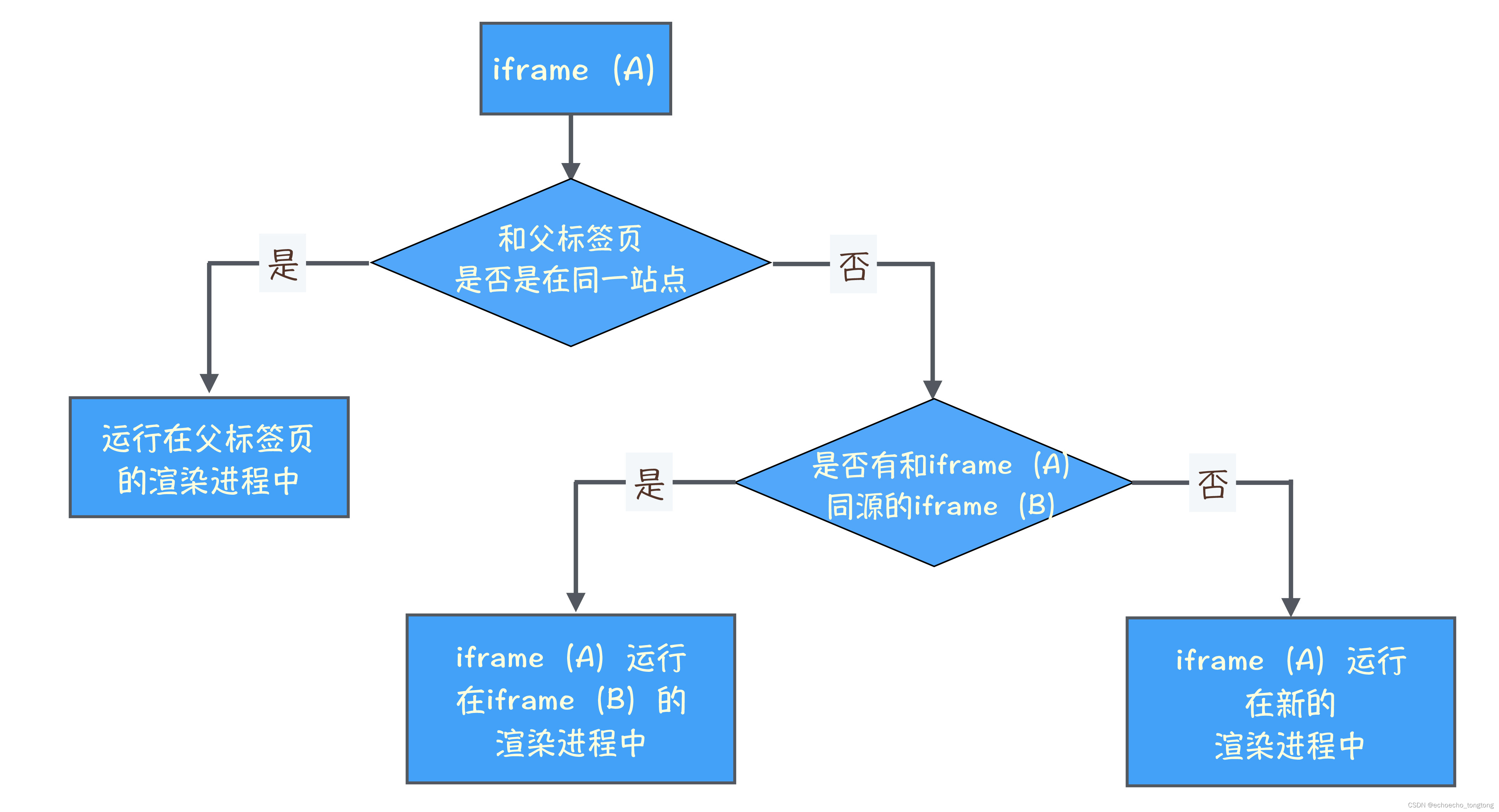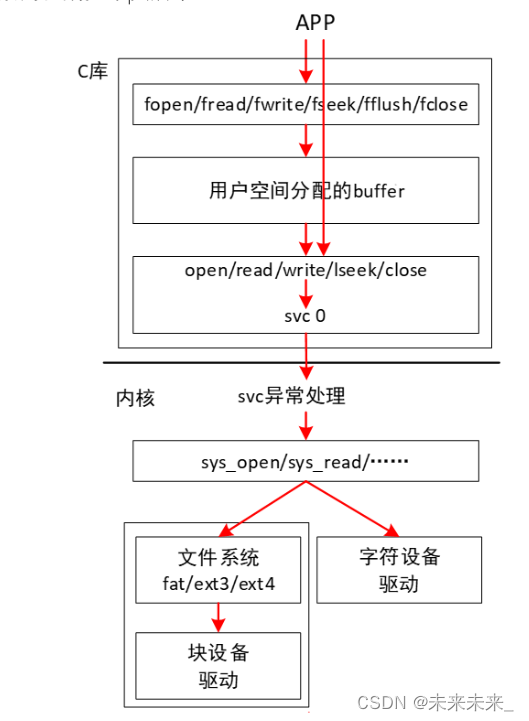


驱动全流程:
以基于设备树、Pinctrl、gpio子系统,打开一个字符设备为例:
1、通过系统调用open进入内核
当我们在用户空间调用open之后,应用程序会使用系统调用指令(在上图中可看到,ARM架构中软中断汇编指令为svc指令,X86架构中为int0X80)触发一个软中断,保存中断上下文后切换用户栈到内核栈,陷入内核空间,将控制权转移到操作系统内核。
2、内核调用sys_open服务函数
内核中的中断处理程序sys_call通过系统调用号(EABI形式中,系统调用号通过通用寄存器R7传递)查找系统调用表,也就是sys_call_table数组,它是一个函数指针数组,每一个函数指针都指向其系统调用的封装例程,有NR_syscalls个表项,第n个表项包含系统调用号为n的服务例程的地址来调用相应的系统调用处理函数,在此示例中也就是sys_open函数,sys_open是经过宏替换定义的,源码在fs/open.c中。
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode)
{
if (force_o_largefile())
flags |= O_LARGEFILE;
return do_sys_open(AT_FDCWD, filename, flags, mode);
}
展开SYSCALL_DEFINE3(open, const char __user , filename, int, flags, int, mode)函数原型如下:
asmlinkage long sys_open(const char __user* filename, int flags, int mode)
do_sys_open
在sys_open里面继续调用do_sys_open完成 open操作,该函数主要分为如下几个步骤来完成打开文件的操作:
1.将文件名参数从用户态拷贝至内核,调用函数get_name();
2.从进程的文件表中找到一个空闲的文件表指针也就是文件句柄,调用了函数get_unused_fd_flgas();
3.完成真正的打开操作,调用函数do_filp_open();
4.将打开的文件添加到进程的文件表数组中,调用函数fd_install();
long do_sys_open(int dfd, const char __user *filename, int flags, int mode)
{
/*从进程地址空间读取该文件的路径名*/
char *tmp = getname(filename);
int fd = PTR_ERR(tmp);
if (!IS_ERR(tmp)) {
