GitHub - hiyouga/LLaMA-Factory: Unify Efficient Fine-Tuning of 100+ LLMsUnify Efficient Fine-Tuning of 100+ LLMs. Contribute to hiyouga/LLaMA-Factory development by creating an account on GitHub.![]() https://github.com/hiyouga/LLaMA-FactoryQwen1.5 介绍 | QwenGITHUB HUGGING FACE MODELSCOPE DEMO WeChat简介 最近几个月,我们专注探索如何构建一个真正「卓越」的模型,并在此过程中不断提升开发者的使用体验。农历新年到来之际,我们推出通义千问开源模型1.5版本: Qwen1.5。我们开源了包括0.5B、1.8B、4B、7B、14B和72B共计6个不同规模的Base和Chat模型,, 以及一个MoE模型(点击博客 了解详情),并同步放出了各尺寸模型对应的量化模型。此次更新中,我们不仅像之前一样提供Int4和Int8的GPTQ模型,还提供了AWQ以及GGUF量化模型。为了提升开发者体验,我们将Qwen1.5的代码正式合并到HuggingFace transformers代码库中,所以现在可以直接使用 transformers>=4.37.0 原生代码,而无需指定 trust_remote_code 选项即可进行开发。我们已经与vLLM、SGLang(用于部署)、AutoAWQ、AutoGPTQ(用于量化)、Axolotl、LLaMA-Factory(用于微调)以及llama.cpp(用于本地 LLM 推理)等框架合作,所有这些框架现在都支持 Qwen1.5。Qwen1.5 系列可在 Ollama 和 LMStudio 等平台上使用。此外,API 服务不仅在 DashScope 上提供,还在 together.ai 上提供,全球都可访问。请访问here开始使用,我们建议您试用Qwen1.5-72B-chat。相较于以往版本,本次更新我们着重提升Chat模型与人类偏好的对齐程度,并且显著增强了模型的多语言处理能力。在序列长度方面,所有规模模型均已实现 32768 个 tokens 的上下文长度范围支持。同时,预训练 Base 模型的质量也有关键优化,有望在微调过程中为您带来更佳体验。这次迭代是我们朝向「卓越」模型目标所迈进一个坚实的步伐。模型效果 为了全面洞悉 Qwen1.5 的效果表现,我们对 Base 和 Chat 模型在一系列基础及扩展能力上进行了详尽评估,包括如语言理解、代码、推理等在内的基础能力,多语言能力,人类偏好对齐能力,智能体能力,检索增强生成能力(RAG)等。基础能力 关于模型基础能力的评测,我们在 MMLU(5-shot)、C-Eval、Humaneval、GS8K、BBH 等基准数据集上对 Qwen1.5 进行了评估。Model MMLU C-Eval GSM8K MATH HumanEval MBPP BBH CMMLU GPT-4 86.4 69.9 92.0 45.8 67.0 61.8 86.7 71.0 Llama2-7B 46.
https://github.com/hiyouga/LLaMA-FactoryQwen1.5 介绍 | QwenGITHUB HUGGING FACE MODELSCOPE DEMO WeChat简介 最近几个月,我们专注探索如何构建一个真正「卓越」的模型,并在此过程中不断提升开发者的使用体验。农历新年到来之际,我们推出通义千问开源模型1.5版本: Qwen1.5。我们开源了包括0.5B、1.8B、4B、7B、14B和72B共计6个不同规模的Base和Chat模型,, 以及一个MoE模型(点击博客 了解详情),并同步放出了各尺寸模型对应的量化模型。此次更新中,我们不仅像之前一样提供Int4和Int8的GPTQ模型,还提供了AWQ以及GGUF量化模型。为了提升开发者体验,我们将Qwen1.5的代码正式合并到HuggingFace transformers代码库中,所以现在可以直接使用 transformers>=4.37.0 原生代码,而无需指定 trust_remote_code 选项即可进行开发。我们已经与vLLM、SGLang(用于部署)、AutoAWQ、AutoGPTQ(用于量化)、Axolotl、LLaMA-Factory(用于微调)以及llama.cpp(用于本地 LLM 推理)等框架合作,所有这些框架现在都支持 Qwen1.5。Qwen1.5 系列可在 Ollama 和 LMStudio 等平台上使用。此外,API 服务不仅在 DashScope 上提供,还在 together.ai 上提供,全球都可访问。请访问here开始使用,我们建议您试用Qwen1.5-72B-chat。相较于以往版本,本次更新我们着重提升Chat模型与人类偏好的对齐程度,并且显著增强了模型的多语言处理能力。在序列长度方面,所有规模模型均已实现 32768 个 tokens 的上下文长度范围支持。同时,预训练 Base 模型的质量也有关键优化,有望在微调过程中为您带来更佳体验。这次迭代是我们朝向「卓越」模型目标所迈进一个坚实的步伐。模型效果 为了全面洞悉 Qwen1.5 的效果表现,我们对 Base 和 Chat 模型在一系列基础及扩展能力上进行了详尽评估,包括如语言理解、代码、推理等在内的基础能力,多语言能力,人类偏好对齐能力,智能体能力,检索增强生成能力(RAG)等。基础能力 关于模型基础能力的评测,我们在 MMLU(5-shot)、C-Eval、Humaneval、GS8K、BBH 等基准数据集上对 Qwen1.5 进行了评估。Model MMLU C-Eval GSM8K MATH HumanEval MBPP BBH CMMLU GPT-4 86.4 69.9 92.0 45.8 67.0 61.8 86.7 71.0 Llama2-7B 46.![]() https://qwenlm.github.io/zh/blog/qwen1.5/
