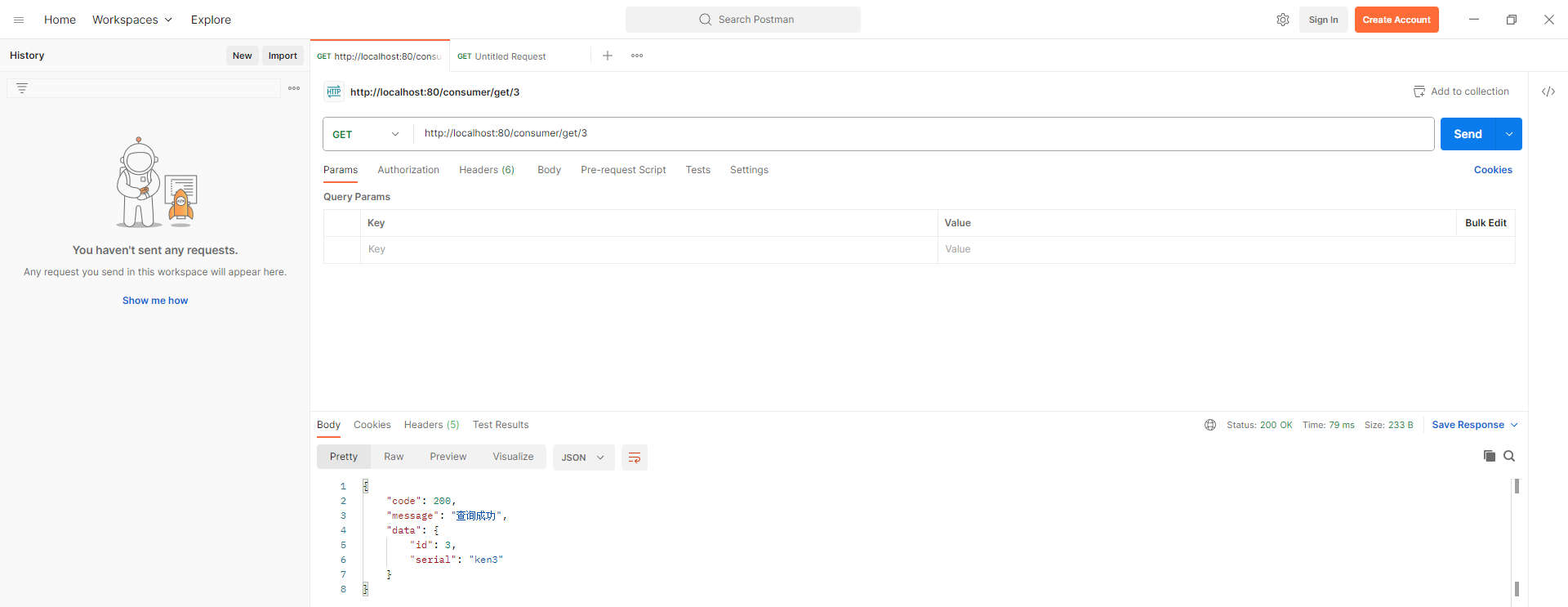
AIDE:自动驾驶目标检测的自动数据引擎
- 摘要
- Introduction
- Related Works
- Method
- Data Feeder
- Model Updater
- 4 Experiments
摘要
自动驾驶车辆(AV)系统依赖于健壮的感知模型作为安全保证的基石。然而,道路上遇到的物体表现出长尾分布,罕见或未见过的类别对部署的感知模型提出了挑战。
这需要耗费大量人力进行持续的数据策划和标注。作者 Proposal 利用视觉语言和大型语言模型最近的进展来设计一个自动数据引擎(AIDE),它能自动识别问题,高效策划数据,通过自动标注改进模型,并通过生成多样化场景来验证模型。
这个过程是迭代进行的,允许模型持续自我提升。作者进一步为AV数据集上的开放世界检测建立了一个基准,以全面评估各种学习范式,展示了作者方法在降低成本的同时具有优越的性能。
Introduction
自动驾驶车辆(AVs)在一个不断变化的世界中运行,遭遇着在长尾分布中的各种物体和情景。这种开放世界的特性对AV系统提出了重大挑战,因为这是一个对安全至关重要的应用,必须部署可靠且训练有素的模型。随着环境的发展,对持续模型改进的需求变得明显,要求具备应对突发事件的可适应性。
尽管每分钟在路上收集到的大量数据,但由于难以辨别哪些数据值得利用,其有效利用率仍然很低。尽管业界存在解决这一问题的方案[1, 2],但它们往往是商业机密,并且可能需要大量的人力。因此,开发一个全面的自动化数据引擎可以降低自动驾驶行业的进入门槛。
设计自动化数据引擎可能具有挑战性,但视觉-语言模型(VLMs)和大型语言模型(LLMs)的存在为这些难题开辟了新的途径。传统的数据引擎可以分为发现问题、策划和标注数据、模型训练和评估等步骤,所有这些步骤都可以从自动化中受益。
在本文中,作者提出了一个自动改进数据引擎(称为AIDE),它利用VLMs和LLMs来自动化数据引擎。具体来说,作者使用VLMs来识别问题, Query 相关数据,自动标注数据,并与LLMs一起验证。高级步骤在图1顶部显示。
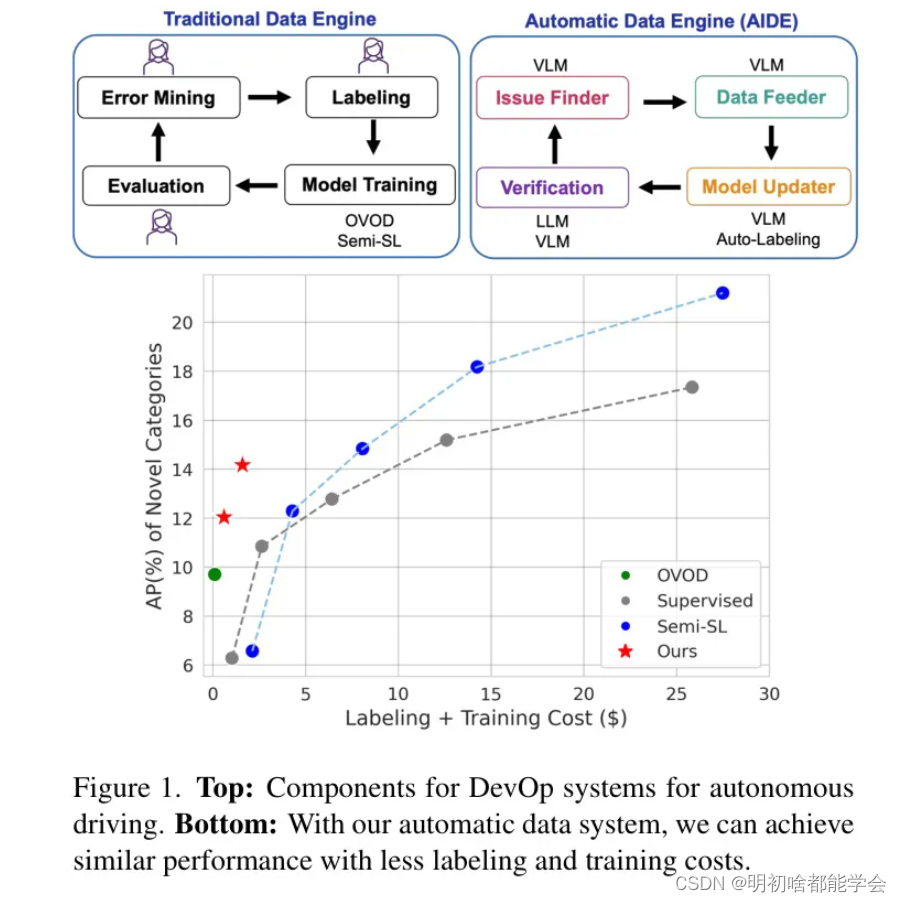
与依赖大量人工标注和干预的传统数据引擎相比,AIDE通过利用预训练的视觉语言模型(VLMs)和大型语言模型(LLMs)来自动化这一过程。与业界其他专有解决方案[1, 2]不同,作者提供了高效的解决方案以降低入门门槛。尽管开放词汇目标检测(OVOD)方法[3, 4]无需任何人工标注,它们作为检测新目标的一个良好起点,但在自动驾驶(AV)数据集上的表现相较于监督学习方法有所不足。另一条旨在最小化标注成本的研究线路是半监督学习[5, 6]和主动学习[7, 8, 9, 10]。尽管它们生成伪标签,但与作者的方法相比,它们仍然没有充分利用在道路上收集的大量数据,作者的方法利用预训练的VLMs和LLMs以更好地利用数据。
