ReID(Re-Identification,即对摄像机视野外的人进行再识别)


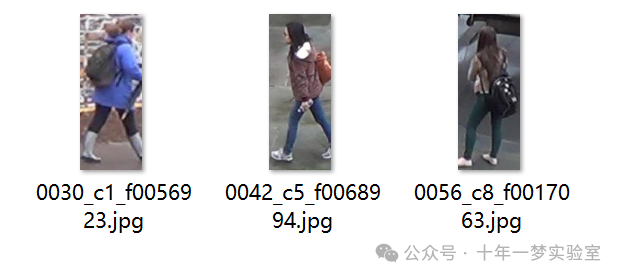
0030_c1_f0056923.jpg

0042_c5_f0068994.jpg

0056_c8_f0017063.jpg
以上为输出结果:result文件夹下

galleryLIst.txt

queryList.txt
模型下载:
https://github.com/ReID-Team/ReID_extra_testdata/tree/main
https://drive.google.com/drive/folders/1wFGcuolSzX3_PqNKb4BAV3DNac7tYpc2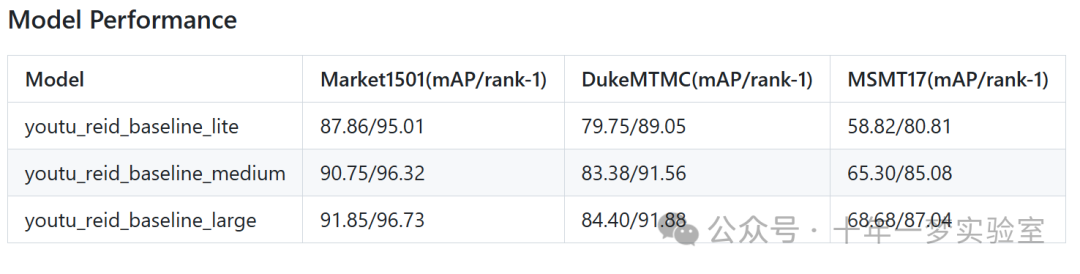
这段代码是一个使用OpenCV库实现的人员识别(ReID,Re-Identification)系统。程序的主要功能是用于处理图像数据,根据查询图片(queries)识别并匹配图库中(gallery)的图片。
首先,导入所需的头文件,包括标准输入输出(iostream)、文件流(fstream),以及OpenCV库中的图像处理(imgproc)、图像显示(highgui)和深度神经网络(dnn)相关的模块。
定义命令行参数,并使用OpenCV的CommandLineParser类来解析输入参数。参数包括模型文件路径、查询图像列表路径、图库图像列表路径、批次大小、输入图像调整大小的高和宽、可视化时显示的最多图库图像数(topk)、可视化结果保存路径、计算后端和目标计算设备的设置。
接下来定义一个cv::reid命名空间,包含一系列函数:
preprocess:预处理函数,对读入的图像进行标准化处理,按照给定的均值和标准差进行缩放。
normalization:特征归一化函数,将特征向量转换为单位向量。
extractFeatures:特征提取函数,从图像列表中批量读取图像,进行预处理后输入神经网络提取特征。
getNames:获取图像名单函数,从存储图像路径的文件中读取图像名称。
similarity:计算相似度函数,通过点积操作得出两个特征向量的相似度。
getTopK:选取TopK函数,对每一个查询特征,计算与所有图库特征的相似度,并排序选取最相似的K个结果。
addBorder:添加边框函数,给图像添加边框。
drawRankList:绘制排名列表函数,将查询图像和它的TopK相似图库图像绘制在一起进行可视化。
visualization:可视化函数,将所有查询结果进行可视化并保存到指定目录。
最后,main函数是程序的入口点,首先解析命令行参数,然后读取查询和图库图像的文件路径。使用readNet函数读取训练好的网络模型,并设置计算后端和设备。提取查询和图库图像的特征,并计算TopK结果。最后,对结果进行可视化和存储。
简单总结,该代码定义了一个基于OpenCV的人员重识别系统,可以读取图像,提取特征,并通过计算相似度来匹配查询图像与图库中的图像,最后可视化输出匹配结果。使用了OpenCV库中的深度学习模块和图像处理模块,以及标准的归一化和相似度计算方法来实现该功能。
// 以下是用于行人重识别(ReID)的基础模型和示例输入的下载地址:
// https://github.com/ReID-Team/ReID_extra_testdata
// 行人重识别(ReID)基础模型和示例的作者信息:
// Xing Sun <winfredsun@tencent.com>
// Feng Zheng <zhengf@sustech.edu.cn>
// Xinyang Jiang <sevjiang@tencent.com>
// Fufu Yu <fufuyu@tencent.com>
// Enwei Zhang <miyozhang@tencent.com>
// 版权信息
// Copyright (C) 2020-2021, Tencent.
