文章目录
- 一 顺序表
- 代码:
- 二 链表
- 单链表
- 双向链表
一 顺序表
顺序表是线性表的一种
所谓线性表指一串数据的组织存储在逻辑上是线性的,而在物理上不一定是线性的
顺序表的底层实现是数组,其由一群数据类型相同的元素组成,其在逻辑与物理上均是线性的。
代码:
对于顺序表的结构及各种操作函数的声明

#define _CRT_SECURE_NO_WARNINGS 1
#include <assert.h>
#include<string.h>
#include<stdlib.h>
#include<string.h>
#include<assert.h>
//顺序表的声明
typedef int Datatype; //规定顺序表的基本元素是什么类型
struct SeqList {
Datatype* arr; //顺序表空间的首地址
int size; //顺序表中当前元素的个数
int capacity; //顺序表当前所申请的空间个数,单位为数据类型大小
};
//初始化一个顺序表的声明
void Initialize(struct SeqList* ps);
// 插入数据操作
//尾插法
void TailInsert(struct SeqList* ps, Datatype x);
//头插法
void HeadInsert(struct SeqList* ps, Datatype x);
//在指定位置插入数据
void RanInsert(struct SeqList* ps, int pos, Datatype x);
//删除数据操作
//头删法
void HeadDelete(struct SeqList* ps);
//尾删法
void TailDelete(struct SeqList* ps);
//在指定位置删除数据
void RanInsert(struct SeqList* ps, int pos);
//查找数据,返回下标
int Select(struct SeqList* ps, Datatype x);
//删除顺序表的声明
void DeleteList(struct SeqList* ps);
对于顺序表及各种操作函数的实现:

#include "seqlist.h"
// 初始化一个顺序表
void Initialize(struct SeqList * ps) {
//初始化地址
ps->arr = NULL; //NULL在文件string.h中定义
ps->size = ps->capacity = 0;
}
// 判断空间是否够用,不够的话申请空间
void DeterSpace(struct SeqList* ps) {
if (ps == NULL) {
perror("ps");
}
if (ps->size == ps->capacity) {
// 如果并未分配空间,返回
int exsp = ps->capacity == 0 ? 4 : 2 * ps->capacity;
ps->capacity = exsp; //将扩展后的空间大小记录下来
Datatype* p1 = NULL;
// 扩展空间大小
p1 = realloc(ps->arr, exsp * sizeof(Datatype));
assert(p1);
ps->arr = p1;
}
}
//尾插法
void TailInsert(struct SeqList* ps, Datatype x) {
if (ps == NULL) {
perror("ps");
}
//需要先确定空间是否够用?
//如果顺序表中的元素个数等于空间大小,则需要扩展空间--申请原来空间两倍的空间
DeterSpace(ps);
// 将值插到顺序表末尾
ps->arr[ps->size++] = x;
}
// 头插法:
void HeadInsert(struct SeqList* ps, Datatype x) {
//对于头插法,我们也需要判断空间是否足够用
DeterSpace(ps);
//在保证了空间之后,将顺序表中数据先往右移动一个元素大小,再进行插入
