原文链接:https://www.techbeat.net/article-info?id=4467
作者:seven_
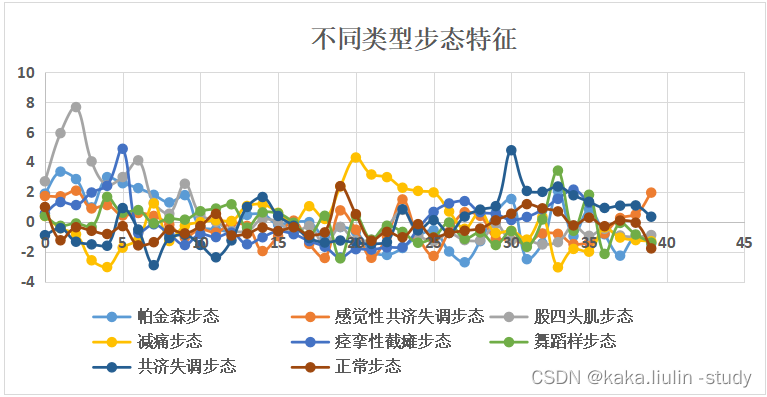
视频字幕生成目前已成为工业界AI创作领域非常火热的研究话题,这一技术可以应用在短视频的内容解析和讲解中,AI讲故事的技术已经越来越成熟。而在学术界,研究者们更加倾向于探索字幕生成的评价标准以及可扩展性。

论文链接:
https://arxiv.org/abs/2211.15103
代码链接:
https://github.com/UARK-AICV/VLTinT
本文介绍一篇刚刚被人工智能领域顶级会议AAAI2023录用的文章,该文不再局限于传统的短视频字幕生成任务,而是在此基础上更进一步探索视频段落字幕概括任务。视频段落字幕生成任务要求模型对未处理的一段长视频生成概况性的文字描述,且该视频中所描述的连贯故事严格遵循一定的时间位置。这要求模型具有很强的时空事件提取能力,本文由美国阿肯色大学和卡内基梅隆大学合作完成。
作者遵循人类观看视频时的感知过程,通过将视频场景分解为视觉(例如人类、动物)和非视觉成分(例如动作、关系)来层次化的理解场景,并且提出了一种称为Visual-Linguistic(VL)的多模态视觉语言特征。在VL特征中,一个完整的视频场景主要由三种模态进行建模,包括:
- 代表周围整体场景的全局视觉环境表征
- 代表当前发生事件的局部视觉主体表征
- 描述视觉和非视觉元素的语言性场景元素
作者设计了一种自回归Transformer结构(TinT)来对这三种模态进行表征和建模,可以同时捕获视频中事件内和事件间内容的语义连贯性。为了更加高效的训练模型,作者还配套提出了一种全新的VL多模态对比损失函数,来保证学习到的嵌入特征与字幕语义相匹配,作者在多个段落级字幕生成基准上对模型进行了评估,结果表明本文方法在字幕生成的准确性和多样性方面性能达到SOTA!
