mamba(其对应论文为:https://arxiv.org/abs/2312.00752,这是其对应的GitHub代码地址:GitCode - 开发者的代码家园),在语言、音频、DNA序列模态上都实现SOTA,在最受关注的语言任务上,Mamba-3B超越同等规模的Transformer,与两倍大的Transformer匹敌,并且相关代码、预训练模型checkpoint都已开源
简言之,Mamba是一种状态空间模型(SSM),建立在更现代的适用于深度学习的结构化SSM (简称S6)基础上,与经典架构RNN有相似之处
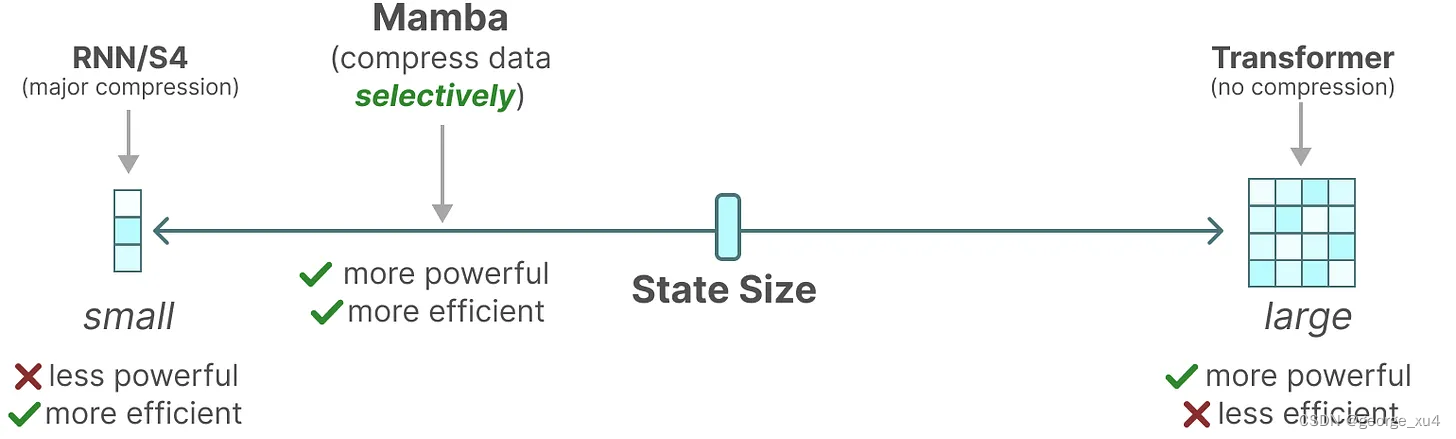
Mamba = 有选择处理信息 + 硬件感知算法 + 更简单的SSM架构
与先前的研究相比,Mamba主要有三点创新:
- 对输入信息有选择性处理(Selection Mechanism)
- 硬件感知的算法(Hardware-aware Algorithm)
该算法采用“并行扫描算法”而非“卷积”来进行模型的循环计算(使得不用CNN也能并行训练),但为了减少GPU内存层次结构中不同级别之间的IO访问,它没有具体化扩展状态
当然,这点也是受到了S5(Simplified State Space Layers for Sequence Modeling)的启发
3.更简单的架构
将SSM架构的设计与transformer的MLP块合并为一个块(combining the design of prior SSM architectures with the MLP block of Transformers into a single block),来简化过去的深度序列模型架构,从而得到一个包含selective state space的架构设计
选择性状态空间模型:从S4到S6
作者认为,序列建模的一个基础问题是把上下文压缩成更小的状态(We argue that a fundamental problem of sequence modeling is compressing context into a smaller state),从这个角度来看
