文章目录
- 1. 前言
- 2. 案例背景
- 3. 案例问题
- 4. 案例分析
- 4.1 普通文件写入流程概要
- 4.2 dd 写 NAND 时,会不会使用 page cache ?
- 4.3 dd 写 NAND 时,对比 U-Boot 读 NAND,是否采用了相同的坏块策略 ?
- 4.3.1 U-Boot 读 NAND 过程中遇坏块的处理策略
- 4.3.2 Linux 写 NAND 过程中遇坏块的处理策略
- 5. 解决方案
- 5.1 避免数据在 page cache 逗留
- 5.2 数据写入同步
- 5.3 将 Linux 内核写入坏块处理 和 U-Boot 保持一直:跳过坏快
- 6. 参考资料
1. 前言
限于作者能力水平,本文可能存在谬误,因此而给读者带来的损失,作者不做任何承诺。
2. 案例背景
TI AM335x + Linux 4.19 内核,存储设备为 NAND FLASH,其包含 11 个分区,如下:
[ 1.635286] omap-gpmc 50000000.gpmc: GPMC revision 6.0
[ 1.640473] gpmc_mem_init: disabling cs 0 mapped at 0x0-0x1000000
[ 1.648388] nand: device found, Manufacturer ID: 0x2c, Chip ID: 0xda
[ 1.654908] nand: Micron MT29F2G08AAD
[ 1.658589] nand: 256 MiB, SLC, erase size: 128 KiB, page size: 2048, OOB size: 64
[ 1.666252] nand: using OMAP_ECC_BCH8_CODE_HW ECC scheme
[ 1.671692] 11 fixed-partitions partitions found on MTD device omap2-nand.0
[ 1.678704] Creating 11 MTD partitions on "omap2-nand.0":
[ 1.684146] 0x000000000000-0x000000020000 : "NAND.SPL"
[ 1.690415] 0x000000020000-0x000000040000 : "NAND.SPL.backup1"
[ 1.697268] 0x000000040000-0x000000060000 : "NAND.SPL.backup2"
[ 1.704018] 0x000000060000-0x000000080000 : "NAND.SPL.backup3"
[ 1.710719] 0x000000080000-0x0000000c0000 : "NAND.u-boot-spl-os"
[ 1.717798] 0x0000000c0000-0x0000001c0000 : "NAND.u-boot"
[ 1.724932] 0x0000001c0000-0x0000001e0000 : "NAND.u-boot-env"
[ 1.731558] 0x0000001e0000-0x000000200000 : "NAND.u-boot-env.backup1"
[ 1.738956] 0x000000200000-0x000000a00000 : "NAND.kernel"
[ 1.752614] 0x000000a00000-0x00000e000000 : "NAND.rootfs"
[ 1.958515] 0x00000e000000-0x000010000000 : "NAND.userdata"这 11 个分区,分别对应 Linux 下块设备节点 /dev/mtdblock[0~10] 。
3. 案例问题
在应用场景下,通过 dd 命令升级内核,即:
dd if=kernel.img of=/dev/mtdblock8通过上面的命令写入内核后,接着执行 reboot 命令重启系统。启动初期,U-Boot 读取内核并加载它。这样升级内核后,测试发现,某些次数的升级,内核无法启动。
4. 案例分析
要搞清楚故障的原因,需要回答下列 2 个问题:
1. dd 写 NAND 时,会不会使用 page cache ?