/*在内核中,每个打开的文件由一个文件描述符表示该描述符在特定于进程的数组中充当位置索引(数组是
task_struct->files->fd_arry),该数组的元素包含了file结构,其中包括每个打开文件的所有必要信息。因此,调用下面
函数查找一个未使用的文件描述符,返回的是上面说的数组的下标*/
fd = get_unused_fd_flags(flags);
if (fd >= 0) {
/*fd获取成功则开始打开文件,此函数是主要完成打开功能的函数*/
//如果分配fd成功,则创建一个file对象
struct file *f = do_filp_open(dfd, tmp, flags, mode, 0);
if (IS_ERR(f)) {
put_unused_fd(fd);
fd = PTR_ERR(f);
}
}
}
} else {
/*文件如果打开成功,调用fsnoTIfy_open()函数,根据inode所指定的信息进行打开
函数(参数为f)将该文件加入到文件监控的系统中。该系统是用来监控文件被打开,创建,
读写,关闭,修改等操作的*/
fsnotify_open(f->f_path.dentry);
/*将文件指针安装在fd数组中
将struct file *f加入到fd索引位置处的数组中。如果后续过程中,有对该文件描述符的
操作的话,就会通过查找该数组得到对应的文件结构,而后在进行相关操作。*/
fd_install(fd, f);
}
}
putname(tmp);
return fd;
}
getname()
其中getname函数主要的任务是将文件名filename从用户态拷贝至内核态
char * getname(const char __user * filename)
{
char *tmp, *result;
result = ERR_PTR(-ENOMEM);
tmp = __getname(); //从内核缓存中分配空间;
if (tmp) {
//将文件名从用户态拷贝至内核态;
int retval = do_getname(filename, tmp);
result = tmp;
if (retval){
__putname(tmp);
result = ERR_PTR(retval);
}
}
audit_getname(result);
return result;
}
get_unused_fd_flags
get_unused_fd_flags实际调用的是alloc_fd,该函数为需要打开的文件在当前进程内分配一个空闲的文件描述符fd,该fd就是open()系统调用的返回值
#define get_unused_fd_flags(flags) alloc_fd(0, (flags))
/*
* allocate a file descriptor, mark it busy.
