官方https://openai.com/research/video-generation-models-as-world-simulators
概述:
- sora可以生成变长的、不同分辨率的最长可到1分钟的视频;
- 整体流程是 v i d e o c o m p r e s s i o n n e r w o r k ( v i d e o → l a t e n t ) + p a t c h i f y ( s p a c e t i m e p a t c h e s ) + d i f f u s i o n t r a n s f o r m e r + d e c o d e r ( l a t e n t → v i d e o ) video\ compression\ nerwork(video\rightarrow latent) + patchify (spacetime\ patches)+ diffusion\ transformer + decoder(latent\rightarrow video) video compression nerwork(video→latent)+patchify(spacetime patches)+diffusion transformer+decoder(latent→video);
- spacetime patches是作为transformer的tokens;
- sora是一个diffusion transformer21-26,输入带有噪声的patches,以文本作为条件,通过预测原本的干净样本来完成训练;
- text caption的获取,类似与DALL.E3,训练了一个highly descriptive captioner model,除此之外,还使用GPT来将短的caption变长;
- 除了文本作为输入,还可以输入图片和视频完成
- https://www.yuque.com/xinntao/nm1yxs/yyqt6n02n2gkmg32
related papers:
Scalable Diffusion Models with Transformers
https://github.com/facebookresearch/DiT
WALT这篇文章里面关于transformer diffusion类似,只是那一篇文章加入了windowed这一个操作来efficient
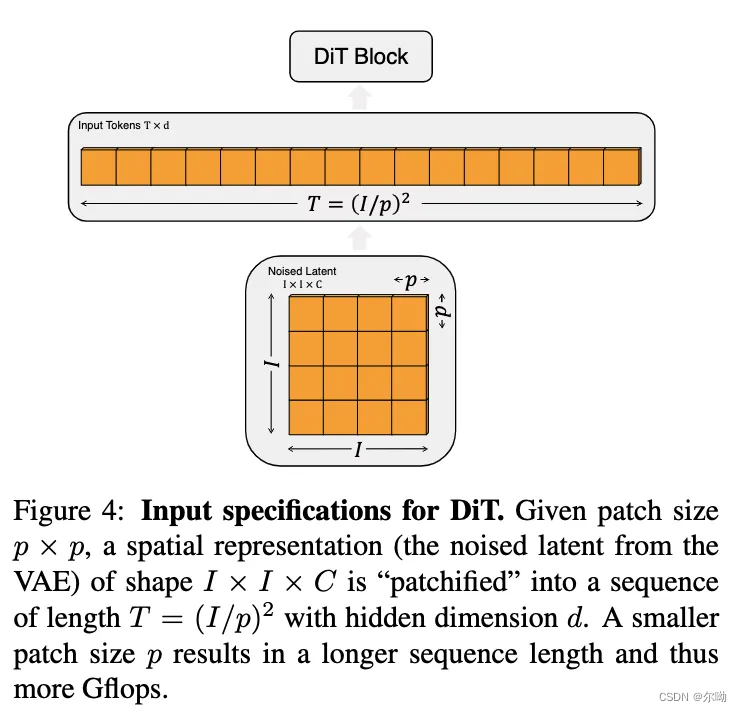
- raw picture首先输入到VAE里面,得到输出,例如 256 × 256 × 3 → 32 × 32 × 4 256\times 256 \times 3 \rightarrow 32 \times 32 \times 4 256×256×3→32×32×4
- 之后是patchify的操作,,input中
