文章目录
- 基本设计目标
- 监控系统设计基本要求
- 三个基本设计目标
- Dapper监控系统简介
- 三个基本概念
- 区间Helper.Call的详细信息
- 监控信息的汇总
- 监控数据汇总单独进行的原因
- 关键性技术
- 轻量级核心功能库
- 二次抽样技术
- 常用Dapper工具
- Dapper存储API
基本设计目标
监控系统设计基本要求
- 广泛可部署性(Ubiquitous Deployment):设计出的监控系统应当能够对尽可能多的Google服务进行监控
- 不间断的监控:Google的服务是全天候的,如果不能对Google 的后台同样进行全天候的监控很可能会错过某些无法再现的关键性故障
三个基本设计目标
- 低开销:监控系统的开销越低,对于原系统的影响就越小
- 对应用层透明:监控系统对程序员应当是不可见的。如果监控系统的使用需要程序开发人员对其底层的一些细节进行调整才能正常工作的话,这个监控系统肯定不是一个完善的监控系统。
- 可扩展性:满足集群的需求
Dapper监控系统简介
Dapper 是 Google 公司内部的一个大规模分布式系统跟踪基础设施,设计目的是了解系统行为和性能。尽管 Dapper 的具体实现细节并未公开。但在论文中,Dapper 的目标是提供低开销、应用级的透明和延展性,以便于在大规模分布式系统中跟踪请求流。
Dapper 监控系统的特点:
-
全面性:Dapper 设计用于收集分布式系统中所有组件的性能数据,从而为系统提供全面的视图。
-
低开销:尽管 Dapper 收集大量数据,但它的设计确保对系统性能的影响最小。这通过各种策略实现,包括采样和异步日志记录。
-
应用级透明性:Dapper 设计为对应用程序代码的侵入性最小。对于许多服务,开发者可以在不修改代码的情况下启用 Dapper 跟踪。
-
跨语言支持:Google 的系统通常使用多种编程语言编写,因此 Dapper 支持跨语言的数据收集。
-
可扩展性:Dapper 能够处理 Google 规模的数据量,这意味着它必须高度可扩展以应对数以百万计的交易和事件。
