文章目录
- 学习链接
- 准备
- 建表
- 插入数据
- 方法
- MySQL逗号拼接的列拆分为多行(不使用mysql.help_topic)
- 遇到字段以逗号分隔符分号分隔符存放多个值,需要一行转化多行,以用来关联(使用mysql.help_topic)
- 改为LEFT JOIN后的效果
- 封装为函数
- 原理简析
- SUBSTRING_INDEX(str, delim, count)
- replace( str, from_str, to_str)
- LENGTH( str )
- 将逗号分割的字段内容转换为多行并group by
- 1、原来的字段格式
- 2、将逗号分割的字段内容转换为多行
- 3、对以上结果进行分组
学习链接
MYSQL: sql中某一个字段内容为用逗号分割的字符串转换成多条数据(适用于部分树机构)
MySQL逗号拼接的列拆分为多行(不使用mysql.help_topic)
遇到字段以逗号分隔符分号分隔符存放多个值,需要一行转化多行,以用来关联(使用mysql.help_topic)
【mysql】将逗号分割的字段内容转换为多行并group by
Mysql 行转列,把逗号分隔的字段拆分成多行(这个也还可以)
【mysql】将逗号分割的字段内容转换为多行并group by(这个讲的很详细)
MySql字符串拆分实现split功能(字段分割转列、转行)(很nice)
MySql逗号拼接的列拆分为多行(nice)
PostgreSQL 字符串分隔函数(regexp_split_to_table)介绍以及示例应用
准备
建表
CREATE TABLE `u_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
`hobbies` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8;
插入数据
INSERT INTO `test`.`u_user` (`id`, `name`, `hobbies`) VALUES (1, 'zj', 'ps,blender,java');
INSERT INTO `test`.`u_user` (`id`, `name`, `hobbies`) VALUES (2, 'ls', 'u8,u9,pmp,cpa');
INSERT INTO `test`.`u_user` (`id`, `name`, `hobbies`) VALUES (3, 'zzhua', 'spring');
