由于现在做的项目中需要针对数据库进行国产化操作,最终完成从mysql到达梦的迁移,记录整合迁移记录如下:
安装初始化达梦数据库(傻瓜式安装即可)
安装达梦数据库(windows、linux)
初始化数据库实例关键信息
工具:DM数据库配置助手
步骤如下:



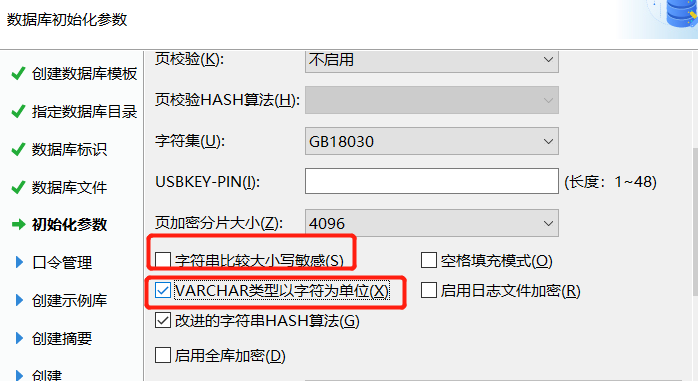
初始化数据库实例后,切换到DM管理工具进行连接
执行数据库兼容性sql
>> 查看COMPATIBLE_MODE参数:
select para_name,para_value,para_type from v$dm_ini where para_name=‘COMPATIBLE_MODE’;
>> 经过查询参数意义如下:
0:不兼容,1:兼容SQL92标准,2:兼容ORACLE,3:兼容MS SQL SERVER,4:兼容MYSQL
>> 我们兼容mysql,所以执行
sp_set_para_value(2,‘COMPATIBLE_MODE’,4);>> 执行完成记得提交事务!!这个是区别于mysql得必备步骤。

字符串比较大小写敏感取消原因说明
>> 如果不取消,那么每个查询都得加上数据库名(模式名).表名进行查询,并且表名还得加上双引号,where筛选条件后得列名和值也都得加上双引号,语法很是严格
>> 取消了大小写敏感后,那么我们springboot中得某些jar包内得sql语法兼容性就更强了,至少可以保证顺利启动
>> 写法更类似mysql,如: 可以直接写成select * from sys_user进行查询操作
数据库迁移
具体数据库迁移教程CSDN一大堆,各有所长,综合来看吧。
我们这里主要是mysql迁移达梦实现
主要是以下几点急需注意:
1.mysql中json格式转达梦数据类型。
这个json类型在mysql中是存在得,但是在达梦中是不存在得,直接转是不能转成功得。
解决方式网上几乎找不到解决方式,而且都是挂羊头卖狗肉,其实就是将mysql中得json数据类型转成longText类型,然后再重新进行迁移,就可以完美迁移成功了,如果最好在在列进行约束下,设置列约束IS JSON,这样在进行存储得时候就可以按需存储。
2. mysql中和达梦varchar类型字符和字节数不一致,mysql中varchar(20),在达梦中差不多需要varchar(40)才能够存储。
所以网上针对这块设置说的很少,最后是经过多次测试和重建数据库实例发现一切皆源于配置,前面得图片中varchar类型以字符存储勾上后就可以完美解决问题
3. goupby 和 orderby不能作用于text、blob、clob等大字段中。
描述: 在DM8上对大字段类型列进行排序、分组等操作时,会报错-2685:试图在blob或者clob列上排序或比较
处理方式:修改数据库参数ENABLE_BLOB_CMP_FLAG
-- 第三个参数是0或者1 0是不能操作大字段;类型 1是可以操作大数据类型
sp_set_para_value(1,'ENABLE_BLOB_CMP_FLAG',1);
-- 查询是狗更改成功
select para_name,para_value,para_type from v$dm_ini where para_name='ENABLE_BLOB_CMP_FLAG';执行完成后提交事务。
其他处理方式 https://blog.csdn.net/Mrkill123/article/details/127478828
4. 其他问题都可以在网上找答案对症下药,我只记录网上很少或者很难找到得解决方式。
springboot兼容达梦数据库
达梦数据源配置(JDBC)
补充说明: DM8在集成到springboot后需要针对语言包进行配置引进
<!--达梦数据库驱动包 -->
<dependency>
<groupId>com.dameng</groupId>
<artifactId>DmJdbcDriver18</artifactId>
<scope>system</scope>
<version>8.1.1.193</version>
<systemPath>${project.basedir}/../lib/DmJdbcDriver18.jar</systemPath>
</dependency>
<!--达梦数据库hibernate语言包 -->
<dependency>
<groupId>org.hibernate.dialect</groupId>
<artifactId>DmDialect</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>${project.basedir}/../lib/DmDialect-for-hibernate5.3.jar</systemPath>
</dependency># 达梦 连接地址
url:jdbc:dm://IP:5236/SYSDBAzeroDateTimeBehavior=convertToNull&useUnicode=true&characterEncoding=utf-8&clobAsString=true
username: SYSDBA
password: SYSDBA
jpa:
show-sql: true
properties:
hibernate:
dialect: org.hibernate.dialect.DmDialectspringboot整合activity5.22.0
原则上acitivity是不兼容DM数据库得,我们得修改acitivity得源码,然后让他兼容。
参考文档:Activiti5.22.0扩展支持达梦数据库.