I
×
I
I\times I
I×I作为一个token,得到的输出是
T
×
d
T\times d
T×d的,其中
T
=
(
I
/
p
)
2
T=(I/p)^2
T=(I/p)2,
p
p
p是patch size;
- 之后是frequent based positional embedding和VIT是相同的;
- 输入还会有类别、timestep和文本,所以在vit的基础上有一定的改动,
a. In-context conditioning:直接将timestep和class label的embedding与image token进行拼接,这样就可以不改变原始的vit结构,将其与cls相同对待;
b. Cross-attention block:将timestep和class label进行拼接,在模型层面在self attention的后面加上cross attention;
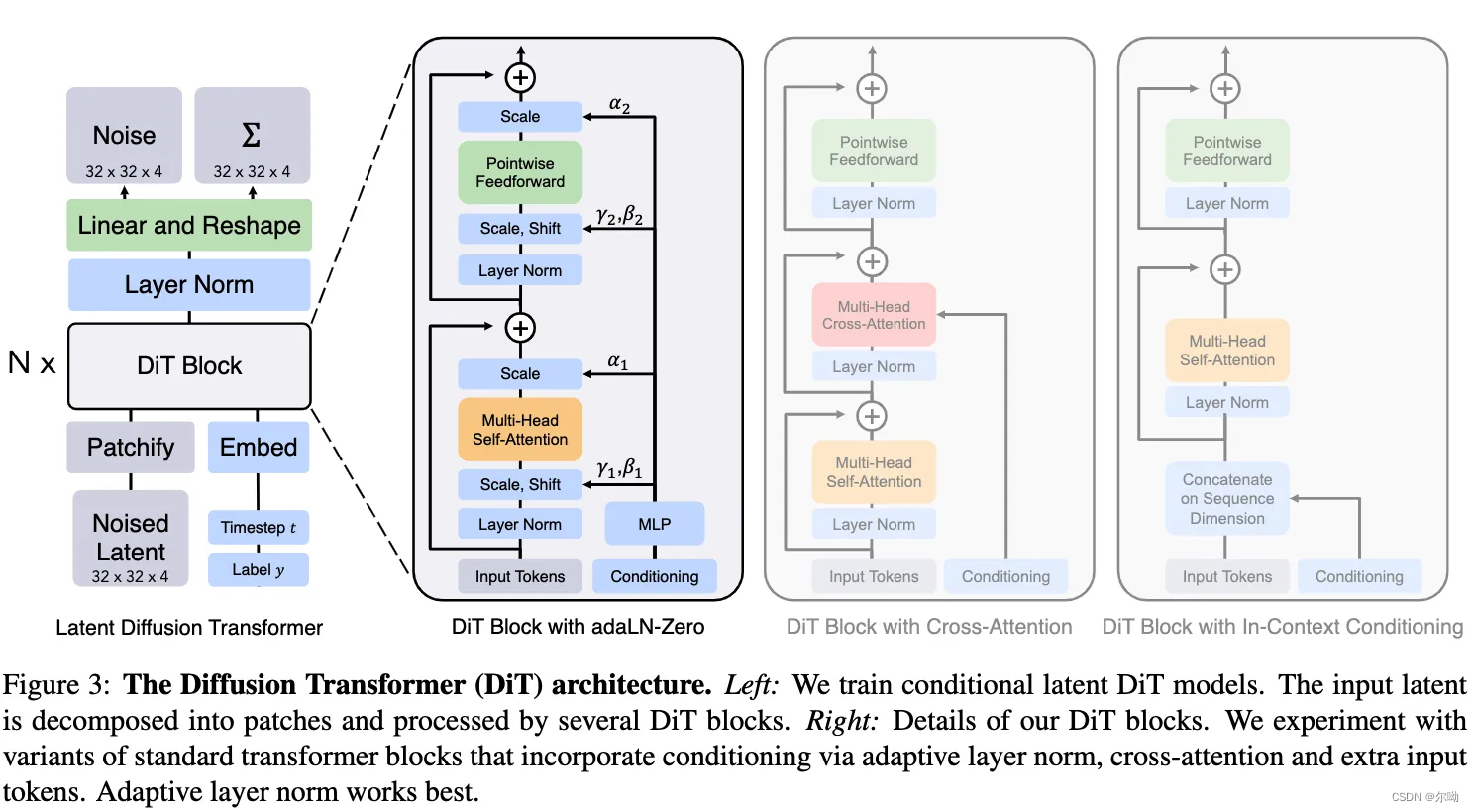
c. Adaptive layer norm (adaLN) block:替换原本的layer norm,Rather than directly learn dimensionwise scale and shift parameters σ , γ \sigma , \gamma σ,γ, we regress them from the sum of the embedding vectors of t and c;
d. adaLN-Zero block:In addition to regressing and , we also regress dimensionwise scaling parameters that are applied immediately prior to any residual connections within the DiT block.We initialize the MLP to output the zero-vector for all; this initializes the full DiT block as the identity function. - decoder:模型结构是线性的将输出的通道变为 p × p × 2 C p\times p \times 2C p×p×2C, C C C是原始vae的输出通道数4,输出的内容物分别是output noise prediction and an output diagonal covariance prediction.Finally, we rearrange the decoded tokens into their original spatial layout to get the predicted noise and covariance.