for (int i = ps->size; i > 0; i--) {
ps->arr[i] = ps->arr[i - 1];
}
//空出首地址之后:
ps->arr[0] = x;
//元素的个数也需要++
ps->size++;
}
// 在指定位置插入一个数据
void RanInsert(struct SeqList *ps,int pos,Datatype x) {
assert(ps);
assert(pos>=0 &&pos<=ps->size -1);
//在指定位置插入一个数据可以由 将此位置及此位置以后的数据往后移动一位,然后再将数据插入此位置
//在此之前要判断空间是否够用
DeterSpace(ps);
for (int i = ps->size-1; i >= pos; i--) {
ps->arr[i+1] = ps->arr[i]; //将pos在内之后的数据往右移动一位
}
ps->arr[pos] = x;
ps->size++;
}
// 头删法
// 即删除顺序表中的首个元素
void HeadDelete(struct SeqList* ps) {
for (int i = ps->size - 1; i > 0; i++) {
ps->arr[i - 1] = ps->arr[i];
}
ps->arr[ps->size - 1] = 0;
ps->size--;
}
// 尾删法 -- 找到最后一个数组元素置为0;
void TailDelete(struct SeqList* ps) {
//直接通过ps->size找到顺序表中最后一个元素置为0
ps->arr[ps->size - 1] = 0;
ps->size--;
}
// 删除指定位置的数据
void RanInsert(struct SeqList*ps,int pos) {
//我们删除指定位置的数据后,可以由在此位置之后的数据整体往前移动来实现
assert(ps);
assert(0 <= pos && pos <= ps->size - 1);
//在下标pos之前的数据向前移动
for (int i = ps->size - 1; i > pos; i--) {
ps->arr[i - 1] = ps->arr[i];
}
ps->arr[ps->size - 1] = 0;//将顺序表原来的最后一个元素位置置为0;
ps->size--; // 元素个数-1
}
// 查找
// 返回相应的下标
int Select(struct SeqList * ps,Datatype x) {
assert(ps);
for (int i = 0; i < ps->size - 1; i++) {
if (ps->arr[i] == x) {
return i;
}
}
//找不到返回0
return 0;
}
// 删除一个顺序表
void DeleteList(struct SeqList* ps) {
if (ps == NULL) {
exit(1);
}
free(ps->arr);
ps->arr = NULL;
//并将元素个数,空间记录清除
ps->size = ps->capacity = 0;
}
二 链表
链表是线性表的一种
1 链表的逻辑结构是线性的,但其物理存储结构不是线性的。
2 链表的基本元素为结点,结点由数据域与指针域组成,数据域中存放存储的数据,
指针域中存放指向其他结点的指针, 结点之间通过指针互相联系。
链表共有8种(2*2*2)
链表的三种特性分别为: 带头与不带头
( 所谓头即指不携带有效数据的头节点)
单向与双向链表
循环与不循环
(所谓循环即第一个结点与尾结点链接在一起)
链表:
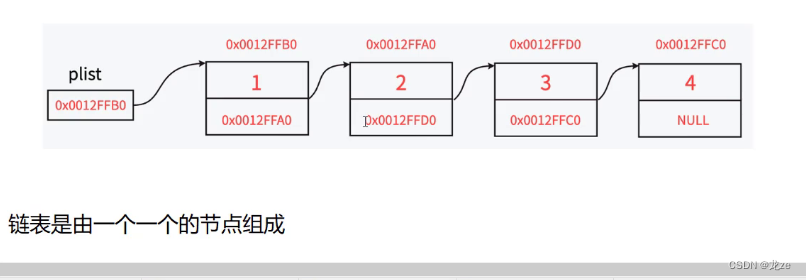
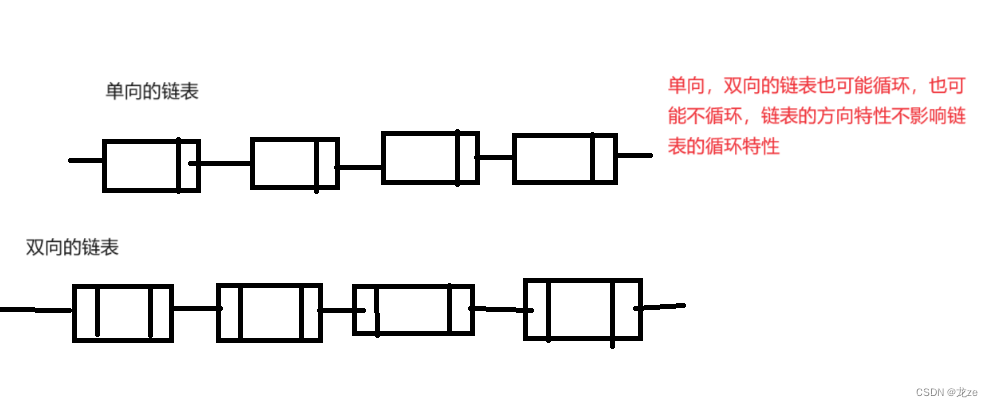
最常见的有两种:单链表与双向链表
单链表
单链表的全称是不带头单向不循环链表
我在代码中的注释所写的首节点是可以携带有效数据的,为了避免与头节点混淆,所以我用首节点作为名称,而不是头节点!