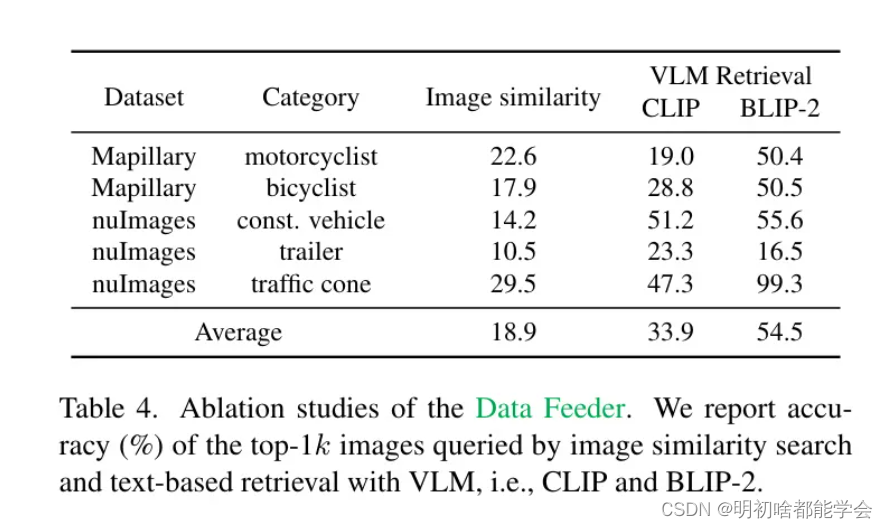
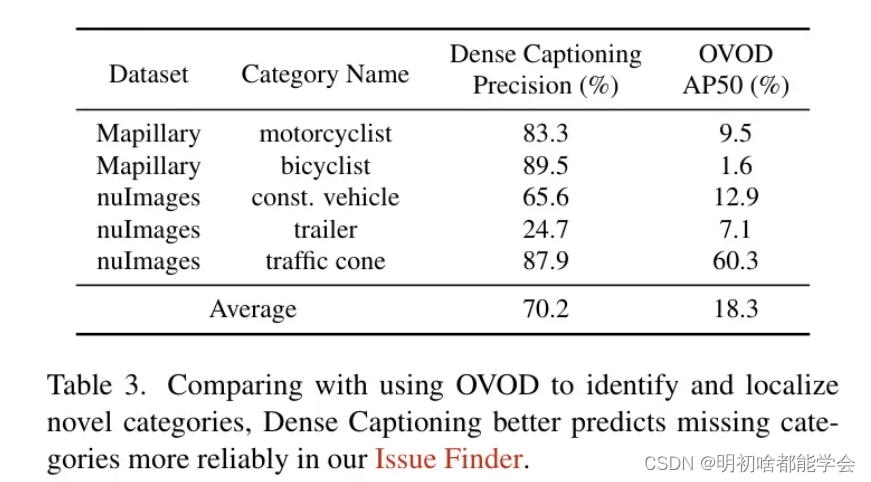
AIDE的详细步骤如图2所示。在问题查找器中,作者使用密集字幕模型详细描述图像,然后匹配描述中的物体是否包含在标签空间或预测中。这是基于一个合理但之前未被利用的假设,即大型图像字幕模型在零样本设置中比OVOD(表3)更鲁棒。下一步是使用作者的数据馈送器找到可能包含新类别的相关图像。作者发现VLM比使用图像相似性检索图像(表4)能获得更准确的图像检索。
然后,作者使用现有的标签空间加上新类别提示OVOD方法,即OWL-v2 [11],对 Query 的图像生成预测。为了过滤这些伪预测,作者使用CLIP对伪框进行零样本分类,为新颖类别生成伪标签。最后,作者在验证中使用LLM,例如ChatGPT [12],给定制的新颖物体生成多样的场景描述。给定生成的描述,作者再次使用VLM Query 相关图像以评估更新后的模型。为确保准确性,作者请人类审查新类别的预测是否正确。如果不正确,作者请人类提供真实标签,这些标签用于进一步改进模型。(图6)


为了验证作者的人工智能开发环境(AIDE)的有效性,作者提出了一个新的基准,在现有的音频视觉(AV)数据集上全面比较作者的AIDE与其他范式。通过作者的问题发现器、数据喂入器和模型更新器,作者在新类别上实现了2.3%的平均精度(AP)提升,与OWL-v2相比,在没有任何人工标注的情况下,并且在已知类别上以8.9%的AP超过了OWL-v2(表1)。作者还展示了通过单一轮次的验证,作者的自动数据引擎可以在不遗忘已知类别的情况下,进一步在新类别上带来2.2%的AP提升,如图1所示。总的来说,作者的贡献有两方面:
作者提出了一种新颖的设计范式,用于自动驾驶的自动数据引擎,该引擎结合了利用视觉语言模型(VLM)的自动数据 Query 和标注以及使用伪标签的持续学习。当扩展到新的类别时,这种方法在检测性能与数据成本之间取得了极好的平衡。
作者引入了一个新的基准,用于评估用于自动驾驶视觉感知的这种自动数据引擎,它能够在开放词汇检测、半监督和持续学习等多个范式下提供综合洞见。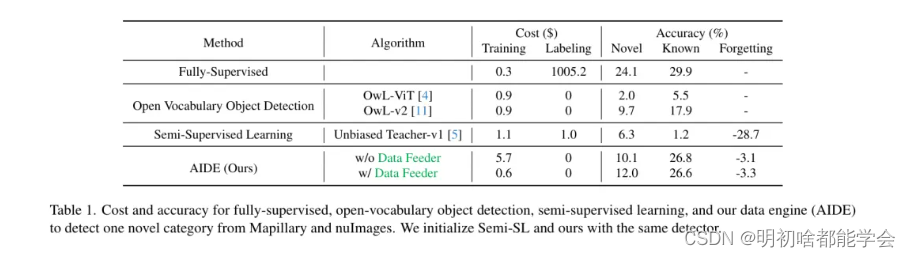
Related Works