2. dd 写 NAND 时,对比 U-Boot 读 NAND,是否采用了相同的坏块策略 ?4.1 普通文件写入流程概要
文件系统 IO 栈 的工作过程,概要流程如下图:
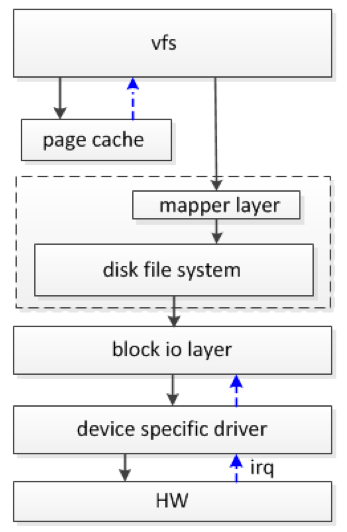
用户发起读写操作时,并不是直接操作存储设备,而是需要经过较长的 IO 栈 才能完成数据的读写。读写操作大体上需依次经过虚拟文件系统 vfs、磁盘文件系统、block 层、设备驱动层,最后到达存储器件,器件处理完成后发送中断通知驱动程序。
来看一下 普通文件 经由 page cache 写入的概要流程(假定普通文件经由 ext4fs 管理,同时 open() 时没带 O_DIRECT, O_SYNC 标志位),这里的代码流程将用来和后面通过 dd 操作 /dev/mtdblockN 设备的写入过程做对比。普通文件 经由 page cache 写入的概要流程代码如下:
// vfs
sys_write(fd, buf, count) /* fs/read_write.c */
vfs_write(f.file, buf, count, &pos);
// disk file system: ext4
ext4_file_write_iter() /* fs/ext4/file.c */
__generic_file_write_iter(iocb, from); /* mm/filemap.c */
generic_perform_write(file, from, iocb->ki_pos);
struct page *page;
...
// 首次,分配用于写入的 page cache 页面
a_ops->write_begin(file, mapping, pos, bytes, flags, &page, &fsdata);
ext4_write_begin() /* fs/ext4/inode.c */
...
/*
* 分配 或 寻找 一个符合条件的用于写入的 page cache 的页面。
* 首次,分配 page cache 页面。
*/
page = grab_cache_page_write_begin(mapping, index, flags);
...
__block_write_begin(page, pos, len, ext4_get_block);
...
*pagep = page; /* 返回 page cache 页面 */
...
/* 将数据从用户空间拷贝到内核空间 */
copied = iov_iter_copy_from_user_atomic(page, i, offset, bytes);
...
/* 提交数据写入请求 */
a_ops->write_end(file, mapping, pos, bytes, copied, page, fsdata);
block_write_end(file, mapping, pos, len, copied, page, fsdata);
__block_commit_write(inode, page, start, start+copied); /* fs/buffer.c */从上面的代码流程可以看到,整个 write() 过程中,都没有涉及到任何存储设备相关的操作,这个实际的写入最终经由 submit_bio() 提交写入请求到存储设备,譬如 shrink_page_list() 回收 page cache 页面触发等。这些细节不是本文关注的重点,在此不再细表。
通过上面的代码分析,我们只需要了解到,文件一般情形下的写入过程会经过 page cache, write() 调用返回,并不意味着数据已经写入到存储设备。
4.2 dd 写 NAND 时,会不会使用 page cache ?
我们为什么要知道,dd 写入 NAND 时会不会经过 page cache ?因为如果经过 page cache,可能会因为 写入内容没有回写到 NAND ,而导致数据异常。
对 dd 不太熟悉的朋友,可能会误解,认为 dd 对块设备节点 /dev/mtdblockN 的操作,就是对存储设备的直接操作,不会经过 page cache,常常会误以为 page cache 仅用于普通文件操作。然而事实并非如此,后面的代码分析会揭示这一点。
接着从代码细节来看一看,dd 命令对块设备 /dev/mtdblockN 的写入过程,到底会不会经过 page cache ?这里只关注 dd if=kernel.img of=/dev/mtdblock8 命令的写操作,其读操作是否经过 page cache 和分析的问题无涉,故忽略。先看一下 open("/dev/mtdblock8") 的过程:
// 先看一下 open("/dev/mtdblock8") 的过程,主要关注 fops 和 a_ops 的绑定
open("/dev/mtdblock8")
...
vfs_open(&nd->path, file);
file->f_path = *path;
do_dentry_open(file, d_backing_inode(path->dentry), NULL);
...
f->f_op = fops_get(inode->i_fop); /* 绑定 fops: &def_blk_fops */
...
if (!open)
open = f->f_op->open; /* blkdev_open() */
if (open) {
open(inode, f) = blkdev_open(inode, f); /* fs/block_dev.c */
struct block_device *bdev;
...
bdev = bd_acquire(inode);
bdev = bdget(inode->i_rdev);
struct inode *inode;
inode = iget5_locked(blockdev_superblock, hash(dev),
bdev_test, bdev_set, &dev);
...
if (inode->i_state & I_NEW) {
...
inode->i_mode = S_IFBLK;
...