代码:
#include<stdlib.h>
#include<stdio.h>
#include<assert.h>
// 声明单链表结点
// 对链表中数据类型的声明
typedef int Datatype;
typedef struct ListNode {
Datatype data; //结点中的数据
struct ListNode* Next;//指向下一个结点的指针
}Node;
//打印链表函数声明
void PrintList(Node* ps);
//创建新结点并赋值的函数声明
Node* CreateNode(Datatype x);
// 插入数据
// 头插
void HeadInsert(Node** phead, Datatype x);
//尾插
void TailInsert(Node** phead, Datatype x);
// 尾删
void TailDelete(Node** phead);
// 头删
void HeadDelete(Node** phead);
// 查找
Node* Select(Node* phead, Datatype x);
// 在指定位置之前插入数据
void RanLeftInsert(Node** phead, Node* pos, Datatype x);
// 在指定位置之后插入数据
// 我们不需要首节点的参数,因为不需要遍历,也不需要在首节点之前插入数据
void RanRightInsert(Node* pos, Datatype x);
// 删除pos位置的结点
void DeleteNode(Node** phead, Node* pos);
// 删除pos之后的结点
void DeleteAfterNode(Node* pos);
// 销毁链表:
void Distory(Node** phead);

代码:
#define _CRT_SECURE_NO_WARNINGS 1
#include"List.h"
//打印链表函数
void PrintList(Node* ps) {
while (ps!=NULL) {
printf("%d\n", ps->data);
ps = ps->Next;
}
}
// 创建新结点:
Node* CreateNode(Datatype x) {
Node* newnode = (Node*)malloc(sizeof(Node));
if (newnode == NULL) {
perror("malloc");
exit(1); //退出程序
}
newnode->data = x;
newnode->Next = NULL;
return newnode;//返回新结点的指针
}
// 插入数据
// 头插
void HeadInsert(Node ** phead,Datatype x ) {
Node* newnode = CreateNode(x);
// 将新节点插入到原链表的首部