pdf官方文档:
链接:https://pan.baidu.com/s/1viwZ9ikYUdtB7YERtFic1Q
提取码:zzyc
语法总结
以下介绍来自于达梦数据库官网,相关的文档在官网中也是可以下载的。
达梦数据库管理系统是达梦公司推出的具有完全自主知识产权的高性能数据库管理系统,简称DM,它具有如下特点:
1、通用性
达梦数据库管理系统兼容多种硬件体系,可运行于X86、X64、SPARC、POWER等硬件体系之上。DM各种平台上的数据存储结构和消息通信结构完全一致,使得DM各种组件在不同的硬件平台上具有一致的使用特性。
达梦数据库管理系统产品实现了平台无关性,支持Windows系列、各版本Linux(2.4及2.4以上内核)、Unix、Kylin、AIX、Solaris等各种主流操作系统。达梦数据库的服务器、接口程序和管理工具均可在32位/64 位版本操作系统上使用。
2、高性能
支持列存储、数据压缩、物化视图等面向联机事务分析场景的优化选项;
通过表级行存储、列存储选项技术,在同一产品中提供对联机事务处理和联机分析处理业务场景的支持;
3、高可用
可配置数据守护系统(主备),自动快速故障恢复,具有强大的容灾处理能力。
4、跨平台
跨平台,支持主流软硬件体系(支持windows、Linux、中标麒麟、银河麒麟等操作系统),支持主流标准接口。
5、高可扩展
支持拓展软件包和多种工具,实现海量数据分析处理、数据共享集群(DSC)和无共享数据库集群(MPP)等扩展功能
与MySQL的区别
创建表的时候,不支持在列的后面直接加 comment 注释,使用 COMMENT ON IS 代替,如:
COMMENT ON TABLE xxx IS xxx
COMMENT ON COLUMN xxx IS xxx
不支持 date_sub 函数,使用 dateadd(datepart,n,date) 代替,
其中,datepart可以为:year(yy,yyyy),quarter(qq,q),month(mm,m),dayofyear(dy,y),day(dd,d),week(wk,ww),weekday(dw),hour(hh), minute(mi,n), second(ss,s), millisecond(ms)
例子:
select dateadd(month, -6, now());
select dateadd(month, 2, now());
不支持 date_format 函数,它有三种代替方法:
a: 使用 datepart 代替:语法:datepart(datepart, date),返回代表日期的指定部分的整数,
datepart可以为:year(yy,yyyy),quarter(qq,q),month(mm,m),dayofyear(dy,y),day(dd,d),week(wk,ww),weekday(dw),hour(hh), minute(mi,n),second(ss,s), millisecond(ms)
例子:
select datepart(year, '2018-12-13 08:45:00'); --2018
select datepart(month, '2018-12-13 08:45:00'); --12b: 使用 date_part 代替,功能和 datepart 一样,写法不同,参数顺序颠倒,且都要加引号,
例子:select date_part('2018-12-13 08:45:00', 'year');--2018
select date_part('2018-12-13 08:45:00', 'mm'); -- 12c: 使用 extract 代替,语法:extract(dtfield from date),从日期类型date中抽取dtfield对应的值
dtfield 可以是 year,month,day,hour,minute,second
例子:
select extract(year from ‘2018-12-13 08:45:00’); --2018
select extract(month from ‘2018-12-13 08:45:00’); --12
不支持 substring_index 函数, 使用 substr / substring 代替,
语法:
substr(char[,m[,n]])
substring(char[from m[ for n]])
不支持 group_concat 函数,使用 wm_concat 代替,
例子:
select wm_concat(id) as idstr from persion ORDER BY id ;
不支持 from_unixtime 函数,使用 round 代替
语法:round(date[,format])
不支持 case-when-then-else ,
例如:
select case when id = 2 then “aaa” when id = 3 then “bbb” else “ccc” end as test