自动驾驶车辆(AV)数据引擎 利用自动驾驶车辆收集的大规模数据对于加速AV系统的迭代开发至关重要[13]。现有文献主要关注开发通用[14, 15]学习引擎或特定[16]数据引擎,其中大部分[17, 18]主要关注模型训练部分。然而,一个完全功能的AV数据引擎需要问题识别、数据整理、模型再训练、验证等。彻底的审查揭示在学术界缺乏深入探讨AV数据引擎的系统性研究论文或文献,其中最近的调查[13]也强调了这个领域研究的不足。另一方面,现有针对AV数据系统的解决方案[1, 2]主要依赖于数据基础设施的设计,仍然需要大量人力和干预,从而限制了其维护的简便性、可负担性和可扩展性。相比之下,本文利用视觉语言模型(VLMs)[19, 20, 21]的蓬勃发展来设计作者的数据引擎,其中它们强大的开放世界感知能力大大提高了作者引擎的可扩展性,使得在检测新类别时扩展作者的AV变得更加可负担。据作者所知,本文也是首次提供了将VLMs整合到AV数据引擎中的系统性设计工作。
新型目标检测 在过去的几十年里,传统的2D目标检测取得了巨大进步[22, 23],但其封闭的标签空间使得对未见类别的检测变得不可行。另一方面,开放词汇目标检测(OVOD)[4, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39]方法承诺通过简单的文本提示来检测任何物体。然而,由于它们必须在预训练类别的特异性和未见类别的泛化性之间保持平衡,其性能仍然不如封闭集目标检测。为了扩展开放词汇检测器(OVD)的能力,近期的研究要么使用弱标注(例如,图像标题)[40]预训练OVD,要么在日常目标数据集[41, 42]或网络规模数据集[4, 43]上执行自训练。然而,在提高新类别的同时减轻已知类别的灾难性遗忘之间的权衡仍然是一个尚未解决的问题[11],这使得它难以适应如自动驾驶等特定任务应用。
另一方面,有限的研究关注于自动驾驶车辆(AVs)的新颖目标检测。这尤其关键,因为对未见物体的假阴性检测可能导致自动驾驶车辆发生致命后果。现有的开放世界目标检测(OVOD)方法大多在一般物体数据集上进行基准测试[44, 42],而对自动驾驶车辆数据集[45, 46, 47, 48, 49, 50]的关注较少。与在OVOD中追求普遍性不同,自动驾驶车辆的感知有其领域关切,这些关切来自于车载相机捕获的图像过程以及由于场景先验(例如,道路/街道物体)所决定的物体类别,这要求进行特定任务的设计,以实现高效且可扩展的系统,在车辆生命周期内不断迭代增强对新颖物体的检测能力。为了在特异性和普遍性之间取得更好的折中,作者提出的AIDE方法迭代地扩展了闭集检测器的标签空间,这样作者可以在新颖和已知类别上都保持良好的性能,以实现更好的检测。