newnode->Next = *phead;
// 将新节点即新链表首节点的地址赋给*phead
*phead = newnode;
}
//尾插
void TailInsert(Node** phead, Datatype x) {
//参数为指向 指定链表的首结点 的指针与要插入的数据
//如果链表一开始为空,即phead =NULL时,则ptail->Next则有问题,
Node* ptail = *phead;
if (* phead == NULL) {
* phead = CreateNode(x); //在函数调用结束后,函数中的局部变量会被收回,
//形参phead值的改变不会影响到实参,如果采用首节点二重指针
// 则可以通过形参改变首节点的指针。
}
else {
//先找到尾结点
while (ptail->Next != NULL) {
ptail = ptail->Next;
}
//在找到尾结点后,在尾结点后插入新的结点,并赋值
ptail->Next = CreateNode(x);
}
}
// 尾删
void TailDelete(Node**phead) {
//链表不能为空
assert(phead && *phead);
//我们在删除尾结点之后,尾结点之前的指针就变为野指针,我们需要找到此指针并置为空
//当链表只有一个结点时:
if ((*phead)->Next == NULL) {
free(*phead);
*phead = NULL;
}
else {
// 创建存放指向尾结点的指针
Node* prev = NULL;
Node* ptail = *phead;
//查找头节点
while (ptail->Next) {// ptail->Next != NULL;
prev = ptail;
ptail = ptail->Next;
}
//在找到尾结点后:
free(ptail);
ptail = NULL;
//将指向尾结点的指针置为空
prev->Next = NULL;
}
}
// 头删
void HeadDelete(Node **phead) {
assert(phead && *phead); //链表不能为空
//在删除首节点之后,我们需要能够找到下一个结点的地址
Node* next = (*phead)->Next;//->的优先级比*大
free(*phead);
*phead = next;
}
// 查找
Node* Select(Node* phead, Datatype x) {
Node* sel = phead;
while (sel) {
if (sel->data == x) {
return sel;
}
sel = sel->Next;
}
}
// 在指定位置之前插入数据
void RanLeftInsert(Node**phead,Node *pos,Datatype x) {
//因为首节点可能会改变,所以用二级指针作为形参,避免用一级指针无法改变链表的首地址
