RAG 介绍
RAG 全称为 Retrieval Augmented Generation(检索增强生成)。是基于LLM构建系统的一种架构。
RAG 基本上可以理解为:搜索 + LLM prompting。根据用户的查询语句,系统会先使用搜索算法获取到相关内容作为上下文,然后将用户查询语句和获取到的上下文一起注入到 prompt 中,然后将 prompt 提供给 LLM 来生成回答内容。
RAG初步实现
RAG 初步实现可以简单分解为以下步骤:
- 将待检索文本分割成块
- 使用 Transformer Encoder 模型将文本嵌入为向量(embedding),并将向量存储
- 构建一个 prompt,可以让模型根据搜索到的内容对用户提出的问题进行回答
使用时:
- 使用相同的 Transformer Encoder 模型,将用户的查询文本转换成向量
- 使用查询的向量从向量存储中找到 top-k 的结果
- 将用户提的问题和查询到的文本块一起作为上下文整合到 prompt 中
def question_answering(context, query):
prompt = f"""
Give the answer to the user query delimited by triple backticks ```{query}```\
using the information given in context delimited by triple backticks ```{context}```.\
If there is no relevant information in the provided context, try to answer yourself,
but tell user that you did not have any relevant context to base your answer on.
Be concise and output the answer of size less than 80 tokens.
"""
response = get_completion(instruction, prompt, model="gpt-3.5-turbo")
answer = response.choices[0].message["content"]
return answer
高级RAG
高级 RAG 架构如下图所示:
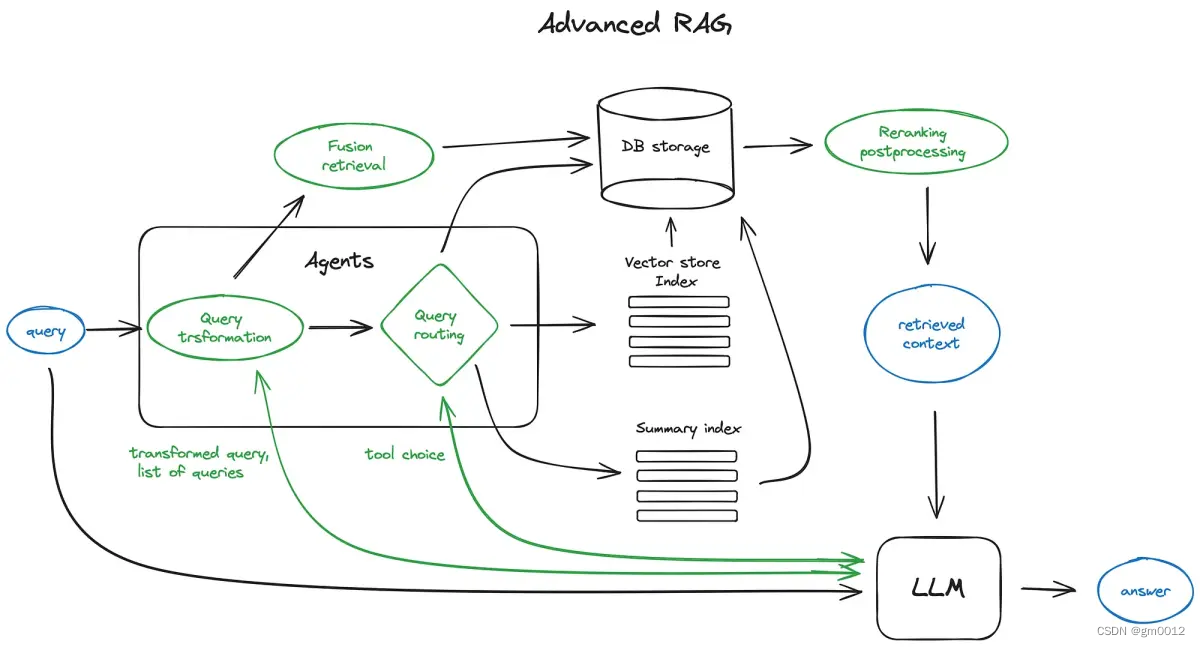
图中,绿色元素为 RAG 核心技术点,蓝色元素为文本。(本架构图对一些细节进行省略,不宜按照本图进行实施)
RAG 核心技术点
1. 分块和矢量化
2. 搜索索引构建
3. 重排序和过滤
4. 查询转换
5. 聊天引擎
6. 查询路由
7. RAG 中的 Agent
8. 响应合成