半监督学习(Semi-SL)和主动学习(AL):随着自动驾驶车辆(AVs)在运营中不断收集数据,一种原生的解决方案来启用新类别检测就是手动在收集的 未标注 数据集中识别出新类别,给它们打上标签,然后再训练检测器。半监督学习 和主动学习 似乎有所帮助,因为它们仅需要少量标记数据来初始化训练。然而,当AVs给出大量 未标注 数据时,即使是为新类别标记少量的数据也将是具有挑战性和成本高昂的 。此外,半监督学习和主动学习都假设标记和 未标注 数据来自相同的分布 ,并且共享相同的标签空间。但是,当新类别出现时,这一假设不再成立,不可避免地导致标签空间的变化。仅在新类别上简单微调检测器将导致对之前学习的已知类别的灾难性遗忘 [64, 65, 66]。然而,针对目标检测的半监督学习方法没有考虑到持续学习,而现有的持续半监督学习方法 [67, 68, 69, 70] 也专门针对图像分类,不适用于目标检测。
Method
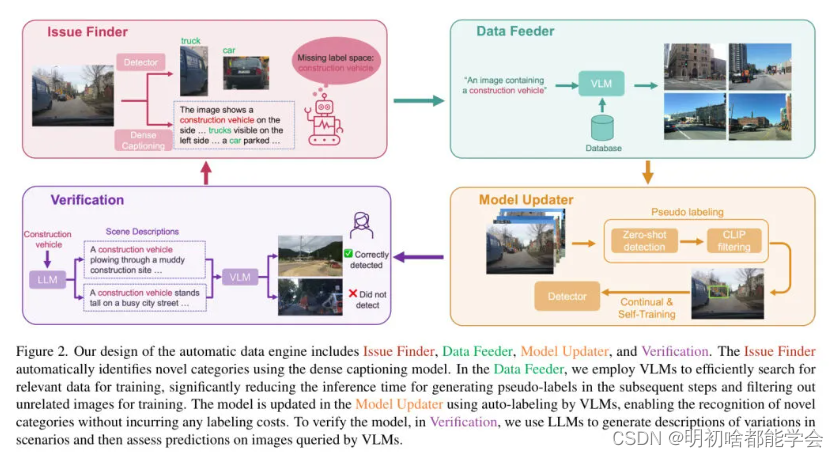
本节展示了作者提出的AIIDE,它由四个组件组成:问题发现器、数据喂入器、模型更新器和验证。问题发现器通过比较给定图像的检测结果和密集字幕,自动识别现有标签空间中缺失的类别。这会触发数据喂入器执行文本引导的检索,从AVs收集的大型图像库中获取相关图像。然后,模型更新器自动标记 Query 的图像,并使用伪标签在现有检测器上持续训练新类别。更新后的检测器随后被传递到验证模块,在不同的场景下进行评估,并在需要时触发新一轮迭代。作者在图2中概述了作者的系统设计。
Issue Finder
鉴于自动驾驶车辆在日常运营中收集的大量未标注数据,要识别现有标签空间中缺失的类别是困难的,因为这需要人类广泛比较检测结果和图像上下文以找出差异,这阻碍了自动驾驶系统的迭代发展。为了降低这一难度,作者考虑采用多模态密集字幕生成(MMDC)模型来自动化这一过程。
由于像Otter [20]这样的MMDC模型是用数百万个多模态上下文指令调整数据集进行训练的,它们能够提供如图3所示的场景上下文的细粒度和全面描述,并且作者推测,它们可能比OVOD方法更有可能返回对新类别所寻求标签的同义词,而不是为新类别检测边界框。具体来说,未标注的图像将分别传递给车上部署的检测器和MMDC模型,以获取预测的类别列表和图像的详细描述。通过基本的文本处理,作者可以轻松识别模型无法检测的新类别。在这种情况下,作者的数据引擎将触发数据馈送器 Query 相关图像,以逐步训练检测器,相应地扩展其标签空间。
Data Feeder
Data Feeder的目的首先是要 Query 可能包含新类别有意义图像。
