1.使用缓存改善网站性能
网站访问的特点和现实世界的财富分配一样遵循二八定律:80%的业务访问集中在20%的数据上。既然大部分业务访问集中在一小部分数据上,那么如果把这一小部分数据缓存在内存中,就可以减少数据库的访问压力,提高整个网站的数据访问速度,改善数据库的写入性能了。网站使用的缓存可以分为两种:缓存在应用服务器上的本地缓存和缓存在专门的分布式缓存服务器上的远程缓存。
本地缓存的访问速度更快一些,但是受应用服务器内存限制,其缓存数据量有限,而且会出现和应用程序争用内存的情况。
远程分布式缓存可以使用集群的方式,部署大内存的服务器作为专门的缓存服务器,可以在理论上做到不受内存容量限制的缓存服务。
1.1本地缓存
本地缓存的概念:本地缓存是指和应用程序在同一个进程内的内存空间去存储数据,数据的读写都是在同一个进程内完成的。
本地缓存优点:读取速度快,但是不能进行大数据量存储。
本地缓存不需要远程网络请求去操作内存空间,没有额外的性能消耗,所以读取速度快。但是由于本地缓存占用了应用进程的内存空间,比如java进程的jvm内存空间,故不能进行大数据量存储。
本地缓存缺点:
(1)应用程序集群部署时,会存在数据更新问题(数据更新不一致)。本地缓存一般只能被同一个应用进程的程序访问,不能被其他应用程序进程访问。在单体应用集群部署时,如果数据库有数据需要更新,就要同步更新不同服务器节点上的本地缓存的数据来保证数据的一致性,但是这种操作的复杂度高,容易出错。可以基于redis的发布/订阅机制来实现各个部署节点的数据同步更新。
(2)数据会随着应用程序的重启而丢失。因为本地缓存的数据是存储在应用进程的内存空间的,所以当应用进程重启时,本地缓存的数据会丢失。
本地缓存的实现:
(1)缓存存储的数据一般都是key-value键值对的数据结构,在java语言中,常用的字典实现包括 HashMap 和 ConcurretHashMap。
