Compact 3D Gaussian Splatting For Dense Visual SLAM
用于密集视觉冲击的紧凑三维高斯散射
Abstract 摘要 Compact 3D Gaussian Splatting For Dense Visual SLAM
Recent work has shown that 3D Gaussian-based SLAM enables high-quality reconstruction, accurate pose estimation, and real-time rendering of scenes. However, these approaches are built on a tremendous number of redundant 3D Gaussian ellipsoids, leading to high memory and storage costs, and slow training speed. To address the limitation, we propose a compact 3D Gaussian Splatting SLAM system that reduces the number and the parameter size of Gaussian ellipsoids. A sliding window-based masking strategy is first proposed to reduce the redundant ellipsoids. Then we observe that the covariance matrix (geometry) of most 3D Gaussian ellipsoids are extremely similar, which motivates a novel geometry codebook to compress 3D Gaussian geometric attributes, i.e., the parameters. Robust and accurate pose estimation is achieved by a global bundle adjustment method with reprojection loss. Extensive experiments demonstrate that our method achieves faster training and rendering speed while maintaining the state-of-the-art (SOTA) quality of the scene representation.
最近的工作表明,基于3D高斯的SLAM能够实现场景的高质量重建、精确姿态估计和实时渲染。然而,这些方法都是建立在大量冗余的3D高斯椭球体上,导致内存和存储成本高,训练速度慢。为了解决这个问题,我们提出了一个紧凑的三维高斯溅射SLAM系统,减少了高斯椭球的数量和参数大小。首先提出了一种基于滑动窗口的掩模策略来减少冗余椭球。然后,我们观察到大多数3D高斯椭球的协方差矩阵(几何形状)非常相似,这促使一种新的几何码本来压缩3D高斯几何属性,即,参数。鲁棒性和准确的姿态估计是通过一个全球光束法平差方法与重投影损失。 大量的实验表明,我们的方法实现了更快的训练和渲染速度,同时保持了最先进的(SOTA)质量的场景表示。

Figure 1:Our framework minimizes storage and accelerates rendering while maintaining the SOTA image reconstruction performance. The proposed framework eliminates unnecessary 3D Gaussian ellipsoids without affecting performance. We highlight and enlarge some areas to show the significant reduction of 3D Gaussian points.
图1:我们的框架最大限度地减少了存储并加速了渲染,同时保持了SOTA图像重建性能。所提出的框架消除了不必要的三维高斯椭球,而不影响性能。我们突出显示并放大了一些区域,以显示3D高斯点的显着减少。
1Introduction 1介绍
Simultaneous localization and mapping (SLAM) has been a fundamental computer vision problem with wide applications such as autonomous driving, robotics, and virtual/augmented reality [7, 28]. Several traditional methods, including ORBSLAM [24, 25], VINS [27], etc. [6, 37, 38], have been introduced over the years, representing scenes with sparse point cloud maps. However, due to the sparse nature of the point cloud, it proves ineffective for navigation or other purposes. Attention has turned to dense scene reconstruction, exemplified by DTAM [26], Kintinuous [35], and ElasticFusion [36]. However, their accuracy remains unsatisfactory due to high memory costs, slow processing speeds, and other real-time running limitations.
同时定位和映射(SLAM)一直是一个基本的计算机视觉问题,具有广泛的应用,如自动驾驶,机器人和虚拟/增强现实[ 7,28]。几种传统的方法,包括ORBSLAM [ 24,25],VINS [ 27]等[ 6,37,38],多年来已经引入,用稀疏点云图表示场景。然而,由于点云的稀疏性,它被证明对于导航或其他目的是无效的。注意力已经转向密集场景重建,例如DTAM [ 26],Kintinuous [ 35]和ElasticFusion [ 36]。然而,由于内存成本高、处理速度慢和其他实时运行限制,它们的精度仍然不令人满意。
Nowadays, with the proposal of Neural Radiance Fields (NeRF) [22], there are many following works on different areas [4]. Many works focus on combining implicit scene representation with SLAM systems. iMAP [32] is the first method to use a single MLP to represent the scene. NICE-SLAM [45], ESLAM [11], Co-SLAM [34], and PLGSLAM [5] further improve the scene representation with the hybrid feature grids, axis-aligned feature planes, joint coordinate-parametric encoding, and progressive scene representation. To further improve the accuracy of rendering, recent methods have started to explore 3D Gaussian Splatting(GS) [13] integration with SLAM, such as SplaTAM [12], GS-SLAM [39], etc [42, 21]. GS-based SLAM methods leverage a point-based representation associated with 3D Gaussian attributes and adopt the rasterization pipeline to render the images, achieving fast rendering speed and promising image quality. However, the original GS-based scene representation entails a substantial number of 3D Gaussian ellipsoids to maintain high-fidelity reconstruction, leading to high memory usage and storage requirements. GS-based SLAM systems usually need more than 500MB to represent a small room-sized scene. Moreover, the running speed of GS-based SLAM systems is significantly slower than NeRF-based methods, which hinders practical deployment, especially on resource-constrained devices.
如今,随着神经辐射场(NeRF)的提出[ 22],在不同领域有许多以下工作[ 4]。许多工作集中于将隐式场景表示与SLAM系统相结合。iMAP [ 32]是第一种使用单个MLP来表示场景的方法。NICE-SLAM [ 45],ESLAM [ 11],Co-SLAM [ 34]和PLGSLAM [ 5]进一步改进了混合特征网格,轴对齐特征平面,联合坐标参数编码和渐进式场景表示的场景表示。为了进一步提高渲染的准确性,最近的方法已经开始探索3D高斯溅射(GS)[ 13]与SLAM的集成,例如SplaTAM [ 12],GS-SLAM [ 39]等[ 42,21]。基于高斯的SLAM方法利用与3D高斯属性相关联的基于点的表示,并采用光栅化流水线来渲染图像,从而实现快速的渲染速度和有希望的图像质量。 然而,原始的基于GS的场景表示需要大量的3D高斯椭球来保持高保真度重建,从而导致高的内存使用和存储要求。基于GS的SLAM系统通常需要超过500MB来表示一个小房间大小的场景。此外,基于GS的SLAM系统的运行速度明显慢于基于NeRF的方法,这阻碍了实际部署,特别是在资源受限的设备上。
To this end, we propose a compact 3D Gaussian scene representation method to address the critical high memory demand and slow training speed issue in GS-based SLAM systems. Our method notably enhances storage efficiency while delivering high-quality reconstruction, fast training speed, and real-time rendering capabilities. First, we design a novel sliding window-based online masking method to remove the millions of redundant and unnecessary 3D Gaussian ellipsoids created during the SLAM system operation. With the proposed masking method, a compact 3D Gaussian scene representation is learned, achieving faster rendering speed and efficient memory usage since the computational complexity is linearly proportional to the number of 3D Gaussian points.
为此,我们提出了一种紧凑的三维高斯场景表示方法,以解决关键的高内存需求和低训练速度的问题,在基于GS的SLAM系统。我们的方法显着提高了存储效率,同时提供高质量的重建,快速的训练速度和实时渲染能力。首先,我们设计了一种新的基于滑动窗口的在线掩模方法来去除SLAM系统操作过程中产生的数百万个冗余和不必要的3D高斯椭球。使用所提出的掩模方法,一个紧凑的3D高斯场景表示的学习,实现更快的渲染速度和有效的内存使用,因为计算复杂度是线性比例的3D高斯点的数量。
Second, we observe that the majority of Gaussian points exhibit similar geometry information in scale and rotation attributes. To this end, a codebook-based method is designed to compress the geometry of each Gaussian point. It learns to find the similarities and geometry shared across the scene. We only store the codebook index for each 3D Gaussian ellipsoid, obtaining compact scene representation.
其次,我们观察到大多数高斯点在尺度和旋转属性方面表现出相似的几何信息。为此,设计了一种基于码本的方法来压缩每个高斯点的几何形状。它学习查找场景中共享的相似性和几何体。我们只存储每个3D高斯椭球的码本索引,获得紧凑的场景表示。
Third, the camera tracking accuracy of GS-based SLAM is relatively low compared with other SLAM systems. A global BA method with reprojection loss is proposed to achieve robust and accurate pose estimation. Our method maintains a global keyframe database and performs bundle adjustment with all the historical observations, which can effectively eliminate the cumulative error. Overall, our contributions are shown as follows:
第三,与其他SLAM系统相比,基于GS的SLAM的相机跟踪精度相对较低。提出了一种具有重投影损失的全局BA方法,以实现鲁棒和精确的位姿估计。该方法维护全局关键帧数据库,并与所有历史观测值进行捆绑平差,可以有效消除累积误差。总体而言,我们的贡献如下:
- •
We propose a novel GS-based SLAM system with compact Gaussian scene representation, achieving fast training and rendering speed, accurate pose estimation, and significantly enhancing storage efficiency.
·我们提出了一种新的基于高斯的SLAM系统,具有紧凑的高斯场景表示,实现了快速的训练和渲染速度,准确的姿态估计,并显着提高存储效率。 - •
A novel sliding window-based online masking method is proposed to remove the number of redundant Gaussian ellipsoids while achieving high-fidelity performance during training.
·提出了一种新的基于滑动窗口的在线掩蔽方法,以去除冗余高斯椭球的数量,同时在训练期间实现高保真性能。 - •
We observe and analyze the geometry similarities of 3D Gaussian ellipsoids and propose a codebook-based method to efficiently restore the geometry of each Gaussian point during the SLAM system operation. A keyframe-based global BA method with reprojection loss is proposed to improve the relative low performance of camera tracking.
·我们观察和分析了3D高斯椭球的几何相似性,并提出了一种基于码本的方法,以有效地恢复SLAM系统操作期间每个高斯点的几何形状。针对摄像机跟踪性能相对较低的问题,提出了一种基于关键帧的重投影损失全局BA方法。 - •
We conduct comprehensive experiments on different datasets and achieve nearly 176% increase in rendering speed and over 1.97× compression on memory usage.
·我们在不同的数据集上进行了全面的实验,实现了渲染速度提高近176%,内存使用量压缩超过1.97 × 。
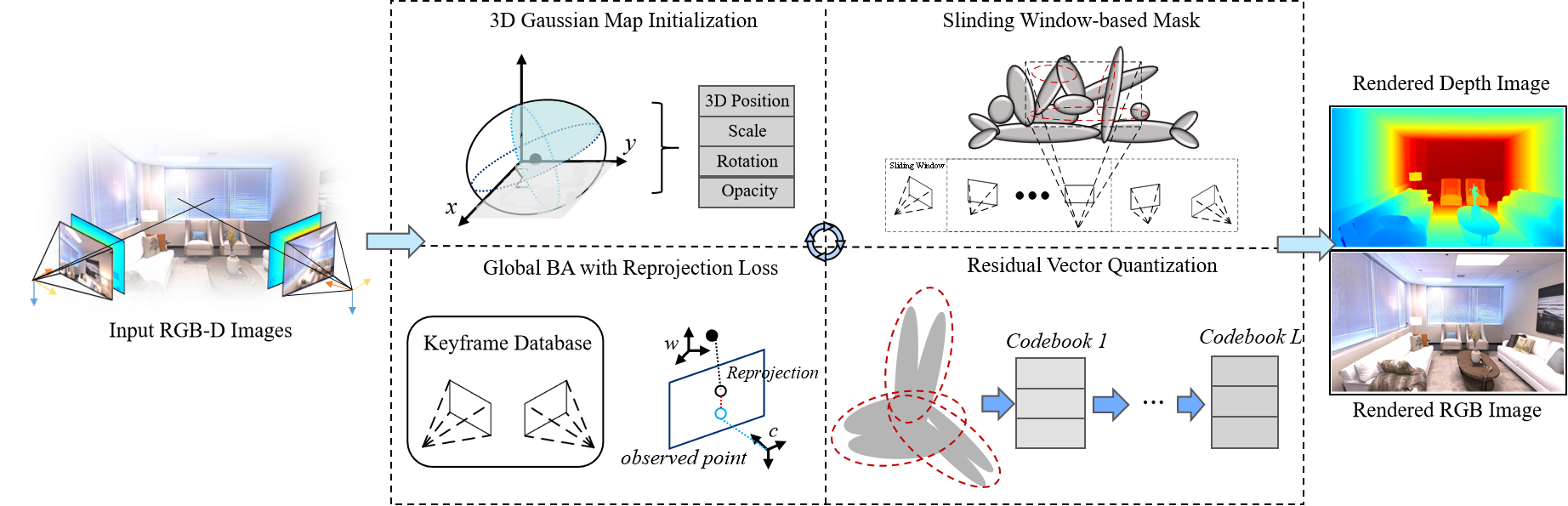
Figure 2:The pipeline of our GS-based SLAM system. The input of our system is the current RGB-D frame. We start the SLAM system by initializing the 3D Gaussian map construct. Then, we update our 3D Gaussian map by adding new Gaussians and using the learnable mask to reduce the redundant 3D Gaussian ellipsoids. We incorporate a codebook-based vector quantization method to compress the scene representation. For camera tracking, we maintain a global keyframe database for global BA and use reprojection loss for robust pose estimation.
图2:我们基于GS的SLAM系统的流水线。我们的系统的输入是当前的RGB-D帧。我们通过初始化3D高斯地图构造来启动SLAM系统。然后,我们通过添加新的高斯和使用可学习的掩模来减少冗余的3D高斯椭球来更新我们的3D高斯映射。我们采用基于码本的矢量量化方法来压缩场景表示。对于相机跟踪,我们维护全局BA的全局关键帧数据库,并使用重投影损失进行鲁棒姿态估计。
2Related Work 2相关工作
Dense Visual SLAM and Localization. SLAM [2, 19] and localization [20] has become an active field for the past two decades. DTAM [26] is the first method to achieve dense scene reconstruction. Kinectfusion [10] uses projective iterative-closet-point (ICP) for camera tracking. Some learning-based methods integrate traditional geometry frameworks with deep learning networks for accurate camera tracking and mapping, such as DROID-SLAM [33].
密集视觉SLAM和定位。SLAM [ 2,19]和本地化[ 20]在过去的二十年中已经成为一个活跃的领域。DTAM [ 26]是实现密集场景重建的第一种方法。Kinectfusion [ 10]使用投影迭代最近点(ICP)进行摄像机跟踪。一些基于学习的方法将传统的几何框架与深度学习网络相结合,以实现准确的相机跟踪和映射,例如DROID-SLAM [ 33]。
NeRF-based SLAM. With the proposal of Neural radiance fields (NeRF) [22], many researchers explore taking advantage of the implicit method into SLAM systems. iMAP [32] is the first method to use a single multi-layer perceptron (MLP) to represent the scene, and NICE-SLAM [45]uses learnable hierarchical feature grids. Vox-Fusion [40] employs octree architecture for dynamic map scalability. ESLAM [11] and Co-SLAM [34] further improve the scene representation with tri-planes and joint coordinate-parametric encoding. [44, 18, 17] use semantic feature embedding to improve scene representation. Point-SLAM [29] uses neural point clouds for the scene representation. Instead of representing maps with neural implicit features, our method utilizes the explicit 3D Gaussian representation, which can significantly improve the rendering speed using splatting-based rasterization.
基于NeRF的SLAM随着神经辐射场(NeRF)[ 22]的提出,许多研究人员探索将隐式方法用于SLAM系统。iMAP [ 32]是第一种使用单个多层感知器(MLP)来表示场景的方法,NICE-SLAM [ 45]使用可学习的分层特征网格。Vox-Fusion [ 40]采用八叉树架构实现动态地图可扩展性。ESLAM [ 11]和Co-SLAM [ 34]进一步改进了具有三平面和联合坐标参数编码的场景表示。[ 44,18,17]使用语义特征嵌入来改进场景表示。Point-SLAM [ 29]使用神经点云进行场景表示。我们的方法不是用神经隐式特征表示地图,而是利用显式3D高斯表示,这可以显着提高基于splatting的光栅化的渲染速度。
GS-based SLAM. Recently, 3D Gaussian Splatting (3DGS) [13] using 3D Gaussians as primitives for real-time neural rendering. 3DGS utilizes highly optimized custom CUDA kernels and novel algorithmic approaches, which achieve significant improvements in rendering speed without sacrificing image quality. SplaTAM [12], GS-SLAM [39], Gaussian-SLAM [42], Gaussian Splatting SLAM [21] are the pioneer works that successfully combine the advantages of 3D Gaussian Splatting with SLAM. These methods achieve fast rendering speed and high-fidelity reconstruction performance. However, the training speed is relatively slow, which is crucial for SLAM as it is an online operation system. Memory and storage usage are also heavy, which makes them difficult to use in real-world scenarios and with handheld devices.
基于GS的SLAM。最近,3D高斯溅射(3DGS)[ 13]使用3D高斯作为实时神经渲染的基元。3DGS利用高度优化的自定义CUDA内核和新颖的算法方法,在不牺牲图像质量的情况下显著提高了渲染速度。SplaTAM [ 12],GS-SLAM [ 39],Gaussian-SLAM [ 42],Gaussian Splatting SLAM [ 21]是成功联合收割机3D Gaussian Splatting与SLAM优点的先驱作品。这些方法实现了快速的绘制速度和高保真的重建性能。然而,训练速度相对较慢,这对于SLAM来说至关重要,因为它是一个在线操作系统。内存和存储使用量也很大,这使得它们难以在现实世界中使用,也难以与手持设备一起使用。
3Method 3方法
The pipeline of our system is shown in Fig. 2. The input of our system is sequential RGB-D frames {��,��}�=1� with known camera intrinsic �∈�3×3. Our system simultaneously reconstructs a dense scene map and estimates camera poses {��|��}�=1�. For the mapping thread, a compact 3D Gaussian scene representation (Sec. 3.1) is designed to represent the environments with sliding window-based masks (Sec. 3.2) and geometry codebook (Sec. 3.3). For the camera tracking thread, a global bundle adjustment method (Sec. 3.4) is designed for robust and accurate pose estimation. The network is incrementally updated with the SLAM system operation.
我们系统的流水线如图2所示。我们的系统的输入是具有已知相机固有 �∈�3×3 的顺序RGB-D帧 {��,��}�=1� 。我们的系统同时重建了一个密集的场景地图,并估计相机姿势 {��|��}�=1� 。对于映射线程,使用紧凑的3D高斯场景表示(Sec. 3.1)被设计为用基于滑动窗口的掩模来表示环境(Sec. 3.2)和几何码本(Sec. 3.3)。对于摄像机跟踪线程,全局光束法平差方法(Sec. 3.4)是专为鲁棒和准确的姿态估计。网络随着SLAM系统操作而递增地更新。
3.13D Gaussian Scene Representation
3.13D高斯场景表示
Inspired by [13], We represent the entire scene as a set of 3D Gaussian ellipsoids. Each 3D Gaussian is associated with 3D attributes (positions, opacity, scale, and rotation). Our Gaussian ellipsoids are defined by a full 3D covariance matrix 𝚺 defined in world space (normalized):
受[ 13]的启发,我们将整个场景表示为一组3D高斯椭球。每个3D高斯都与3D属性(位置、不透明度、缩放和旋转)相关联。我们的高斯椭圆由在世界空间中定义的全3D协方差矩阵 𝚺 定义(归一化):
| �(𝐱)=��−12(�)�𝚺−1(�),𝚺=𝑹𝑺𝑺𝑻𝑹𝑻 | (1) |
where �∈[0,1] is the opacity value. 𝑺 is the scaling matrix, and 𝑹 is the rotation matrix.
其中 �∈[0,1] 是不透明度值。 𝑺 是缩放矩阵, 𝑹 是旋转矩阵。
Then we use the 3D Gaussian ellipsoids to render 2D images with the technique of splatting [14, 41]. Then we can formulate the covariance matrix 𝚺′ in camera coordinates:
然后,我们使用3D高斯椭球体来渲染2D图像与飞溅技术[14,41]。然后,我们可以在相机坐标中公式化协方差矩阵 𝚺′ :
| 𝚺′=𝑱𝑾𝚺𝑾�𝑱� | (2) |
where 𝑾 denotes the view direction, 𝑱 denotes the projection transformation matrix. For each pixel �, the color and opacity of all Gaussian ellipsoids are computed and blended using this formula:
其中, 𝑾 表示观看方向, 𝑱 表示投影变换矩阵。对于每个像素 � ,使用以下公式计算并混合所有高斯椭圆的颜色和不透明度:
| �(�)=∑�∈�𝒄𝒊��(�)∏�=1�−1(1−��(�)) | (3) |
where �� denotes the color of Gaussian ellipsoids. We also propose a similar depth rendering formula:
其中 �� 表示高斯椭圆的颜色。我们还提出了一个类似的深度渲染公式:
| �(�)=∑�=1�����(𝐩)∏�=1�−1(1−��(�)) | (4) |
We also render a silhouette image to determine visibility:
我们还渲染了一个剪影图像来确定可见性:
| �(�)=∑�=1���(�)∏�=1�−1(1−��(�)) | (5) |

Figure 3:The left figure shows the learnable mask strategy. We perform frustum selection and sliding widow reset to remove redundant Gaussian ellipsoids while maintaining the reconstruction accuracy efficiently. The dashed lines represent the removed 3D Gaussian ellipsoids. The right figure shows the varying count of Gaussian ellipsoids during the SLAM system operation. These two curves show the distinction between our system with and without masks. Our mask strategy achieves 1.97 × compression on the number of 3D Gaussians.
图3:左图显示了可学习的掩码策略。我们执行截头体选择和滑动窗口重置,以去除冗余的高斯椭球,同时保持重建精度有效。虚线表示移除的3D高斯椭圆。右图示出了在SLAM系统操作期间高斯椭圆的变化计数。这两条曲线显示了我们的系统在有掩模和没有掩模的情况下的区别。我们的掩模策略在3D高斯的数量上实现了1.97 × 压缩。
3.2Sliding Window-based Mask
3.2基于滑动窗口的掩码
The existing GS-based SLAM systems, such as SplaTAM [12] and GS-SLAM [39], directly use the original 3DGS for scene representation, achieving promising image quality. However, we observe that the 3DGS creates a number of redundant 3D Gaussian ellipsoids with the SLAM system operation(×1.52 Gaussian ellipsoids show similar performance in Fig. 3), while both of them fail to discover this. This finally results in poor performance in training speed, memory, and storage usage, which is crucial for online SLAM systems. Some methods [16, 23, 9] propose novel Gaussian pruning and self-organizing methods to compact the 3DGS attributes. However, all of these strategies are not suitable for GS-based SLAM systems as they have to obtain all the images, pose, and the corresponding point cloud at the beginning, while SLAM systems are incrementally optimized.
现有的基于GS的SLAM系统,如SplaTAM [ 12]和GS-SLAM [ 39],直接使用原始3DGS进行场景表示,实现了有希望的图像质量。然而,我们观察到,3DGS利用SLAM系统操作创建了多个冗余的3D高斯椭圆(图3中的 × 1.52高斯椭圆示出了类似的性能),而它们两者都未能发现这一点。这最终导致训练速度、内存和存储使用方面的性能低下,而这对于在线SLAM系统至关重要。一些方法[ 16,23,9]提出了新的高斯修剪和自组织方法来压缩3DGS属性。然而,所有这些策略都不适合于基于GS的SLAM系统,因为它们必须在开始时获得所有图像、姿态和对应的点云,而SLAM系统是增量优化的。
To this end, we propose a learnable sliding window-based mask strategy to remove the redundant 3D Gaussian ellipsoids with the SLAM system operation. Compared to the original densification method, which only considers the opacity, our method takes into account both the volume � and opacity �∈[0,1] of Gaussian ellipsoids. The volume calculation is �=43����, where ��� are the three dimensions of the scale 𝑺. We introduce a learnable mask parameter �∈�� and a corresponding binary mask �∈{0,1}�, � is the number of Gaussian ellipsoids.