一、引言
视频字幕生成任务来源于图像字幕生成任务,其中一个最主要的分支是密集视频字幕生成(Dense Video Captioning,DVC),在DVC的任务设定中,模型需要按照时间顺序生成事件列表,并对每个事件生成相关的句子描述,以此来保证视频字幕的语义连贯。作为DVC的简化版本,视频段落字幕(Video Paragraph Captioning,VPC)的目的是对给定的视频生成概括性的段落描述,从而简化事件解析和描述的流程。
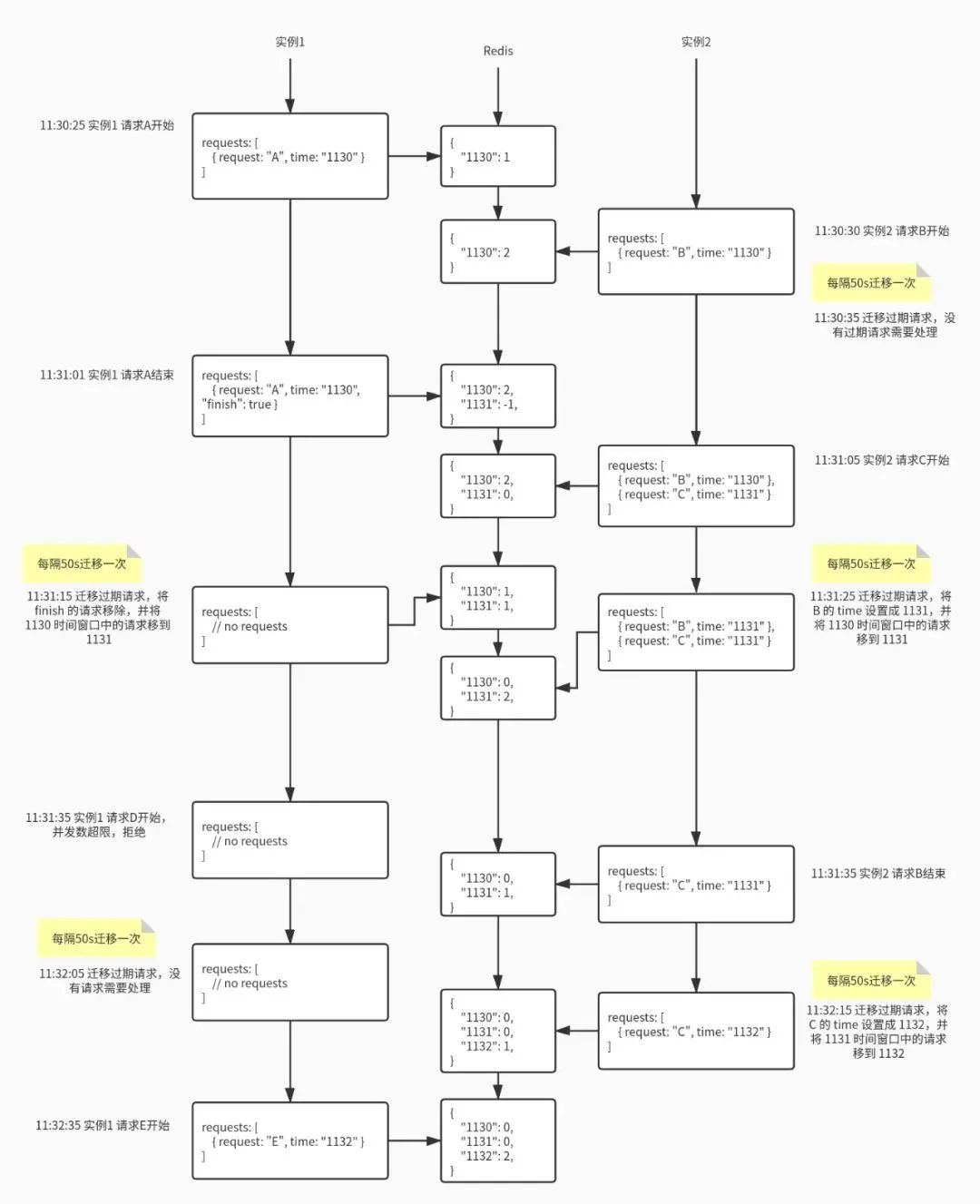
通常来说,VPC模型由两个主要组件组成,即一个编码器对视频的每个事件产生一个特征表示,随后送入到一个解码器来生成相关字幕。之前的VPC方法大多使用一个基于CNN的黑盒网络来对视频特征进行编码,这种做法可能会忽略视频中视频和语言模态之间的交互。本文提出的VLTinT模型将视频场景分解为三种模态,以达到对视频中视觉和非视觉元素的细粒度描述。此外,为了关注对当前事件具有核心影响的主要代理主体,作者对其加入了混合注意机制(Hybrid Attention Mechanism,HAM)进行学习。下图展示了本文所提VLTinT模型与其他常规方法的对比。
在VPC任务中,模型需要对每个事件都生成一句话描述,并且这些话在逻辑上应该是相互关联的,因此非常有必要对视频中的两种依赖关系进行建模,即事件内和事件间的依赖关系。之前的方法往往使用基于RNN的方法来对事件内的一致性进行模拟建模,但随着Transformer技术在自然语言领域中的迅猛发展,这一结构逐渐被自注意力块所取代,例如上图中展示的Trans.XL和MART方法。但是在这些方法中,每个事件依然是独立解码,没有考虑事件间的一致性,为了应对这一挑战,本文作者提出了一个全新的Transformer in Transformer架构(TinT),TinT Decoder可以同时兼顾一段视频中事件内和事件间的依赖关系建模。相比之前方法简单的使用最大似然估计损失(MLE)来训练模型,作者引入了一个新的多模态VL对比损失来保持在训练过程中对视觉和语言语义的学习,而不增加额外的计算成本。