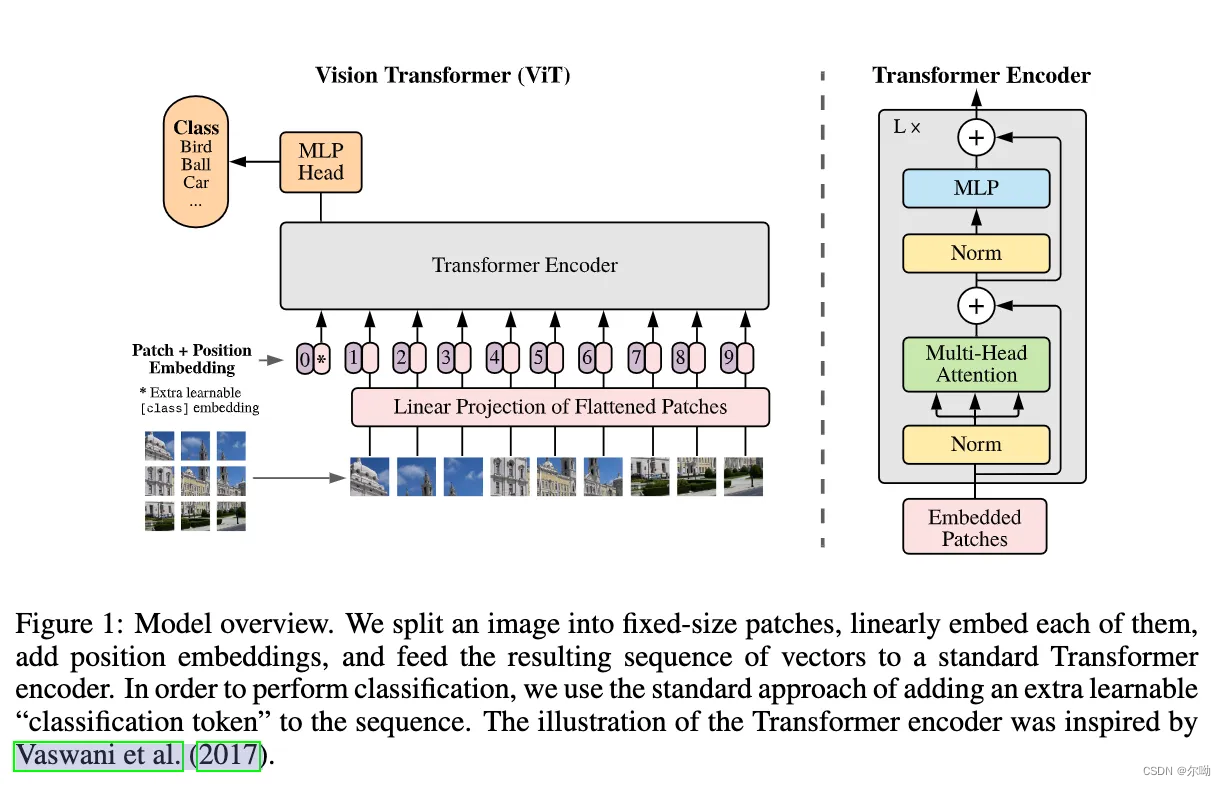
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE(VIT)
ViViT: A Video Vision Transformer
主要是transformer使用到video里面的范式,有几种video token的方法以及加入temporal attention的方法;
一个不错的解读:https://zhuanlan.zhihu.com/p/451386368
Masked Autoencoders Are Scalable Vision Learners
https://blog.csdn.net/iwill323/article/details/128393710
Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
实现可变分辨率和可变长度的vision transformer
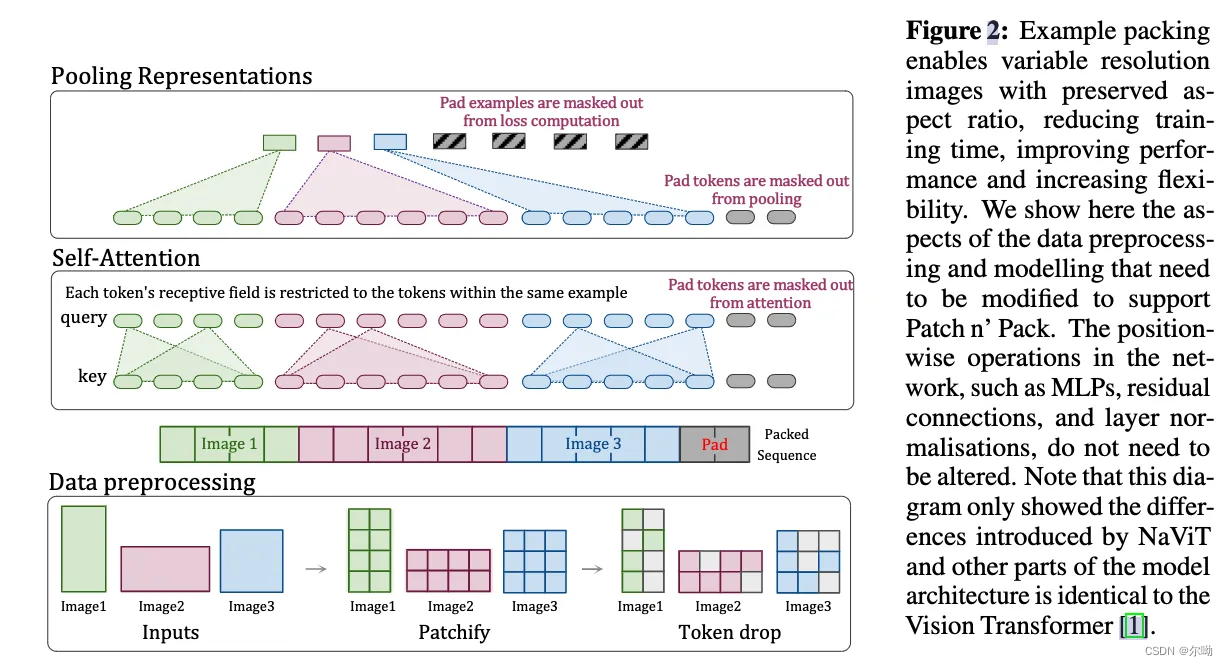