// Copyright (C) 2020-2021, SUSTech.
#include <iostream> // 引入IO流库,用于数据输入输出
#include <fstream> // 引入文件流库,用于文件操作
#include <opencv2/imgproc.hpp> // 引入OpenCV图像处理头文件
#include <opencv2/highgui.hpp> // 引入OpenCV GUI头文件
#include <opencv2/dnn.hpp> // 引入OpenCV深度学习模块头文件
using namespace cv; // 使用cv命名空间
using namespace cv::dnn; // 使用cv::dnn命名空间
// 定义命令行参数解析所需的关键词参数
const char* keys =
"{help h | | show help message}" // 帮助信息
"{model m | youtu_reid_baseline_lite.onnx | network model}" // 网络模型
"{query_list q | ReID_extra_testdata/queryList.txt | list of query images}" // 查询图像列表
"{gallery_list g | ReID_extra_testdata/galleryList.txt | list of gallery images}" // 画廊图像列表
"{batch_size | 32 | batch size of each inference}" // 每次推理的批处理大小
"{resize_h | 256 | resize input to specific height.}" // 输入图像调整到特定的高度
"{resize_w | 128 | resize input to specific width.}" // 输入图像调整到特定的宽度
"{topk k | 5 | number of gallery images showed in visualization}" // 可视化展示中画像的数量
"{output_dir |result | path for visualization(it should be existed)}" // 可视化结果的保存路径(必须已存在)
"{backend b | 5 | choose one of computation backends: "
"0: automatically (by default), " // 计算后端选项:默认自动选择
"1: Halide language (http://halide-lang.org/), " // Halide语言后端
"2: Intel's Deep Learning Inference Engine (https://software.intel.com/openvino-toolkit), " // 英特尔深度学习推理引擎后端
"3: OpenCV implementation, " // OpenCV实现后端
"4: VKCOM, " // VKCOM后端
"5: CUDA }" // CUDA后端
"{target t | 6 | choose one of target computation devices: "
"0: CPU target (by default), " // 计算设备选项:默认使用CPU
"1: OpenCL, " // 使用OpenCL
"2: OpenCL fp16 (half-float precision), " // 使用OpenCL半精度浮点数
"4: Vulkan, " // 使用Vulkan
"6: CUDA, " // 使用CUDA
"7: CUDA fp16 (half-float preprocess) }"; // 使用CUDA半精度预处理
// OpenCV和重识别命名空间内的处理函数
namespace cv{
namespace reid{
// 预处理图像的函数,将图像数据进行归一化处理
static Mat preprocess(const Mat& img)
{
const double mean[3] = {0.485, 0.456, 0.406}; // 定义三个通道的均值
const double std[3] = {0.229, 0.224, 0.225}; // 定义三个通道的标准差
Mat ret = Mat(img.rows, img.cols, CV_32FC3); // 创建一个新的Mat对象来存放处理后的图像
for (int y = 0; y < ret.rows; y ++) // 遍历图像的行
{
for (int x = 0; x < ret.cols; x++) // 遍历图像的列
{
for (int c = 0; c < 3; c++) // 遍历图像的通道
{
// 进行通道值的归一化处理,并将结果存储在新的Mat对象中
ret.at<Vec3f>(y,x)[c] = (float)((img.at<Vec3b>(y,x)[c] / 255.0 - mean[2 - c]) / std[2 - c]);
}
}
}
return ret; // 返回处理后的图像
}
// 特征向量归一化的函数
static std::vector<float> normalization(const std::vector<float>& feature)
{
std::vector<float> ret; // 创建一个用于存储归一化后特征的向量
float sum = 0.0; // 初始化求和变量
for(int i = 0; i < (int)feature.size(); i++) // 遍历特征向量的元素
{
sum += feature[i] * feature[i]; // 计算L2范数的平方累积