https://qwenlm.github.io/zh/blog/qwen1.5/
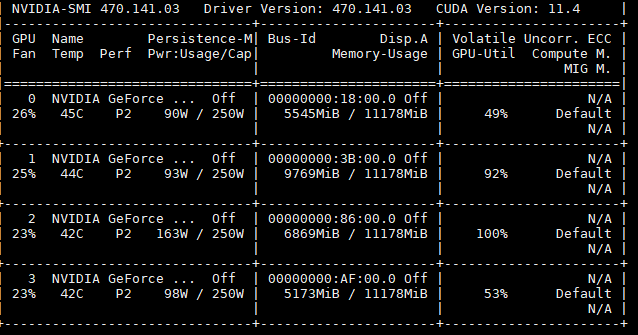
我在4卡1080ti上用lora微调的,1.8B用deepspeed的4卡,bs=1还是会爆显存,因此最终采用了0.5B的版本来训练。
1.数据
新定义的数据格式要在dataset_info.json中,通常我们定义的都是alpaca的格式:
{
"instruction": "三原色是什么?",
"input": "",
"output": "三原色通常指的是红色、绿色和蓝色(RGB)。它们是通过加色混合原理创建色彩的三种基础颜色。在以发光为基础的显示设备中(如电视、计算机显示器、智能手机和平板电脑显示屏), 三原色可混合产生大量色彩。其中红色和绿色可以混合生成黄色,红色和蓝色可以混合生成品红色,蓝色和绿色可以混合生成青色。当红色、绿色和蓝色按相等比例混合时,可以产生白色或灰色。\n\n此外,在印刷和绘画中,三原色指的是以颜料为基础的红、黄和蓝颜色(RYB)。这三种颜色用以通过减色混合原理来创建色彩。不过,三原色的具体定义并不唯一,不同的颜色系统可能会采用不同的三原色。"
}在dataset_info.json中注册:
"alpaca_gpt4_data_zh_retained": {
"file_name": "alpaca_gpt4_data_zh.json",
"file_sha1": ""
},
"sft_gpt4_livestreaming_data_20240105": {
"file_name": "sft_gpt4_data.json",
"file_sha1": ""
}数据包括:alpaca的通用数据,直播带货文案,商品主题词抽取,场景问答,选择题,客服问答,标题扩展,商品介绍seo,写文章,短标题抽取,小红书文案,根据参数扩写,文章总结,人设。
2.训练
在examples中有很多示例:
qwen1.5-1.8b-sft:
#!/bin/bash
deepspeed --num_gpus 4 ../../src/train_bash.py \
--deepspeed ../deepspeed/ds_z3_config.json \
--stage sft \
--do_train \
--model_name_or_path /root/e_commerce_llm/weights/Qwen1.5-0.5B/ \
--dataset alpaca_gpt4_data_zh,sft_gpt4_data \
--dataset_dir ../../data \
--template qwen \
--finetuning_type lora \
--lora_target q_proj,v_proj \
--output_dir ../../saves/Qwen1.5_0.5B_Base/lora/sft \
--overwrite_cache \
--overwrite_output_dir \
--cutoff_len 1024 \
--preprocessing_num_workers 16 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 2 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--warmup_steps 20 \
--save_steps 100 \
--eval_steps 100 \
--evaluation_strategy steps \
--learning_rate 5e-5 \
--num_train_epochs 3.0 \
--max_samples 3000 \
--val_size 0.1 \
--ddp_timeout 180000000 \
--plot_loss
1080ti不支持fp16,去掉了。

3.lora合并
#!/bin/bash
# DO NOT use quantized model or quantization_bit when merging lora weights
CUDA_VISIBLE_DEVICES=0 python ../../src/export_model.py \
--model_name_or_path /root/lgd/e_commerce_llm/weights/Qwen1.5-0.5B/ \
--adapter_name_or_path /root/lgd/e_commerce_llm/llama_factory/saves/Qwen1.5_0.5B_Base/lora/sft/ \
--template qwen \
--finetuning_type lora \
--export_dir ../../models/qwen1.5_0.5B_base_sft \
--export_size 2 \
--export_legacy_format False
4.前向推理
inference下的sh
#!/bin/bash
CUDA_VISIBLE_DEVICES=0 python ../../src/cli_demo.py \
--model_name_or_path /root/lgd/e_commerce_llm/weights/Qwen1.5-0.5B/ \
--adapter_name_or_path /root/lgd/e_commerce_llm/llama_factory/saves/Qwen1.5_0.5B_Base/lora/sft/ \
--template qwen \
--finetuning_type lora
5.结论
我在自己的数据集上用lora微调了qwen-0.5B-Base和qwen-0.5B-Chat:
5.1 效果都不太好;
5.2 base版本出现过很多和提问无关的内容;
5.3 就人格注入来讲,chat一点都注入不进去,但base版本好很多;
5.4 推理显存占用1080ti没问题;
5.5 base版本会不断重复内容;
5.6 chat版本也会不断重复内容;
感觉微调之后chat版本还差一点。