将不同图片的token sequence进行拼接,在原始vit的基础上加上基于图片粒度的mask在self attention和polling上,position embedding也需要相应的改变,不同分辨率的图片拼接到一起训练,但是同时在attention的时候增加mask以限制同一个图片之内进行attention操作;
VideoPoet: A Large Language Model for Zero-Shot Video Generation
模型可以生成包含音频的视频,decoder only的transformer architecture,输入可以包含各种模态,图片、视频、文本和音频,和LLM一样,训练包含两个阶段,预训练阶段以及task specific adaptation
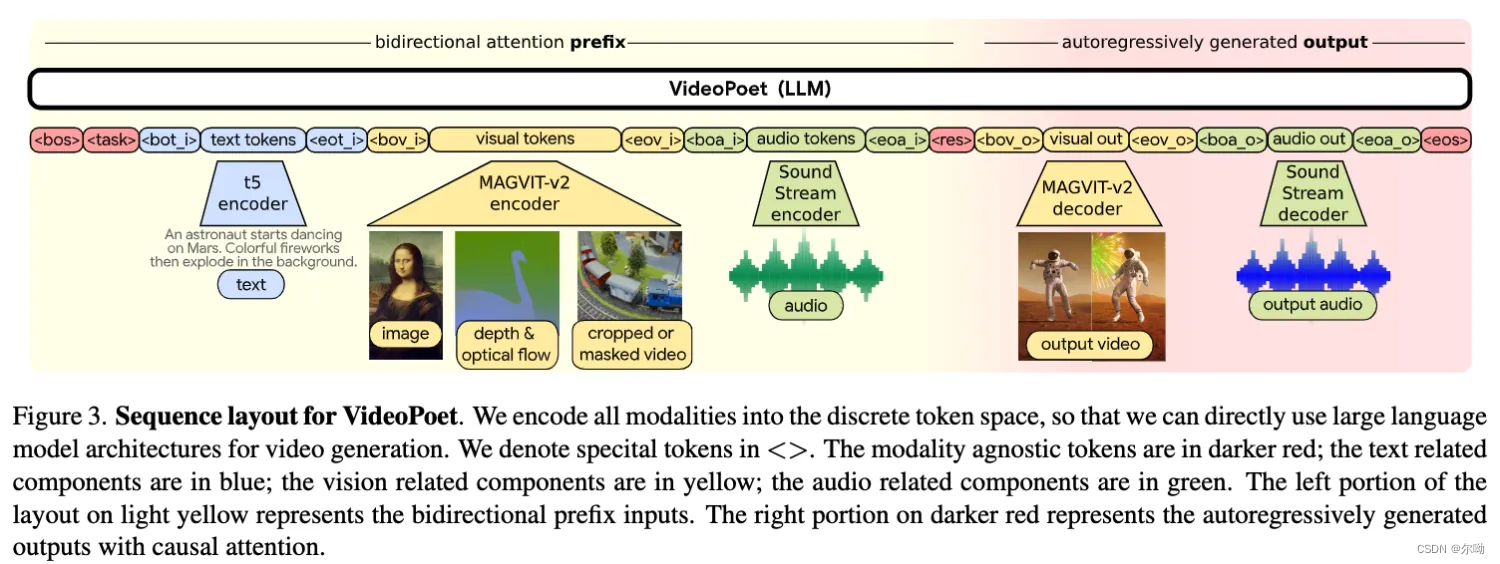
模型包含三个部分:modality specific tokenizer, language model backbone, super resolution module
- tokenizer将各种模态的数据转变为discrete tokens in a unified vocabulary
a. image和video使用的是magvit-v2 tokenizer,audio使用的是soundstream tokenizer
