示已经接受等待发送值过来;
accept阶段:
1、accept(N,value)请求:又回到proposer,之前广播出去的提议编号,当收到多数派(也就是多于一半的Acceptor返回promise),如果存在编号大的议案(肯定携带了value1)返回就进行更新value1,否则返回本次议案的value(这个value是新产生的)
2、accepted(N)返回:再次把选择权给到Acceptor,没有发现比传递过来的编号N更大的提案时就接受提案内容,否则就拒绝;
3、当proposor收到超过半数的acceptor的返回值以后,达成共识。
例子
为了能够更容易理解,我们来举一个例子。比如抗美援朝战场上,我方三个团(A,B,C)已经把联合国军一个团从三面围住,如果单一一个团发起进攻,胜算不大,必须要至少两个团同时发起进攻。此时无线电通讯已经被掐断,必须通过传信兵传信这种最古老的方式来传递信息,现在这三个团要达成一个共识就是何时一齐发起进攻这样才能大大减少本方的伤亡。用paxos算法来实现如下:
1、A团参谋长(proposorA)发送一个编号1给A、B、C团;
2、A团团长马上回复一个promise给A团参谋长,表示已收到;
3、B团,C团团长在收到传令兵的传令后,也回复promise;
4、A团参谋长在收到超过半数的promise后,再次发送编号1+进攻时间(凌晨2点)给A、B、C团;
5、A、B、C团收到编号1,发现这期间没有更大的编号信息传递过来,就接受编号1的进攻时间(凌晨2点),并返回accepted给A团参谋长;
6、A团参谋长在收到了半数以上的accepted之后,把进攻时间最终定格为凌晨2点,并再次将进攻时间下发给Learners,让其记录结果。
以上,只要A、B、C团三个团中,有两个团发送了accepted给proposorA,就达成了一致。进攻的时候至少会有两个团同时发起进攻。此时要注意,并不需要所有的Acceptor都接受提议。
ZAB算法
主要角色
1、领导者(Leader):
2、跟随者(Follower):
目标通过选举,选举出一个领导者,这个Leader会对接客户端提供读写服务,而所有的follower节点只提供读服务。
还有一个角色叫观察者,和选举没有关系我们就不说了。
选举流程
ZAB的leader选举有一个选举优先级,就是epoch > counter > sid
epoch是任期的意思,我们可以理解成第几任leader,已zooker为例,一个服务刚起来之后,每个节点上的epoch都是0;counter记录了事务的index,也就是事务的编号,是不断增长的,刚启动的时候也都是0;sid就是节点自身的编号。
现在假设我们有S0(sid=0)、S1(sid=1)S2(sid=2)三个节点。
1、加上S0先运行起来了,那么先给自己投一票,同时广播给其他节点希望其他节点把票投给自己;
2、S1启动起来了,同样先给自己投一票,此时S0和S1都是一票,但是S1收到了S0的拉票请求,我们根据 epoch > counter > sid 规则,S1发现自己的sid更大,于是拒绝投票并且也广播给其他节点拉票;
3、此时S0收到了S1的拉票请求后,发现其sid比自己大,于是把票投给了S1,这样S1就有了两票,超过了半数,成为了leader,同时将自己的epoch值加1,从0变成了1,并广播给所有follower节点同步。S0成为follower节点,同步自己的epoch为1
4、S2启动起来,发现已经存在leader节点了,那么自动成为follower节点,同步自己的epoch为1
数据同步流程
1、 leader节点S1在本地写入了一个事务log,发起一个事务,事务编号为1,此时自身的counter变成了1。S1先发起一个prepare请求广播给其他节点;
2、S0收到了S1的事务1的请求,并且也在本地写入了一个事务日志,同时返回成功给S1。S1发现已经超过半数的节点写入了日志,那么就先将本地的事务1提交,同时发起广播让follower节点提交事务1;
3、S2直接收到了S1的提交事务请求,也提交本地的事务1。
这里事务的发出与响应是有顺序的,事务编号1先发送,得到响应之后再发送事务编号为2的事务。这样就保证了事务的有序性。
例子
我们还是使用抗美援朝的例子,我方的是三个团分别有一个编号(380团 381团 和382团),这次不仅仅要确定进攻的时间,还需要确定炮火准备的时间。
选举leader节点:
1、380团 381团 和382团各自给自己投了一票,同时派遣传令兵去其他两个团传递信息,并拉票;
2、380团 获得了381团的拉票信息,发现其编号比自己大,就给381团投了一票;
3、382团 获得了381团的拉票信息,发现编号不如自己,就拒绝了381团的拉票请求;