*/
int alloc_fd(unsigned start, unsigned flags)
{
struct files_struct *files = current->files;//获得当前进程的files_struct 结构
unsigned int fd;
int error;
struct fdtable *fdt;
spin_lock(&files->file_lock);
repeat:
fdt = files_fdtable(files);
fd = start;
if (fd next_fd) //从上一次打开的fd的下一个fd开始搜索空闲的fd
fd = files->next_fd;
if (fd max_fds)//寻找空闲的fd,返回值为空闲的fd
fd = find_next_zero_bit(fdt->open_fds->fds_bits,
fdt->max_fds, fd);
//如果有必要,即打开的fd超过max_fds,则需要expand当前进程的fd表;
//返回值error<0表示出错,error=0表示无需expand,error=1表示进行了expand;
error = expand_files(files, fd);
if (error)
goto out;
/*
* If we needed to expand the fs array we
* might have blocked - try again.
*/
//error=1表示进行了expand,那么此时需要重新去查找空闲的fd;
if (error)
goto repeat;
//设置下一次查找的起始fd,即本次找到的空闲的fd的下一个fd,记录在files->next_fd中;
if (start <= files->next_fd)
files->next_fd = fd + 1;
FD_SET(fd, fdt->open_fds);
if (flags & O_CLOEXEC)
FD_SET(fd, fdt->close_on_exec);
else
FD_CLR(fd, fdt->close_on_exec);
error = fd;
#if 1
/* Sanity check */
if (rcu_dereference(fdt->fd[fd]) != NULL) {
printk(KERN_WARNING "alloc_fd: slot %d not NULL!\n", fd);
rcu_assign_pointer(fdt->fd[fd], NULL);
}
#endif
out:
spin_unlock(&files->file_lock);
return error;
}
do_filp_open
do_filp_open函数的一个重要作用就是根据传递进来的权限进行分析,并且分析传递进来的路径名字,根据路径名逐个解析成dentry,并且通过dentry找到inode,inode就是记录着该文件相关的信息, 包括文件的创建时间和文件属性所有者等等信息,根据这些信息就可以找到对应的文件操作方法。在这个过程当中有一个临时的结构体用于保存在查找过程中的相关信息
fs/namei.c
do_sys_open->do_sys_openat2->do_filp_open
struct file *do_filp_open(int dfd, struct filename *pathname,
const struct open_flags *op)
{
struct nameidata nd;
int flags = op->lookup_flags;
struct file *filp;
set_nameidata(&nd, dfd, pathname);
filp = path_openat(&nd, op, flags | LOOKUP_RCU);
if (unlikely(filp == ERR_PTR(-ECHILD)))
filp = path_openat(&nd, op, flags);
if (unlikely(filp == ERR_PTR(-ESTALE)))
filp = path_openat(&nd, op, flags | LOOKUP_REVAL);
restore_nameidata();
return filp;
}
do_file_open 函数的处理如下, 主要调用了path_openat 函数去执行真正的open 流程:
fs/namei.c
do_sys_open->do_sys_openat2->do_filp_open
struct file *do_filp_open(int dfd, struct filename *pathname,
const struct open_flags *op)
{
struct nameidata nd;
int flags = op->lookup_flags;
struct file *filp;
set_nameidata(&nd, dfd, pathname);
filp = path_openat(&nd, op, flags | LOOKUP_RCU);