}
sum = sqrt(sum); // 计算L2范数
for(int i = 0; i < (int)feature.size(); i++) // 再次遍历特征向量元素,进行归一化
{
ret.push_back(feature[i] / sum); // 将归一化后的值添加到结果向量中
}
return ret; // 返回归一化后的特征向量
}
// 提取特征的函数
static void extractFeatures(const std::vector<std::string>& imglist, Net* net, const int& batch_size, const int& resize_h, const int& resize_w, std::vector<std::vector<float>>& features)
{
for(int st = 0; st < (int)imglist.size(); st += batch_size) // 批量处理图像,每次处理batch_size数量的图像
{
std::vector<Mat> batch; // 存储处理后的图像批次的容器
for(int delta = 0; delta < batch_size && st + delta < (int)imglist.size(); delta++) // 遍历当前批次里的所有图像
{
Mat img = imread(imglist[st + delta]); // 读取一张图像
batch.push_back(preprocess(img)); // 对图像进行预处理,并加入到图像批次中
}
Mat blob = dnn::blobFromImages(batch, 1.0, Size(resize_w, resize_h), Scalar(0.0,0.0,0.0), true, false, CV_32F); // 创建一个4维blob作为网络的输入
net->setInput(blob); // 设置网络的输入数据为blob
Mat out = net->forward(); // 网络前向传播,输出每一张图像的特征
for(int i = 0; i < (int)out.size().height; i++) // 遍历每一张图像
{
std::vector<float> temp_feature; // 存储单张图像的特征
for(int j = 0; j < (int)out.size().width; j++) // 遍历提取的特征向量
{
temp_feature.push_back(out.at<float>(i,j)); // 读取特征并存储
}
features.push_back(normalization(temp_feature)); // 对提取出的特征进行归一化处理,并存储到features中
}
}
return ; // 结束函数,无需返回值
}
static void getNames(const std::string& ImageList, std::vector<std::string>& result)
{
std::ifstream img_in(ImageList); // 打开图像列表文件
std::string img_name; // 存储单个图像的名称
while(img_in >> img_name) // 循环读取图像名称
{
result.push_back(img_name); // 将图像名称添加到结果向量中
}
return ; // 结束函数
}
static float similarity(const std::vector<float>& feature1, const std::vector<float>& feature2)
{
float result = 0.0; // 初始化相似度结果为0.0
for(int i = 0; i < (int)feature1.size(); i++) // 遍历特征向量的每一个维度
{
result += feature1[i] * feature2[i]; // 计算两个特征向量的点积,作为相似度度量
}
return result; // 返回相似度结果
}
// getTopK函数
// 计算查询特征和画廊特征之间的相似性,并获取每个查询特征的前K个最相似画廊特征索引
static void getTopK(const std::vector<std::vector<float>>& queryFeatures, const std::vector<std::vector<float>>& galleryFeatures, const int& topk, std::vector<std::vector<int>>& result)
{
for(int i = 0; i < (int)queryFeatures.size(); i++) // 遍历所有查询特征
{
std::vector<float> similarityList; // 存储查询特征与所有画廊特征相似度的列表
std::vector<int> index; // 存储画廊特征索引的列表
for(int j = 0; j < (int)galleryFeatures.size(); j++) // 遍历所有画廊特征
{
similarityList.push_back(similarity(queryFeatures[i], galleryFeatures[j])); // 计算并存储相似度
index.push_back(j); // 存储当前索引
}
sort(index.begin(), index.end(), [&](int x,int y){return similarityList[x] > similarityList[y];}); // 根据相似度对索引进行降序排序
std::vector<int> topk_result; // 存储前K个索引的列表