- transformer的注意力机制虽然有效果但效率不算很高,毕竟其需要显式地存储整个上下文(storing the entire context,也就是KV缓存),直接导致训练和推理消耗算力大好比,Transformer就像人类每写一个字之前,都把前面的所有字+输入都复习一遍,所以写的慢
- RNN的推理和训练效率高,但性能容易受到对上下文压缩程度的限制On the other hand, recurrent models are efficient because they have a finite state, implying constant-time inference and linear-time training. However, their effectiveness is limited by how well this state has compressed the context.好比,RNN每次只参考前面固定的字数(仔细体会这句话:When generating the output, the RNN only needs to consider the previous hidden state and current input. It prevents recalculating all previous hidden states which is what a Transformer would do),写的快是快,但容易忘掉更前面的内容
- 而SSM的问题在于其中的矩阵A B C不随输入不同而不同,即无法针对不同的输入针对性的推理,详见上篇文章
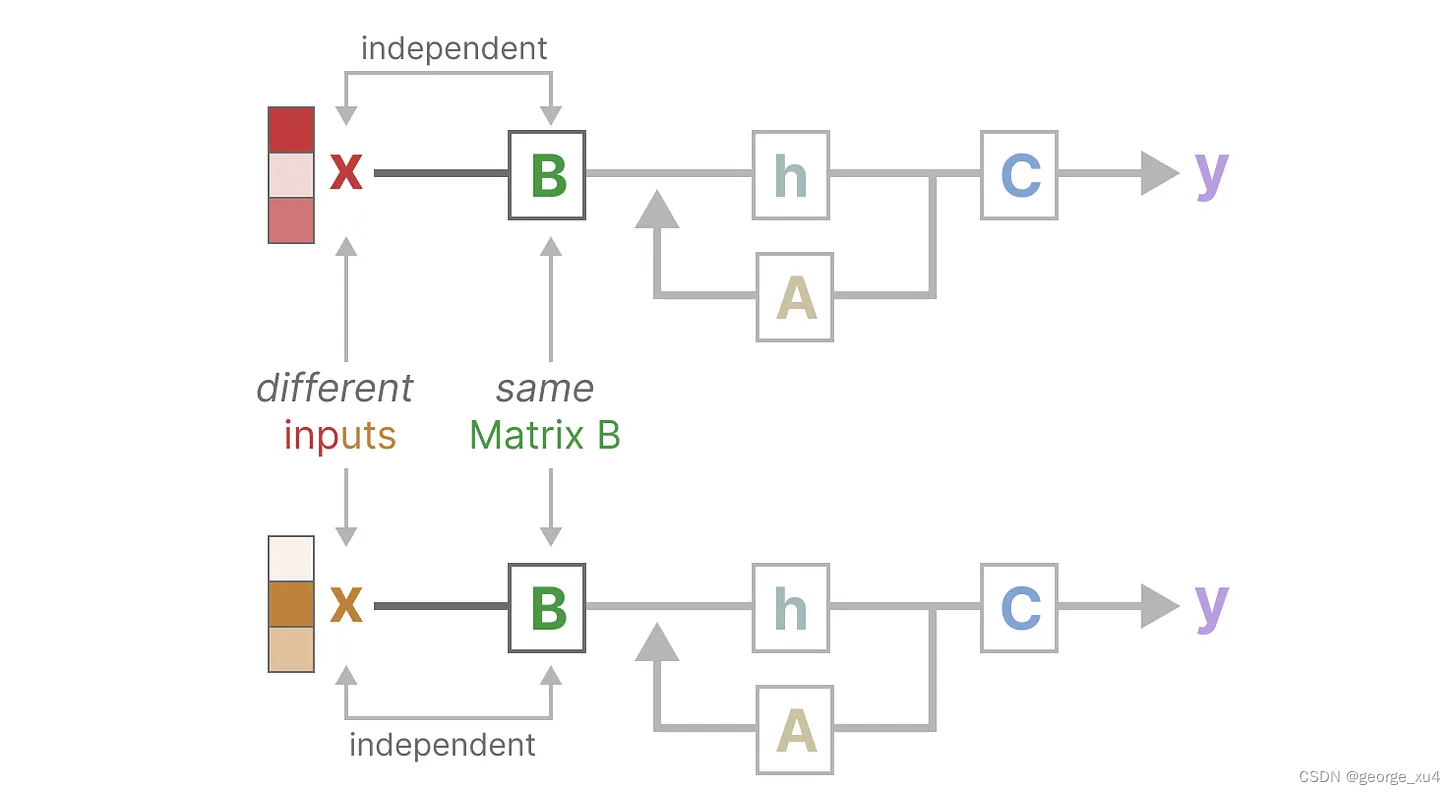
- 最终,Mamba的解决办法是,相比SSM压缩所有历史记录,mamba设计了一个简单的选择机制,通过“参数化SSM的输入”,让模型对信息有选择性处理,以便关注或忽略特定的输入这样一来,模型能够过滤掉与问题无关的信息,并且可以长期记住与问题相关的信息,好比,Mamba每次参考前面所有内容的一个概括,越往后写对前面内容概括得越狠,丢掉细节、保留大意
为方便大家对比,我再用如下表格总结下各个模型的核心特点
| 模型 | 对信息的压缩程度 | 训练的效率 | 推理的效率 |