if (unlikely(filp == ERR_PTR(-ECHILD)))
filp = path_openat(&nd, op, flags);
if (unlikely(filp == ERR_PTR(-ESTALE)))
filp = path_openat(&nd, op, flags | LOOKUP_REVAL);
restore_nameidata();
return filp;
}
path_openat: 执行open的核心流程
(1) 申请 file 结构体, 并做初始化
(2) 找到路径的最后一个分量
(3) 对于最后一个分量进行处理, 这里面会去查找文件是否存在,如果不存在则看条件创建
(4) 执行open的最后步骤, 例如调用open 回调
fs/namei.c
do_sys_open->do_sys_openat2->do_filp_open->path_openat
static struct file *path_openat(struct nameidata *nd,
const struct open_flags *op, unsigned flags)
{
struct file *file;
int error;
file = alloc_empty_file(op->open_flag, current_cred()); /* 1 */
if (IS_ERR(file))
return file;
if (unlikely(file->f_flags & __O_TMPFILE)) {
error = do_tmpfile(nd, flags, op, file);
} else if (unlikely(file->f_flags & O_PATH)) {
error = do_o_path(nd, flags, file);
} else {
const char *s = path_init(nd, flags);
while (!(error = link_path_walk(s, nd)) && /* 2 */
(s = open_last_lookups(nd, file, op)) != NULL) /* 3 */
;
if (!error)
error = do_open(nd, file, op); /* 4 */
terminate_walk(nd);
}
if (likely(!error)) {
if (likely(file->f_mode & FMODE_OPENED))
return file;
WARN_ON(1);
error = -EINVAL;
}
fput(file);
if (error == -EOPENSTALE) {
if (flags & LOOKUP_RCU)
error = -ECHILD;
else
error = -ESTALE;
}
return ERR_PTR(error);
}
(1) 申请 file 结构体, 并做初始化
(2) 找到路径的最后一个分量
(3) 对于最后一个分量进行处理, 这里面会去查找文件是否存在,如果不存在则看条件创建
(4) 执行open的最后步骤, 例如调用open 回调
我们使用的open函数在内核中对应的是sys_open函数,sys_open函数又会调用do_sys_open函数。在do_sys_open函数中,首先调用函数get_unused_fd_flags来获取一个未被使用的文件描述符fd,该文件描述符就是我们最终通过open函数得到的值。紧接着,又调用了do_filp_open函数,该函数通过调用函数get_empty_filp得到一个新的file结构体,之后的代码做了许多复杂的工作,如解析文件路径,查找该文件的文件节点inode等,最后来到了do_dentry_open函数,如下所示:
do_sys_open->do_sys_openat2->do_filp_open->path_openat->do_open->vfs_open->do_dentry_open
fs/open.c
do_sys_open->do_sys_openat2->do_filp_open->path_openat->do_open->vfs_open
int vfs_open(const struct path *path, struct file *file)
{
file->f_path = *path;
return do_dentry_open(file, d_backing_inode(path->dentry), NULL);
}
static int do_dentry_open(struct file *f,
struct inode *inode,
int (*open)(struct inode *, struct file *))
{
static const struct file_operations empty_fops = {};
int error;
path_get(&f->f_path);
f->f_inode = inode;
f->f_mapping = inode->i_mapping;