二、本文方法
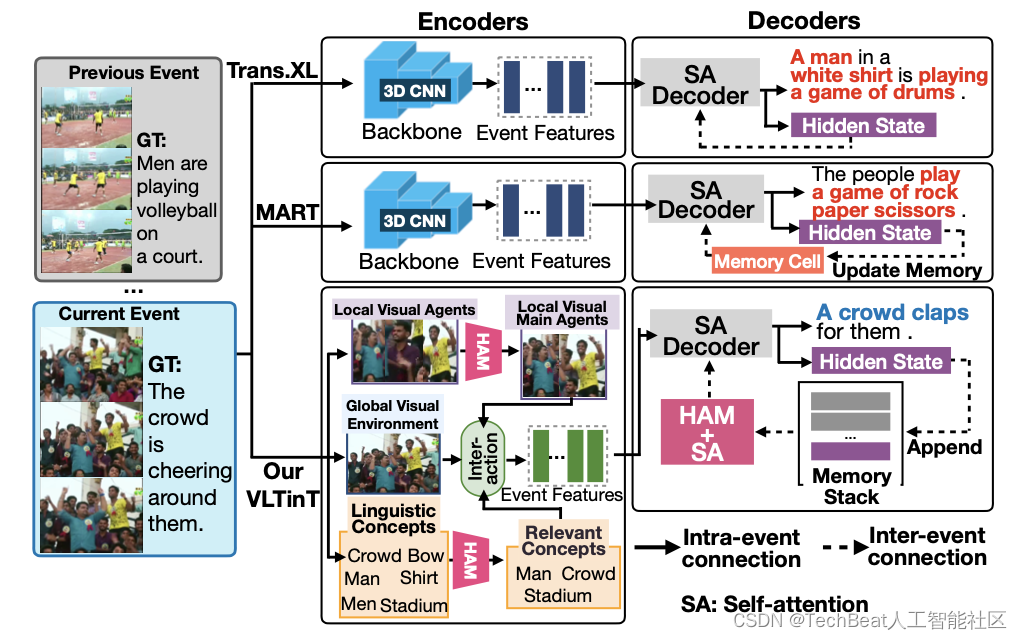
本文的VLTinT由两个主要模块构成,分别对应一个编码器VL Encoder和解码器TinT Decoder。其中VL Encoder主要负责对一段视频中的不同事件提取特征表示,而TinT Decoder主要负责对这些特征进行解码生成每个事件的文字描述,同时对事件内和事件间的一致性进行建模。这两个模块都通过本文提出的VL对比损失以端到端的方式进行训练,VLTinT的整体架构如下图所示,下面我们将详细介绍每个模块中的技术细节。
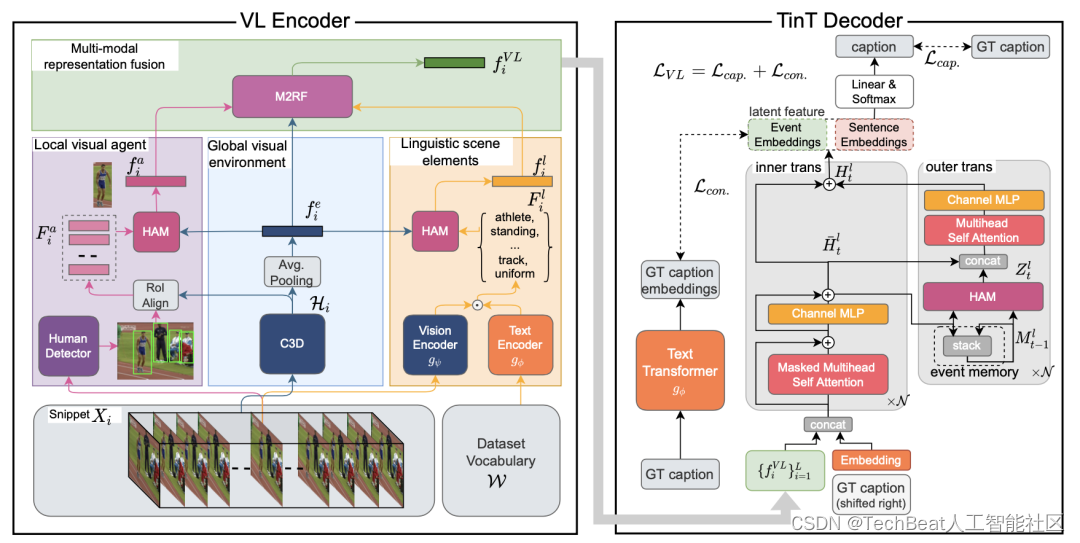
2.1 Visual-Linguistic编码器
在VPC任务中,首先给定一个未修剪的视频 V = { v i } i = 1 ∣ V ∣ \mathcal{V}=\left\{v_{i}\right\}_{i=1}^{|\mathcal{V}|} V={vi}i=1∣V∣ ,其中 ∣ V ∣ |\mathcal{V}| ∣V∣ 是帧数,其中包含重要事件的列表为 E = { e i = ( e i b , e i e ) } i = 1 ∣ E ∣ \mathcal{E}=\left\{e_{i}=\left(e_{i}^{b}, e_{i}^{e}\right)\right\}_{i=1}^{|\mathcal{E}|} E={ei=(eib,eie)}i=1∣E∣ ,其中 ∣ E ∣ |\mathcal{E}| ∣E∣ 是视频中的事件数,事件 e i e_{i} ei 由一对开始和结束时间戳定义 ( e i b , e i e ) \left(e_{i}^{b}, e_{i}^{e}\right) (eib,eie) 。