-
分布式跟踪:Dapper 能够跟踪分布式事务,即使这些事务跨越多个系统和服务也能确保数据的一致性和完整性。
-
分析和可视化工具:Dapper 收集的数据被用于驱动各种分析和可视化工具,帮助员工诊断问题和了解系统行为。
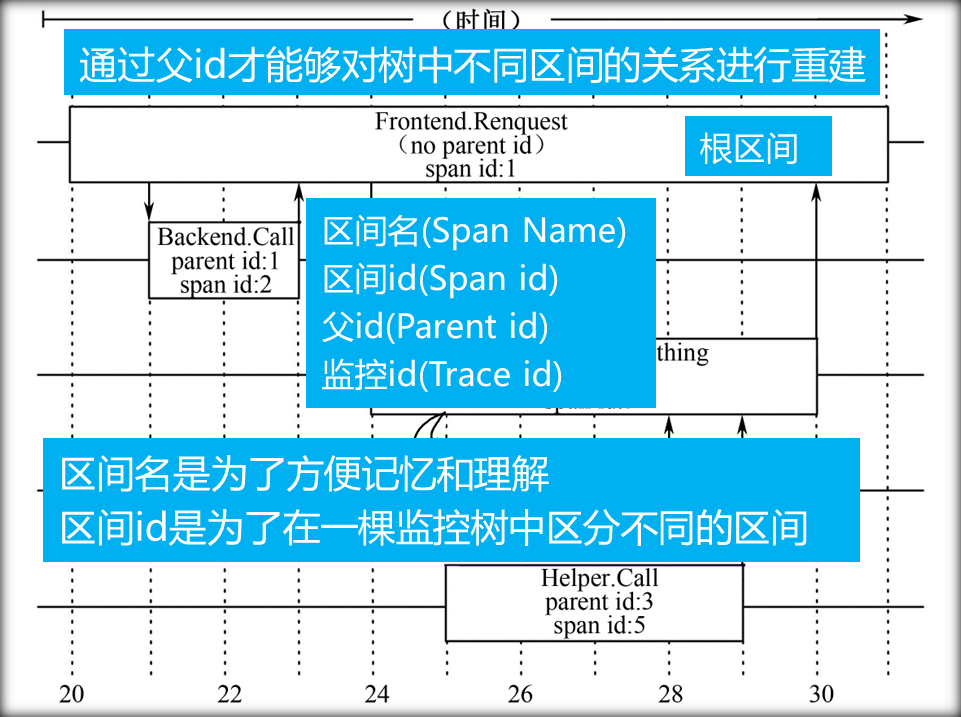
三个基本概念
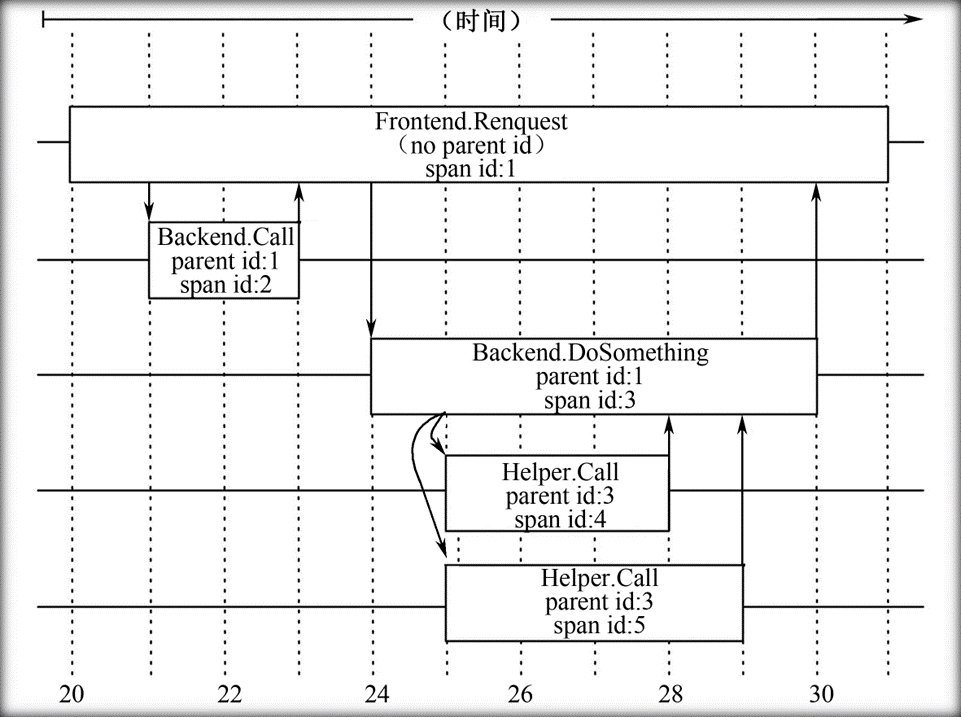
- 监控树(Trace Tree):一个同特定事件相关的所有消息,按照一定的规律以树的形式组织起来
- 区间(Span):树里面的节点,实际上就是一条记录,所有的记录联系在一起就构成了对某个事件的完整监控
- 注释(Annotation):注释主要用来辅助推断区间关系,也可以包含一些自定义的内容
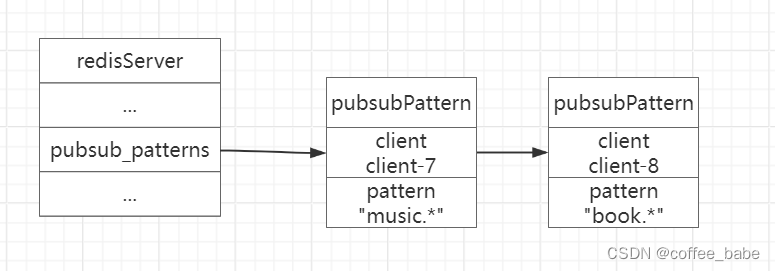
- 监控id是用来在整个Dapper监控系统中区分不同的监控
- 一棵监控树中所有区间的监控id是相同的,id随机分配,并且在整个Dapper唯一。
区间Helper.Call的详细信息
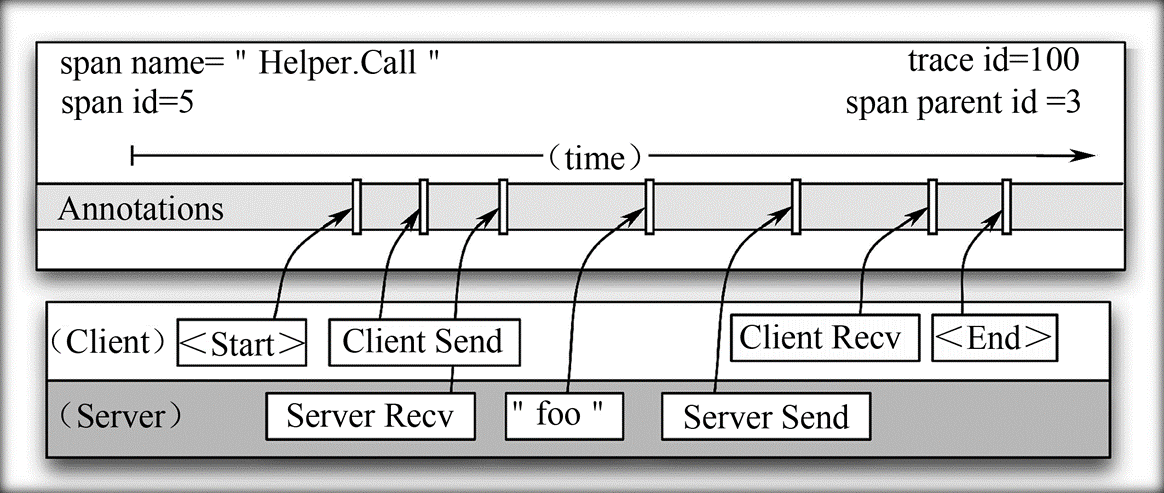
- 一个区间既可以只有一台主机的信息,也可以包含来源于多个主机的信息;
- 双主机区间:最常见,每个RPC(远程过程调用)区间都包含来自于客户端和服务器端的注释。区间包含了来自客户端的注释信息:
<Start>、Client Send、Client Recv和<End>,也包含了来自服务器端的注释信息:Server Recv、foo和Server Send
监控信息的汇总
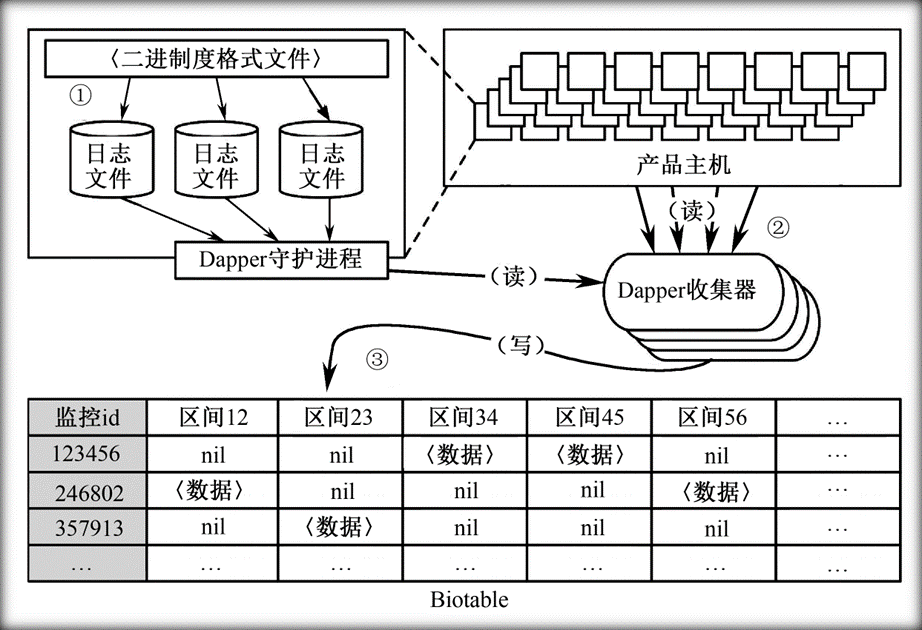
- 将区间的数据写入到本地的日志文件
- 所有机器上的本地日志文件汇集
- 汇集后的数据写入到Bigtable存储库中
监控数据汇总单独进行的原因
监控数据的汇总是单独进行的,而不是伴随系统对用户的应答一起返回的原因。