f->f_wb_err = filemap_sample_wb_err(f->f_mapping);
f->f_sb_err = file_sample_sb_err(f); /* 1 */
if (unlikely(f->f_flags & O_PATH)) {
f->f_mode = FMODE_PATH | FMODE_OPENED;
f->f_op = &empty_fops;
return 0;
}
if (f->f_mode & FMODE_WRITE && !special_file(inode->i_mode)) {
error = get_write_access(inode);
if (unlikely(error))
goto cleanup_file;
error = __mnt_want_write(f->f_path.mnt);
if (unlikely(error)) {
put_write_access(inode);
goto cleanup_file;
}
f->f_mode |= FMODE_WRITER;
}
/* POSIX.1-2008/SUSv4 Section XSI 2.9.7 */
if (S_ISREG(inode->i_mode) || S_ISDIR(inode->i_mode))
f->f_mode |= FMODE_ATOMIC_POS;
f->f_op = fops_get(inode->i_fop); /*取该文件节点inode的成员变量i_fop*/
if (WARN_ON(!f->f_op)) {
error = -ENODEV;
goto cleanup_all;
}
error = security_file_open(f);
if (error)
goto cleanup_all;
error = break_lease(locks_inode(f), f->f_flags);
if (error)
goto cleanup_all;
/* normally all 3 are set; ->open() can clear them if needed */
f->f_mode |= FMODE_LSEEK | FMODE_PREAD | FMODE_PWRITE;
if (!open)
open = f->f_op->open;
if (open) {
error = open(inode, f); /* 3 */
if (error)
goto cleanup_all;
}
f->f_mode |= FMODE_OPENED;
if ((f->f_mode & (FMODE_READ | FMODE_WRITE)) == FMODE_READ)
i_readcount_inc(inode);
if ((f->f_mode & FMODE_READ) &&
likely(f->f_op->read || f->f_op->read_iter))
f->f_mode |= FMODE_CAN_READ;
if ((f->f_mode & FMODE_WRITE) &&
likely(f->f_op->write || f->f_op->write_iter))
f->f_mode |= FMODE_CAN_WRITE;
f->f_write_hint = WRITE_LIFE_NOT_SET;
f->f_flags &= ~(O_CREAT | O_EXCL | O_NOCTTY | O_TRUNC);
file_ra_state_init(&f->f_ra, f->f_mapping->host->i_mapping);
/* NB: we're sure to have correct a_ops only after f_op->open */
if (f->f_flags & O_DIRECT) {
if (!f->f_mapping->a_ops || !f->f_mapping->a_ops->direct_IO)
return -EINVAL;
}
/*
* XXX: Huge page cache doesn't support writing yet. Drop all page
* cache for this file before processing writes.
*/
if ((f->f_mode & FMODE_WRITE) && filemap_nr_thps(inode->i_mapping))
truncate_pagecache(inode, 0);
return 0;
cleanup_all:
if (WARN_ON_ONCE(error > 0))
error = -EINVAL;
fops_put(f->f_op);
if (f->f_mode & FMODE_WRITER) {
put_write_access(inode);
__mnt_drop_write(f->f_path.mnt);
}
cleanup_file:
path_put(&f->f_path);
f->f_path.mnt = NULL;