VPC的目标是生成一个可以与整个视频 V \mathcal{V} V 真实段落相匹配的连贯段落 P = { s i } i = 1 ∣ E ∣ \mathcal{P}=\left\{\mathbf{s}_{i}\right\}_{i=1}^{|\mathcal{E}|} P={si}i=1∣E∣ 。VL编码器负责将事件的每个片段 X i X_{i} Xi 综合编码为一个代表性特征,从而为解码器构成一系列段落级特征。例如给定事件 e = ( e b , e e ) e=\left(e^{b}, e^{e}\right) e=(eb,ee) 及其对应的视频帧 V e = { v i ∣ e b ≤ i ≤ e e } \mathcal{V}_{e}=\left\{v_{i} \mid e^{b} \leq i \leq e^{e}\right\} Ve={vi∣eb≤i≤ee},作者遵循现有标准设置对 V e \mathcal{V}_{e} Ve 进行划分。每个片段 X i X_{i} Xi 由 δ \delta δ 个连续帧组成, V e \mathcal{V}_{e} Ve 总共有 L = ⌈ ∣ V e ∣ δ ⌉ L=\left\lceil\frac{\left|\mathcal{V}_{e}\right|}{\delta}\right\rceil L=⌈δ∣Ve∣⌉ 个片段。如上图左半部所示,VL编码器模块将每个片段 X i X_{i} Xi 编码为 f i V L f_{i}^{V L} fiVL 。
在具体的编码过程中,作者首先对三种模态数据分开建模,随后根据它们之间的相互作用将其融合成一个综合表示,具体来说,给定一个片段 X i X_{i} Xi ,它被编码为三种模式,分别对应于 f i e f_{i}^{e} fie 、 f a i f_{a}^{i} fai 和 f l e i f_{l}^{ei} flei 。然后通过多模态表征融合(Multi-modal Representation Fusion,M2RF)模块得到代表交互的最终特征 f i V L f_{i}^{V L} fiVL ,具体如下。
