1·1、保姆版安装
Anoconda安装(python的一个发行版本)
优点:集成了许多关于python科学计算的第三方库,保姆级别
下载:www.anaconda.com/download/
版本默认64位,py37
√:add anaconda to my path environment variable
√:path设置(F:\python37),也可以默认安装路径
√:暂时skip VSCODE的安装
安装完后,菜单有以下IDE(代码编辑器)
基础运行:
create new project>>existing interpreter(XXX\anaconda\python.exe>>create>>new>>python file
编写代码后,RUN一下就OK


1·2简洁版安装
直冲python官网下载,选择喜欢的版本
Download Python | Python.org

2、选择自己喜欢的编译器下载
——小编喜欢用pycharm和notepad++喜欢的同学可以去官网下载——
Download PyCharm: The Python IDE for data science and web development by JetBrains
记得选community版本,cause free
3、库的下载
在PYTHON2>=2.7.9 or python3>=3.4的版本,都自带了pip(安装神器)
操作:windows+r>>cmd>>pip
便可以查看pip版本,后续可以pip万库,(#^.^#)
——or——
如果有pycharm,可以进行以下操作,比较直观
file>>settings>>project>>project interpreter>>+>>搜索要安装的库的名字>>install package
4、虚拟环境virtualenv与Docker容器技术
4.1virtualenv
(作用:实行多个python版本或者环境互相隔离,互不干扰,新手可跳过,暂时用不上)
打开终端:
win+r>>cmd>>pip install virtualenv(安装虚拟环境创造工具)
virtualenv ENV #创建第一个虚拟环境
cd ENV\Scripts
activate #激活
Deactivate #退出——or——
在pycharm的interpreter选择中也可以配置虚拟环境
4.2Docker容器技术
1)简介:Docker是dotCloud公司开源的一个基于LXC的高级容器引擎,基于go语言并且遵从Apache2.0协议开源。多用于应用程序,不包含数据。
2)日志、数据库等放在Docker容器外。存储一般通过外部挂载等方式使用:NFS、ipsan、MFS等 ,docker命令 ,-v映射磁盘分区。
3)作用:Namespace —> 实现Container的进程、网络、消息、文件系统和主机名的隔离。
| A-文件系统隔离: | 每个进程容器运行在一个完全独立的根文件系统里。 |
|---|---|
| B-资源隔离: | 系统资源,像CPU和内存等可以分配到不同的容器中,使用cgroup。 |
| C-网络隔离: | 每个进程容器运行在自己的网路空间,虚拟接口和IP地址。 |
| D-日志记录: | Docker将收集到和记录的每个进程容器的标准流(stdout/stderr/stdin),用于实时检索或者批量检索 |
| E-变更管理: | 容器文件系统的变更可以提交到新的镜像中,并可重复使用以创建更多的容器。无需使用模板或者手动配置。 |
| F-交互式shell: | Docker可以分配一个虚拟终端并且关联到任何容器的标准输出上,例如运行一个一次性交互shell |
————————————————
版权声明:关于DOCKER部分介绍,原文请参考下方链接
(本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。原文链接:https://blog.csdn.net/m0_61503020/article/details/125456520)
4)下载
(根据自己的系统选择合适的版本)
下载:Install Docker Desktop on Windows | Docker Docs
![]() 下载后安装
下载后安装
 安装后第一次打开时间会比较长,等页面出来就OK。
安装后第一次打开时间会比较长,等页面出来就OK。
5)初运行
下载官方指引新人用的示例文件 ,当然有GIT也可以用代码下载。这里下载的路径要做下笔记。
https://github.com/docker/welcome-to-docker

找到下载的dockerfile文件,复制它的路径
cd \你记住的路径\
docker build -t welcome-to-docker .然后你会得到新建的第一个images

然后:run>>option>>post→8089
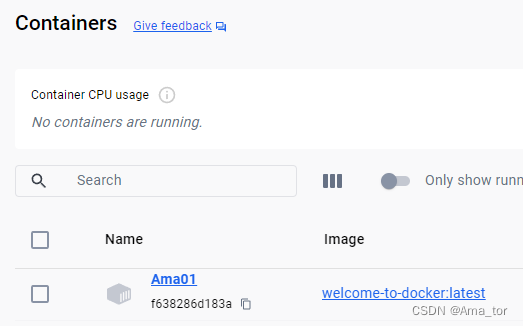
run了 第一个container后转到浏览器你会看见官方的恭喜画面,即成功。
5、库的入门——requests
作用:发送网络请求
A:分类:
1)get:从指定的资源请求数据
import requests
baidu="https://baidu.com"
q=requests.get(url=baidu).text
print(q)get到的是HTML源码

2)post:向指定的资源提交要被处理的数据
(httpbin.org 一个简单的 HTTP 请求和响应服务,用 Python + Flask 编写)
import requests
url = "http://httpbin.org/post"
data={'key':'value'}
r = requests.post(url=url, data=data)
r=r.text
print(r)运行结果返回一堆json数据

3)其他用得较少:put/delete/options
GET->查
POST->改
PUT->增
DELETE->删
B:URL的参数传递
(URL不仅是网址,还带查询的字符串,即类似key/value之类的键值),
练习:通过字典或者字符串传参。
mport requests
#参数设定
payload={'key1':'value1','key2':'value2'}
#若key对应多个value:payload={'key1':'value1','key2':['value2','value3']}
r= requests.get('http://httpbin.org/post',params=payload)
print(r.url)
C: 设置超时
超时会报错断开
r= requests.get('http://github.com',timeout=0.5)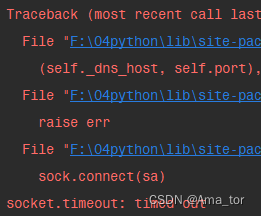
D:设置请求表头
(这个在小编的Python学习笔记(1)应用过)
import requests #引用requests库
import re
#模拟浏览器访问强求,在谷歌浏览器输入about:version即可获取
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}
#将网址赋值给变量url
url='https://www.baidu.com/s?rtt=1&bsst=1&cl=2&tn=news&rsv_dl=ns_pc&word=%E9%98%BF%E9%87%8C%E5%B7%B4%E5%B7%B4'
#通过requests库的get()函数访问该网址,通过.text获取网页源代码的文本内容
res=requests.get(url,headers=headers).text
#print(res) #打印输出获取的网页源代码