f->f_path.dentry = NULL;
f->f_inode = NULL;
return error;
}
def_chr_fops结构体(位于内核源码/fs/char_dev.c文件)
const struct file_operations def_chr_fops = {
.open = chrdev_open,
.llseek = noop_llseek,
};
(1) (2) 设置file结构体的一些成员
(3) 找到open 回调, 并执行
以上代码中的使用fops_get函数来获取该文件节点inode的成员变量i_fop,在上图中我们使用mknod创建字符设备文件时,将def_chr_fops结构体赋值给了该设备文件inode的i_fop成员。到了这里,我们新建的file结构体的成员f_op就指向了def_chr_fops。
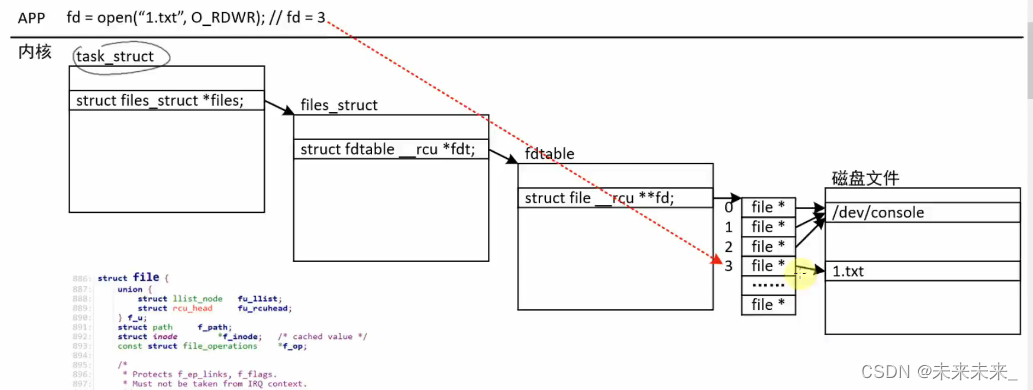
得到的file 结构体如下图所示:

此处的f_pos是文件的偏移地址,即read函数读文件的开始位置。而file结构体的位置如下图所示:
每个进程都有对应的 task_struct 结构体
3、执行最底层open
最终,会执行file_operation中的open函数,也就是驱动程序中的chrdev_open函数可以理解为一个字符设备的通用初始化函数,根据字符设备的设备号,找到相应的字符设备,从而得到操作该设备的方法,代码实现如下。chrdev_open函数(位于内核源码/fs/char_dev.c文件)
(注:可以自己在自定义驱动程序中定义drv_open,drv_open函数执行具体的寄存器操作,完成硬件驱动,其中如果引入Pinctrl、gpio子系统,将由gpio子系统指定硬件资源,这工作一般芯片厂家会提前做好,Pinctrl子系统设置gpio的功能,驱动程序可以直接使用gpio函数接口完成gpio的访问,所以具体的寄存器操作将由pinctrl、gpio子系统代劳。底层platform_driver结构体匹配设备节点时调用probe函数(记录引脚信息,创建设备节点)后,将硬件信息传给drv_open硬件操作函数)
static int chrdev_open(struct inode *inode, struct file *filp)
{
const struct file_operations *fops;
struct cdev *p;
struct cdev *new = NULL;
int ret = 0;
spin_lock(&cdev_lock);
p = inode->i_cdev;
if (!p) {
struct kobject *kobj;
int idx;
spin_unlock(&cdev_lock);
kobj = kobj_lookup(cdev_map, inode->i_rdev, &idx);
if (!kobj)
return -ENXIO;
new = container_of(kobj, struct cdev, kobj);
spin_lock(&cdev_lock);
/* Check i_cdev again in case somebody beat us to it while
we dropped the lock.
*/
p = inode->i_cdev;
if (!p) {
inode->i_cdev = p = new;
list_add(&inode->i_devices, &p->list);
new = NULL;
} else if (!cdev_get(p))
ret = -ENXIO;
} else if (!cdev_get(p))
ret = -ENXIO;
spin_unlock(&cdev_lock);
cdev_put(new);
if (ret)
return ret;
ret = -ENXIO;
fops = fops_get(p->ops);
if (!fops)
goto out_cdev_put;
replace_fops(filp, fops);
if (filp->f_op->open) {
ret = filp->f_op->open(inode, filp);
if (ret)
goto out_cdev_put;
}
return 0;
out_cdev_put:
cdev_put(p);
return ret;
}
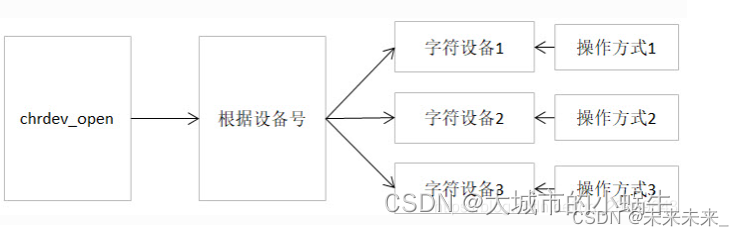
在Linux内核中,使用结构体cdev来描述一个字符设备。在以上代码中的第14行,inode->i_rdev中保存了字符设备的设备编号,通过函数kobj_lookup函数便可以找到该设备文件cdev结构体的kobj成员,再通过函数container_of便可以得到该字符设备对应的结构体cdev。函数container_of的作用就是通过一个结构变量中一个成员的地址找到这个结构体变量的首地址。同时,将cdev结构体记录到文件节点inode中的i_cdev,便于下次打开该文件。继续阅读第36~45行代码,我们可以发现,函数chrdev_open最终将该文件结构体file的成员f_op替换成了cdev对应的ops成员,并执行ops结构体中的open函数。