/* 绑定 address space 操作接口 */
inode->i_data.a_ops = &def_blk_aops;
...
}
...
...
return blkdev_get(bdev, filp->f_mode, filp);
}上面的流程,重点关注 f_op(struct file_operations) 绑定到了 def_blk_fops,而 a_ops(struct address_space_operations) 绑定到了 def_blk_aops 。dd 的写操作也没什么稀奇的,仍然是从 write() 发起:
// vfs
sys_write(fd, buf, count) /* fs/read_write.c */
vfs_write(f.file, buf, count, &pos);
...
blkdev_write_iter() /* fs/block_dev.c */
__generic_file_write_iter(iocb, from) /* mm/filemap.c */
/*
* 后面的写入流程,在没有指定 oflag=direct 的前提下,
* 和前面分析的 普通文件 的写入流程一样,都将会使用
* page cache !!!
*/
generic_perform_write(file, from, iocb->ki_pos);
struct page *page;
/* 首次,分配 page cache 页面 */
a_ops->write_begin(file, mapping, pos, bytes, flags, &page, &fsdata);
blkdev_write_begin()
block_write_begin(mapping, pos, len, flags, pagep, blkdev_get_block);
/*
* 分配 或 寻找 一个符合条件的用于写入的 page cache 的页面。
* 首次,分配 page cache 页面。
*/
page = grab_cache_page_write_begin(mapping, index, flags);
...
*pagep = page; /* 返回 page cache 页面 */
...
...
/* 将数据从用户空间拷贝到内核空间 */
copied = iov_iter_copy_from_user_atomic(page, i, offset, bytes);
...
a_ops->write_end(file, mapping, pos, bytes, copied, page, fsdata);
blkdev_write_end()
...到此,我们可以给出本小节提出问题的答案。dd 写 NAND 时,会不会使用 page cache ?在 dd 命令未指定 oflag=direct 的前提下,dd 写入过程中的数据,会经过 page cache 。
4.3 dd 写 NAND 时,对比 U-Boot 读 NAND,是否采用了相同的坏块策略 ?
4.3.1 U-Boot 读 NAND 过程中遇坏块的处理策略
从博文 U-Boot: NAND 驱动简介 章节 3.3 NAND 写操作 和 3.4 NAND 读操作 分析知道,U-Boot 在 NAND 读写过程,遇到坏块会跳过,直到读取到要求数目的 block 为止,且坏块不会包含在读写 block 计数内。这就意味着,在 Linux 下通过 dd 写入 kernel.img ,也必须和 U-Boot 读操作保持相同的策略,即写入 NAND 时遇到坏块跳过,这样才使得启动期间 U-Boot 能正确读到 kernel.img 的完整内容,也才能正确加载内核。
4.3.2 Linux 写 NAND 过程中遇坏块的处理策略
首先,dd 并不对坏块做处理,这就要看 Linux 内核 NAND 驱动在读写过程中,对坏块的处理策略。这里只关注和本文相关写入过程中 NAND 驱动坏块处理过程。这里的分析,刻意跳过了前面冗长的无关部分,即前面分析提到的提交写操作请求到设备的部分(submit_bio()),我们重点关注块类设备拉取写操作请求,并进行实际对设备写入的部分。分析从 mtd_blktrans_work() 开始(Linux 将 NAND 设备抽象为 MTD 设备进行访问):
// 在不影响主干逻辑的前提下,为方便查看,对代码有做一些改动。
mtd_blktrans_work() /* drivers/mtd/mtd_blkdevs.c */
// 拉取一个写入请求
req = blk_fetch_request(rq);
...