全局视觉环境表征
这种模态包含了输入片段
X
i
X_{i}
Xi 的整个空间场景的视觉语义信息。作者使用预训练的3D-CNN作为骨干网络进行特征抽取,在网络的最后一个卷积块提取特征图
H
i
H_{i}
Hi 。然后通过对
H
i
H_{i}
Hi 进行平均池化操作以减少整个空间维度,并通过通道MLP来获得全局环境视觉特征
f
i
e
∈
R
d
e
m
b
f_{i}^{e} \in \mathbb{R}^{d_{\mathrm{emb}}}
fie∈Rdemb 。该过程形式化表达如下:
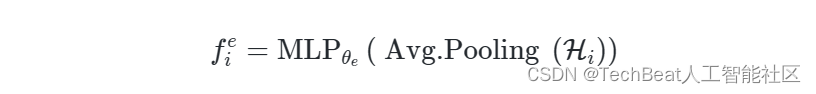
局部视觉主体表征
局部视觉主体作为事件的主要贡献对象,需要进行重点关注,但是需要注意的是,并非所有的主体动作都与事件片段的主要内容有关,因此作者首先对
X
i
X_{i}
Xi 的中心帧使用人体检测器进行检测来获得视觉主体的边界框,随后使用RoIAlign获取每个边界框的特征图,然后将这些特征图平均汇集到一个单一的特征向量中以代表该框内视觉主体的视觉特征。最后使用HAM来适应性地从检测到的主体中提取其中的相互关系,形成一个统一的代理感知的视觉特征
f
i
a
∈
R
d
e
m
b
f_{i}^{a} \in \mathbb{R}^{d_{\mathrm{emb}}}
fia∈Rdemb ,具体操作如下:

语言场景元素
与前两种模态中包含的场景空间外观和主体对象的运动视觉信息相比,语言场景元素提供了额外的场景上下文细节。此外作者考虑到普通的视觉主干可能只会关注到视觉特征,而忽略掉一些与场景事件高度相关的非视觉信息,因此作者考虑使用对比语言图像预训练模型CLIP[1,2]来将非视觉文本与给定的图像进行关联,具体来说,作者为数据集构建一个词汇表
W
=
{
w
1
,
…
w
m
}
\mathcal{W}=\left\{w_{1}, \ldots w_{m}\right\}
W={w1,…wm} 。每个词汇表
w
i