(1)减少伪标签(pseudo-labeling)的搜索空间并在模型更新器(Model Updater)中加速伪标签过程。
(2)在训练过程中移除琐碎或不相关的图像,以此作者可以减少训练时间同时提高性能。
这在每天可以收集大量数据的现实世界场景中尤为重要。由于新类别可能是任意的和开放词汇的,一个简单的解决方案是利用特征相似性,比如通过CLIP [71]的图像特征相似性来搜索与问题发现器(Issue Finder)输入图像相似的图像。
然而,作者发现由于AV数据集的高多样性(见表4),图像相似性不能可靠地识别足够数量的相关图像。相反,作者的数据喂食器使用视觉语言模型(VLMs)在图像池上执行文本引导的图像检索,以 Query 与新类别相关的图像。考虑到BLIP-2 [21]在开放词汇文本引导检索方面的强大能力,作者选择了它。确切地说,给定一张图像和一个特定的文本输入,作者测量它们从BLIP-2得到的嵌入之间的余弦相似性,并只检索顶部-的图像以供在作者的模型更新器中进行进一步标注。对于文本提示,作者尝试了常见的提示工程实践 [71],并发现像 “包含的图像” 这样的模板在实践中可以很容易地为新类别提供良好的精确性和召回率。图4展示了一些检索到的图像的示例。

Model Updater
作者的模型更新器的目标是让检测器学会在没有人工标注的情况下检测新物体。为此,作者对数据馈送器 Query 的图像进行伪标签处理,然后使用它们来训练作者的检测器。
3.3.1 Two-Stage Pseudo-Labeling
受到之前在目标检测中伪标签化成功的启发[41],作者将伪标签化过程设计为两部分:框生成和标签生成。这种两阶段框架可以帮助作者更好地剖析伪标签生成问题,并提高标签生成的质量。框生成的目标是尽可能识别图像中的多个目标 Proposal ,即对新颖类别的高召回率定位,以确保标签生成有足够的候选数量。为此,可以考虑使用在闭集标签空间[41]上预训练的区域 Proposal 网络(RPN)和开放词汇检测器(OVD)[11],其中前者可以定位通用目标,而后者可以执行文本引导的定位。作者观察到,当前最优的OVD,即自行在网页级数据集[43]上训练的OWL-v2[11],与RPN相比,在定位新颖类别上展现出更高的召回率。作者推测,RPN的 Proposal 可能容易偏向于预训练的类别。
因此,作者选择OWL-v2作为作者的零样本检测器来获取边界框 Proposal 。具体来说,作者将问题查找器提供的新的类别名称追加到作者现有的标签空间中,并创建文本提示,然后提示OWL-v2对图像进行推理。请注意,作者只保留边界框 Proposal ,并从OWL-v2的预测中移除标签。