最后,调用上图的fd_install函数,完成文件描述符和文件结构体file的关联,之后我们使用对该文件描述符fd调用read、write函数,最终都会调用file结构体对应的函数,实际上也就是调用cdev结构体中ops结构体内的相关函数。
背景知识:
系统函数调用和常规函数调用的不同
在典型的 Linux 内核源代码中,用户调用 open 系统调用后,实际上会调用内核中的 sys_open 函数。但是,这个过程并不是通过常规的函数调用方式实现的。用户态的 open 系统调用会触发一个软中断(或者是通过系统调用指令),使得处理器从用户模式切换到内核模式,然后内核会根据中断号来执行相应的中断服务例程。在 Linux 内核中,这个中断服务例程会调用 sys_open 函数来完成实际的文件打开操作。
在典型的 Linux 内核源代码中,sys_open 函数通常被实现在一个文件中,例如 fs/open.c 或者类似的文件中。虽然你可以通过跳转到定义(jump to definition)的方式查看 open 函数的定义,但是在用户空间的代码中并不能直接看到 sys_open 函数的定义。这是因为 sys_open 是在内核空间中实现的,而用户空间的代码无法直接访问或查看内核空间的函数定义。
因此,虽然用户可以在代码中调用 open 系统调用,但是 sys_open 函数的具体实现对于用户是不可见的。用户只需要知道调用 open 函数即可发起文件打开操作,而具体的系统调用实现细节是由操作系统内核来处理的。
所以这也解答了笔者的疑惑,在查看源代码时,根据对open函数的jump to definition操作回溯到的open函数定义并不能显示出调用sys_open的具体过程,原因就是系统调用方式和常规的函数调用不同。
OABI 和 EABI
在 arm 平台架构中,存在两种不同的 ABI 形式,OABI 和 EABI,OABI 中的 O 是 old 的意思,表示旧有的 ABI,而 EABI 是基于 OABI 上的改进,或者说它更适合目前大多数的硬件,OABI 和 EABI 的区别主要在于浮点的处理和系统调用,浮点的区别不做过多讨论,对于系统调用而言,OABI 和 EABI 最大的区别在于,OABI 的系统调用指令需要传递参数来指定系统调用号,而 EABI 中将系统调用号保存在 r7 中.
所以在系统调用的源码实现中,尽管大多数情况下都是使用 EABI 的系统调用方式,也会保持对 OABI 的兼容。
SVC指令
SVC(Supervisor Call)指令是一种特权指令,用于触发软中断或异常,进入supervisor模式,使得处理器从用户模式切换到supervisor模式,以便执行特权操作,例如系统调用。
ARM架构中的特权模式包括以下几种:
-
用户模式(User mode):也称为非特权模式,用户空间应用程序通常在该模式下运行。在用户模式下,应用程序只能访问受限资源,无法直接执行特权指令或访问特权寄存器。
-
特权模式(Privileged mode):也称为特权级或特权状态。在特权模式下,处理器可以执行特权指令、访问特权寄存器,并且可以执行一些受限制的操作。操作系统内核通常在特权模式下运行,以便执行特权操作,例如处理中断、管理内存、执行系统调用等。
在ARM架构中,特权模式可以进一步细分为以下几种:
-
中断模式(Interrupt mode):用于处理中断请求。当处理器接收到中断请求时,会从当前模式切换到中断模式,并执行相应的中断处理程序。
-
监管者模式(Supervisor mode):也称为超级用户模式。在监管者模式下,操作系统内核执行大部分特权操作,包括管理进程、调度任务、执行系统调用等。监管者模式是操作系统内核的主要执行模式。
-
其他特权模式:ARM架构还包括一些其他特权模式,如快速中断模式(FIQ mode)和异常模式(Abort mode)。这些模式通常用于处理特定类型的中断或异常,以提高系统的响应速度和稳定性。
保存中断上下文
-
保存寄存器状态:处理器中的通用寄存器和特殊寄存器的状态需要保存下来,以便在系统调用完成后能够正确地恢复。通用寄存器保存的是用户空间应用程序的状态,而特殊寄存器保存的是处理器的状态,如程序计数器(PC)、堆栈指针(SP)等。
-
保存堆栈状态:当前用户空间的堆栈状态也需要保存下来。这通常包括保存当前堆栈指针(SP)的值,以及将堆栈指针移动到内核空间的堆栈区域。
-
保存程序计数器:程序计数器(PC)是用于指示下一条要执行的指令的寄存器。在系统调用触发的过程中,需要保存当前用户空间应用程序的程序计数器的值,以便在系统调用完成后能够正确地返回到用户空间继续执行。
-
保存其他状态信息:根据具体的架构和实现,可能还需要保存其他的一些状态信息,如标志寄存器状态等。
参考博文:linux设备驱动模型一字符设备open系统调用流程_open是怎么一步一步调用到cdev的?-CSDN博客
Linux ARM系统调用过程分析(三)——Linux中open系统调用实现原理_sys_open-CSDN博客