// 处理写入请求
do_blktrans_request(dev->tr, dev, req);
for (; nsect > 0; nsect--, block++, buf += tr->blksize) // (1)
tr->writesect(dev, block, buf) = mtdblock_writesect() /* drivers/mtd/mtdblock.c */
if (unlikely(!mtdblk->cache_data && mtdblk->cache_size)) {
/*
* 第一次写入, 分配 cache 缓存。
*
* 注意,这里的 cache 不同于 page cache,主要是为了一些
* 非对齐数据操作等。
*/
mtdblk->cache_data = vmalloc(mtdblk->mbd.mtd->erasesize);
}
do_cached_write(mtdblk, block<<9, 512, buf); /* drivers/mtd/mtdblock.c */
// 这里只取主干逻辑
...
while (len > 0) { // (2)
erase_write (mtd, pos, size, buf);
...
// 写入之前总是要先擦除
mtd_erase(mtd, &erase); /* drivers/mtd/mtdcore.c */
if (ret) { /* 擦除出错 */
...
// 打印擦除出错的范围区间
printk (KERN_WARNING "mtdblock: erase of region [0x%lx, 0x%x] "
"on \"%s\" failed\n",
pos, len, mtd->name);
return ret; // 擦除失败,终止写入过程
}
...
// 擦除成功后再写入
mtd_write(mtd, pos, len, &retlen, buf);
}
...
...
// 展开一下前面的 mtd_erase()
mtd_erase(mtd, &erase); /* drivers/mtd/mtdcore.c */
mtd->_erase(mtd, instr) = part_erase() /* drivers/mtd/mtdpart.c */
part->parent->_erase(part->parent, instr)
nand_erase() /* drivers/mtd/nand/nand_base.c */
nand_erase_nand(mtd, instr, 0)
...
instr->state = MTD_ERASING;
while (len) { // (3)
/* Check if we have a bad block, we do not erase bad blocks! */
// 检查擦除位置是不是有坏块:无法对坏块进行擦除操作
if (nand_block_checkbad(mtd, ((loff_t) page) <<
chip->page_shift, allowbbt)) {
// 打印擦除出错的 NAND PAGE 位置
pr_warn("%s: attempt to erase a bad block at page 0x%08x\n",
__func__, page);
instr->state = MTD_ERASE_FAILED; // 标记擦除出错
goto erase_exit; // 擦除出错,终止擦除过程
}
}
instr->state = MTD_ERASE_DONE;
erase_exit:
// 擦除正常完成为 MTD_ERASE_DONE 状态, 如果不是, 返回 EIO 错误码
ret = instr->state == MTD_ERASE_DONE ? 0 : -EIO;
...
return ret;上面的代码分析告诉我们,在 Linux 下,试图写入 NAND 坏块位置,NAND 驱动将会终止写入过程,并报告错误信息。如下是试图用 dd 写入坏块时的一个例子,内核爆出如下日志:
$ dd if=/mnt/nfs-remote/t.img bs=128K seek=416 count=8 of=/dev/mtdblock9 # 执行 dd 试图往坏块位置写入
[ 6002.927447] nand: nand_erase_nand: attempt to erase a bad block at page 0x00007c80
[ 6002.935145] mtdblock: erase of region [0x3440000, 0x20000] on "NAND.rootfs" failed
[ 6002.943396] print_req_error: I/O error, dev mtdblock9, sector 107264
[ 6002.949794] Buffer I/O error on dev mtdblock9, logical block 13408, lost async page write
[ 6002.958470] nand: nand_erase_nand: attempt to erase a bad block at page 0x00007c80
[ 6002.966143] mtdblock: erase of region [0x3440000, 0x20000] on "NAND.rootfs" failed
[ 6002.973973] print_req_error: I/O error, dev mtdblock9, sector 107272
[ 6002.980360] Buffer I/O error on dev mtdblock9, logical block 13409, lost async page write
......
