paper:Big Self-Supervised Models are Strong Semi-Supervised Learners
official implementation:https://github.com/google-research/simclr
本文的创新点
本文在SimCLR的基础上做了一些改进,提出了SimCLR v2,进一步提升了无监督预训练模型的性能。此外,基于SimCLR v2,本文提出一种新的半监督学习算法,包括无监督预训练、监督微调、知识蒸馏,并在ImageNet上取得了新的SOTA。
方法介绍
SimCLR v2相比于SimCLR的改进主要包括下面三个方面:
- 更大的模型架构。为了充分利用通用预训练的能力,作者探索了更大的ResNet模型。在SimCLR和之前的其它工作中,最大的模型为ResNet-50(4x),本文训练了更深但不那么宽的模型。本文训练的最大模型为ResNet-152,通道3倍宽,并使用了selective kernels(一种通道注意力机制,具体介绍见SKNet: Selective Kernel Networks_sknet(selective kernel network-CSDN博客)。通过将模型从ResNet-50增大到ResNet-152(3x+SK),当用1%的标签数据进行微调时,top-1精度提升了29%。
- 本文还增加了非线性网络 \(g(\cdot)\)(即projection head)的容量,通过增加它的深度。此外,和SimCLR中预训练完就完全丢弃 \(g(\cdot)\) 的做法不同,本文从 \(g(\cdot)\) 的中间层进行微调。这个小变化对linear evaluation和在少量标签数据上微调都带来了显著的提升。与使用2层映射头的SimCLR相比,使用3层映射头并从第1层开始微调,在1%的标签数据上微调时,top-1精度提升了14%。
- 本文还引入了MoCo(具体介绍见MoCo v1(CVPR 2020)原理与代码解读-CSDN博客)中的memory机制,其中通过动量更新的方式来稳定训练。但因为SimCLR本身就基于大batch size进行训练的,有充足的对比负样本,因此该点带来的提升只有大约1%。
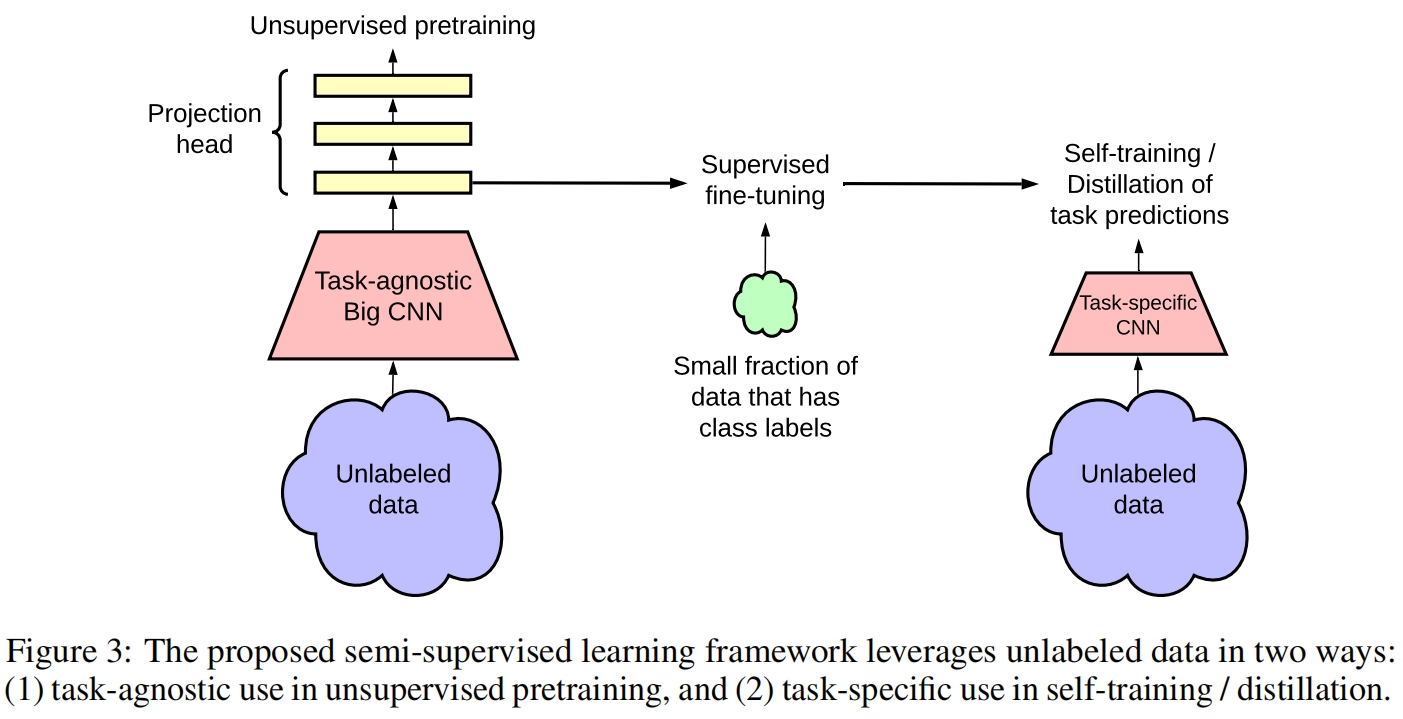
此外,本文还提出一种新的半监督学习算法,如图3所示。它包括三步:(1)在无标签数据上用SimCLR v2得到一个预训练模型。(2)用少量有标签数据进行监督微调。(3)用微调得到模型作为教师模型,在无标签数据上蒸馏出一个小模型。
实验结果
如表1所示,Linear eval表示得到无监督的预训练后,增加一层分类层,freeze预训练权重,只训练这一层分类层最终得到的精度。可以看到,增大模型的深度和宽度并使用SK显著提升了Linear eval的准确率。

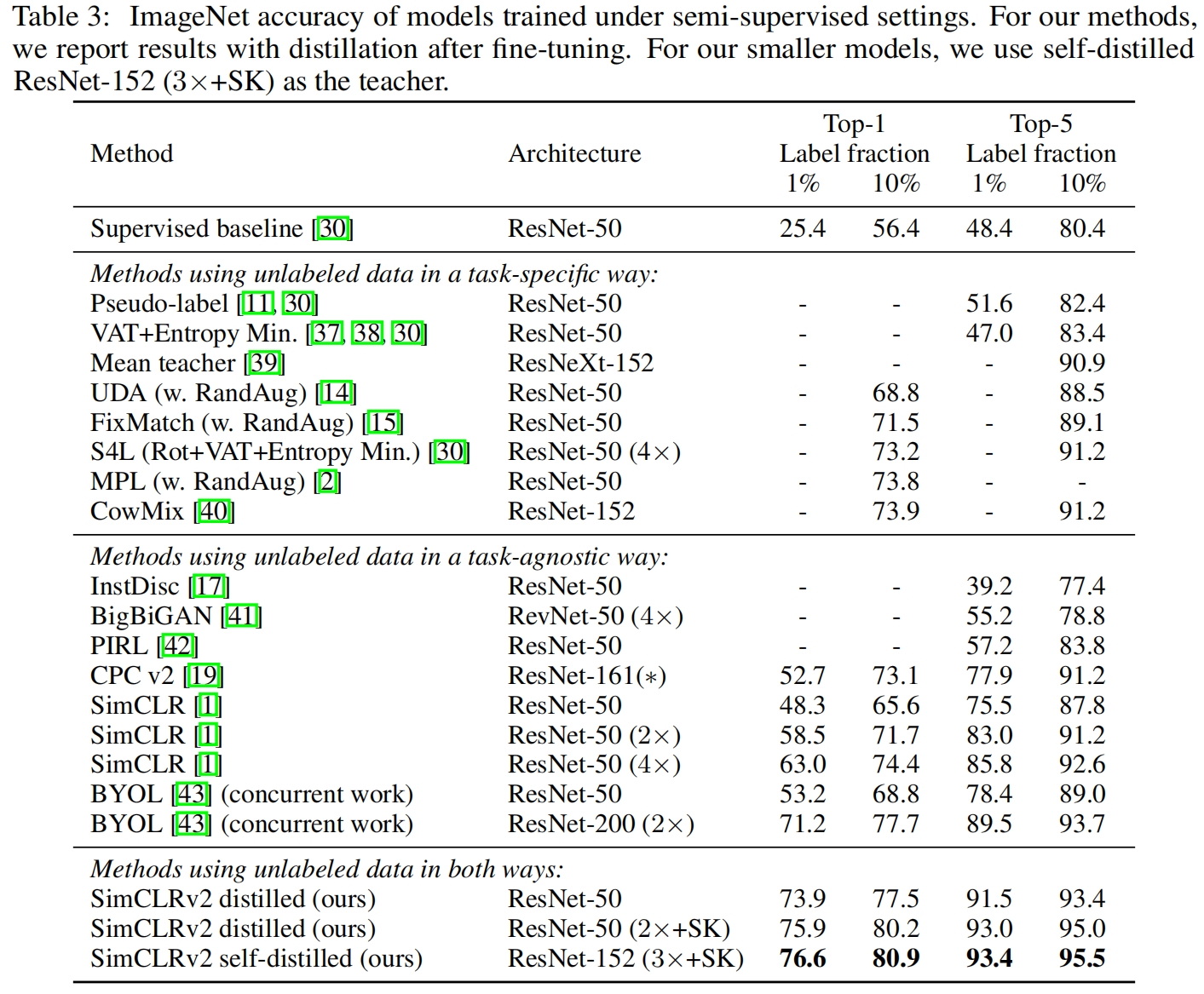
表3是本文提出的基于SimCLR v2的半监督算法与其它半监督方法的对比,可以看到本文提出的基于SimCLR v2的无监督预训练、少量有标签数据微调、无监督数据蒸馏的方法取得了SOTA的结果。