INSERT INTO `test`.`u_user` (`id`, `name`, `hobbies`) VALUES (4, 'zengjian', NULL);
INSERT INTO `test`.`u_user` (`id`, `name`, `hobbies`) VALUES (5, 'halo', '');
INSERT INTO `test`.`u_user` (`id`, `name`, `hobbies`) VALUES (6, 'netty', 'a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z');
-- truncate table u_user;
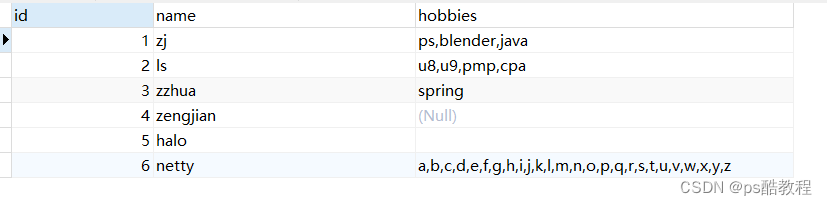
插入数据如下图所示,有多个的使用逗号分隔的,有单个未使用逗号的,有nul的,有空字符的,有特别多个的。
方法
MySQL逗号拼接的列拆分为多行(不使用mysql.help_topic)
SELECT
id,
name,
SUBSTRING_INDEX( SUBSTRING_INDEX( hobbies, ',', n ), ',', - 1 ) AS split
FROM
`u_user`,
( SELECT @rownum := @rownum + 1 AS n FROM ( SELECT @rownum := 0 ) r, `u_user` ) x
WHERE
1 = 1
AND n <= ( LENGTH( hobbies ) - LENGTH( REPLACE ( hobbies, ',', '' ) ) + 1 )
ORDER BY
id
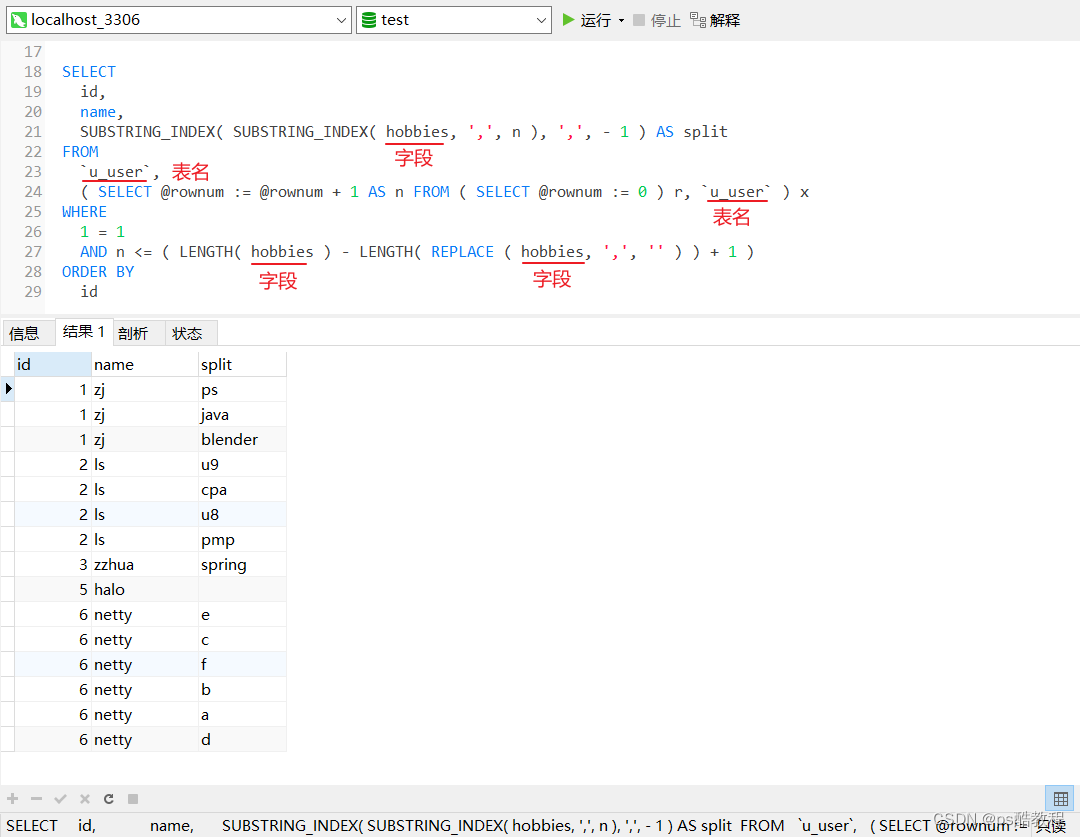
从查询结果来看,这个方法有几个缺点:1、不按顺序来(如果顺序没有特定含义的话,可以忽略),2、会忽略null的数据 3、netty所在的那1条数据,只拆分出了前面6个(这个问题比较严重,这个6经过测试是原表数据的总条数。假设原表中只有2条数据,那么netty所在的那条数据就只会拆分出前2条数据)
遇到字段以逗号分隔符分号分隔符存放多个值,需要一行转化多行,以用来关联(使用mysql.help_topic)
原文链接:https://blog.csdn.net/qq_35124072/article/details/124716478
SELECT
u.id,
u.name,