[ 6003.231379] nand: nand_erase_nand: attempt to erase a bad block at page 0x00007c80
[ 6003.239003] mtdblock: erase of region [0x3440000, 0x20000] on "NAND.rootfs" failed
[ 6003.246899] nand: nand_erase_nand: attempt to erase a bad block at page 0x00007c80
[ 6003.254636] mtdblock: erase of region [0x3440000, 0x20000] on "NAND.rootfs" failed
......
8+0 records in
8+0 records out
# echo $? # 查询 dd 命令的执行退出码,惊不惊喜?意不意外?
0从上面 dd 测试写坏块的例子看到,即使往坏块位置去写,dd 的退出码依然是 0 ,这可能违反我们的直觉。从前面的代码分析可以知道,出现这种现象的根本原因是因为,写入 NAND 的操作实际上分为两步:write() 给出数据写入需求后返回;然后内核在某个不确定的时间点将写入请求提交给 NAND 设备,然后 NAND 设备驱动取出写入请求并做实际的写入操作。也就是说,写入的发起和实际写入,是一个异步过程,write() 返回成功并不表示写入成功,在 NAND 设备写入时如果出错,已经没法将这个错误返回给 write(),因为 write() 可能已经(成功)返回用户空间。
到此,仍然没有对 Linux 下 NAND 坏块管理策略做出说明。下面来分析说明这一点:
// 上面判断坏块的代码
nand_block_checkbad(mtd, ((loff_t) page) << chip->page_shift, allowbbt)) /* drivers/mtd/nand/nand_base.c */
struct nand_chip *chip = mtd_to_nand(mtd);
if (!chip->bbt) /* 没有在驱动加载初期, 扫描 NAND 建立位于内存 BBT 表的情形下, */
/*
* 用 NAND 的 OOB 区域 标记 判断 是不是 NAND 坏块.
* drivers/mtd/nand/nand_base.c, nand_block_bad()
* ...
*/
return chip->block_bad(mtd, ofs);
nand_block_bad()
...
for (; page < page_end; page++) {
/*
* 读取 NAND 不带 ECC 的 OOB 数据。
* drivers/mtd/nand/nand_base.c: nand_read_oob_std() [default]
* ...
*/
res = chip->ecc.read_oob(mtd, chip, page);
nand_read_oob_std()
// 从 NAND 设备读取 OOB
chip->read_buf(mtd, chip->oob_poi, mtd->oobsize);
...
bad = chip->oob_poi[chip->badblockpos];
/* 从 NAND 读取的 OOB 数据判定是否为坏块 */
if (likely(chip->badblockbits == 8))
res = bad != 0xFF;
else
res = hweight8(bad) < chip->badblockbits;
if (res)
return res; /* 坏块 */
}
return 0; /* 非坏块 */
/* Return info from the table */
return nand_isbad_bbt(mtd, ofs, allowbbt); /* 从已经建立的内存 BBT 表判定是否为坏块 */从上面的代码分析知道,在 U-Boot 读时、Linux 写时遇到坏块的处理策略上存在差异:U-Boot 读时会跳过坏块,直到读取到要求的大小为止;而 Linux 写时,遇到坏块会报错并终止对 NAND 设备的写入过程,但由于实际对 NAND 设备的写操作相对 write() 调用是异步的,而不是在 write() 调用中完成,因此实际写操作过程中的错误状况无法反馈给 write(),即 dd 的 write() 的调用在写坏块时不会返回错误码,导致即使实际的 NAND 设备写操作发生了错误,dd 仍会继续完成所有的写操作,并最终以错误码 0 成功退出。
5. 解决方案
针对本文讨论的 2 个问题:
1. dd 写 NAND 时,会不会使用 page cache ?
2. dd 写 NAND 时,对比 U-Boot 读 NAND,是否采用了相同的坏块策略 ?分别对它们给出解决方案。
5.1 避免数据在 page cache 逗留
对于问题 1. ,可以通过将 dd 命令行选项 oflag=direct 来解决,这样写入数据可以绕过 page cache 。来看看代码实现细节:
/*
* coreutils 的 dd 命令将 oflag=direct 转换为 O_DIRECT
*/
/* src/dd.c */
/* Flags, for iflag="..." and oflag="...". */
static struct symbol_value const flags[] =
{
...