from (select id from person) tt;
current_timestamp 的返回值带有时区,
例子:
select current_timestamp();
2018-12-17 14:34:18.433839 +08:00
convert(type, value) 函数,
与 mysql 的 convert 一样,但是参数是反过来的,mysql 是 convert(value, type)
不支持 on duplicate key update,
使用 merge into 代替
不支持 ignore,即 insert ignore into
不支持 replace into,
使用 merge into 代替
不支持 if。
不支持 “”,只支持’’
不支持 auto_increment, 使用 identity 代替
如: identity(1, 1),从 1 开始,每次增 1
不支持 longtext 类型,
可用 CLOB 代替。
总结
达梦数据库和 oracle 数据库比较像,如果找不到和 MySQL 对应的函数,可以看下 oracle 的相关函数。
其他具体语法和安装运维等细节详细见达梦官网和安装包doc文档
https://eco.dameng.com/document/dm/zh-cn/sql-dev/index.html
实战小记(持续更新):
达梦数据库开启MySQL兼容后,大部门语法可以兼容MySQL,比如groupby,不兼容MySQL,那么groupby后面出现的列必须在select出现,兼容mysql后,则跟MySQL中groupby一样。
达梦数据库char()类型是定长的 如果从MySQL同步过来,开始是char(1)–>char(3)那么存的值"y"就会变成"y ",多了空格站位,这样我们程序读取出来进行判断等于的时候就会出错。
【解决方法】:
如下三种方法
>>修改char类型为varchar2类型。
在DTS迁移时,映射char类型为varchar2类型;
>>生成批量修改char为varchar2
select ‘alter table ‘||a.TABLE_NAME||’ modify ‘||a.COLUMN_NAME||’ VARCHAR2(’||data_length||‘);’ from all_tab_columns a where a.data_type=‘CHAR’ AND OWNER=‘用户名’;
>>通过rtrim函数把数据右边的空格清除掉
update 表名 set 列名1=rtrim(列名1);
假如我们MySQL储存的数据是blob,在我们达梦中存储的是image或者BLOB类型,那么我们要读取出来如果无法显示的情况出现,可以使用函数可视化处理select utl_raw.cast_to_varchar2(dbms_lob.substr(表列)),即可完美解决(JAVA可以在xml中进行编写)
将数据类型char批量转成varchar2
-- 批量处理截取char超过得空格字符
select 'update '||a.TABLE_NAME||' set '||a.COLUMN_NAME||'= rtrim('||a.COLUMN_NAME||');'
from all_tab_columns a where a.data_type='VARCHAR2' AND OWNER='SYSDBA';
-- 批量将所有表中得char类型替换成varchar2类型
select 'alter table '||a.TABLE_NAME||' modify '||a.COLUMN_NAME||' VARCHAR2('||data_length||');'
from all_tab_columns a where a.data_type='CHAR' AND OWNER='SYSDBA';达梦关键字转化:``–>“”,关键字mysql是`号引起得,达梦用”“包关键字,如:”name“
达梦组合排序:如果列为null排在前面,达梦暂时使用nulls first来进行处理
-- mysql
order by name desc,name is not null;
-- 达梦
order by name desc,name NULLS LAST;
groupby 不是表达式(实例设置sql)
select para_name,para_value,para_type from v$dm_ini where para_name='GROUP_OPT_FLAG';
sp_set_para_value(1,'GROUP_OPT_FLAG',1);mysql需要对某列按照中文首字母进行排序: mysql:convert(列 using gbk) dm: nlssort(列, ‘NLS_SORT = SCHINESE_PINYIN_M’)











![[SUCTF 2019]EasySQL](https://img-blog.csdnimg.cn/6eb0c11911a14dd1828579fdb3b925f3.png)