//在指定位置之前插入数据的情况只有图中的三种情况,在链表之前,在链表中,在链表最后一个元素之前
assert(phead&& *phead);
assert(pos); //因为pos不能为空,所以*phead也不能为空,否则*phead为空时,也可以进行头插
if (pos == *phead) {
//pos在首节点处,这相当于头插法
HeadInsert(phead, x);
}
else {
//pos位置在链表中与链表最后一个元素上,操作没有本质区别
Node* newnode = CreateNode(x);
Node* prev = *phead;
while (prev->Next!=pos) {
prev = prev->Next;
}
//当找到了pos之前的prev时:
newnode->Next = pos;
prev->Next = newnode;
}
}
// 在指定位置之后插入数据
// 我们不需要首节点的参数,因为不需要遍历,也不需要在首节点之前插入数据
void RanRightInsert(Node * pos,Datatype x) {
assert(pos);
//我们先创建新结点
Node* newnode = CreateNode(x);
//将结点插入到pos之后:
newnode->Next = pos->Next;
pos->Next = newnode;
}
// 删除pos位置的结点
void DeleteNode(Node** phead, Node* pos) {
assert(phead && *phead);
assert(pos);
//在删除pos结点时,我们需要将pos之后的结点与pos之前的结点链接起来,
//pos之后的结点可以用pos->next找到,pos之前的结点需要在遍历时,用变量prev保存!
if (pos == *phead) {
//当pos是首节点时,此时的情况即头删法
HeadDelete(phead);
}
else {
Node* prev = *phead;
//在采用这条判断语句的前提是:pos不是首结点
while (prev->Next != pos) {
prev = prev->Next;
}
//当找到prev时,将pos之后的结点与pos之前的结点链接起来;
prev->Next = pos->Next;
//释放掉pos
free(pos);
}
}
// 删除pos之后的结点
void DeleteAfterNode(Node* pos) {
assert(pos && pos->Next);
//要删除pos之后的结点,要将pos->next之后的结点与pos链接起来,再删除pos
Node* del = pos->Next;
pos->Next = del->Next;
free(del);//难道此时pos->Next的值不会发生变化?
del = NULL;
// 兄弟们,下面的c打印的值是多少?它的值会不会随着a的变化而变化呢?