SUBSTRING_INDEX( SUBSTRING_INDEX( u.`hobbies`, ',', b.help_topic_id + 1 ), ',', -1 ) AS REGEXP_COUNT_COL
FROM
u_user u
INNER JOIN mysql.help_topic b ON b.help_topic_id < (
LENGTH( u.`hobbies` ) - LENGTH( REPLACE(u.`hobbies`,',','') ) + 1 -- hobbies的长度 - hobbies去掉所有逗号的长度 + 1
)
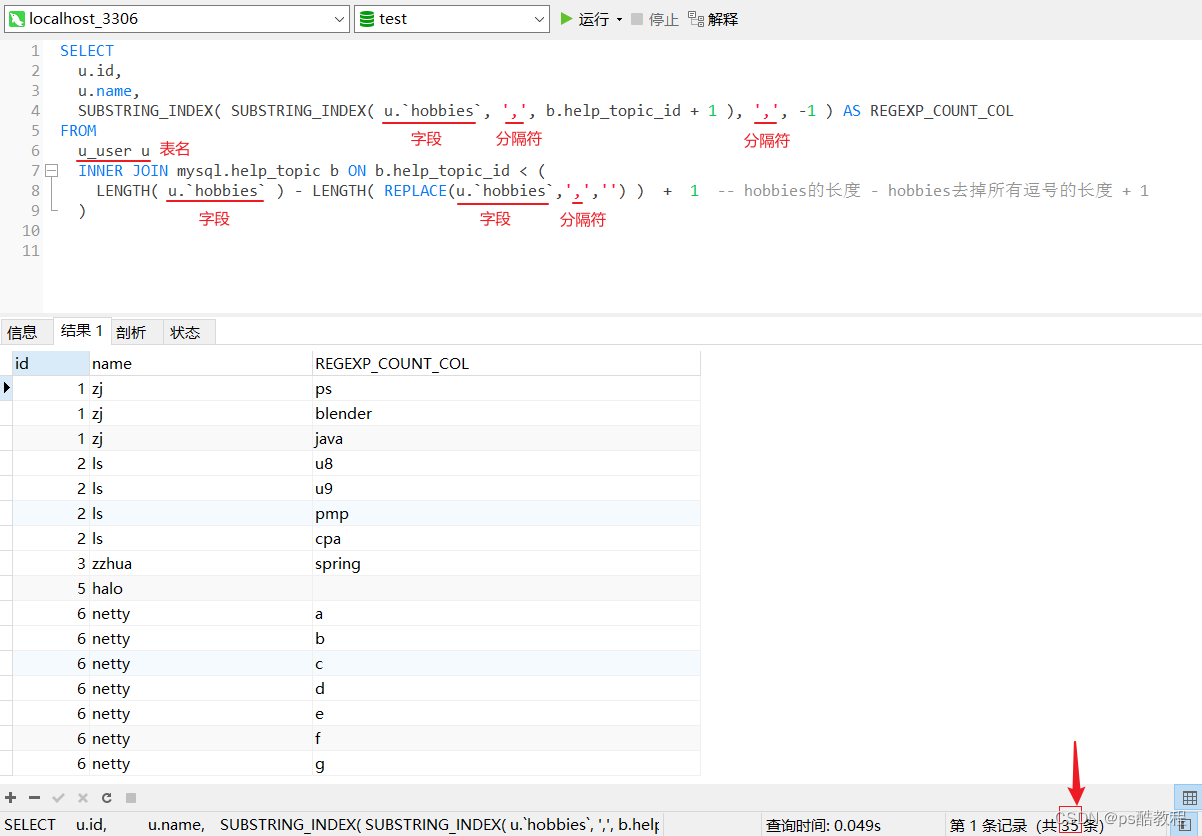
从查询结果来看,1、保留了原来的顺序,2、忽略了null的数据(可以将INNER JOIN改成LEFT JOIN即可),3、netty那一条比较多的数据保留了下来,4、感觉就是上一种方法的变体,就是借助了mysql.topic表的从0开始递增的id字段,这个表中在当前5.17.7版本中有637条数据。5、其实可以不用借助mysql.topic这张表,但是我们就需要自建这样的一张表了,或者我们手动select 1 union select 2 union…这样拼着来使用
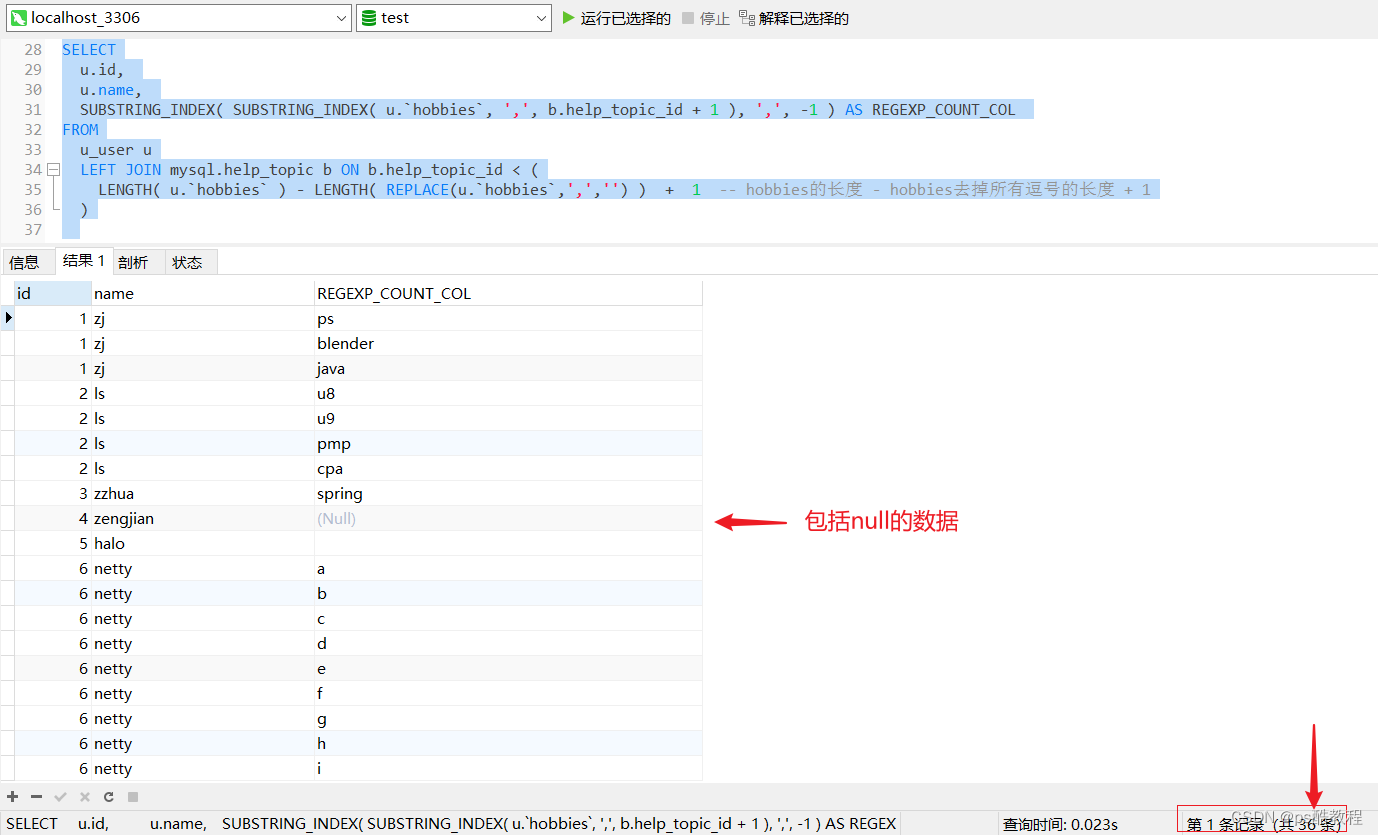
改为LEFT JOIN后的效果
封装为函数
可以参照上面将待分隔的数据作为参数传入,并可封装为函数使用,如下:
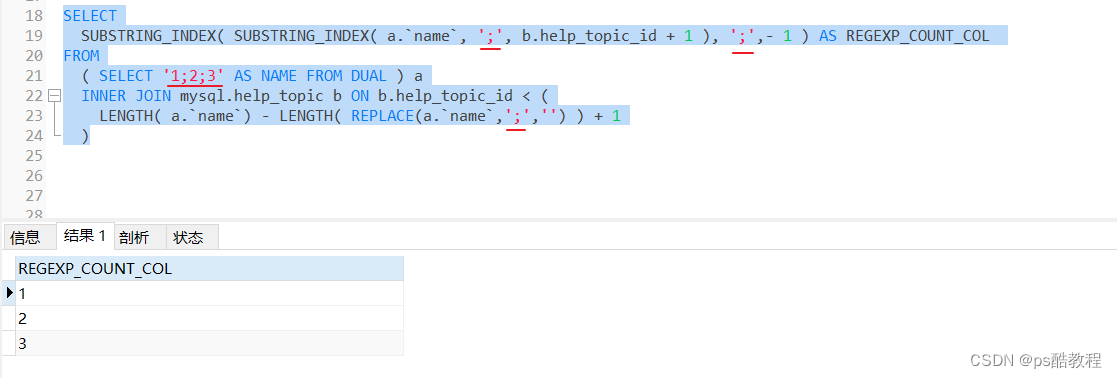
原理简析
1、mysql.help_topic表的help_topic_id 字段是从0开始的自增的int类型的值,所以当部分用户访问该表被拒绝的时候,可以自己建一张临时辅助表,id的值建议至少从0到100,保存100列(取决于参数中可能出现多少个分隔符);
2、如果是别的分隔符,把sql中的’;'替换成其他就好
3、sql原理:大概就是利用参数中分隔符出现的次数来重复连接,以多次返回值,每次返回值都利用SUBSTRING_INDEX截取不同位置的值,达到拆分到多行的目的。
SUBSTRING_INDEX(str, delim, count)
str需要拆分的字符串delim分隔符,通过某字符进行拆分count当 count 为正数,取第 n 个分隔符之前的所有字符; 当 count 为负数,取倒数第 n 个分隔符之后的所有字符
-- 得到的结果: 7654,7698
SUBSTRING_INDEX('7654,7698,7782,7788',',',2)
-- 得到的结果: 7782,7788
