谢韦尔数据集
在kaggle上即可找到,在csdn、百度、知乎上搜索都能搜到,这里不附下载链接了
谢韦尔数据集的标注为CSV文件,格式如下:
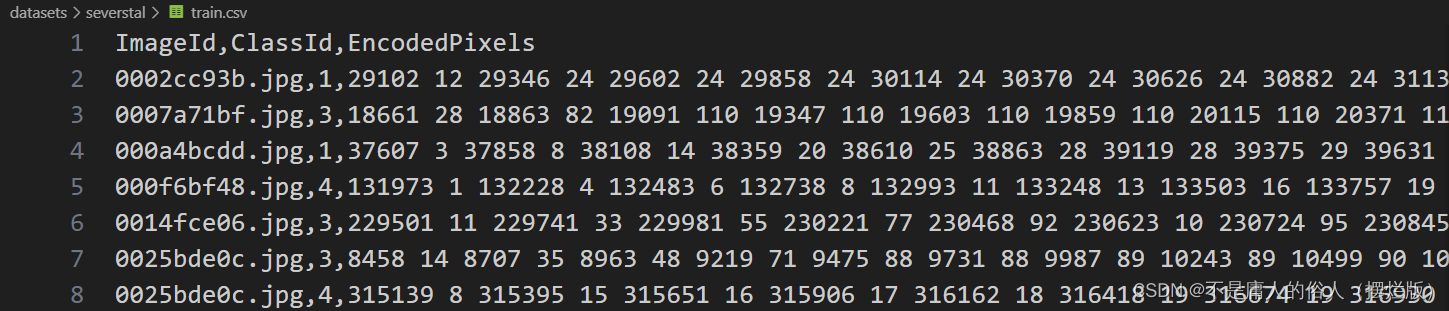
谢韦尔数据集为分割数据集,像素编码格式
格式
谢韦尔数据集为像素编码格式,使用YOLO相关模型进行检测任务,需要进行格式转换。
YOLO的格式为:
类别id 坐标1x 坐标1y 坐标2x 坐标2y 坐标3x 坐标3y 坐标4x 坐标4y…
像素编码格式为:
29102 12 ,为一对,从第29102开始往后数12个像素。
要直接转成YOLO格式的顶点坐标有点困难,所以我采用了先转换为掩码形式,然后再寻找顶点。
处理代码
import os
import cv2
import numpy as np
import pandas as pd
from PIL import Image
from PIL import Image, ImageOps
def mask_pil2xy(mask_pil,ImageId,ClassId,save_txtfolder):
# 转换为 NumPy 数组
mask_np = np.array(mask_pil)
# 使用阈值化将图像转换为二值图像
_, binary_image = cv2.threshold(mask_np, 200, 255, cv2.THRESH_BINARY)
# 查找轮廓
contours, _ = cv2.findContours(binary_image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 存储有效区域的顶点坐标
valid_vertices = []
# 设置最小轮廓点数阈值(根据需要调整)
min_contour_points = 3
label_name=os.path.splitext(ImageId)[0]+ ".txt"
save_path = os.path.join(save_txtfolder, label_name)
#保存到文件
with open(save_path, 'a') as f:
# 遍历每个轮廓
for contour in contours:
# 忽略太小的轮廓
if len(contour) < min_contour_points:
continue
# 获取轮廓的顶点坐标
approx = cv2.approxPolyDP(contour, 0.01 * cv2.arcLength(contour, True), True)
# 确保轮廓有足够的顶点来形成有效区域
if len(approx) >= min_contour_points:
# 存储当前区域的顶点坐标
# vertices_str = ""
vertices_str = f"{ClassId} "
for point in approx:
x, y = point[0]
# 归一化顶点坐标并保留小数点后6位
normalized_x = round(x / 1600, 6)
normalized_y = round(y / 256, 6)
vertices_str += f"{normalized_x} {normalized_y} "
# 移除末尾的空格
vertices_str = vertices_str[:-1]
# 将当前区域的顶点坐标字符串添加到列表中
valid_vertices.append(vertices_str + "\n")
# 输出所有有效区域的顶点坐标
for vertices_str in valid_vertices:
print(vertices_str)
f.write(vertices_str)
def rle2mask(rle, imgshape):
width = imgshape[1]
height = imgshape[0]
mask = np.zeros(width * height, dtype=np.uint8)
array = np.asarray([int(x) for x in rle.split()])
starts = array[0::2]
lengths = array[1::2]
for index, start in enumerate(starts):
mask[int(start):int(start + lengths[index])] = 1
# 将掩码数组重塑为图像尺寸
mask = mask.reshape(height, width)
# 将 numpy 数组转换为 PIL 图像
mask_pil = Image.fromarray(mask * 255)
# 旋转图像以横向显示(逆时针旋转90度)
mask_pil = mask_pil.rotate(90, expand=True)
# 保存掩码图像前进行垂直翻转
mask_pil = ImageOps.flip(mask_pil)
return mask_pil
#路径
# 设置保存标签文件的路径
save_txtfolder = ""
os.makedirs(save_txtfolder, exist_ok=True) # 确保保存目录存在
save_folder = ""
os.makedirs(save_folder, exist_ok=True) # 确保保存目录存在
# 读取CSV文件
csv_path = ""
df = pd.read_csv(csv_path)
# 过滤出带有有效掩码的数据
df_train = df[df['EncodedPixels'].notnull()].reset_index(drop=True)
# 处理每个带有有效掩码的样本
for index in range(len(df_train)):
ImageId = df_train['ImageId'].iloc[index] # 获取图像标识
ClassId = df_train['ClassId'].iloc[index] # 获取类别 ID
maskName = ImageId.split(".")[0] + ".png" # 生成保存的掩码文件名,去除后缀并添加文件扩展名
# 生成掩码图像
mask_pil = rle2mask(df_train['EncodedPixels'].iloc[index], (1600, 256))
mask_pil2xy(mask_pil,ImageId,ClassId,save_txtfolder)
save_path = os.path.join(save_folder, maskName)
mask_pil.save(save_path)
print(f"Saved mask image: {save_path}")
上述内容为作者原创,转载请附上链接