4、此时关键在于381团,381团如果先收到了380团的投票请求,那么自己就成了leader,同时告知382团leader已经产生,让其自动生成follower;如果381团先收到了382团的拉票请求,那么自己先把投给自己的票去除,再投票给382团,最终382团成为leader。
发送信息:假设上一步是382团成为leader
1、382团发送第一个事务,事务编号 00010001,内容是凌晨2点进攻。382团先把内容记在了本子上;并派遣传令兵告知380团与381团
2、380团收到内容,也记在了自己的本子上,并回复:收到事务00010001,已经记录;381团也是如此;
3、382团在收到了380团的确认回复后,先把自己本上记录的00010001的内容打上一个√,再遣传令兵告知380团与381团事务提交。
4、380和381团在收到了事务提交指令以后,分别在自己的小本本上也打上一个√。
5、382团发送第二个事务,事务编号00010002,内容是炮火准备开始时间为凌晨1点,流程与之前一样。
Raft算法
主要角色
1、Follower:Follower是请求的被动更新者,从Leader接收更新请求,将日志写入本地文件中;
2、Candidate: 候选人,如果Follower在一定时间内,没有收到Leader的心跳,就判定Leader已经挂了,就把本身节点切换成Candidate,并尝试发起选主流程;
3、Leader:所有请求的处理者,接收客户端发起的操作请求,写入本地日志后,同步至其他Follower节点。
选举过程
0、S1、S2、S3三个节点,term值都是1
1、每个节点都维护了一个term字段,和ZAB中的epoch字段类似,是一个不断增长的数字,代表了第几次选举。假设S1节点先超时切换成了Candidate节点之后,term值先加1变成2,,然后先给自己投一票,同时向S2和S3发送RPC请求,发起投票选举;
2、此时集群中只有一个候选人,那么S2、S3同意投票,同时把自身的term值改成2。
3、S1收到了投票后,超过了半数就把自己的节点切换成Leader节点,并且开始不断地给其他节点发送心跳;
4、当某个节点长时间没有收到Leader节点的心跳时,就重复1-3步重新选举。
投票分裂
上述是理想状态下的情况,但是也有可能出现投票分裂的情况。例如目前有S1-S5五个节点,term值都是2。其中S1节点本来是Leader节点,挂了。此时S2和S3同时达到了超时时间,同时把自己变成候选人(Candidate),term值也同时加1都变成了3,这样集群中就出现了两个候选人。
两个候选人(S2,S3)会都先给自己投1票,然后发送RPC拉票请求。此时S4和S5在分别收到了S2和S3的请求时,一个投给了S2,一个投给了S3。由于候选人之间term相同的情况下是不会给对方投票的,这样S2与S3就都有两票且没有过半数。这就出现了投票分裂的情况。
解决方法:由于Leader节点没有选出,那么还会有新的节点超时,此时S4超时并把自己变成候选人(Candidate),term值加1变成了4,并广播RPC投票请求,此时S2和S3虽然也是候选人但term值小与S4,故而把票投给了S4,这样S4的得票数就超过了半数,成了Leader。
日志复制过程
这里日志的复制和状态转化的过程和ZAB基本一致,就不详细说了,大致的流程还是Leader节点顺序向本地写入日志,并顺序的发送日志给follower节点,当得到超过半数的follower节点的应答后,就把本地这条日志状态改为已提交,并通知给所有follower节点修改这条日志的状态。
数据一致性(leader强一致性)
每个节点都会维护自己的日志列表,并有两个index值,一个叫match Index表示已经检查与leader节点的日志一致的最大index位置,一个叫next index标示下一条新的日志将要写入的位置。
当一个节点变成了Leader节点后,首先会检查各节点和自己维护的日志列表是否一致,比如自己的日志已经写到了index=3的位置,那么就要检查各节点是否都有一个index=3的日志且数值和自己相同(会发起一个日志检查的RPC请求)。如果收到的应答是不一致的,就更新follower节点的日志
数据安全性
leader的强一致性有一个问题,如果一个节点的日志列表数据少于其他节点,比如S5的日志列表是3条,其他的S1-S4都是5条,那么如果S5成为了leader,按照强一致性原理就会把S1-S4的第四条与第五条日志抹除,这样就造成数据的不安全。所以此时S1-S4都会拒绝给S5投票,这样保证数据的安全性
这里是动画演示:
https://raft.github.io/raftscope-replay/index.html
RAFT就不举例子了,上面已经描述的比较清晰了(笔者自认为)