SUBSTRING_INDEX('7654,7698,7782,7788',',',-2)
replace( str, from_str, to_str)
str需要进行替换的字符串from_str需要被替换的字符串to_str需要替换的字符串
-- 得到的结果: 7654769877827788
REPLACE('7654,7698,7782,7788',',','')
LENGTH( str )
str需要计算长度的字符串
-- 得到的结果: 19
LENGTH('7654,7698,7782,7788')
将逗号分割的字段内容转换为多行并group by
1、原来的字段格式

2、将逗号分割的字段内容转换为多行
下面直接给出sql,并对sql的每一步做出解释,更有助于大家理解
首先要说明的是,mysql.help_topic本身是mysql的一张信息表,用来存储各种注释等帮助信息,help_topic拥有一个自增为1的id属性–help_topic_id ,并且可以当做下标来使用,拥有固定数量的数据
解释:
- length(a.attendee_uid) - length(REPLACE(a.attendee_uid, ‘,’, ‘’)) + 1
- 第一步的意思是 字段attendee_uid的长度 - 字段attendee_uid去除掉逗号的长度,然后再+1就得到了通过逗号分割后有几条数据
- 比如上一步得到是3 那就可以确定这个字段要拆分为3行 help_topic_id<3 也就是可以得到下标 0,1,2
- 比如这条数据’zhangsan,lisi,wangwu’ 第一个substring_index的意思就是把’zhangsan,lisi,wangwu’通过逗号分割,然后取b.help_topic_id + 1(help_topic_id就是第3步得到的下标)结果就是zhangsan
- 第二个substring_index的意思是 再从第4步的结果 从右边取第一个, 因为’zhangsan,lisi,wangwu’如果获取到下标为2的话那得到的就是’zhangsan,lisi’ 所以再从右边取第一个就得到了 ‘lisi’
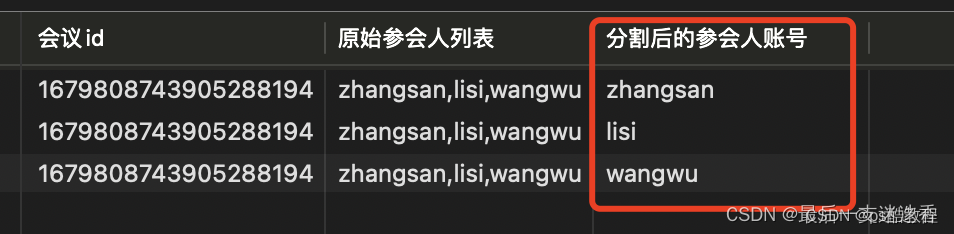
SELECT
a.id '会议id',
a.attendee_uid '原始参会人列表',