这是因为作者凭经验发现,OWL-v2在AV数据集中呈现的新类别上不能达到可靠的精确度,例如,在AV数据集的新类别上平均准确率小于10%[45, 50],而在LVIS[42]数据集的新类别上可以获得大于40%的AP。作者推测,这种性能下降可能来自在AV场景中收集的图像的域偏移。例如,OWL-v2的预训练数据主要来自人类近距离捕捉的日常图像。然而,由于车载摄像头与街道物体的距离较远,图像中的街道物体通常较小,且AV数据集中的图像长宽比相对较大,这使得OWL-v2难以对物体 Proposal 进行正确分类。
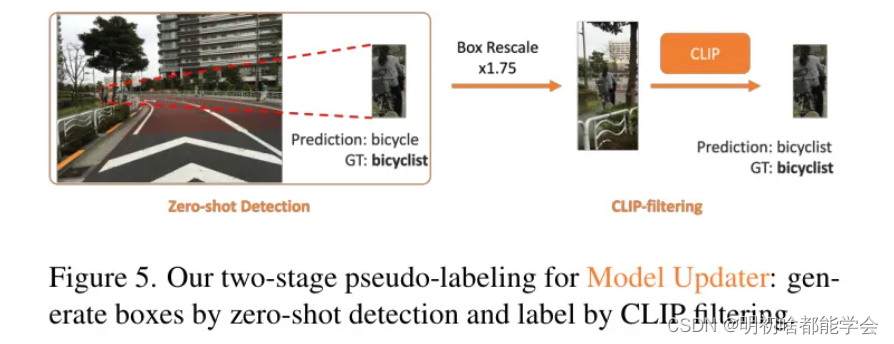
受此洞察的启发,作者考虑使用CLIP [71] 进行另一轮标签过滤,以净化OWL-v2的预测并生成伪标签。具体来说,作者将OWL-v2的框预测传递给原始的CLIP模型 [71] 进行零样本分类(ZSC),如图5所示。为了减轻上述提到的长宽比问题,作者扩大了框的大小来裁剪图像,然后将裁剪的图像块发送给CLIP进行ZSC。这可以包含更多的场景上下文信息,帮助CLIP更好地区分新颖类别和已知类别。关于CLIP进行零样本分类的标签空间,作者首先创建了一个基本标签空间,这是作者从作者预训练的数据集和COCO [44]的标签空间组合而成,以确保作者能够大部分覆盖可能出现在街上的日常物品。当Issue Finder识别出基本标签空间中没有的新颖类别时,基本标签空间将自动扩展。
3.3.2 Continual Training with Pseudo-labels
直接用作者现有检测器在新型类别伪标签上进行训练面临挑战,因为这些标签可能导致检测器过拟合,并且灾难性地忘记已知的类别。这个问题之所以出现,是因为 未标注 的数据可能同时包含检测器先前学过的新型类别和已知类别。如果没有那些已知类别的标签,而只有新型类别的标签,模型可能会错误地抑制对已知类别的预测,而只专注于预测新型类别。
随着训练的进行,已知类别会逐渐从记忆中消失。为了解决这个问题,作者从现有的自我训练策略中获得灵感,并包含了已训练过的已知类别的伪标签。因此,作者现有的检测器用新型类别和已知类别的伪标签进行更新。为了获得已知类别的伪标签,作者首先使用检测器对数据进行推理,然后应用OWL-v2到数据上。从经验上讲,作者发现包括已知类别的伪标签有助于模型区分已知类别和新型类别,提升了新型类别的性能,并减轻了与已知类别相关的灾难性遗忘问题。另外,考虑到已知类别和新型类别的伪标签可能并不完美,作者对伪标签进行了筛选。对于已知类别,作者只使用检测器预测置信度高的伪标签。对于新型类别,作者已经如第3.3.1节所述,集成了CLIP来过滤伪标签。
Verification
