1. 引言
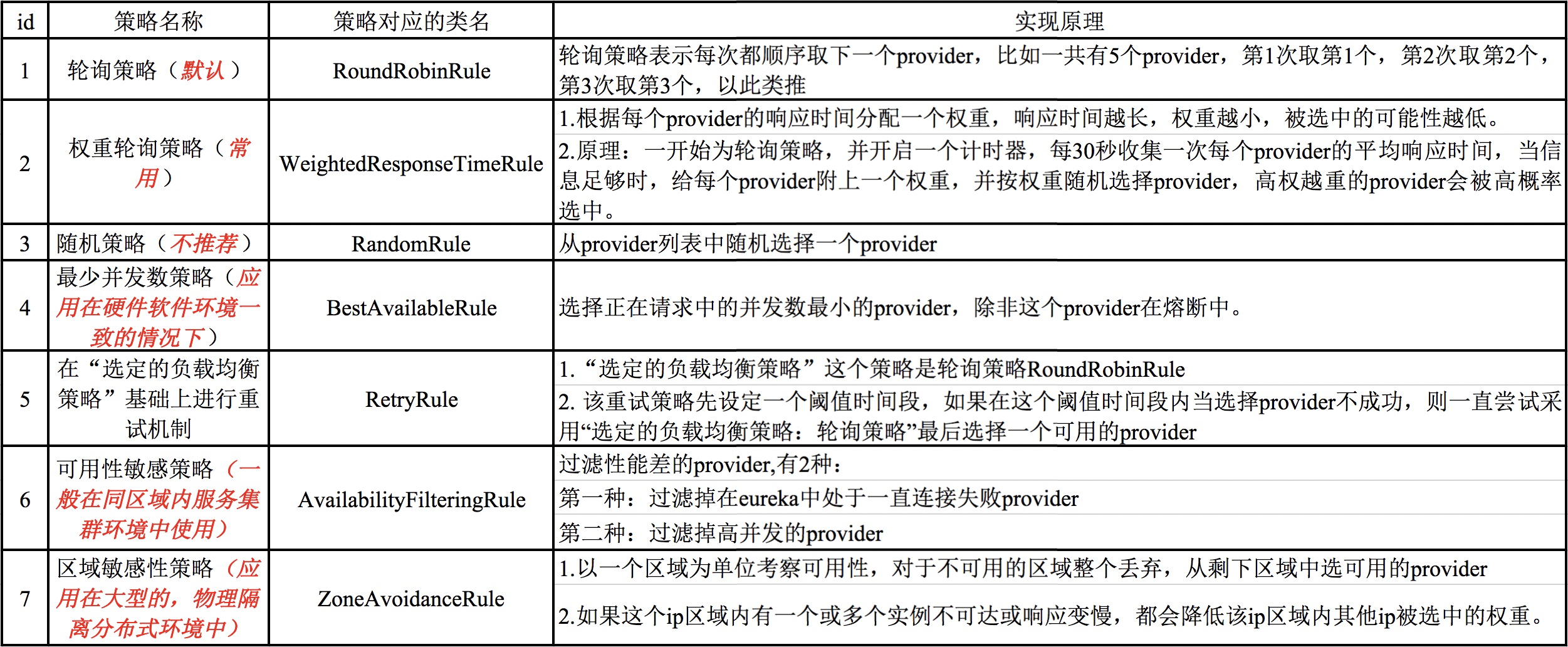
Seaborn 是建立在 matplotlib 基础上的数据可视化库,并与 Python 中的 pandas 数据结构紧密结合。可视化是 Seaborn 的核心部分,有助于直观的理解数据。
闲话少说,我们直接开始吧!
2. 安装
Seaborn库主要提供以下功能:
面向数据集的应用程序接口,用于确定变量之间的关系。
自动估计和绘制线性回归图。
它支持多网格图的高级抽象。
使用Seaborn库,我们可以方便地绘制各种图形。我们可以使用的以下命令进行安装:
pip install seaborn
要初始化 Seaborn 库,一般使用以下命令:
import seaborn as sns
3. 引入数据集
为了展示使用 Seaborn 库进行各种图形的绘制,我们这里使用googleplaystore.csv数据集,大家可以在kaggle网站进行下载。
在继续之前,首先让我们访问一下数据集:
import pandas as pd
import numpy as np
pstore = pd.read_csv("googleplaystore.csv")
pstore.head(10)
数据集的示例如下:

4. 数据直方分布图
首先,让我们看看上述数据集中第三列 Rating 列即APP评分列的数据直方分布图,代码如下:
#importing all the libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
pstore = pd.read_csv("googleplaystore.csv")
#Create a distribution plot for rating
sns.distplot(pstore.Rating)
plt.show()
运行后得到结果如下:

观察上图,在直方分布图上绘制的曲线KDE就是近似的概率密度曲线。
5. 参数设置
与matplotlib 中的直方图类似,在直方分布图中,我们也可以改变bins 数目,使图形更易于理解。
#Change the number of bins
sns.distplot(inp1.Rating, bins=20, kde=False)
plt.show()
现在,图表看起来是这样的,如下:

在上图中,我们在代码中设置kde = False 后,运行后没有概率密度曲线。要删除该曲线,只需对变量kde 进行相应设置即可。
6. 控制颜色
我们还可以像matplotlib 一样为直方分布图提供标题和颜色。相关代码如下:
#importing all the libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#Create a distribution plot for rating
sns.distplot(pstore.Rating, bins=20, color="g")
plt.title("Distribution of app ratings", fontsize=20, color = 'red')
plt.show()
运行后结果如下:

7. 默认样式
使用 Seaborn 的最大优势之一是,它为我们的图表提供了多种默认样式选项。以下都是 Seaborn 提供的默认样式:
'Solarize_Light2',
'_classic_test_patch',
'bmh',
'classic',
'dark_background',
'fast',
'fivethirtyeight',
'ggplot',
'grayscale',
'seaborn',
'seaborn-bright',
'seaborn-colorblind',
'seaborn-dark',
'seaborn-dark-palette',
'seaborn-darkgrid',
'seaborn-deep',
'seaborn-muted',
'seaborn-notebook',
'seaborn-paper',
'seaborn-pastel',
'seaborn-poster',
'seaborn-talk',
'seaborn-ticks',
'seaborn-white',
'seaborn-whitegrid',
'tableau-colorblind10'
我们只需编写一行代码,就能将这些样式整合到我们的图表中。
#importing all the libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#Adding dark background to the graph
plt.style.use("dark_background")
#Create a distribution plot for rating
sns.distplot(pstore.Rating, bins=20, color="g")
plt.title("Distribution of app ratings", fontsize=20, color = 'red')
plt.show()
为图表添加深色背景后,分布图看起来就像这样了,如下所示:

8. 饼图
饼图一般用于分析不同类别中的数据分布。在我们使用的数据集中,我们将分析内容评级列Content Rating 中排名前 4 位的类别的数量。首先,我们将对 "内容评级 "列Content Rating 进行数据清理和挖掘,并统计相应类别的数量。
#importing all the libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#Analyzing the Content Rating column
count = pstore['Content Rating'].value_counts()
print(count)
得到结果如下:

根据上述输出结果,由于 Adults only 18+ 和 Unrated 的这两个类别的计数明显少于其他类别,我们将从内容分级中删除这些类别并更新数据集。
#Remove the rows with values which are less represented
pstore = pstore[~pstore['Content Rating'].isin(["Adults only 18+","Unrated"])]
#Resetting the index
pstore.reset_index(inplace=True, drop=True)
#Analyzing the Content Rating column again
count = pstore['Content Rating'].value_counts()
print(count)
得到结果如下:

现在,让我们为 上述统计结果绘制相应的饼图,代码如下:
#Plotting a pie chart
plt.figure(figsize=[9,7])
pstore['Content Rating'].value_counts().plot.pie()
plt.show()
运行后得到结果如下:

9. 柱状图
观察上述代码输出的饼图中,我们无法正确推断类别 Everyone 10+和类别 Mature 17+这两个类别的比例谁大。当这两个类别的数值有些相似时,直接观察饼图很难评估它们之间的差异。
此时,我们可以将上述数据绘制成柱状图来克服这种情况。绘制柱状图的代码如下:
#Plotting a bar chart
plt.figure(figsize=[9,7])
pstore['Content Rating'].value_counts().plot.barh()
plt.show()
运行后如下:

当然,我们可以给不同类别设置不同颜色,如下:
plt.figure(figsize=[9,7])
pstore['Content Rating'].value_counts().plot.barh(color=["purple","orange","green","pink"])
plt.show()
结果如下:

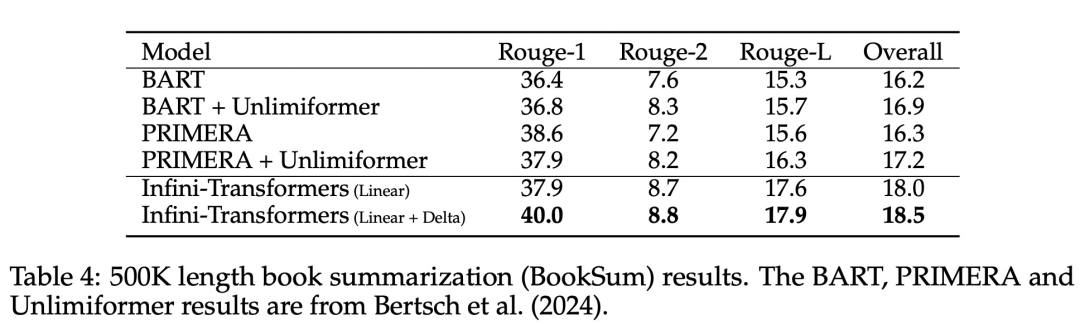
10. 总结
本文重点介绍了如何利用Seaborn库绘制数据直方分布图以及饼图和柱状图,并给出了相应的代码示例!
您学废了嘛!