核心概念
Brocker:消息队列服务器实体
Exchange(消息交换机):它指定消息按什么规则,路由到哪个队列。
Queue(消息队列载体):每个消息都会被投入到一个或多个队列。
Binding(绑定):它的作用就是把exchange和queue按照路由规则绑定起来。
Routing Key(路由关键字):exchange根据这个关键字进行消息投递;
vhost:权限数据隔离。
Producer(消息生产者):就是投递消息的程序。
Consumer(消息消费者):就是接受消息的程序;
工作模式
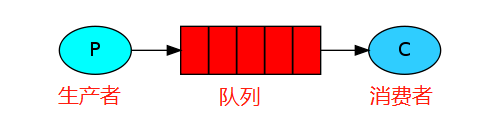
simple模式
简单收发模式,其中一个生产者一个消费者,一个队列。也称为点对点模式
work模式
一个消息生产者,一个交换机,一个消息队列,多个消费者。
生产者P发送消息到队列,多个消费者C消费队列的数据。
工作流队列也被称为公平性队列模式,RabbitMQ将按顺序将每条消息发送给笑一个消费者,每个消费者将获得相同数量的消息。
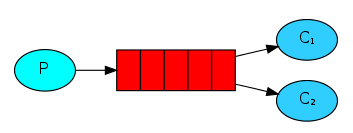
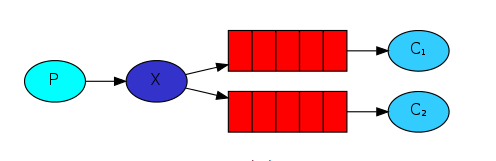
publish/subscribe发布订阅
无选择接收消息,一个生产者,一个Fanout交换机,多个队列,多个消费者。
在应用中,需要将队列绑定到交换机上,一个发送到交换机的消息都会被转发到与该交换机绑定的所有队列上。
生产者P只需吧消息发送到交换机X上,绑定这个交换机的队列都会获得一份一样的数据。
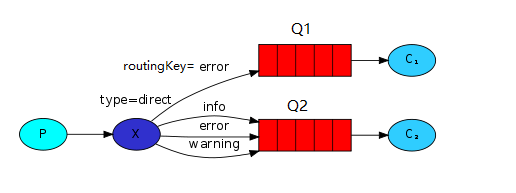
Routing路由模式
在发布订阅模式的基础上,有选择的接收消息,也是通过routing理由进行匹配条件是否满足接收消息,Direct交换机。
生产者P发送数据是要指定交换机(X)和routing发送消息 ,指定的routingKey=error,则队列Q1和队列Q2都会有一份数据,如果指定routingKey=into,或=warning,交换机(X)只会把消息发到Q2队列。
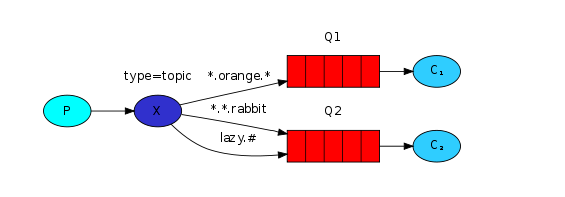
Topic主题模式
topics(主题)模式跟routing路由模式类似,只不过路由模式是指定固定的路由键 routingKey,而主题模式是可以模糊匹配路由键 routingKey,类似于SQL中 = 和 like 的关系。
没匹配routingKey的消息将会被丢弃。
* 代表一个词,# 代表零个或多个
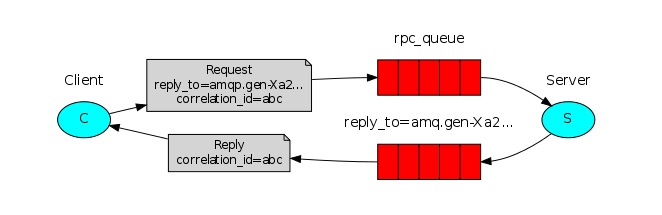
RPC模式
与上面其他5种所不同之处,该模式是拥有请求/回复的。也就是有响应的,上面5种都没有。
RPC是指远程过程调用,也就是说两台服务器A,B,一个应用部署在A服务器上,想要调用B服务器上应用提供的处理业务,处理完后然后在A服务器继续执行下去,把异步的消息以同步的方式执行。
一般都不会选用 RabbitMQ 的 RPC 模式,因为有专门进行远程调用的框架如 Dubbo,用起来会更加方便。
常见命令
- rabbitmqctl list_queues:查看所有队列信息
- rabbitmqctl stop_app:关闭应用
- rabbitmqctl start_app:启动应用
- rabbitmqctl reset:从管理数据库中移除所有数据,例如配置过的用户和vhost,删除所有持久化信息
- rabbitmqctl force_reset:作用和rabbitmqctl reset一样,区别是无条件重置节点,不管当前管理数据库状态以及集群的配置。如果数据库或者集群配置发生错误才使用这个最后的手段
- rabbitmqctl status:节点状态
- rabbitmqctl add_user username password:添加用户
- rabbitmqctl list_users:列出所有用户
- rabbitmqctl list_user_permissions username:列出用户权限
- rabbitmqctl change_password username newpassword:修改密码
- rabbitmqctl add_vhost vhostpath:创建虚拟主机
- rabbitmqctl list_vhosts:列出所有虚拟主机
- rabbitmqctl set_user_tags username administrator : 设置管理员角色
- rabbitmqctl set_permissions -p vhostpath username “." ".” “.*”:设置用户权限
- rabbitmqctl list_permissions -p vhostpath:列出虚拟主机上的所有权限
- rabbitmqctl clear_permissions -p vhostpath username:清除用户权限
- rabbitmqctl -p vhostpath purge_queue blue:清除队列里的消息
- rabbitmqctl delete_user username:删除用户
- rabbitmqctl delete_vhost vhostpath:删除虚拟主机
集群方面:
- rabbitmqctl cluster_status:查看集群状态
- rabbitmqctl forget_cluster_node rabbit@node1:移除指定节点,注意移除的节点必须是从节点,在移除前必须要关掉从节点
- rabbitmqctl join_cluster rabbit@node3:将节点加入到指定集群中