//int a = 1;
//int c = a;
// a++;
//printf("%d\n",c);
}
// 销毁链表:
void Distory(Node **phead) {
assert(phead && *phead);
Node* pcur = *phead;
while (pcur != NULL) {//链表的销毁需要一个结点一个结点的释放
Node* next = pcur->Next;
free(pcur);
pcur = next;
}
*phead = NULL;
}
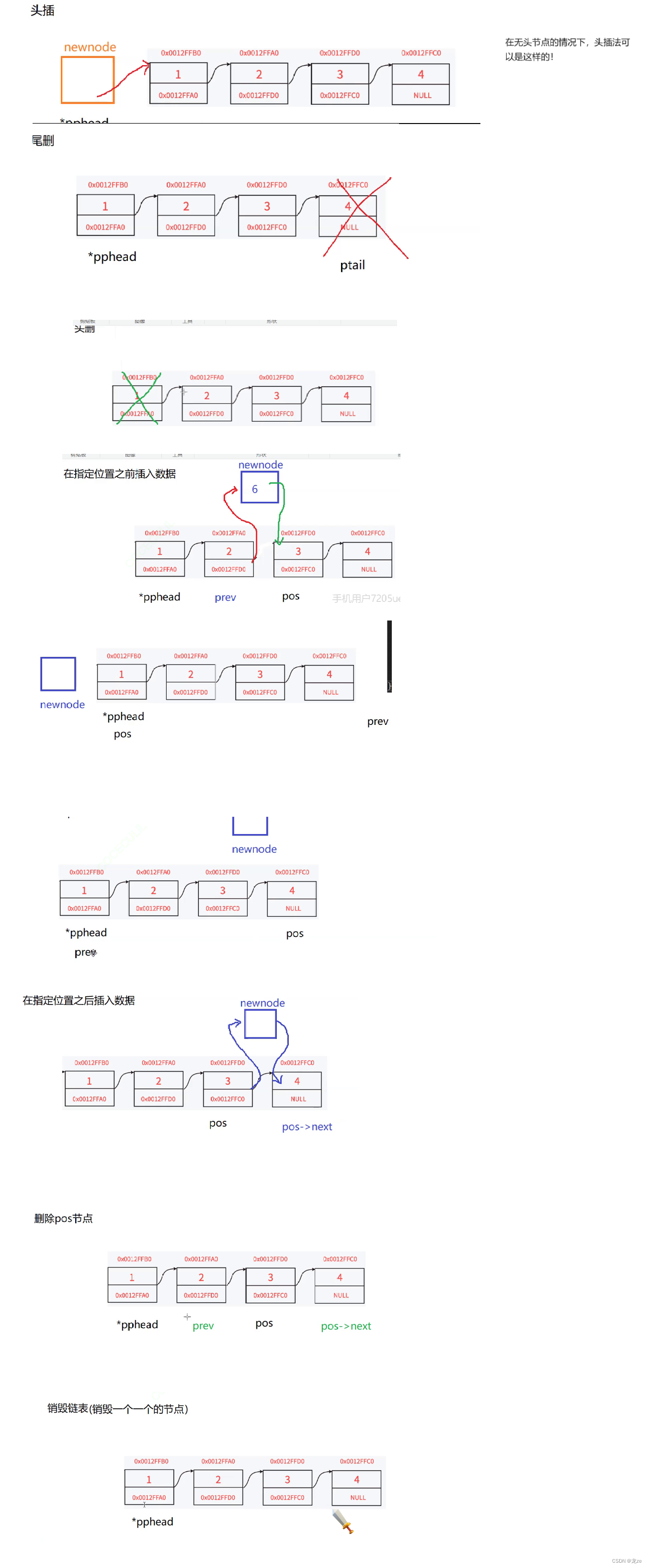
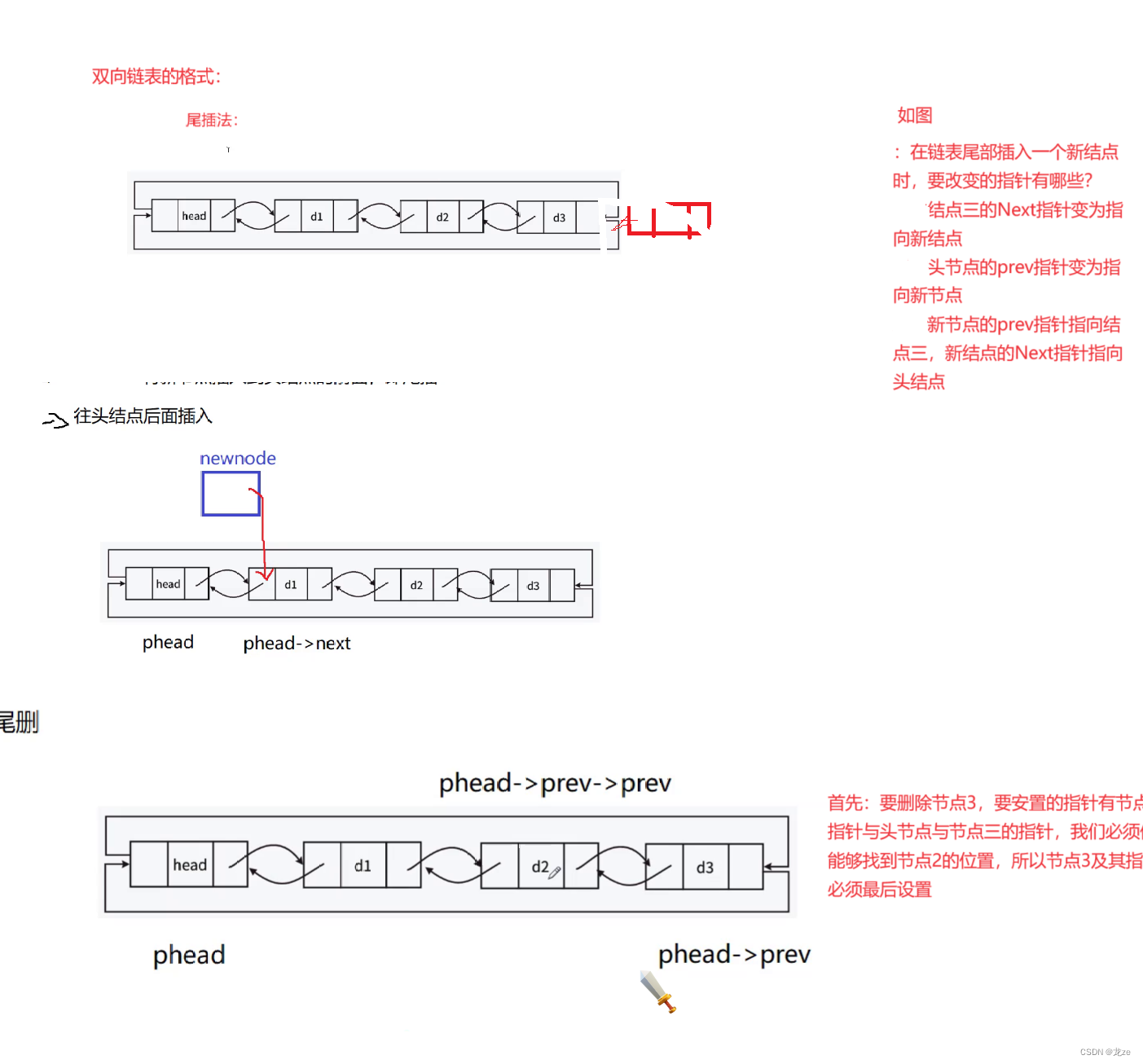
双向链表
双向链表的全称是带头双向循环链表
分析图:

#define _CRT_SECURE_NO_WARNINGS 1
#include<string.h>
#include<assert.h>
#include<stdlib.h>
typedef int Datatype;
//定义双链表结点的格式
typedef struct ListNode {
Datatype data;
struct ListNode* next;
struct ListNode* prev;
}ListNode;
//函数操作的声明:
// 创建结点
void CreateNode(Datatype x);
// 打印链表:
void PrintList(ListNode* phead);
//初始化链表
void Initialize(ListNode** phead);
//插入数据操作
// 尾插法:
// 我们不需要改变头节点,所以用一级指针作为形参即可
void TailInsert(ListNode* phead, Datatype x);
//头插法
void HeadInsert(ListNode* phead, Datatype x);
// 尾删法
void TailDelete(ListNode* phead);
//头删:
void HeadDelete(ListNode* phead);
// 查找
ListNode* Select(ListNode* phead, Datatype x);
// 在指定位置之后插入数据
ListNode* AfterSelect(ListNode* pos, Datatype x);
//删除指定位置pos节点
//pos的形参是一级而不是二级是因为前面的函数形参皆是一级指针 ,这样保证了接口的一致性,确保了
// 他人的方便调用与解读。
void DeleteNode(ListNode* pos, ListNode* phead);
//销毁链表:
void Distory(ListNode* phead);

#include"List.h"
// 打印链表:
void PrintList(ListNode *phead){
//我们遍历双向链表的条件是什么?
//我们能够找到判断条件是因为,我们知道双向链表从哪里开始到哪里结束是一个循环,我们只是把自己所知道的
//用符号的形式表述出来,这是一种能力!
ListNode* p1 = phead->next;
while(p1 !=phead)
{
printf("%d\n", p1->data);
p1 = p1->next;
}
}
//初始化链表
//因为双向链表是带头的【即有头节点】,所以需要先为链表创建一个头节点
void Initialize(ListNode ** phead) {
*phead = CreateNode(-1);//创建头节点并随便赋值为1
}
//创建新节点并赋值函数
ListNode * CreateNode(Datatype x) {
ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));
newnode->data = x;
//既然双向链表是循环的,我们在创建结点时,可以先使其自循环!
newnode->next = newnode;
newnode->prev = newnode;
return newnode;
}
//插入数据操作
// 尾插法:
// 我们不需要改变头节点,所以用一级指针作为形参即可
void TailInsert(ListNode * phead,Datatype x) {
ListNode* newnode = CreateNode(x);//创建一个新结点
//用phead->prev即可找到尾结点
//找到后
phead->prev->next = newnode;//将新节点插入到链表尾部
newnode->next = phead;
newnode->prev = phead->prev;
phead->prev = newnode;
}
//头插法
void HeadInsert(ListNode* phead, Datatype x) {
ListNode* newnode = CreateNode(x);
//指针先动谁?
//先操作phead->next指向的结点
//如果先操作phead结点,则在将phead->next指向新节点后,后面的链表部分就找不到位置了
//头插法最多动4个指针:头节点的next,原来第二个结点(可能没有)的prev,新节点的prev与next指针
newnode->next = phead->next;
newnode->prev = phead;
phead->next->prev = newnode;
phead->next = newnode;
}
// 尾删法
void TailDelete(ListNode * phead) {
// 尾删首先要找到尾结点,然后安排好相应的结点
//这是判断链表有效,必须有头节点
assert(phead);
//这是判断链表不能为空,否则无法删除
assert(phead->next!=phead);
// phead del del->prev //涉及的节点
ListNode* del = phead->prev;
del->prev->next = phead;
phead->prev = del->prev;
// 删除del节点
free(del);
del = NULL;
}
//头删:
void HeadDelete(ListNode* phead) {
assert(phead && phead->next != phead);
ListNode* del = phead->next;
del->next->prev = phead;
// 删除节点
free(del);
del = NULL;
}
// 查找
ListNode* Select(ListNode* phead,Datatype x) {
ListNode* pcur = phead->next;
while (pcur != phead) {
if (pcur->data == x) {
return pcur;
}
pcur = pcur->next;
}
//没有找到
return NULL;
}
// 在指定位置之后插入数据
ListNode* AfterSelect(ListNode* pos, Datatype x) {
assert(pos);
ListNode* newnode = CreateNode(x);
newnode->next = pos->next;
newnode->prev = pos;
pos->next->prev = newnode;
pos->next = newnode;
}
//删除指定位置pos节点
//pos的形参是一级而不是二级是因为前面的函数形参皆是一级指针 ,这样保证了接口的一致性,确保了
// 他人的方便调用与解读。
void DeleteNode(ListNode * pos,ListNode* phead) {
assert(pos && pos != phead);
pos->next->prev = pos->prev;
pos->prev->next = pos->next;
free(pos);
pos = NULL;
}
//销毁链表:
void Distory(ListNode*phead) {
assert(phead);
ListNode* pcur = (phead)->next;
while (pcur != NULL) {
ListNode* next = pcur->next;
free(pcur);
pcur = next;
}
// 此时pcur指向phead,而phead还没有被销毁
free(phead);
phead = NULL; //为了接口的一致性,不将形参改为ListNode**类型,
//则需要在调用函数后,再将实参赋值为NULL;
}
![bug(警告):[vue-router] Duplicate named routes definition: …](https://img-blog.csdnimg.cn/direct/6f60d4f4c61e4011b96e57fc15734fb1.png)