{"direct", O_DIRECT},
...
{"", 0}
};/*
* write() 时,如果设置了 O_DIRECT 的处理流程
*/
static inline bool io_is_direct(struct file *filp)
{
return (filp->f_flags & O_DIRECT) || IS_DAX(filp->f_mapping->host);
}
static inline int iocb_flags(struct file *file)
{
int res = 0;
...
if (io_is_direct(file))
res |= IOCB_DIRECT; // O_DIRECT ==> IOCB_DIRECT
...
return res;
}
// vfs
sys_write(fd, buf, count) /* fs/read_write.c */
vfs_write(f.file, buf, count, &pos);
// 这里比前面的分析细化了一点,主要是标志位 O_DIRECT 的处理
__vfs_write(file, buf, count, pos);
new_sync_write(file, p, count, pos);
...
init_sync_kiocb(&kiocb, filp);
*kiocb = (struct kiocb) {
...
.ki_flags = iocb_flags(filp), // O_DIRECT ==> IOCB_DIRECT
...
};
...
call_write_iter(filp, &kiocb, &iter);
blkdev_write_iter()
__generic_file_write_iter(iocb, from);
...
if (iocb->ki_flags & IOCB_DIRECT) { /* O_DIRECT */
loff_t pos, endbyte;
/* 不通过 page cache 的 direct IO */
written = generic_file_direct_write(iocb, from);
/*
* If the write stopped short of completing, fall back to
* buffered writes. Some filesystems do this for writes to
* holes, for example. For DAX files, a buffered write will
* not succeed (even if it did, DAX does not handle dirty
* page-cache pages correctly).
*/
if (written < 0 || !iov_iter_count(from) || IS_DAX(inode))
goto out;
/*
* 如果不带 page cache 的 direct 没有写入所有数据 或 失败,
* 我们用带 page cache 的 写入操作,此时,为了保持 O_DIRECT
* 的语义,需要将 page cache 中写入的内容刷入到存储设备,然
* 后将这些 page cache 页面置为无效状态。
*/
status = generic_perform_write(file, from, pos = iocb->ki_pos);
...
endbyte = pos + status - 1;
err = filemap_write_and_wait_range(mapping, pos, endbyte);
if (err == 0) {
iocb->ki_pos = endbyte + 1;
written += status;
/* 将 page cache 页面置为无效状态 */
invalidate_mapping_pages(mapping,
pos >> PAGE_SHIFT,
endbyte >> PAGE_SHIFT);
} else {
...
}
} else {
// 没有设置 O_DIRECT 的时候执行路径,也就是前面分析的执行路径
...
}
// 展开 generic_file_direct_write()
written = generic_file_direct_write(iocb, from); /* 不通过 page cache 的 direct IO */
...
// 这里代码有做些调整,不影响主干逻辑
written = filemap_write_and_wait_range(mapping, pos, pos + write_len - 1);
...
written = invalidate_inode_pages2_range(mapping, pos >> PAGE_SHIFT, end);
...
written = mapping->a_ops->direct_IO(iocb, from);
blkdev_direct_IO(iocb, from)
__blkdev_direct_IO(iocb, iter, min(nr_pages, BIO_MAX_PAGES));
...
/* 分配当前数据的第一个 bio */
bio = bio_alloc_bioset(GFP_KERNEL, nr_pages, blkdev_dio_pool);
bio_get(bio); /* extra ref for the completion handler */
...
dio->is_sync = is_sync = is_sync_kiocb(iocb);
if (dio->is_sync)
dio->waiter = current;
else
...
...
for (;;) {
bio_set_dev(bio, bdev);
bio->bi_iter.bi_sector = pos >> 9;
...