- rabbitmqctl change_cluster_node_type ram:修改node1节点的节点类型从dist改为ram
- rabbitmqctl rename_cluster_node ‘rabbit@node1’ ‘rabbit@node1update’:重命名节点
- rabbitmqctl update_cluster_nodes rabbit@node1:更新节点数据,指定与哪个节点同步
- rabbitmqctl force_boot:强制启动节点
启动
- rabbitmq-server -detached 后台启动
集群搭建
RabbitMQ 集群对延迟非常敏感,应当只在本地局域网内使用。在广域网中不应该使用集群。
普通集群
普通集群,又称为标准集群,具备以下特征:
- 在集群的各个节点间共享部分数据,包括交换机、队列元信息,但不包括队列中的消息
- 当访问集群某节点时,如果队列不在该节点,会从数据所在节点传递到当前节点并返回
- 队列所在节点如果宕机,队列中的消息就会丢失,因此普通集群只是提高了并发能力,并未实现高可用
使用docker搭建rabbitmq集群
docker pull rabbitmq:3.9.15-management
# 运行5672
docker run -d --name rabbitmq5672 \
-p 5672:5672 -p 15672:15672 \
-v /Users/lzq/docker/rabbitmq5672/data:/var/lib/rabbitmq \
-v /Users/lzq/docker/rabbitmq5672/log:/var/log/rabbitmq \
-v /Users/lzq/docker/rabbitmq5672/rabbitmq_delayed_message_exchange-3.9.0.ez:/opt/rabbitmq/plugins/rabbitmq_delayed_message_exchange-3.9.0.ez \
--hostname rabbitmq5672 \
-e RABBITMQ_DEFAULT_VHOST=localhost \
-e RABBITMQ_DEFAULT_USER=root \
-e RABBITMQ_DEFAULT_PASS=root \
-e RABBITMQ_LOGS=/var/log/rabbitmq/rabbitmq.log \
--net=my_net \
-v /etc/localtime:/etc/localtime \
rabbitmq:3.9.29-management
# 运行5673
docker run -d --name rabbitmq5673 \
-p 5673:5672 -p 15673:15672 \
-v /Users/lzq/docker/rabbitmq5673/data:/var/lib/rabbitmq \
-v /Users/lzq/docker/rabbitmq5673/log:/var/log/rabbitmq \
-v /Users/lzq/docker/rabbitmq5673/rabbitmq_delayed_message_exchange-3.9.0.ez:/opt/rabbitmq/plugins/rabbitmq_delayed_message_exchange-3.9.0.ez \
--hostname rabbitmq5673 \
-e RABBITMQ_DEFAULT_VHOST=localhost \
-e RABBITMQ_DEFAULT_USER=root \
-e RABBITMQ_DEFAULT_PASS=root \
-e RABBITMQ_LOGS=/var/log/rabbitmq/rabbitmq.log \
--net=my_net \
-v /etc/localtime:/etc/localtime \
rabbitmq:3.9.29-management
# 运行5674
docker run -d --name rabbitmq5674 \
-p 5674:5672 -p 15674:15672 \
-v /Users/lzq/docker/rabbitmq5674/data:/var/lib/rabbitmq \
-v /Users/lzq/docker/rabbitmq5674/log:/var/log/rabbitmq \
-v /Users/lzq/docker/rabbitmq5674/rabbitmq_delayed_message_exchange-3.9.0.ez:/opt/rabbitmq/plugins/rabbitmq_delayed_message_exchange-3.9.0.ez \
--hostname rabbitmq5674 \
-e RABBITMQ_DEFAULT_VHOST=localhost \
-e RABBITMQ_DEFAULT_USER=root \
-e RABBITMQ_DEFAULT_PASS=root \
-e RABBITMQ_LOGS=/var/log/rabbitmq/rabbitmq.log \
--net=my_net \
-v /etc/localtime:/etc/localtime \
rabbitmq:3.9.29-management
进入第一个节点
docker exec -it rabbitmq5672 bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl start_app
exit
进入第二个节点
docker exec -it rabbitmq5673 bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster rabbit@rabbitmq5672