(2)除了上面说的实现方式以外,也可以用Guava、Ehcache以及Caffeine等封装好的工具包来实现本地缓存。
1.2分布式缓存
分布式缓存概念:分布式缓存是独立部署的服务进程,并且和应用程序没有部署在同一台服务器上。所以是需要通过远程网络请求来完成分布式缓存的读写操作,并且分布式缓存主要应用在应用程序集群部署的环境下。
分布式缓存优点:
(1)支持大数据量存储
分布式缓存是独立部署的进程,拥有自身独自的内存空间,不需要占用应用程序进程的内存空间,并且还支持横向扩展的集群方式部署,所以可以进行大数据量存储。
(2)数据不会随着应用程序重启而丢失
分布式缓存和本地缓存不同,拥有自身独立的内存空间,不会受到应用程序进程重启的影响,在应用程序重启时,分布式缓存的存储数据仍然存在。
(3)数据集中存储,保证数据的一致性
当应用程序采用集群方式部署时,集群的每个部署节点都有一个统一的分布式缓存进行数据的读写操作,所以不会存在像本地缓存中数据更新问题,保证了不同服务器节点的 数据一致性。
(4)数据读写分离,高性能,高可用
分布式缓存一般支持数据副本机制,实现读写分离,可以解决高并发场景中的数据读写性能问题。而且在多个缓存节点冗余存储数据,提高了缓存数据的可用性,避免某个缓存节点宕机导致数据不可用问题。
分布式缓存缺点:
(1)数据跨网络传输,读写性能不如本地缓存
分布式缓存是一个独立的服务进程,并且和应用程序进程不在同一台机器上,所以数据的读写要通过远程网络请求,这样相对于本地缓存的数据读写,性能要低一些。
分布式缓存的实现:
分布式缓存的典型实现包括 MemCached 和 Redis。
2.第三阶段网站架构图
此时,网站系统的架构如图1所示。使用缓存后,数据访问压力得到有效缓解,但是单一应用服务器能够处理的请求连接有限,在网站访问高峰期,应用服务器成为整个网站的瓶颈。
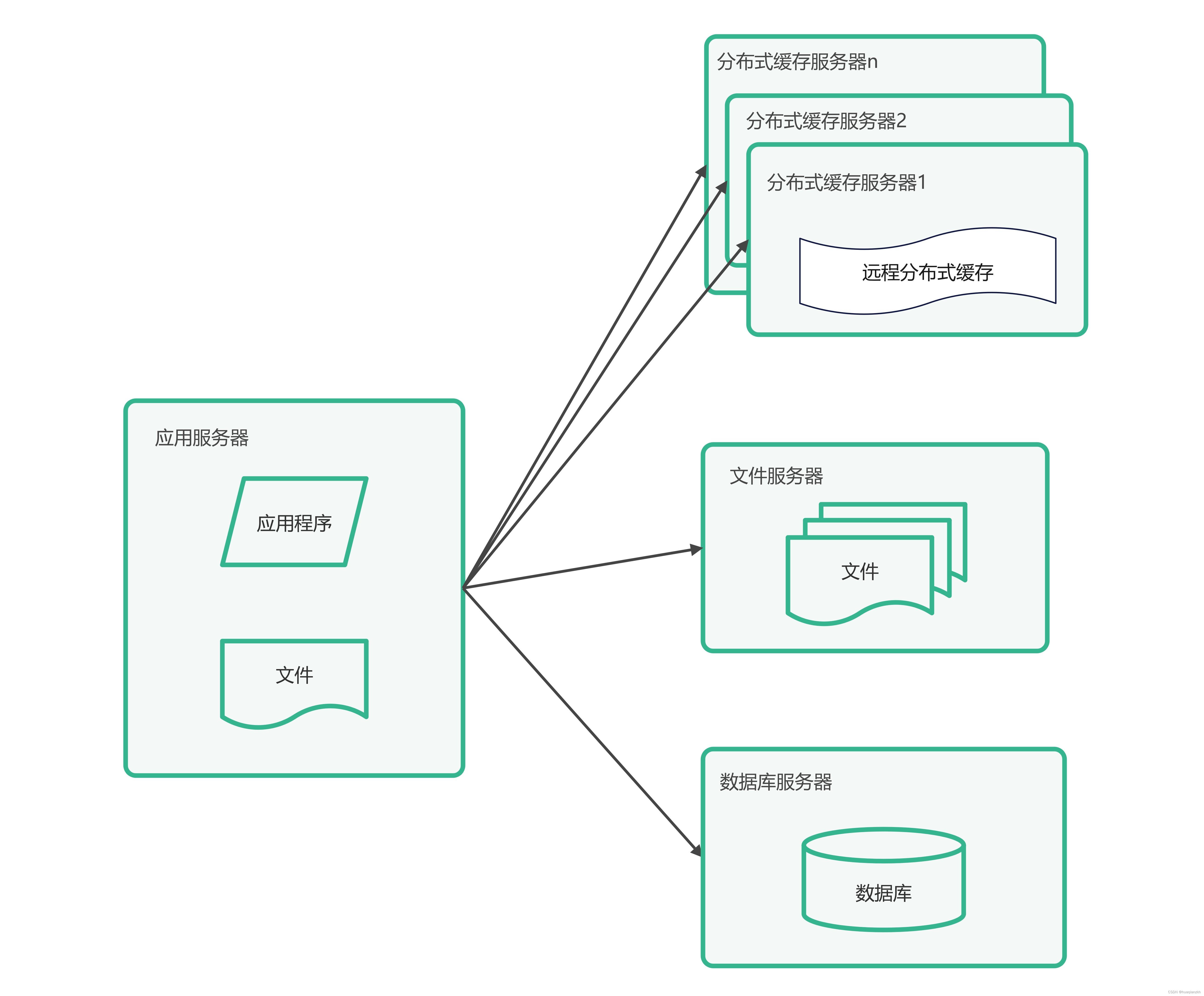
图1 第三阶段网站架构