/* 设置 bio 已经提交到 io 请求队列时回调, 但数据还没有写到存储设备 */
bio->bi_end_io = blkdev_bio_end_io;
...
nr_pages = iov_iter_npages(iter, BIO_MAX_PAGES);
if (!nr_pages) {
qc = submit_bio(bio); /* 提交当前数据的最后一个 bio 请求 */
break; /* 退出循环 */
}
...
submit_bio(bio); /* 提交一个 bio 请求 */
bio = bio_alloc(GFP_KERNEL, nr_pages); /* 分配一个新的 bio */
}
...
/* 等待所有 bio 进入 io 请求队列 */
for (;;) {
// bio 进入 io 请求队列时触发的回调 blkdev_bio_end_io()
// 修改 dio->waiter 并唤醒在这里等待的进程。
set_current_state(TASK_UNINTERRUPTIBLE);
if (!READ_ONCE(dio->waiter))
break;
if (!(iocb->ki_flags & IOCB_HIPRI) ||
!blk_mq_poll(bdev_get_queue(bdev), qc))
io_schedule();
}
__set_current_state(TASK_RUNNING);
...
...
iov_iter_revert(from, write_len - iov_iter_count(from));
out:
return written; // 返回 direct IO 写入字节数
blkdev_bio_end_io()
if (dio->multi_bio && !atomic_dec_and_test(&dio->ref)) {
...
} else {
if (!dio->is_sync) {
...
} else {
struct task_struct *waiter = dio->waiter;
/*
* 唤醒在 __blkdev_direct_IO() 等待 bio 进入 io 请求队列的进程:
* __blkdev_direct_IO()
* for (;;) {
* set_current_state(TASK_UNINTERRUPTIBLE);
* if (!READ_ONCE(dio->waiter))
* break;
* ...
* }
*/
WRITE_ONCE(dio->waiter, NULL);
wake_up_process(waiter);
}
}
...从上面的分析我们了解到,dd 带上 oflag=direct (即 open() 带上 O_DIRECT 标志),告诉内核不使用 page cache(或同等操作,详见代码分析)进行写入操作,这样可以避免数据逗留在 page cache 而导致数据异常的情况。但要知道的是,write() 调用返回时,只是保证写入的 bio 已经进行设备的 io 请求队列;至于这些 io 请求什么时候兑现,即真正的将数据写入存储设备,这是不确定的,write() 仍然无法知道存储设备的写入错误。
前面提到了 bio,有必要对 bio 做一些简单说明。按照 io 请求的生命周期,io 请求被抽象成了 bio、request(简称 rq)、cmd。bio 由前面提到的 submit_bio() 接口提交。访问存储器件上相邻区域的 bio、request 可能会被合并,称为 bio merge、request merge。若 bio 的长度超过软件或者硬件的限制,bio 会被拆分成多个,称为 bio split。block 层接收到一个 bio 后,这个 bio 将生成一个新的 request,或者合并到已有的 request 中。如下图所示:
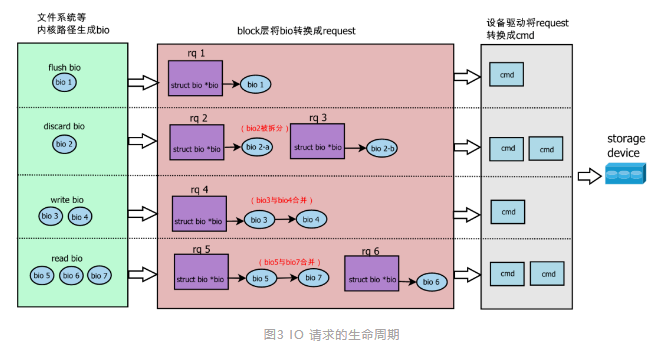
更多关于 bio 的细节,可参考博文 linux IO Block layer 解析 。
5.2 数据写入同步
章节 5.1 中,给 dd 加上 oflag=direct 避免了写入数据在 page cache 逗留的问题。如果同时给 dd 带上 oflag=sync 标记(即 dd oflag=direct,sync) ,则可以认为在没有写入错误的情况下(没遇到坏块), write() 调用返回时数据已经写入设备(实际上这也只是软件层面的保证,存储设备本身可能也会有写入缓存)。来看一下 dd 带上 oflag=sync 标记时发生了什么。首先 dd 将 oflag=sync 转换为 O_SYNC 标记:
/* src/dd.c */
/* Flags, for iflag="..." and oflag="...". */
static struct symbol_value const flags[] =
{
...