rabbitmqctl start_app
exit
进入第三个节点
docker exec -it rabbitmq5674 bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster rabbit@rabbitmq5672
rabbitmqctl start_app
exit
**rabbitmqctl join_cluster {cluster_node} [–ram]**表示将节点加入指定集群中。在这个命令执行前需要停止RabbitMQ应用并重置节点。参数“–ram”表示同步 rabbit@rabbitmq01的内存节点,忽略此参数默认为磁盘节点。
rabbitmqctl join_cluster rabbit@rabbitmq5672
移除节点
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl start_app
rabbitmqctl forget_cluster_node rabbit@rabbitmq5674
rabbitmqctl join_cluster rabbit@rabbitmq5672
rabbitmqctl forget_cluster_node --offline rabbit@rabbitmq5672
负载均衡
docker pull haproxy
docker run -d \
-p 5671:5671 \
-p 15671:15671 \
-p 5670:5670 \
-p 15670:15670 \
--net=my_net \
--hostname haproxy \
--name haproxy \
-v /Users/lzq/docker/haproxy/haproxy.cfg:/usr/local/etc/haproxy/haproxy.cfg:ro haproxy
在docker的宿主机上编写haproxy.cfg文件如下
# 全局配置
global
#定义全局的syslog服务器
log 127.0.0.1 local0 info
#每个haproxy进程可以接受的最多并发数
maxconn 4096
#让haproxy以守护进程的方式工作于后台
daemon
#默认参数的配置部分
defaults
log global
#工作模式 http ,tcp 是 4 层,http是 7 层
mode tcp
option tcplog
option dontlognull
#健康检查。3次连接失败就认为服务器不可用,主要通过后面的check检查
retries 3
maxconn 2000
#ha服务器与后端服务器连接超时时间
timeout connect 5s
#客户端超时
timeout client 120s
#服务端超时
timeout server 120s
listen rabbitmq_cluster
#监听地址
bind :5671
#工作模式
mode tcp
#负载均衡方法轮询
balance roundrobin
server rabbit-node01 10.60.57.62:5672 check inter 5000 rise 2 fall 3 weight 1
server rabbit-node02 10.60.57.62:5673 check inter 5000 rise 2 fall 3 weight 1
server rabbit-node03 10.60.57.62:5674 check inter 5000 rise 2 fall 3 weight 1
listen rabbitmq_manager
#监听地址
bind :15671
#工作模式
mode tcp
#负载均衡方法轮询
balance roundrobin
server rabbit-node01 10.60.57.62:15672 check inter 5000 rise 2 fall 3 weight 1
server rabbit-node02 10.60.57.62:15673 check inter 5000 rise 2 fall 3 weight 1
server rabbit-node03 10.60.57.62:15674 check inter 5000 rise 2 fall 3 weight 1
镜像集群
跟普通集群模式相比,该模式加入镜像队列 ,镜像模式有以下特征:
- 镜像队列结构是一主多从,即一个主节点和多个镜像节点。
- 所有操作都由主节点完成,然后同步到镜像节点。
- 如果主节点宕机,镜像节点可以接替成为新的主节点,确保高可用性。但在主从同步完成之前,宕机可能导致数据丢失。
- 镜像模式不具备负载均衡功能,因为所有操作都由主节点完成。然而,不同队列可以有不同的主节点,这可以提高系统的吞吐量。
镜像模式通过数据同步和主节点切换提供了更高的可用性和数据冗余,适合对数据可用性有要求较高的应用场景
镜像模式配置
有三种模式,使用不同的参数来定义镜像策略
exactly 模式
可以精确控制队列在集群中的副本数量。例如:如果将ha-params设置为2,表示每个队列将有2个副本,启动一个是主节点,另一个是镜像节点。如果集群中的节点数不足以维护所需的副本数,队列将被镜像到所有节点。如果有足够多的节点,但其中某些节点出现故障,将在其他节点上创建新的镜像。
配置命令如下:
#进入任意一个rabbitmq节点,执行
rabbitmqctl set_policy ha-two "^two\." '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
- rabbitmqctl set_policy:用于设置策略的RabbitMQ命令。