for(int j = 0; j < min(topk, (int)index.size()); j++) // 选择前K个最相似的特征索引
{
topk_result.push_back(index[j]); // 存储排序后的索引
}
result.push_back(topk_result); // 将结果存入最终结果列表
}
return ;
}
// addBorder函数:给图像增加一个固定尺寸的边框
static void addBorder(const Mat& img, const Scalar& color, Mat& result)
{
const int bordersize = 5; // 定义边框大小为5
copyMakeBorder(img, result, bordersize, bordersize, bordersize, bordersize, cv::BORDER_CONSTANT, color); // 对图像img进行边框扩展,每边增加bordersize个像素宽度,边框类型为固定颜色,颜色由参数color指定
return ; // 函数无返回值
}
// drawRankList函数:绘制查询结果的排名列表
static void drawRankList(const std::string& queryName, const std::vector<std::string>& galleryImageNames, const std::vector<int>& topk_index, const int& resize_h, const int& resize_w, Mat& result)
{
const Size outputSize = Size(resize_w, resize_h); // 定义输出图像大小
Mat q_img = imread(queryName), temp_img; // 读取查询图像queryName,temp_img为临时变量
resize(q_img, temp_img, outputSize); // 将查询图像调整到定义的大小
addBorder(temp_img, Scalar(0,0,0), q_img); // 给查询图像增加黑色边框
putText(q_img, "Query", Point(10, 30), FONT_HERSHEY_COMPLEX, 1.0, Scalar(0,255,0), 2); // 在查询图像上放置文字"Query"
std::vector<Mat> Images; // 定义Mat类型的向量,用于存放所有图片
Images.push_back(q_img); // 将查询图像加入向量
for(int i = 0; i < (int)topk_index.size(); i++) // 遍历topk_index中的所有索引
{
Mat g_img = imread(galleryImageNames[topk_index[i]]); // 读取画廊图像
resize(g_img, temp_img, outputSize); // 将读取的画廊图像调整到定义的大小
addBorder(temp_img, Scalar(255,255,255), g_img); // 给画廊图像增加白色边框
putText(g_img, "G" + std::to_string(i), Point(10, 30), FONT_HERSHEY_COMPLEX, 1.0, Scalar(0,255,0), 2); // 在画廊图像上放置文字(显示排名)
Images.push_back(g_img); // 将画廊图像加入向量
}
hconcat(Images, result); // 将所有图像水平拼接成一张图
return ; // 函数无返回值
}
// visualization函数:可视化展示查询的排名结果
static void visualization(const std::vector<std::vector<int>>& topk, const std::vector<std::string>& queryImageNames, const std::vector<std::string>& galleryImageNames, const std::string& output_dir, const int& resize_h, const int& resize_w)
{
for(int i = 0; i < (int)queryImageNames.size(); i++) // 遍历所有查询图像名称
{
Mat img; // 定义图像变量,用于存放绘制后的排名列表
drawRankList(queryImageNames[i], galleryImageNames, topk[i], resize_h, resize_w, img); // 调用drawRankList函数绘制单个查询图像的排名列表
std::string output_path = output_dir + "/" + queryImageNames[i].substr(queryImageNames[i].rfind("/")+1); // 定义输出路径,生成每张查询图像的排名图像保存位置
imwrite(output_path, img); // 将绘制的排名列表图像写入文件
}
return ; // 函数无返回值
}
}; // 结束命名空间
// main函数
// 程序入口,解析命令行参数,加载网络模型,提取特征,获取相似性排名,并进行结果可视化
int main(int argc, char** argv)
{
CommandLineParser parser(argc, argv, keys); // 创建命令行参数解析器
if (argc == 0 || parser.has("help")) // 如果没有参数或请求帮助信息