{"sync", O_SYNC},
...
{"", 0}
};看 O_SYNC 标记对写入过程的影响:
/*
* write() 时,如果设置了 O_SYNC 的处理流程
*/
#ifndef O_SYNC
#define __O_SYNC 04000000
#define O_SYNC (__O_SYNC|O_DSYNC)
#endif
static inline int iocb_flags(struct file *file)
{
int res = 0;
...
// O_SYNC ==> IOCB_DSYNC | IOCB_SYNC
if ((file->f_flags & O_DSYNC) || IS_SYNC(file->f_mapping->host))
res |= IOCB_DSYNC;
if (file->f_flags & __O_SYNC)
res |= IOCB_SYNC;
return res;
}
// vfs
sys_write(fd, buf, count) /* fs/read_write.c */
vfs_write(f.file, buf, count, &pos);
__vfs_write(file, buf, count, pos);
new_sync_write(file, p, count, pos);
init_sync_kiocb(&kiocb, filp);
*kiocb = (struct kiocb) {
...
// O_SYNC ==> IOCB_DSYNC | IOCB_SYNC
.ki_flags = iocb_flags(filp),
...
};
call_write_iter(filp, &kiocb, &iter);
blkdev_write_iter()
ret = __generic_file_write_iter(iocb, from);
if (ret > 0) /* 写入成功, 根据 sync 设置看是否要做数据同步操作 */
ret = generic_write_sync(iocb, ret);
if (iocb->ki_flags & IOCB_DSYNC) { /* 如果需要做数据同步操作 */
/* 做数据同步操作 */
int ret = vfs_fsync_range(iocb->ki_filp,
iocb->ki_pos - count, iocb->ki_pos - 1,
(iocb->ki_flags & IOCB_SYNC) ? 0 : 1);
if (ret) /* 数据同步操作出错 */
return ret;
}
return count; /* 数据同步操作成功 */
...
// 展开一下 vfs_fsync_range()
int ret = vfs_fsync_range(iocb->ki_filp,
iocb->ki_pos - count, iocb->ki_pos - 1,
(iocb->ki_flags & IOCB_SYNC) ? 0 : 1);
...
return file->f_op->fsync(file, start, end, datasync);
blkdev_fsync(file, start, end, datasync)
error = file_write_and_wait_range(filp, start, end);
...
error = blkdev_issue_flush(bdev, GFP_KERNEL, NULL);
...
bio = bio_alloc(gfp_mask, 0);
bio_set_dev(bio, bdev);
bio->bi_opf = REQ_OP_WRITE | REQ_PREFLUSH; // flush 数据到存储设备
ret = submit_bio_wait(bio);
...5.3 将 Linux 内核写入坏块处理 和 U-Boot 保持一直:跳过坏快
从前面分析了解到,直接使用 dd ,无法自动跳过坏块,那么就需要通过 MTD 子系统提供的字符类设备 /dev/mtdN 来进行编程:
1. 通过 ioctl(MEMGETBADBLOCK) 判定设备的坏块,写入遇到坏块时跳过;
2. 写数据时进行数据同步,从软件层面确保写入操作完成时,数据已经到达存储设备。到此,对于本文所叙问题,已经给出了一个解决方案,这不一定是唯一或者最好的解决方案,甚至在实际场景都不一定是正确的解决方案,一切都需要时间来验证。要注意的是,sync 和 direct IO 都可能导致性能损失,这需要权衡是否能够用在实际环境中。
6. 参考资料
[1] linux IO Block layer 解析
[2] https://www.man7.org/linux/man-pages/man1/dd.1.html