- ha-two:策略的名称,可以自定义。
- “^two.”:用正则表达式匹配队列的名称,这个策略将应用于所有以 “two.” 开头的队列。
- ‘{“ha-mode”:“exactly”,“ha-params”:2,“ha-sync-mode”:“automatic”}’:策略的具体配置,包括:
- “ha-mode”:“exactly”:指定策略的模式,这里是 “exactly”,表示要设置队列的副本数量。
- “ha-params”:2:指定副本的数量,这里设置为2,表示一个主副本和一个镜像副本。
- “ha-sync-mode”:“automatic”:同步策略,这里设置为 “automatic”,表示新加入的镜像节点会同步主节点中的所有消息,以确保消息的一致性。
all 模式
队列将在集群中的所有节点之间进行镜像,队列将镜像到任何新加入的节点。
将队列镜像到所有的节点会增加额外的压力,包括网络I/O、磁盘I/O和磁盘空间的使用。因此,不建议使用all模式
配置命令如下:
#进入任意一个rabbitmq节点,执行
rabbitmqctl set_policy ha-all "^all\." '{"ha-mode":"all"}'
- ha-all:策略的名称,可以自定义。
- “^all.”:用正则表达式匹配队列的名称,这个策略将应用于所有以 “all.” 开头的队列。
- ‘{“ha-mode”:“all”}’:策略的具体配置,包括:
- “ha-mode”:“all”:指定策略的模式,这里是 “all”,表示要将队列镜像到集群中的所有节点。
nodes 模式
可以明确指定队列应该创建在哪些节点上。如果执行的节点全部存在,队列将在这些节点说上创建。如果指定的节点在集群中存在,但是某些节点不可用,队列将在当前客户端连接到的节点上创建。如果指定的节点在集群中不存在,可能会引发异常。
配置命令如下:
#进入任意一个rabbitmq节点,执行
rabbitmqctl set_policy ha-nodes "^nodes\." '{"ha-mode":"nodes","ha-params":["rabbit@rabbitmq5672", "rabbit@rabbitmq5673"]}'
- rabbitmqctl set_policy:用于设置策略的RabbitMQ命令。
- ha-nodes:策略的名称,可以自定义。
- “^nodes.”:用正则表达式匹配队列的名称,这个策略将应用于所有以 “nodes.” 开头的队列。
- ‘{“ha-mode”:“nodes”,“ha-params”:[“rabbit@nodeA”, “rabbit@nodeB”]}’:策略的具体配置,包括:
- “ha-mode”:“nodes”:指定策略的模式,这里是 “nodes”,表示要指定队列创建在哪些节点上。
- “ha-params”:[“rabbit@rabbitmq5672”, “rabbit@rabbitmq5673”]:指定了队列应该创建在哪些节点上
进入任意一个rabbitmq节点,执行
rabbitmqctl set_policy -p localhost ha "^" '{"ha-mode":"all","ha-sync-mode":"automatic"}'
rabbitmqctl set_policy -p /study ha "^" '{"ha-mode":"all","ha-sync-mode":"automatic"}'
可以设置镜像队列,"^"表示匹配所有队列,-p表示针对当前vhost,即所有队列在各个节点上都会有备份。在集群中,只需要在一个节点上设置镜像队列,设置操作会同步到其他节点。
注意:例如:队列A存在主节点rabbit5672,镜像节点rabbit5673、rabbit5674。如果rabbit5672下线,rabbit5673和rabbit5674会升成主节点,当rabbit5672节点重新上线后,会变为镜像节点。
仲裁队列集群
尽管镜像模式能够做到主从复制,但是并不是强一致的,因此可能还是会导致数据的丢失。
仲裁队列是 3.8 版本以后才有的新功能,用来替代镜像队列,属于主从模式,支持基于 Raft 协议强一致的主从数据同步。
具有以下特点:
- 与镜像队列一样,都是主从模式,支持主从数据同步
- 使用非常简单,没有复杂的配置
- 主从同步基于Raft协议,强一致
添加仲裁队列的方式非常简单,只需要在创建队列的使用指定队列的类型为 Quorum 即可
生产者确认
confirm模式
此模式是作用在生产者端的,开启了这个模式就可以知道消息有没有发送到交换机上,不管有没有发送到都会触发回调方法。
publisher-confirm-type: correlated
rabbitTemplate.setConfirmCallback((correlationData, ack, cause) -> {
System.out.println("confirm,correlationData:" + correlationData);
System.out.println("confirm,ack:" + ack);
System.out.println("confirm,cause:" + cause);
});
returns模式
作用于生产者端的,这个模式iuu是知道消息有没有发送到对应的队列上,如果没有发送到了对接的队列才会触发回调方法
#设置交换机确认发布模式,默认为禁用
publisher-confirm-type: correlated
#退回消息
publisher-returns: true
rabbitTemplate.setReturnsCallback(returned -> {
System.out.println("returnedMessage,getMessage:" + returned.getMessage());