∈
W
w_{i} \in \mathcal{W}
wi∈W 都被一个transformer网络
f
ϕ
f_{\phi}
fϕ 编码成一个文本特征
f
i
w
f_{i}^{w}
fiw ,如下图所示。
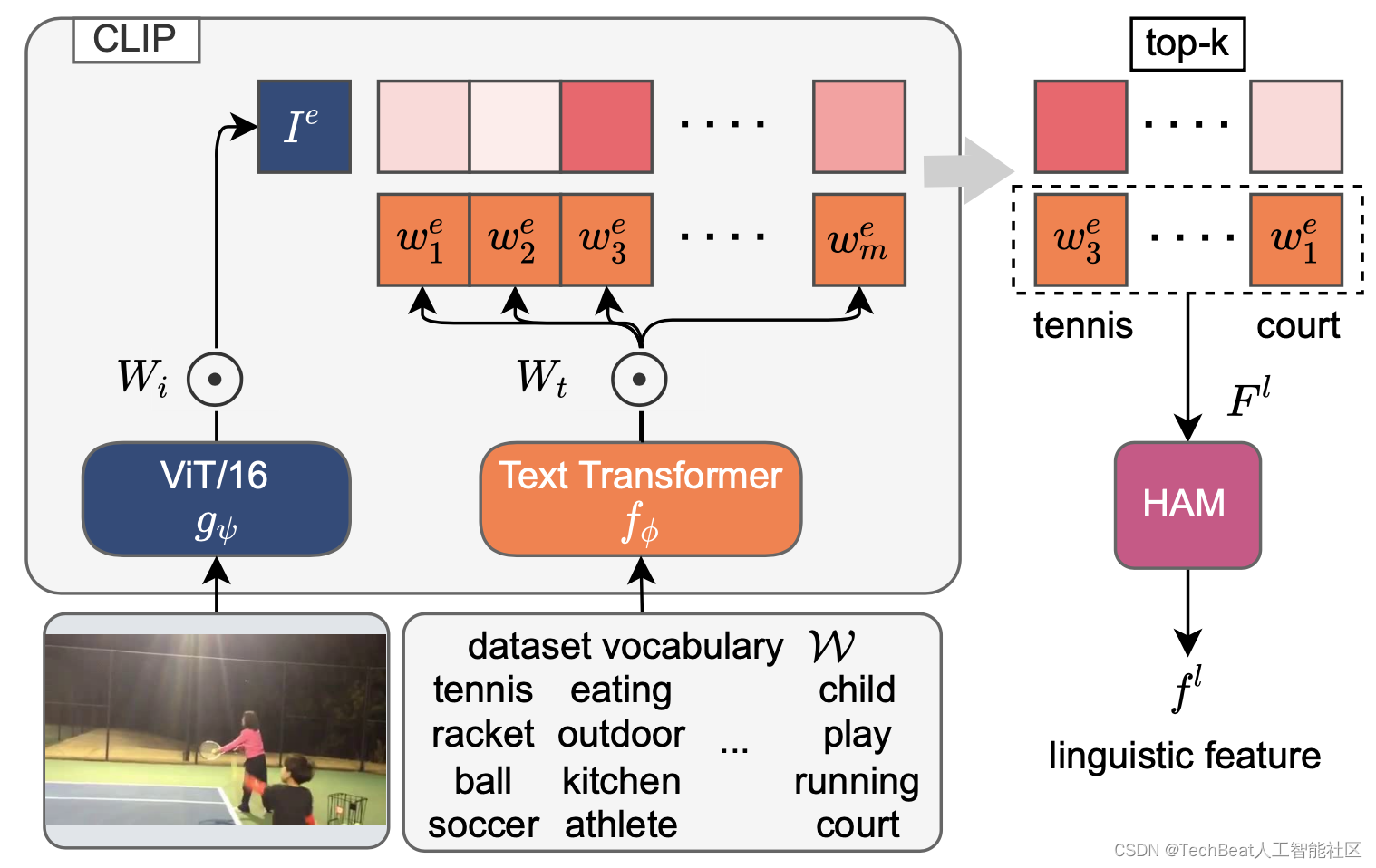
令
W
t
W_{t}
Wt 为CLIP预训练的文本投影矩阵,其中嵌入文本词汇计算过程如下:
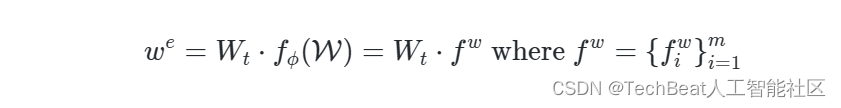
多模态表征融合M2RF模块
M2RF的作用是融合三种模态的特征,与目前常见的连接和求和方式不同,M2RF更着重于模拟每个单独模态对结果的影响,作者将M2RF形式化为一个函数
g
γ
g_{\gamma}
gγ ,它将特征
f
i
e
,
f
i
a
f_{i}^{e}, f_{i}^{a}
fie,fia 以及
f
l
i
f_{l}^{i}
fli 作为输入,然后通过自注意层来提取特征间的关系,然后再进行平均运算。给定一个片段
X
i
X_{i}
Xi ,其最终表示
f
i
V
L
∈
R
d
e
m
b
f_{i}^{V L} \in \mathbb{R}^{d_{\mathrm{emb}}}
fiVL∈Rdemb 如下:
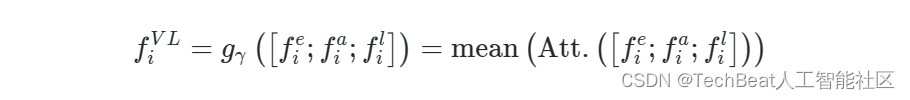
2.2 TinT解码器
TinT解码器的结构受视觉语言Transformer模型的启发,采用统一的编码-解码Transformer结构作为字幕生成器的基础。在这种设计原则指引下,视频特征
F
V
L
\mathcal{F}^{V L}
FVL 首先将VL编码器得到的所有片段特征进行串联,即
F
V
L
=
{
f
i
V
L
}
i
=
1
L
∈
R
L
×
d
cmb
\mathcal{F}^{V L}=\left\{f_{i}^{V L}\right\}_{i=1}^{L} \in \mathbb{R}^{L \times d_{\text {cmb }}}
