
一、背景:
在人工智能领域,尤其是计算机视觉和自然语言处理中,自回归(AR)大型模型(如GPT系列)因其强大的生成能力和在多种任务上的通用性而受到广泛关注。这些模型通过自监督学习策略,即预测序列中的下一个标记,展现出了卓越的性能和可扩展性。然而,在图像生成领域,传统的自回归模型面临着性能不足和计算效率低下的问题,尤其是在与扩散模型等其他先进生成模型的比较中。因此,研究者们一直在探索如何改进自回归模型,使其在图像生成任务上达到甚至超越现有技术的性能。
二、摘要:
论文:https://arxiv.org/pdf/2404.02905.pdf
代码:https://github.com/FoundationVision/VAR
本文提出了一种名为视觉自回归(VAR)建模的新范式,它通过将图像的自回归学习重新定义为“下一尺度预测”,与传统的栅格扫描“下一个标记预测”方法不同。VAR模型采用多尺度VQ-VAE来编码图像,并利用自回归Transformer来学习图像的分布。这种方法不仅提高了图像生成的质量,还显著加快了推理速度。VAR模型在ImageNet 256×256基准测试中的表现超越了现有的自回归和扩散模型,其Fréchet inception distance (FID) 和inception score (IS) 分别达到了1.80和356.4,同时推理速度提升了20倍。文章中甚至做了与DiTs相同量级参数的对比,指标上也有明显优势。
VAR模型还展现出了类似大型语言模型(LLMs)的幂律缩放法则和零样本泛化能力,这表明通过扩大模型规模可以持续提高性能。此外,VAR模型在图像修复、外绘和编辑等下游任务中也表现出色,无需特殊设计或微调即可泛化到新任务。