# 4、比如这条数据'zhangsan,lisi,wangwu' 第一个substring_index的意思就是把'zhangsan,lisi,wangwu'通过逗号分割,
# 然后取b.help_topic_id + 1(help_topic_id就是第3步得到的下标)结果就是zhangsan
# 5 第二个substring_index的意思是 再从第4步的结果 从右边取第一个, 因为'zhangsan,lisi,wangwu'如果获取到下标为2的话那得到的就是'zhangsan,lisi' 所以再从右边取第一个就得到了 'lisi'
substring_index(substring_index(a.attendee_uid, ',', b.help_topic_id + 1), ',', -1) AS '分割后的参会人账号'
FROM `fusion_meeting` a
JOIN mysql.help_topic b
# 1、length(a.attendee_uid) - length(REPLACE(a.attendee_uid, ',', '')) + 1
# 2、这个的意思是 字段attendee_uid的长度 - 字段attendee_uid去除掉逗号的长度,然后再+1就得到了通过逗号分割后有几条数据
# 3、比如上一步得到是3 那就可以确定这个字段要拆分为3行 help_topic_id<3 也就是可以得到下标 0,1,2
ON b.help_topic_id < length(a.attendee_uid) - length(REPLACE(a.attendee_uid, ',', '')) + 1
WHERE a.hw_conf_id = '969471016';
结果:
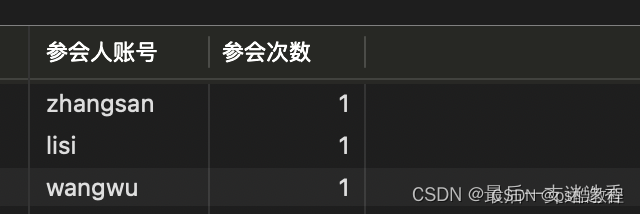
3、对以上结果进行分组
SELECT uid as '参会人账号',COUNT(*) '参会次数' FROM (
SELECT
a.id '会议id',
a.attendee_uid '原始参会人列表',
substring_index(substring_index(a.attendee_uid, ',', b.help_topic_id + 1), ',', -1) AS uid
FROM `fusion_meeting` a
JOIN mysql.help_topic b
ON b.help_topic_id < length(a.attendee_uid) - length(REPLACE(a.attendee_uid, ',', '')) + 1
WHERE a.hw_conf_id = '969471016'
) c GROUP BY c.uid;
结果: