摘要
从指定网址获取公募基金净值数据,快速解析并存储数据。
(该博文针对自由学习者获取数据;而在投顾、基金、证券等公司,通常有Wind、聚源、通联等厂商采购的数据)
- 导入所需的库:代码导入了一些常用的库,包括ast(用于安全地将字符串转换为Python对象)、pandas(用于数据处理)、requests(用于发送HTTP请求)、re(用于正则表达式匹配)、sqlalchemy和 pymysql(用于数据库操作)。
- 定义HTTP请求的头部信息:headers字典包含了HTTP请求的头部信息,包括用户代理、接受的内容类型等。
- 主程序入口:使用 if name == ‘main’: 来确保代码在作为脚本运行时才执行。
- 发送HTTP请求获取数据:通过 requests.get() 发送HTTP GET请求获取公募基金的净值数据,并使用response.raise_for_status() 来检查是否请求成功。
- 解析数据:使用正则表达式从响应文本中提取JSON格式的数据,并通过 ast.literal_eval()将字符串转换为Python对象。
- 数据处理:将JSON数据转换为 pandas 的DataFrame对象,并进行必要的数据处理,选择需要的列并添加基金代码列。
- 数据库操作:使用 sqlalchemy.create_engine()创建数据库引擎,将DataFrame数据写入MySQL数据库中的指定表格。
- 异常处理:使用 try…except… 结构来捕获可能发生的异常,如网络请求错误。
源码
import ast
import pandas as pd
import requests
import re
import sqlalchemy
import pymysql
"""
desc: 采集公募基金净值
author: xiong
"""
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Cookie": "st_si=58097080196087; st_asi=delete; qgqp_b_id=7443897b6898879ff2ccc867c516cf28; EMFUND1=null; EMFUND2=null; EMFUND3=null; EMFUND4=null; EMFUND5=null; EMFUND6=null; EMFUND7=null; EMFUND0=null; EMFUND9=04-16%2021%3A02%3A33@%23%24%u4E1C%u5434%u79FB%u52A8%u4E92%u8054%u6DF7%u5408A@%23%24001323; EMFUND8=04-16 21:15:34@#$%u4E1C%u5434%u79FB%u52A8%u4E92%u8054%u6DF7%u5408C@%23%24002170; st_pvi=04007721649495; st_sp=2022-12-16%2010%3A38%3A55; st_inirUrl=https%3A%2F%2Fwww.1234567.com.cn%2F; st_sn=42; st_psi=20240416211534146-112200305282-1968554493",
"Host": "api.fund.eastmoney.com",
"Referer": "https://fundf10.eastmoney.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
}
if __name__ == '__main__':
print(f'-------------------------开始爬取基金净值-----------------------')
fund_code = "002170"
page, page_size = 1, 1000
start_date, end_date = "2022-04-16", "2024-04-16"
url = f'https://api.fund.eastmoney.com/f10/lsjz?callback=jQuery18309423849775920161_1713265454102&' \
f'fundCode={fund_code}&pageIndex={page}&pageSize={page_size}&' \
f'startDate={start_date}&endDate={end_date}&_=1713273437750'
try:
# 1. 爬取数据
response = requests.get(url=url, headers=headers)
response.raise_for_status() # Raises an exception for HTTP errors
print(f'-------------------------1. 成功爬取数据-----------------------')
# 2. 解析数据
data_str = re.findall('\[(.*?)\]', response.text)[0].replace("null", "None")
data = ast.literal_eval(data_str)
print(f'-------------------------2. 完成解析数据-----------------------')
# 3. 数据入库
fund_nav_df = pd.DataFrame(data)
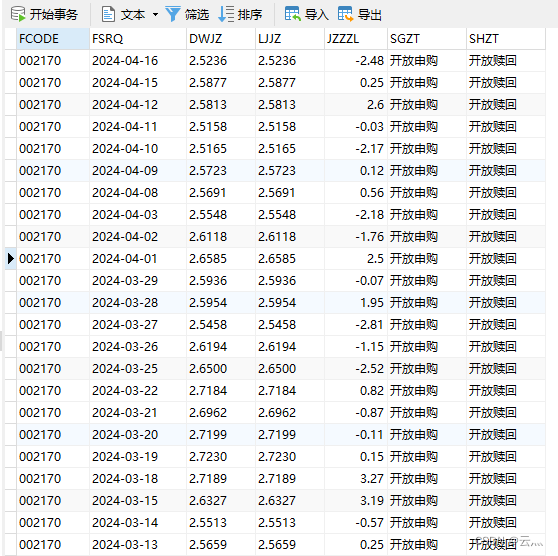
fund_nav_df = fund_nav_df[['FSRQ', 'DWJZ', 'LJJZ', 'JZZZL', 'SGZT', 'SHZT']]
fund_nav_df.insert(0, 'FCODE', fund_code)
print(fund_nav_df)
pymysql.install_as_MySQLdb()
engine: sqlalchemy.engine.Engine = sqlalchemy.create_engine(
'mysql://root:282013@localhost/xjjjj?charset=utf8', pool_size=50, pool_recycle=200
)
fund_nav_df.to_sql('fund_nav', con=engine, if_exists='append', index=False)
print(f'-------------------------3. 完成数据入库-----------------------')
except requests.exceptions.RequestException as e:
print(f"Error fetching data: {e}")
数据库
-- ----------------------------
-- Table structure for fund_nav
-- ----------------------------
DROP TABLE IF EXISTS `fund_nav`;
CREATE TABLE `fund_nav` (
`FCODE` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '基金代码',
`FSRQ` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '' COMMENT '净值日期',
`DWJZ` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '单位净值',
`LJJZ` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '累计净值',
`JZZZL` double(16, 8) DEFAULT NULL COMMENT '净值增长率',
`SGZT` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '申购状态',
`SHZT` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '赎回状态'
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
结果

预告
下一期:基金十大重仓数据分析








![[Meachines][Easy] Usage](https://img-blog.csdnimg.cn/img_convert/62515585be4342b217e3d2cd5a9db43c.jpeg)