文章的贡献包括提出了一种新的视觉效果生成框架、验证了VAR模型的缩放法则和零样本泛化潜力,并提供了开源代码以促进视觉自回归学习的进步。这些成果不仅推动了图像生成技术的发展,也为将自然语言处理领域的成功经验整合到计算机视觉中提供了新的思路。
三、算法
本文的核心算法创新、亮点、贡献以及细节网络结构和训练步骤如下:
核心算法创新:
- Visual AutoRegressive (VAR) modeling:本文提出了一种新的图像生成范式,即视觉自回归模型(VAR),它将图像的自回归学习重新定义为粗到细的“下一尺度预测”或“下一分辨率预测”,与传统的栅格扫描“下一个标记预测”不同。
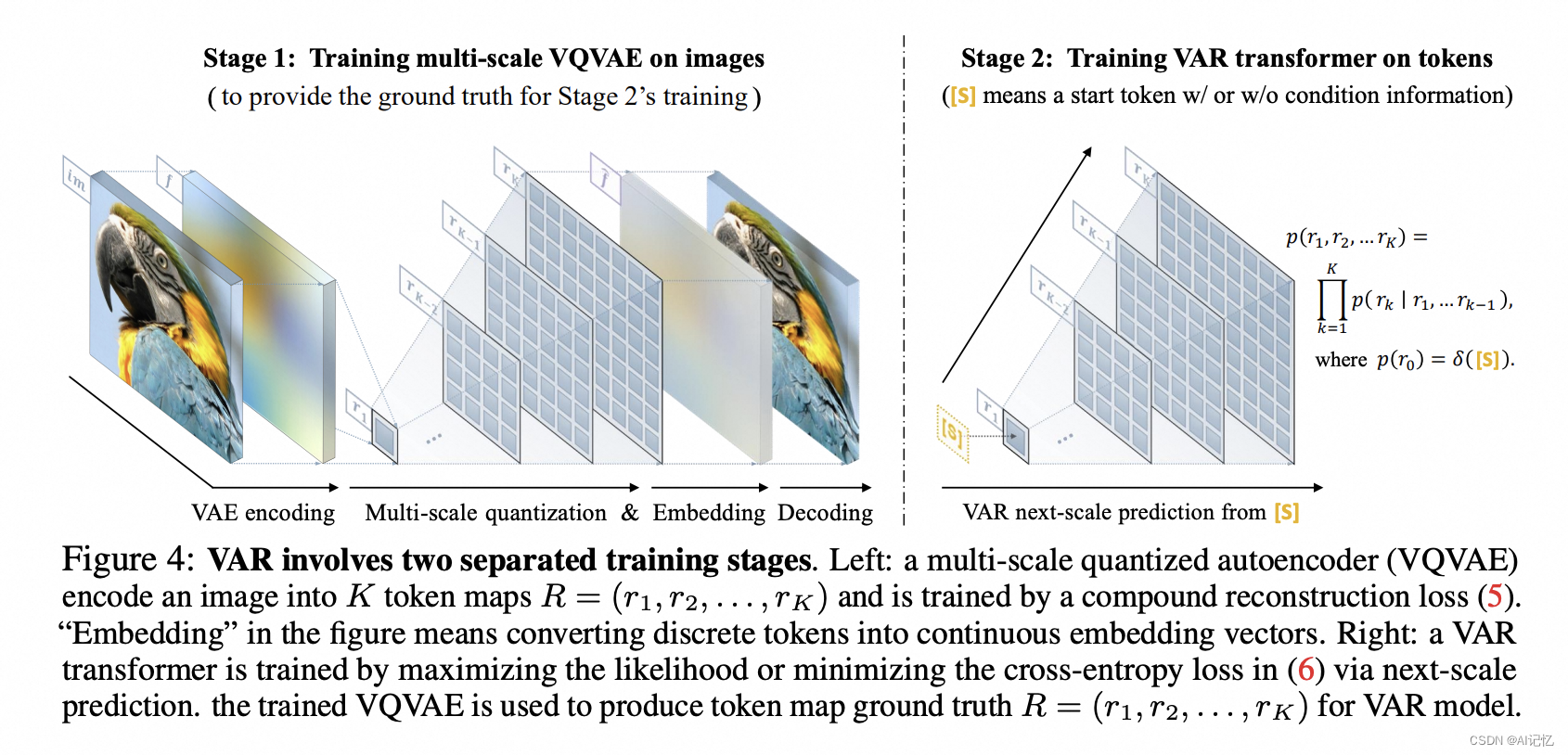
- 多尺度VQ-VAE:VAR模型需要一个多尺度的向量量化自编码器(VQ-VAE)来工作,该自编码器能够将图像编码为不同分辨率的标记图(token maps)。
- 并行标记生成:在每个尺度上,VAR模型能够并行生成标记,这显著提高了生成效率。
亮点:
- 性能超越:VAR模型首次使得GPT风格的自回归模型在图像生成方面超越了扩散变换器(diffusion transformers)。
- 高效推理速度:在ImageNet 256×256基准测试中,VAR模型的推理速度比AR基线快20倍。
- 多维度优势:VAR在图像质量、推理速度、数据效率和可扩展性方面均优于Diffusion Transformer (DiT)。

- 幂律缩放法则:VAR模型展现出与大型语言模型(LLMs)中观察到的类似的幂律缩放法则,证明了其在性能预测方面的潜力。
- 零样本泛化能力:VAR在图像修复、外绘和编辑等下游任务中展示了零样本泛化能力。