b. unified vocabulary的前256留给special token和task prompts,后面的212644是用来image和video,其余的4096是分配给audio,text使用的是text embedding,现成的T5-XL
c. 以一个17帧 128 ∗ 128 128*128 128∗128分辨率的视频为例,tokenizer将其tokenize到 5 ∗ 16 ∗ 16 5*16*16 5∗16∗16,之后flatten为1280tokens
d. magvit-v2是casual的,the frame are encoded without any information from future frames;
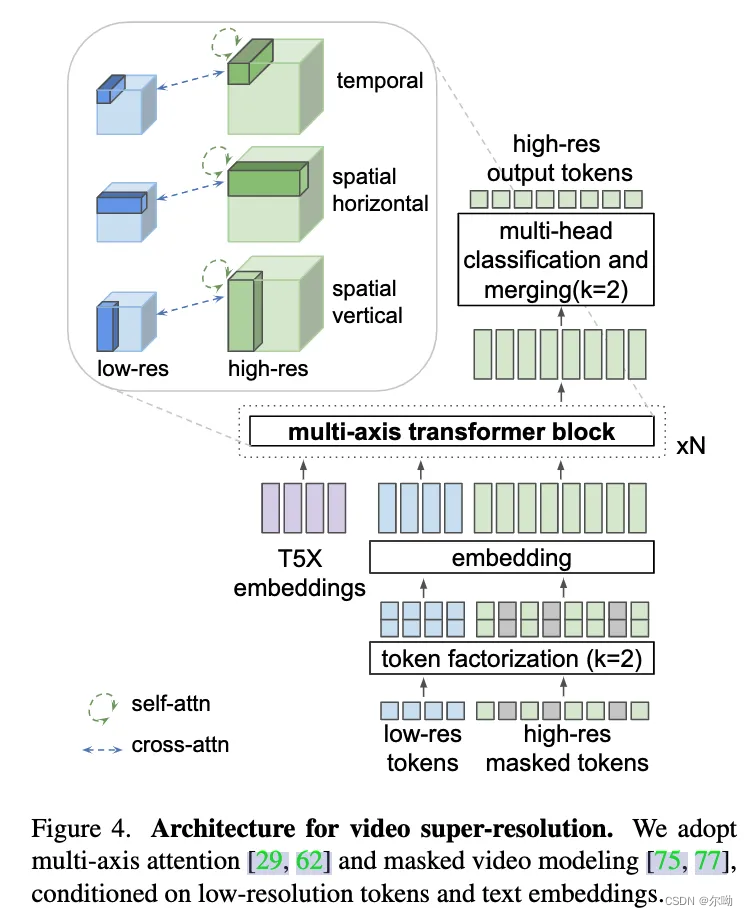
e. 为了联合的表示image和video,将视频的第一帧 1 ∗ 16 ∗ 16 1*16*16 1∗16∗16,之后每4帧为 1 ∗ 16 ∗ 16 1*16*16 1∗16∗16 - super resolution









![[生活][杂项] 如何正确打开编织袋](https://img-blog.csdnimg.cn/direct/b8ad0f399082468ca95c63e7e3379886.jpeg)