概述
大规模语言模型在理解和生成人类语言方面具有非凡的能力,但迄今为止,它们的能力主要局限于文本处理。然而,现实世界是一个多模式的环境,信息通过视觉、听觉和触觉等多种感官进行交换。融入这种多样性是开发下一代系统的主要目标。具体来说,多模态编码器的加入有望使大规模语言模型能够处理不同模式的信息,并利用其先进的文本处理能力生成一致的响应。然而,这种方法无法产生多模态输出。
Emu (Sun et al., 2023b)、SEED-LaMA (Ge et al., 2023b) 和 SpeechGPT (Zhang et al., 2023a)等开创性工作在实现语言模型中的多模态理解和生成方面取得了重大进展,但这些但这些模型只集成了单一的非文本模态,如图像或音频。虽然将文本与一种额外的模态对齐相对容易,但将多种模态(N ≥ 3)整合到一个框架中并实现它们之间的双向一致性则是一个更大的挑战。
为了应对这一挑战,本文开发了 “AnyGPT”。这是一种新型的多模态大规模语言模型,带有一个多模态标记器,可将图像和语音等原始数据转换为离散的语义标记。这种方法允许大规模语言模型在语义层面以统一的方式执行识别、理解、推理和生成。此外,该模型还可处理多模态输入和输出的任何组合,实验结果表明,其零点性能可与专用模型相媲美。

本文还建立了一个新的以文本为中心的多模态对齐数据集。由于自然语言是最复杂的语义表示模式,而且存在于大多数多模态数据集中,因此该数据集旨在以文本为桥梁,实现所有模态之间的相互对齐。通过这一举措,AnyGPT 促进了多模态对话,并证明了使用离散表示统一多种模态的可行性。
本文提出了一种新的多模态大规模语言模型 AnyGPT,它可以理解和生成多种模态,并开发了一个数据集 AnyInstruct-108k,该数据集遵循多模态交织指令,并使用离散表示法有效地统一了多种模态。在演示中,我们看到了这样做的可能性。这些发展为下一代多模态系统的开发开辟了新的可能性。
AnyGPT
AnyGPT 为每种图像、语音和音乐模式都引入了专用的标记器,从而创建了一种底层技术,使 AnyGPT 的应用更加多样化。
首先,采用 SEED 标记器对图像进行标记。该标记器将 224 x 224 RGB 图像作为输入,ViT 编码器将图像编码为 16 x 16 补丁,然后因果 Q 形成器将补丁特征转换为 32 个因果嵌入。用于量化这些嵌入,并通过 MLP 将其解码为视觉代码。这一过程最终由 UNet 解码器还原为原始图像。这种先进的标记器可以精确标记图像,并将其与 unCLIP 稳定扩散的潜空间对齐。
然后使用编码器-解码器架构 SpeechTokenizer 对音频数据进行标记化。该系统使用分层量化器将音频序列压缩成离散矩阵,同时捕捉语义和语外信息。在 Commonvoice 和 Librispeech 数据集上进行预训练后,标记器能够有效地对语义和语外信息进行建模,并与语音克隆模型结合使用,生成逼真的语音。
然后,Encodec 被用作音乐数据的专用标记器。这种卷积自动编码器使用残差向量量化技术将音乐曲目量化到潜在空间;Encodec 在超过 20,000 首曲目上进行了预先训练,以高分辨率处理音乐数据,并使用四个量化器捕捉音乐的语义元素。标记器与语言模型一起预测音乐片段,彻底改变了音乐的创作和生成。
AnyGPT 大幅扩展了其语言模型的词汇量,使其能够理解和生成多模态数据,不仅包括文本,还包括图像和音频。这种新方法引入了针对每种模式的标记,并相应地扩展了模型的嵌入层和预测层。这些新添加的参数首先被随机初始化,然后进行训练,以整合来自所有模态的标记,形成一个新的词汇表,从而实现共享表征空间的一致性。这种方法使模型能够无缝整合不同类型数据的知识和信息。
为了有效处理多模态数据,AnyGPT 为每种模态配备了专用的标记器,用于将数据转换为离散的标记序列。转换后的数据通过损失函数预测下一个标记,用于训练模型。通过这种一致的学习方法,模型获得了理解和生成所有类型数据的能力,包括文本、图像和音频。主干是 LLaMA-2 7B 模型,该模型已在一个大型文本标记数据集上进行了预训练,并针对新词汇进行了微调。
此外,生成高分辨率图像和高质量音频数据尤其具有挑战性,因为需要处理大量信息。为了高效处理长序列,AnyGPT 采用了两阶段框架。这种方法首先处理语义层面的信息,然后利用这些信息生成高保真多模态内容。
此外,对于视觉内容,使用扩散模型从 SEED 标记生成高质量图像。对于音频,则采用非自回归 SoundStorm 模型从语义标记生成声音标记,然后将其转换为原始音频数据。这一过程能够从短短三秒的音频提示中再现任何说话者的声音。音乐生成使用 Encodec 标记来过滤人类感知不到的细节,并将其重构为高质量的音频数据
因此,AnyGPT 采用了创新方法来处理复杂的多模态数据并生成高质量的内容。这些技术能够深入理解和生成文本、图像和音频模式。
AnyInstruct-108k
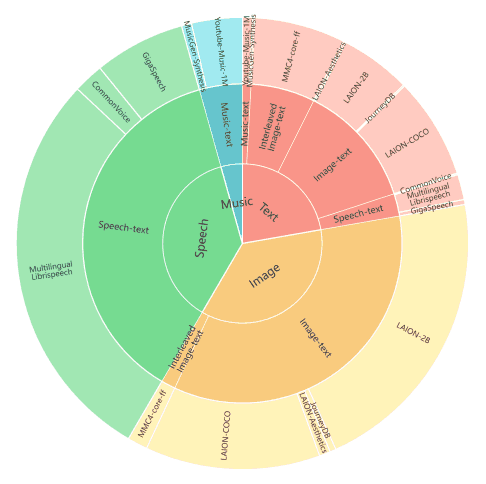
AnyGPT 预训练数据集的分布如下图所示。该数据集根据标记数量进行了划分。内侧部分显示了模式,中间部分显示了数据类型的详细信息,外侧部分显示了各个数据集。
为了实现不同信息模态的无缝生成,目前正在开发以文本为中心的双模态数据集,精心连接不同的模态。以文本为关键,目的是通过语言模型整合图像和音频等不同模式,并使所有这些模式相互协调。
为了便于比较来自不同模式的数据,我们采用了基于标记数量的量化方法。无论数据类型如何,这种方法都能在一致的基础上对数据量进行比较。
在图像和文本方面,使用了从 LAION-2B、LAION-COCO、LAION-Aesthetics 和 JourneyDB 收集的图像-文本对。这些数据集经过精心挑选,以提高图像和文本质量,从而形成高质量的语料库。此外,我们还添加了 LAION-Aesthetics 的一个子集和 JourneyDB 的一个合成数据集,以提高图像生成的质量。我们还加入了图像和文本交叉的数据,以确保模型能在不同模式下有效工作。
在 "语音与文本 "方面,收集了大型数据集,如 Gigaspeech、Common Voice 和多语言 LibriSpeech (MLS),用于英语自动语音识别 (ASR)。这些数据集是从在线平台、众包和有声读物中收集的 57,000 小时的口语文本对,涵盖了广泛的说话者、领域和环境。
音乐与文本》从互联网上收集了 100 多万个音乐视频,并通过 Spotify API 对歌曲和视频标题进行了匹配。收集到的元数据包括视频标题、描述、关键词、播放列表名称和 Spotify 歌词,并以 JSON 格式输入到 GPT-4 中。字幕。这样就能有效地为大量音乐音频提供高质量的字幕,并最大限度地减少数据集中的错误信息。
此外,有效的人机交互应允许以各种交叉模式交换信息。然而,对话中模式数量的增加大大增加了数据收集过程的复杂性。目前,还没有包含两种以上模式的大型指示性数据集。这是开发能够管理多种交织模式对话的综合模型的主要制约因素�
为了克服这一局限性,本文从最近的数据合成研究(Wang 等人,2022 年;Wu 等人,2023 年)中汲取灵感,利用生成模型建立了一个由 108k 多轮对话样本组成的数据集。通过精心策划,每个合成对话都整合了多种交叉模式,如文本、语音、图像和音乐。数据合成过程如下图所示。

通过这种方式,可以建立连接不同模态的预训练数据集,为整合各种信息开辟新的可能性。
试验
本文评估了基于预训练的 AnyGPT 的基本性能,涵盖所有模态的多模态理解和生成任务。评估旨在测试预学习过程中不同模态之间的一致性。具体来说,每种模态都测试了文本到 X 和 X 到文本的任务。在这里,X 适用于图像、音乐和音频。
为了模拟真实世界的场景,所有的评估都是零次测试。这种严格的评估设置要求模型能够泛化到未知的测试分布,并通过不同的模态展示了 AnyGPT 的通用能力。评估结果表明,AnyGPT 作为一种通用的多模态语言模型,在各种多模态理解和生成任务中表现出色。
AnyGPT 的图像理解性能在图像字幕任务中进行了评估。下表列出了比较结果,使用的是 MS-COCO 2014 标题基准(Lin 等人,2014 年),并根据现有研究(Li 等人,2023 年;Tang 等人,2023 年b)使用了 Karpathy 细分测试集。

文本到图像图像生成任务的结果如下表所示。为了与现有研究(Koh 等人,2023;Ge 等人,2023b;Sun 等人,2023a)保持一致,从 MS-COCO 验证集中随机选取了 30 000 幅图像,并使用 CLIPscore 作为评估指标。该指标基于 CLIP-ViTL(Radford 等人,2021 年)计算生成的图像与其对应的实际图像标题之间的相似度得分。

我们还通过计算 LibriSpeech 数据集(Panayotov et al.vec 2.0 和 Whisper Large V2 作为基线,不过 Wav2vec 2.0 是用 60,000 小时的语音进行预训练,并用 LibriSpeech 进行微调的,而 Whisper Large V2 则是在零拍摄设置下进行评估的、而 Whisper Large V2 则是在零拍摄设置下进行评估的,使用 680,000 小时的语音进行训练。结果如下表所示。

此外,还在 VCTK 数据集上进行了零镜头文本到语音(TTS)评估。结果如下表所示。TTS 系统根据说话人相似度和词错误率 (WER) 进行评估。这里的 WER 侧重于语音质量。

MusicCaps 基准(Agostinelli 等人,2023 年)用于评估 AnyGPT 在音乐理解和生成任务中的表现。CLAPscore(Wu 等人,2022 年;Huang 等人,2023 年)被用作客观测量指标。它衡量生成的音乐与文本描述之间的相似度。

在对音乐字幕进行评估时发现,现有的客观测量方法在反映音乐字幕任务的表现方面能力有限。音乐的多样性和主观性会引起每个人的不同看法。只有某些音乐流派和乐器具有易于识别的显著特征。最近的研究(Gardner 等人,2023 年)对这一问题进行了探讨,但它仍然是一个难以解决的问题。为了确保评估的客观性,我们计算并比较了<音乐、实际标题>和<音乐、生成标题>对的 CLAPscores。这些分数是整个测试集的平均值。
总结
AnyGPT的核心在于使用离散表示法,可以在不改变现有大规模语言模型的框架和训练方法的情况下毫不费力地纳入新的模态。AnyGPT 的核心在于使用离散表示法,可以在不改变现有大规模语言模型的框架和学习方法的情况下毫不费力地纳入新的模式。这就赋予了模型学习新语言的灵活性。
为了使 AnyGPT 能够熟练处理不同的模式,我们还开发了一个多模式指令数据集 AnyInstruct-108k。这是一个开创性的大规模数据集,包含涉及多种模式的多轮对话。
此外,实验结果表明,AnyGPT 在不同的跨模态任务中取得了显著的成果,并有能力在单一语言模型中高效、便捷地统一具有不同离散表征的模态。AnyGPT 的引入为语音、图像、文本等不同信息源的整合开辟了新途径、AnyGPT 为整合语音、图像、文本和音乐等不同信息源开辟了新途径,有望开发出更加丰富的多模态应用。