贡献:
- 提出了一种新的多尺度自回归范式,为计算机视觉中的自回归算法设计提供了新的见解。
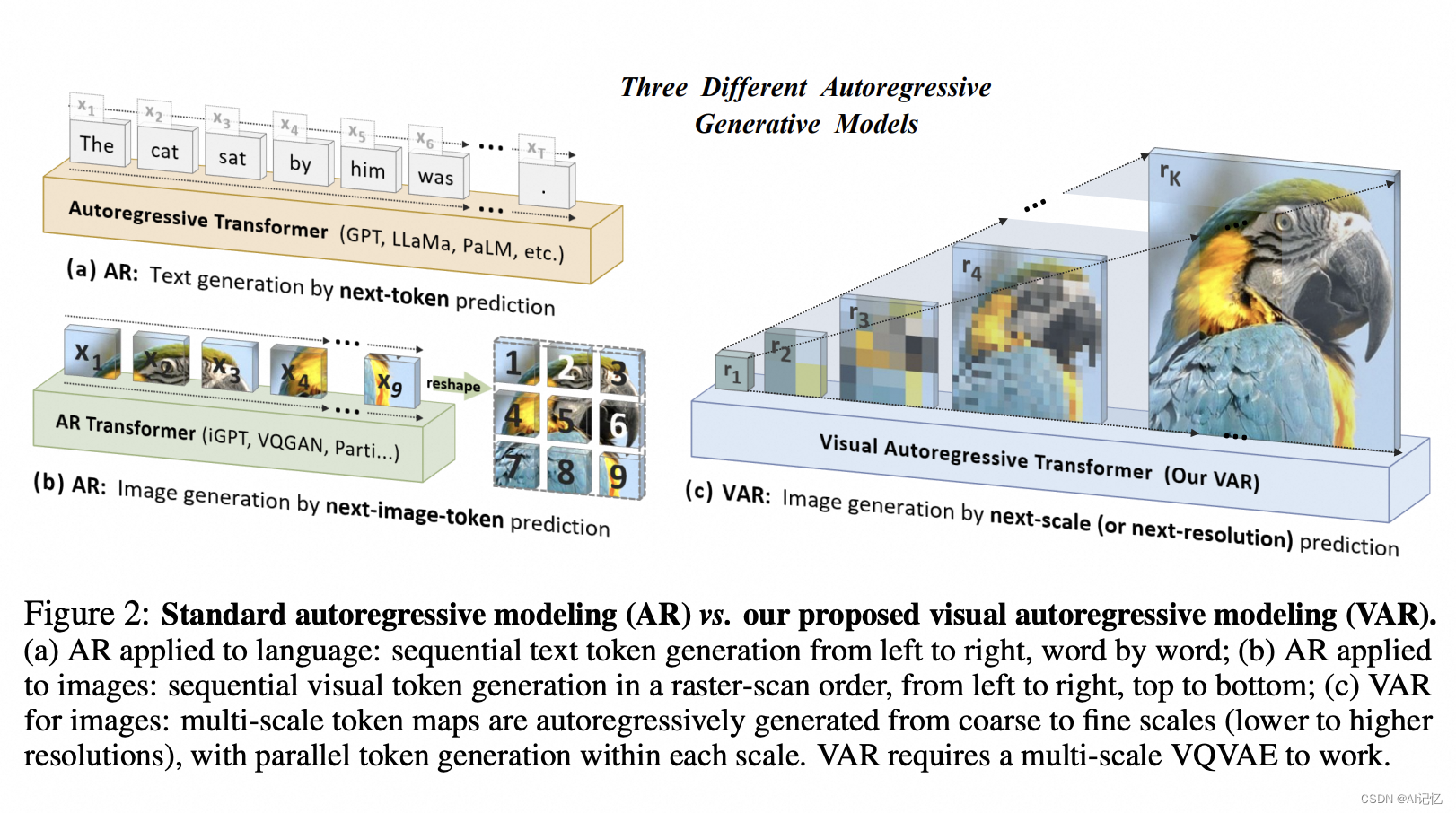
- 经验性验证了VAR模型的缩放法则和零样本泛化潜力,这些特性最初模仿了大型语言模型(LLMs)的吸引力。
- 在图像合成方面,使GPT风格的自回归方法首次超越了强大的扩散模型。
- 提供了一个全面的开源代码套件,包括VQ标记器和自回归模型训练流程,以推动视觉自回归学习的进步。
细节网络结构:
- 多尺度VQ-VAE:使用与VQGAN相同的架构,但修改了多尺度量化层,以编码图像到多个离散标记图。
- VAR Transformer:采用了类似于GPT-2的解码器仅Transformer架构,唯一的修改是将传统的层归一化替换为自适应归一化(AdaLN)。
- 模型参数和训练:模型的宽度、头数和丢弃率与深度线性缩放,所有模型均使用类似的设置进行训练。
训练步骤:
- 训练多尺度VQ-VAE:首先,使用复合重建损失训练多尺度量化自编码器,将图像编码为K个标记图。
- 训练VAR Transformer:然后,通过最大化似然或最小化交叉熵损失来训练VAR Transformer,进行下一尺度预测。
这些创新和贡献表明,VAR模型在图像生成领域具有重要的应用潜力,并且通过开源代码的提供,将进一步推动相关技术的发展和应用。
四、效果










![[Meachines][Easy] Usage](https://img-blog.csdnimg.cn/img_convert/62515585be4342b217e3d2cd5a9db43c.jpeg)

