👽发现宝藏
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【点击进入巨牛的人工智能学习网站】。
Django中的数据库优化与ORM性能调优
在开发基于Django的Web应用程序时,数据库是至关重要的组成部分之一。Django的ORM(对象关系映射)为开发者提供了便利,使得与数据库的交互变得简单且直观。然而,在处理大量数据或者对性能要求较高的应用中,数据库优化和ORM性能调优是至关重要的。本文将介绍一些优化数据库和ORM性能的技巧,并提供相应的案例代码。

1. 使用索引
索引是提高数据库查询效率的关键。在Django中,可以通过在模型的字段上添加db_index=True来为字段创建索引。
from django.db import models
class MyModel(models.Model):
name = models.CharField(max_length=100, db_index=True)
age = models.IntegerField()
上述代码中,为name字段创建了索引,这将加快根据name字段进行的查询操作。
2. 批量操作
当需要对大量数据进行操作时,尽量使用批量操作而不是逐个操作。这可以减少与数据库的交互次数,提高效率。
from myapp.models import MyModel
# 不推荐的逐个操作
for item in queryset:
item.save()
# 推荐的批量操作
MyModel.objects.bulk_create([MyModel(name='name1', age=20), MyModel(name='name2', age=25)])
3. select_related和prefetch_related
在处理关联查询时,使用select_related和prefetch_related可以减少数据库查询次数,提高性能。
from myapp.models import Author, Book
# 使用select_related
book = Book.objects.select_related('author').get(pk=1)
# 使用prefetch_related
authors = Author.objects.prefetch_related('books')
4. 优化查询集
在处理查询集时,尽量避免使用all()方法,而是根据实际需求选择只取需要的字段或者进行过滤操作,以减少数据传输和处理的开销。
from myapp.models import MyModel
# 不推荐的查询方式
items = MyModel.objects.all()
# 推荐的查询方式
items = MyModel.objects.filter(age__gt=18).values_list('name', flat=True)
5. 使用延迟加载
对于一些不是必需立即加载的大字段或关联对象,可以使用延迟加载以提高初始加载速度。
from django.db import models
class MyModel(models.Model):
name = models.CharField(max_length=100)
big_text_field = models.TextField()
# 延迟加载
obj = MyModel.objects.defer('big_text_field').get(pk=1)
6. 使用Raw SQL
在某些情况下,使用原生的SQL语句可能比ORM更高效。Django允许执行原生SQL查询,这在需要进行复杂的数据操作时非常有用。
from django.db import connection
def custom_query():
with connection.cursor() as cursor:
cursor.execute("SELECT * FROM myapp_mymodel WHERE age > %s", [18])
result = cursor.fetchall()
return result

7. 数据库连接池
对于高负载的应用程序,使用数据库连接池可以有效地管理数据库连接,减少连接的创建和销毁开销,提高性能和并发能力。
# 使用django-db-pool插件配置数据库连接池
# settings.py
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'mydatabase',
'USER': 'myuser',
'PASSWORD': 'mypassword',
'HOST': 'localhost',
'PORT': '3306',
'OPTIONS': {
'pool_size': 10,
'max_overflow': 5,
'pool_timeout': 30,
},
}
}
8. 缓存
使用缓存可以减少数据库查询次数,提高数据访问速度。Django内置了缓存机制,可以轻松地将常用数据缓存起来。
from django.core.cache import cache
def get_cached_data():
data = cache.get('my_cached_data')
if not data:
data = MyModel.objects.all()
cache.set('my_cached_data', data, timeout=3600)
return data
9. 数据库结构优化
合理设计数据库结构也是优化数据库性能的重要步骤。包括适当的范式化、索引优化、表分区等手段都可以提高数据库的性能。
# 示例:合理设计数据模型,避免过度冗余和不必要的字段
class UserProfile(models.Model):
user = models.OneToOneField(User, on_delete=models.CASCADE)
bio = models.TextField()
avatar = models.ImageField(upload_to='avatars/')
# 其他字段...
10. 分页查询
对于大量数据的查询,使用分页可以有效地减轻数据库的负载和减少数据传输的开销,同时提高用户体验。
from django.core.paginator import Paginator
def paginated_query(page_number, page_size):
queryset = MyModel.objects.all()
paginator = Paginator(queryset, page_size)
page_obj = paginator.get_page(page_number)
return page_obj.object_list
11. 监控和调优
持续监控数据库的性能并进行调优是保证应用程序高效运行的重要手段。可以使用一些监控工具来实时监测数据库的负载、查询性能等指标,并根据监控数据进行调整和优化。