验证步骤旨在评估更新后的检测器是否能够在不同情境下检测到新类别,以确保模型能够处理预期之外或未见过的情境。为此,作者用新类别的名称提示ChatGPT [12]生成多样的场景描述。这些描述包含了情境的各种变化,比如物体的不同外观、周围的物体、一天中的时间、天气条件等。
对于每个场景描述,作者再次使用BLIP-2 Query 相关的图像,这些图像用于测试模型的鲁棒性。为确保准确性,作者请人类审核新类别的预测是否正确。如果预测正确,检测器就通过了单元测试。否则,作者请人类提供真实标签,这可以用于进一步改进模型。与现有的人手工逐一检查模型预测的解决方案相比,作者的验证方法利用了大型语言模型来通过多样化场景生成寻找潜在的失败案例,这样可以大幅节省搜索成本,同时验证一个正确检测甚至修正一个错误检测的成本也更低。
4 Experiments
Experimental Setting
数据集和新型类别选择 在实际应用中,自动驾驶视觉系统几乎不可能仅用单一数据源进行训练,例如,自动驾驶车辆可能在世界各地不同地点收集数据。为了真实地模拟这一特性,作者利用现有的自动驾驶数据集来联合训练作者的闭集检测器,包括 Mapillary [50],Cityscapes [47],nuImages [45],BDD100k [49],Waymo [46] 和 KITTI [48]。作者将这个预训练检测器作为监督训练、半监督学习(Semi-SL)和作者的AIDE的初始化,以便进行公平的比较。合并标签空间后,总共有46个类别。
为了模拟新型类别,并确保所选类别对于街道上的自动驾驶具有意义和重要性,作者从 Mapillary 中选择了“摩托车手”和“自行车手”,从 nuImages 中选择了“施工车辆”、“拖车”和“交通锥”。其余的41个类别设置为已知。作者在联合数据集中移除了这些类别的所有标注,并也移除了具有相似语义含义的相关类别,例如,“自行车手”与“骑手”。关于数据集统计的更多详细信息,作者将在补充材料中提供。
对比方法 据作者所知,关于针对自动驾驶系统新颖目标检测的自动数据引擎的系统性设计工作甚少。因此,很难为作者的AIDE找到一个可比较的对应物。
为此,作者将评估分解为两部分:
在新型目标检测的性能上,与替代的检测方法和学习范式进行比较;2. 对自动数据引擎每一步的消融研究与分析。
对于(1),由于作者的AIDE可以让检测器无需任何标签就能检测到新的类别,作者首先将作者的方法与零样本OVOD方法在新类别性能上进行比较。