| transformer(注意力机制) | transformer对每个历史记录都不压缩 | 训练消耗算力大 | 推理消耗算力大 |
| RNN | 随着时间的推移,RNN 往往会忘记某一部分信息 | RNN没法并行训练 | 推理时只看一个时间步 故推理高效(相当于推理快但训练慢) |
| CNN | 训练效率高,可并行「因为能够绕过状态计算,并实现仅包含(B, L, D)的卷积核」 | ||
| SSM | SSM压缩每一个历史记录 | 矩阵不因输入不同而不同,无法针对输入做针对性推理 | |
| mamba | 选择性的关注必须关注的、过滤掉可以忽略的 | mamba每次参考前面所有内容的一个概括,兼备训练、推理的效率 | |
总之,序列模型的效率与效果的权衡点在于它们对状态的压缩程度:
- 高效的模型必须有一个小的状态(比如RNN或S4)
- 而有效的模型必须有一个包含来自上下文的所有必要信息的状态(比如transformer)
而mamba为了兼顾效率和效果,选择性的关注必须关注的、过滤掉可以忽略的
为方便大家理解,再进一步阐述mamba与其前身结构化空间模型S4的优势
mamba前身S4的4个参数的不随输入不同而不同
首先,在其前身S4中,其有4个参数(∆, A, B, C)
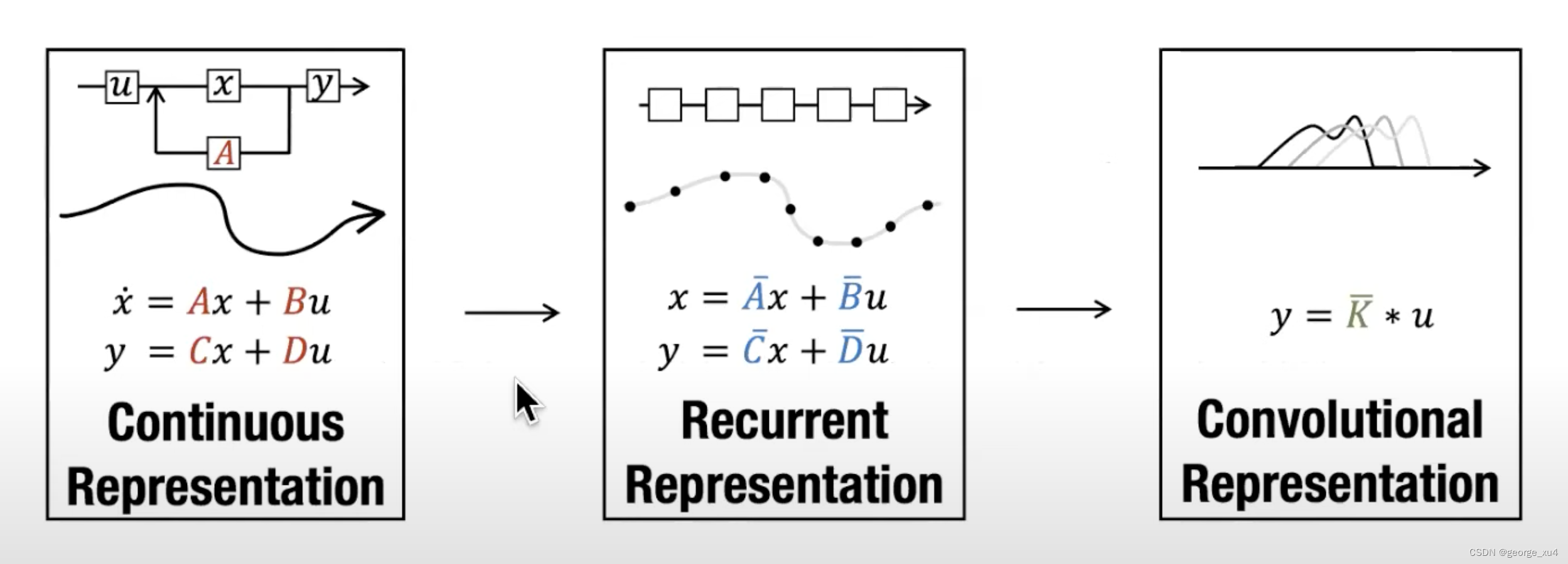
且它们不随输入变化(即与输入无关),这些参数控制了以下两个阶段
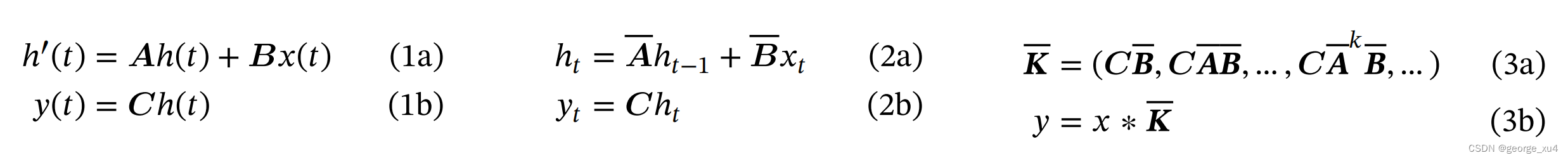
- 第一阶段(1a 1b),通常采用固定公式
和
,将“连续参数
”转化为“离散参数”
,其中
称为离散化规则,且可以使用多种规则来实现这一转换
The first stage transforms the “continuous parameters” (∆, A, B) to “discrete parameters” (A, B) through fixed formulas A = 𝑓&











![[大模型]Qwen-7B-Chat 接入langchain搭建知识库助手](https://img-blog.csdnimg.cn/direct/8e31bb780d2c4d90904223580e5b59cf.png#pic_center)