# 使用Django Debug Toolbar等工具进行性能监控
# 安装并配置Django Debug Toolbar
# settings.py
INSTALLED_APPS = [
...
'debug_toolbar',
...
]
MIDDLEWARE = [
...
'debug_toolbar.middleware.DebugToolbarMiddleware',
...
]
12. 数据库备份与恢复
定期进行数据库备份是保障数据安全的重要措施之一。在数据库出现问题或需要迁移时,能够及时进行恢复操作也非常关键。
# 使用Django的dumpdata和loaddata命令进行数据库备份和恢复
# 备份数据库
python manage.py dumpdata > backup.json
# 恢复数据库
python manage.py loaddata backup.json
13. 异步任务
在处理大量数据或者需要执行耗时操作时,将部分任务异步化可以提高应用的响应速度和性能。Django提供了Celery等工具来管理异步任务。
# 定义异步任务
# tasks.py
from celery import shared_task
@shared_task
def process_data(data):
# 处理数据的耗时操作
pass
# 调用异步任务
from .tasks import process_data
data = ... # 要处理的数据
process_data.delay(data)
14. 数据库分片
当单一数据库无法满足大规模数据存储和查询的需求时,可以考虑使用数据库分片技术,将数据分布到多个数据库节点上,以提高数据库的并发能力和性能。
# 使用Django的数据库路由功能进行数据库分片
# routers.py
class MyRouter:
def db_for_read(self, model, **hints):
# 返回要读取的数据库
pass
def db_for_write(self, model, **hints):
# 返回要写入的数据库
pass
# 在settings.py中配置数据库路由
DATABASE_ROUTERS = ['myapp.routers.MyRouter']
15. 使用缓存服务
除了Django内置的缓存机制外,还可以使用专门的缓存服务如Redis来提高数据访问速度和降低数据库负载。Redis支持更复杂的数据结构和操作,能够更灵活地应对各种场景。
# 使用Redis作为缓存服务
# settings.py
CACHES = {
'default': {
'BACKEND': 'django_redis.cache.RedisCache',
'LOCATION': 'redis://localhost:6379/1',
'OPTIONS': {
'CLIENT_CLASS': 'django_redis.client.DefaultClient',
}
}
}
数据库连接管理
在高负载环境下,每个请求都创建和销毁数据库连接可能会导致性能问题。为了更有效地管理数据库连接,可以考虑使用连接池。连接池可以在应用程序启动时创建一组数据库连接,并在需要时将连接提供给请求。这样可以减少连接创建和销毁的开销,提高数据库访问效率。
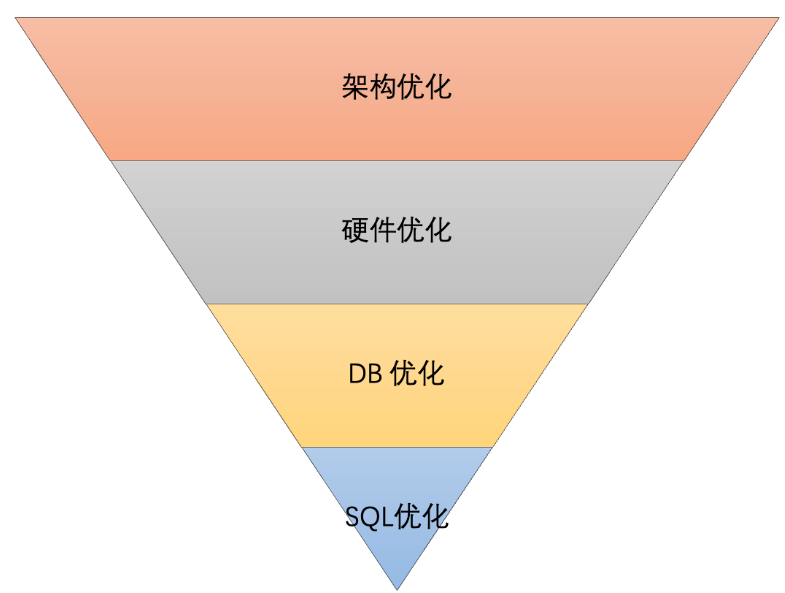
SQL优化
除了使用ORM进行数据操作外,有时直接执行SQL语句可能更高效。但是,在执行原生SQL语句时需要注意防止SQL注入攻击。另外,合理地优化SQL查询语句也可以提高数据库查询效率,例如使用索引、优化查询语句结构等方式。
定时任务
后台任务通常会对数据库性能产生影响,特别是在执行大量数据操作时。为了避免影响正常请求的处理,可以考虑使用异步任务,并将这些任务调度到非高峰时段执行。这样可以降低对数据库的负载,提高系统的稳定性和性能。
数据库备份与恢复
定期进行数据库备份是保障数据安全的重要手段之一。通过定期备份数据库,可以在数据丢失或损坏时快速恢复数据,保障系统的正常运行。同时,备份数据库也是系统迁移和数据迁移的重要准备工作之一。
结语
数据库优化和ORM性能调优是提升Django应用程序性能和稳定性的关键步骤。通过合理地管理数据库连接、优化SQL查询、使用异步任务以及定期进行数据库备份与恢复等方法,可以有效地提高系统的响应速度、降低数据库负载、保障数据安全,从而提升用户体验和系统可靠性。
在实际应用中,开发者需要根据应用的特点和需求,选择合适的优化策略,并持续关注系统性能指标,及时调整和优化系统。通过不断地优化数据库和ORM性能,可以使Django应用程序在面对日益复杂的业务需求和高并发访问时依然保持高效稳定的运行状态,为用户提供更好的服务体验。