System.out.println("returnedMessage,getExchange:" + returned.getExchange());
System.out.println("returnedMessage,getRoutingKey:" + returned.getRoutingKey());
System.out.println("returnedMessage,getReplyCode:" + returned.getReplyCode());
System.out.println("returnedMessage,getReplyText:" + returned.getReplyText());
});
死信队列
死信队列,英文缩写:DLX 。DeadLetter Exchange(死信交换机),当消息成为Dead message后,可以被重新发送到另一个交换机,这个交换机就是DLX。
消息成为死信的三种情况
- 队列消息数量达到限制,比如队列最大只能存储10条消息,但是发送了11条消息,根据先进先出,最先发送的消息会进入死信队列
- 消费者拒绝消费消息,basicNack/basicReject,并且不把消息重新放入原目标队列,requeue=false;
- 原队列存在消息过期设置,消息达到超时时间未被消费
死信消息的三种处理方式
- 丢弃。如果不是很重要,可以选择丢弃
- 记录死信入库。然后做后续要业务的分析或处理
- 通过死信队列也有负责监听死信的应用程序进行处理
队列绑定死信交换机:
给队列设置参数: x-dead-letter-exchange 和 x-dead-letter-routing-key
Map<String, Object> arguments = new HashMap<>();
arguments.put("x-dead-letter-exchange", exchange_dead);
arguments.put("x-dead-letter-routing-key", routing_dead_routing_key);
return new Queue(queue_dead, true, false, false, arguments);
延迟队列
延迟队列存储的对象肯定是对应的延时消息,所谓”延时消息”是指当消息被发送以后,并不想让消费者立即拿到消息,而是等待指定时间后,消费者才拿到这个消息进行消费。
在RabbitMQ中并未提供延迟队列功能,但是可以使用:TTL+死信队列 组合实现延迟队列的效果。
延迟插件
没有安装延迟插件报错如下:
Caused by: com.rabbitmq.client.ShutdownSignalException: connection error; protocol method: #method<connection.close>(reply-code=503, reply-text=COMMAND_INVALID - invalid exchange type 'x-delayed-message', class-id=40, method-id=10)
at com.rabbitmq.utility.ValueOrException.getValue(ValueOrException.java:66)
at com.rabbitmq.utility.BlockingValueOrException.uninterruptibleGetValue(BlockingValueOrException.java:36)
at com.rabbitmq.client.impl.AMQChannel$BlockingRpcContinuation.getReply(AMQChannel.java:505)
at com.rabbitmq.client.impl.AMQChannel.privateRpc(AMQChannel.java:296)
at com.rabbitmq.client.impl.AMQChannel.exnWrappingRpc(AMQChannel.java:144)
... 133 common frames omitted
先确定docker中rabbitmq的版本号,如果镜像中没有版本号,使用命令docker inspect rabbitmq:management查看RABBITMQ_VERSION字段。根据当前版本下载延迟队列插件。
下载RabbitMQ延迟插件:https://github.com/rabbitmq/rabbitmq-delayed-message-exchange/releases
rabbitmq-delayed-message-exchange插件为交换机提供了新的类型:x-delayed-message
开启延迟插件命令:
#进入容器中执行
rabbitmq-plugins enable rabbitmq_delayed_message_exchange
在管理页面上Exchanges新增页面能够看到x-delayed-message类型后即可
插件的禁用要慎重,以下方式可以实现将插件禁用,但是注意如果此时还有延迟消息未消费,那么禁掉此插件后所有的未消费的延迟消息将丢失。
rabbitmq-plugins disable rabbitmq_delayed_message_exchange
RabbitMQ脑裂
所谓的脑裂问题,就是在多集群中节点与节点之间失联,都认为对方出现故障,而自身裂变为独立的个体,那么久出现了抢夺对方的资源,争抢启动,至此就发生了事故,RabbitMQ
Spring-RabbitMQ并发消费
RabbitListenerContainerFactory的代码如下:
@Bean
public RabbitListenerContainerFactory<?> rabbitListenerContainerFactory(ConnectionFactory connectionFactory) {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
factory.setConnectionFactory(connectionFactory);
factory.setMessageConverter(new Jackson2JsonMessageConverter());
factory.setAcknowledgeMode(AcknowledgeMode.MANUAL);
//设置线程并发数,默认1
factory.setConcurrentConsumers(2);
//最大线程数,默认null
factory.setMaxConcurrentConsumers(5);
//设置本地缓存消息数,默认250
factory.setPrefetchCount(1);
//连续成功处理消息数,进行扩容,默认10
factory.setConsecutiveActiveTrigger(3);
//连续空闲数,进行缩容,默认10
factory.setConsecutiveIdleTrigger(3);
//默认等待队列超时时间,默认1000ms
factory.setReceiveTimeout(1000L);
return factory;
}
concurrentConsumers
concurrentConsumers默认为1,即每个Listener容器静静开启一个线程去处理消息
maxConcurrentConsumers
private final class AsyncMessageProcessingConsumer implements Runnable {
@Override // NOSONAR - complexity - many catch blocks
public void run() { // NOSONAR - line count
if (!isActive()) {
this.start.countDown();
return;
}
try {
initialize();
while (isActive(this.consumer) || this.consumer.hasDelivery() || !this.consumer.cancelled()) {
mainLoop();
}
}
}
private void mainLoop() throws Exception { // NOSONAR Exception
try {
if (SimpleMessageListenerContainer.this.stopNow.get()) {
this.consumer.forceCloseAndClearQueue();
return;
}
boolean receivedOk = receiveAndExecute(this.consumer); // At least one message received
if (SimpleMessageListenerContainer.this.maxConcurrentConsumers != null) {
checkAdjust(receivedOk);
}
long idleEventInterval = getIdleEventInterval();
if (idleEventInterval > 0) {
if (receivedOk) {
updateLastReceive();
}
else {
long now = System.currentTimeMillis();
long lastAlertAt = SimpleMessageListenerContainer.this.lastNoMessageAlert.get();
long lastReceive = getLastReceive();
if (now > lastReceive + idleEventInterval
&& now > lastAlertAt + idleEventInterval
&& SimpleMessageListenerContainer.this.lastNoMessageAlert
.compareAndSet(lastAlertAt, now)) {
publishIdleContainerEvent(now - lastReceive);
}
}
}
}
prefetchCount
每个消费者会在MQ预取一些消息放入内存的LinkedBlockingQueue中进行消费,这个值越高,消息传递的越快,单非顺序处理消息的风险更高。如果ack模式为none,则忽略。将增加此值以匹配txSize或messagePerAck。从2.0开始默认为250;设置为1将还原为以前的行为。
不过在在有些情况下,尤其是处理速度比较慢的大消息,消息可能在内存中大量堆积,消耗大量内存,以及对于一些严格要求顺序的消息,prefetchCount应当设置为1
搭建环境常用命令
linux中以守护程序的形式在后台启动
rabbitmq-server -detached
新建一个用户
rabbitmqctl add_user root root
创建一个虚拟环境
rabbitmqctl add_vhost /study
设置管理员角色
rabbitmqctl set_user_tags root administrator
设置权限
rabbitmqctl set_permissions -p /study root “." ".” “.*”