- 一个内置的汇总方案(监控数据随RPC应答头返回)会影响网络动态。一般来说,RPC应答数据规模比较的小,通常不超过10KB。而区间数据往往非常的庞大,如果将二者放在一起传输,会使这些RPC应答数据相对“矮化”进而影响后期的分析。
- 内置的汇总方案需要保证所有的RPC都是完全嵌套的,但有许多的中间件系统在其所有的后台返回最终结果之前就对调用者返回结果,这样有些监控信息就无法被收集。
关键性技术
轻量级核心功能库
- 实现对应用层透明的目标

- 最关键的代码基础是基本RPC、线程和控制流函数库的实现
- 主要功能是实现区间创建、抽样和在本地磁盘上记录日志。
- 将复杂的功能实现限制在一个轻量级的核心功能库中保证了Dapper的监控过程基本对应用层透明。
二次抽样技术
- 统一抽样率:不利于流量较低的服务,可能忽略关键性事件
- 适应性抽样率
- 利用二次抽样技术可以解决低开销及广泛可部署性的问题
-
第一次抽样:实践中,设计人员发现当抽样率低至1/1024时也能够产生足够多的有效监控数据,即在1024个请求中抽取1个进行监控也是可行的,从而可以捕获有效数据【海量数据,关注的事件出现的次数足够多】
-
第二次抽样:发生在数据写入Bigtable前。具体方法是将监控id散列(hash,压缩映射)成一个标量z(0≤z≤1),如果某个区间的z小于事先定义好的汇总抽样系数,则保留这个区间并将它写入Bigtable,否则丢弃。
常用Dapper工具
Dapper存储API
- Dapper的“存储API”简称为 DAPI,提供了对分散在区域Dapper存储库(DEPOTS)的监控记录的直接访问。一般有以下三种方式访问这些记录。
- 通过监控id访问 (Access by Trace id):利用全局唯一的监控id直接访问所需的监控数据
- 块访问 (Bulk Access):借助MapReduce对数以十亿计的Dapper监控数据的并行访问
- 索弓l访问 (lndexed Access):Dapper存储库支持单索引| (Single Index)