{
parser.printMessage(); // 打印帮助信息
return 0; // 退出程序
}
parser = CommandLineParser(argc, argv, keys); // 重新创建命令行参数解析器(貌似是多余的)
parser.about("Use this script to run ReID networks using OpenCV."); // 关于信息
// 从命令行参数中获取网络模型路径、查询图像列表、画廊图像列表等信息
const std::string modelPath = parser.get<String>("model");
const std::string queryImageList = parser.get<String>("query_list");
const std::string galleryImageList = parser.get<String>("gallery_list");
const int backend = parser.get<int>("backend");
const int target = parser.get<int>("target");
const int batch_size = parser.get<int>("batch_size");
const int resize_h = parser.get<int>("resize_h");
const int resize_w = parser.get<int>("resize_w");
const int topk = parser.get<int>("topk");
const std::string output_dir= parser.get<String>("output_dir");
// 读取图像列表
std::vector<std::string> queryImageNames;
reid::getNames(queryImageList, queryImageNames);
std::vector<std::string> galleryImageNames;
reid::getNames(galleryImageList, galleryImageNames);
// 加载网络模型,并设置计算后端和目标设备
dnn::Net net = dnn::readNet(modelPath);
net.setPreferableBackend(backend);
net.setPreferableTarget(target);
// 提取查询图像特征
std::vector<std::vector<float>> queryFeatures;
reid::extractFeatures(queryImageNames, &net, batch_size, resize_h, resize_w, queryFeatures);
// 提取画廊图像特征
std::vector<std::vector<float>> galleryFeatures;
reid::extractFeatures(galleryImageNames, &net, batch_size, resize_h, resize_w, galleryFeatures);
// 获取查询图像特征和画廊图像特征之间的前K个相似性排名
std::vector<std::vector<int>> topkResult;
reid::getTopK(queryFeatures, galleryFeatures, topk, topkResult);
// 可视化结果
reid::visualization(topkResult, queryImageNames, galleryImageNames, output_dir, resize_h, resize_w);
return 0; // 程序执行完成
}Mat blob = dnn::blobFromImages(batch, 1.0, Size(resize_w, resize_h), Scalar(0.0,0.0,0.0), true, false, CV_32F);
sort(index.begin(), index.end(), [&](int x, int y) {return similarityList[x] > similarityList[y]; });其利用了C++的STL(Standard Template Library,标准模板库)中的sort函数来对索引进行排序。具体来说,这行代码的作用是根据similarityList中元素的值来对索引进行从大到小的排序。

copyMakeBorder(img, result, bordersize, bordersize, bordersize, bordersize, cv::BORDER_CONSTANT, color);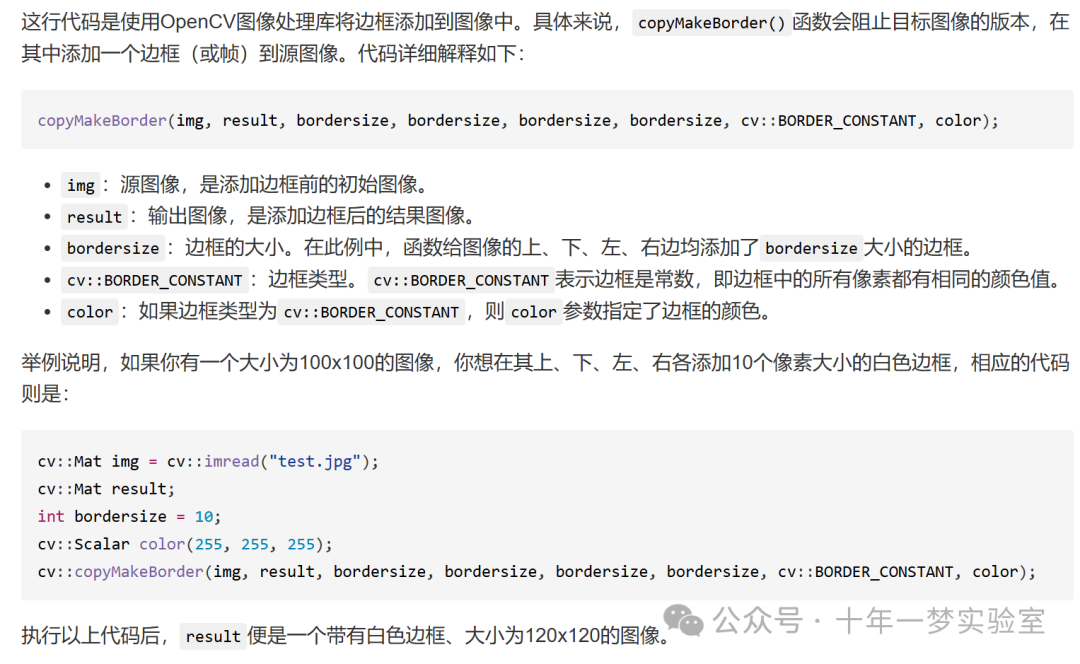
ReID网络的输出:Mat out = net->forward();
记录:Debug报错。Release ok

C:\Users\cxy\AppData\Local\Programs\Python\Python310\python.exe -m onnxsim youtu_reid_baseline_large.onnx youtu_reid_baseline_large_sim.onnx
C:\Users\cxy\AppData\Local\Programs\Python\Python310\python.exe -m onnxsim youtu_reid_baseline_lite.onnx youtu_reid_baseline_lite_sim.onnxThe End
作者陈晓永:智能装备专业高级职称,软件工程师,机械设计中级职称,机器人与自动化产线仿真动画制作