此外,为了展示作者的AIDE在降低标签成本方面的效率与有效性,作者进一步与半监督学习(Semi-SL)和全监督学习进行比较,后者使用不同比例的真实标签训练检测器。具体来说,作者将作者的数据引擎与最先进(SOTA)的OVOD方法如OWL-v2 [11]、OWL-ViT [4]以及像Unbiased Teacher [5, 6]这样的半监督学习方法进行了比较。
实验协议 作者将五个选定类别中的每一个都视为新类别,并分别进行实验,以模拟作者的问题发现器一次识别一个新类别的场景。对于半监督学习方法,作者为训练提供了不同数量的真实图像。每张图像可能包含一个或多个新类别的目标。作者在新类别的数据集上评估所有比较方法,以保证公平比较。
评估 由于作者的AI辅助开发环境(AIDE)为自动驾驶视觉(AV)系统自动化了整个数据策展、模型训练和验证过程,作者对于作者的引擎如何在图像搜索和标注的成本与新目标检测性能之间取得平衡感兴趣。作者测量了人工标注成本[72]以及GPU推理成本[73],即在作者的AIDE中使用视觉语言模型/大型语言模型以及使用伪标签为作者的AIDE训练模型或使用 GT 标签为比较方法训练模型的成本,在图1中表示为“标注+训练成本”。一个边界框的标注成本为0.06美元[72],而GPU成本为每小时1.1美元[73]。ChatGPT的成本可以忽略不计(小于0.01美元)。
实验细节 鉴于推理的实时性要求,作者选择Fast-RCNN [22]作为检测器,而不是像OWL-ViT [4]这样的OVOD方法,因为OWL-ViT的每秒帧数(FPS)仅为3。作者运行作者的AIDE来迭代地提高其检测新目标的能力。对于多数据集训练,作者遵循来自[74]的相同方法。对于每个新类别,作者以5e-4的学习率进行3000次迭代训练,如果其他比较方法需要训练,作者也使用相同的超参数。作者将在补充材料中附上作者完整的实验细节。
Overall Performance
在本节中,作者提供了在完整周期内运行作者的AIDE后新目标检测的整体性能。作者的结果展示在图1和表1中。与当前最高水平的OVOD方法,OwL-v2 [11]相比,作者的方法在新型类别上提高了2.3%AP,在已知类别上提高了8.7%AP,表明作者的AIDE可以从挖掘OVOD方法中的开放词汇知识中受益。
这是由于作者在3.3.2节中描述的简单而有效的持续训练策略。此外,与半监督学习方法相比,作者的AIDE在灾难性遗忘方面的问题要小得多,因为当前的半监督学习方法在目标检测中并不包含持续学习设置。关于持续半监督学习[67, 70]的现有研究仅考虑图像分类,不适用于目标检测。结合作者的AIDE,无论是否使用数据馈送器,都显而易见,作者的数据馈送器可以充分减少推理时间成本,因为数据馈送器可以预先过滤不相关的图像,模型更新器只需要在少量相关图像上分配伪标签。表1显示,预先过滤可以在新型类别上获得更好的AP。