FVL={fiVL}i=1L∈RL×dcmb 。其中文本标记
F
text
\mathcal{F}^{\text {text }}
Ftext 由来自CLIP的预训练文本编码器
g
ϕ
g_{\phi}
gϕ 和MLP层编码得到:
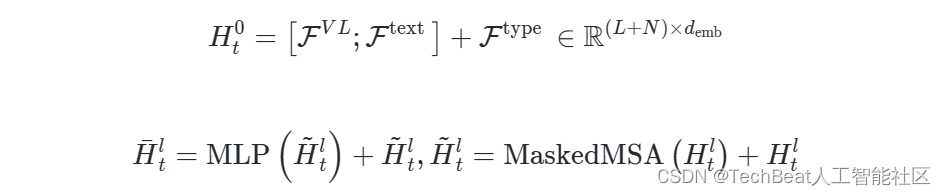
2.3 VL多模态对比损失
与之前方法使用的MLE损失相比,本文提出的VL对比损失在学习预测字幕与GT文本相匹配的基础上,利用对比学习的优势帮助模型对同一类事件的不同片段进行事件级的匹配对齐。本文提出的VL损失由两部分组成,分别对应字幕损失 L c a p . \mathcal{L}_{cap.} Lcap. 和对比性语境损失 L c o n . \mathcal{L}_{c o n.} Lcon. 。其中 L c a p . \mathcal{L}_{cap.} Lcap. 的目的是解码与GT相匹配的字幕,而 L c o n . \mathcal{L}_{c o n.} Lcon. 则保证学习到的潜在特征与GT字幕中编码的语义信息接近。
三、实验效果
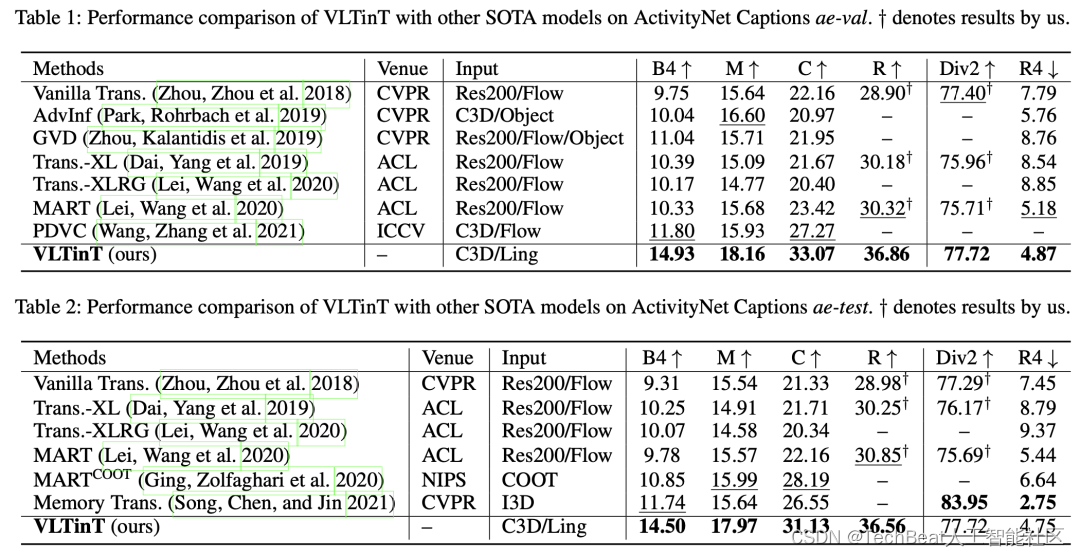
本文在两个流行的视频多事件数据集ActivityNet Captions和YouCookII上进行了基准侧测试,评价指标分为准确性和多样性两种。作者首先将VLTinT与之前的SOTA VPC方法进行了对比,实验结果如下表所示,其中作者突出显示了每个指标对应的最佳和次佳分数。与其他方法相比,本文的VLTinT在这两个方面都表现出了生成字幕的准确性和多样性。

此外,作者还展示了VLTinT与其他方法的可视化字幕生成对比,如下图所示,可以观察到,VLTinT可以生成更多具有细粒度细节的描述性字幕。特别地,作者观察到VTrans和MART更倾向于在其标题中使用高频词,而VLTinT可以使用富有表现力但出现频率较低的词,例如示例中的“A man”与“An athlete man”。这是因为VLTinT中的VL编码器可以更加全面的捕获场景中的其他视觉元素,这帮助模型更加全面的对场景进行理解。

四、总结
在这项工作中,作者针对视频段落级字幕生成任务(VPC)提出了一种新式的Transformer in Transformer结构,该结构由一个VL编码器和TinT解码器组成。值得注意的是,作者在VL编码器中首次对视频场景划分了三种独特模态进行分层次建模和学习,这种方式非常贴合人脑对视频数据的感知过程。这为社区在这一方面的研究树立了一个非常好的研究思路,此外,在TinT解码器中的自回归结构可以有效地学习视频中事件内和事件间的不同依赖关系,也帮助提高了模型的整体性能。作者在未来展望中提到,可以将VLTinT模型提取的多模态视频特征扩展到其他用途更广泛的密集视频字幕生成任务中,以提高AI视频制作的工作效率。
参考
[1] Patashnik, O.; Wu, Z.; et al. 2021. StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery. In ICCV, 2065–2074.
[2] Yang, B.; and Zou, Y. 2021. CLIP Meets Video Captioners: Attribute-Aware Representation Learning Promotes Accurate Captioning. ArXiv preprint, abs/2111.15162.
Illustration by IconScout Store from IconScout
-The End-
关于我“门”
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门-TechBeat技术社区以及将门创投基金。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”:
bp@thejiangmen.com