为此,我们提出了一个可学习的滑动窗口为基础的掩模策略,以消除冗余的三维高斯椭球的SLAM系统操作。与只考虑不透明度的原始致密化方法相比,我们的方法同时考虑了高斯椭球的体积 � 和不透明度 �∈[0,1] 。体积计算是 �=43���� ,其中 ��� 是刻度 𝑺 的三维。我们引入了一个可学习的掩码参数 �∈�� 和一个相应的二进制掩码 �∈{0,1}� , � 是高斯椭球的数量。
| ��=sg(𝕀[���(��)>�]−���(��))+���(��) | (6) | ||
| 𝑺𝒏^=��𝑺𝒏,��^=���� | (7) |
where � is the index of the Gaussian ellipsoids, � denotes the mask threshold. Inspired by [1], we employ the stop gradient operator ��(⋅) to calculate gradients from binary masks. 𝕀 and ���(⋅) denote the indicator and sigmoid function. This formulation of mask strategy allows us to effectively combine the influence of volume and opacity of Gaussian ellipsoids. We formulate the loss function �� of our mask:
其中 � 是高斯椭圆的索引, � 表示掩码阈值。受[ 1]的启发,我们采用停止梯度算子 ��(⋅) 来计算二进制掩码的梯度。 𝕀 和 ���(⋅) 表示指示符和sigmoid函数。这种掩模策略的制定使我们能够有效地联合收割机的体积和不透明度的高斯椭球的影响。我们用公式表示掩码的损失函数 �� :
| ��=1�∑�=1����(��) | (8) |
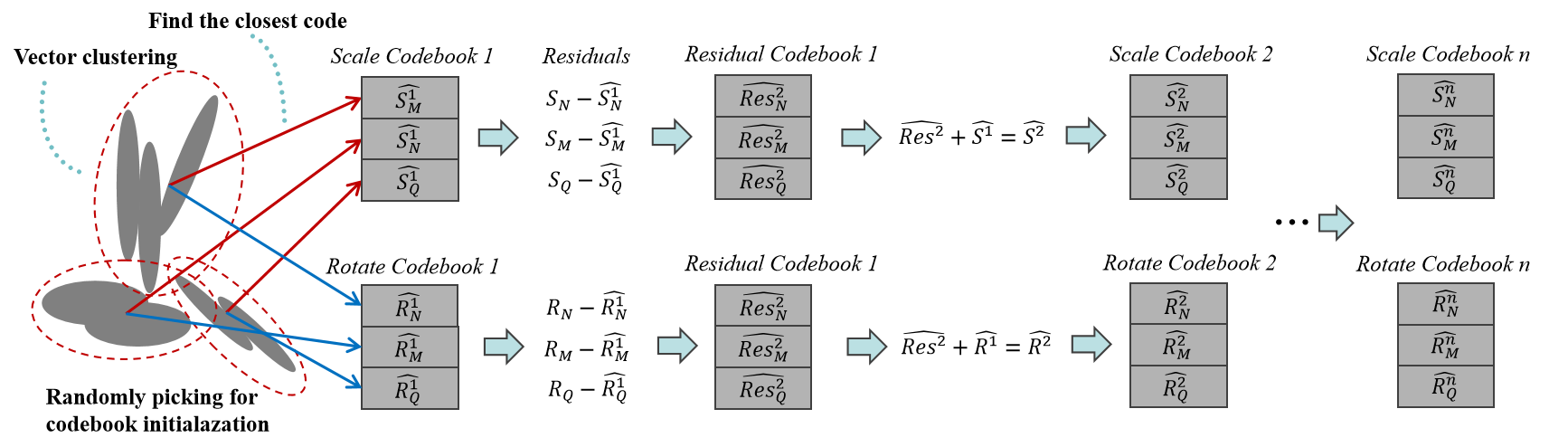
Figure 4:The R-VQ process to represent the scale and rotation of Gaussian ellipsoids. In the first stage, we cluster the scale and rotation vectors and randomly select codebook initialization with the closest code. In the subsequent stage, the residual between the original vector and the result from the first stage is stored in another codebook. This iterative process continues through to the ultimate stage, at which point, the collectively chosen indices and codebook from each stage provide a representation of the original vector.
图4:R-VQ过程表示高斯椭球的尺度和旋转。在第一阶段,我们聚类的尺度和旋转矢量和随机选择码本初始化与最接近的代码。在随后的阶段中,原始矢量和来自第一阶段的结果之间的残差被存储在另一个码本中。该迭代过程继续到最终阶段,此时,来自每个阶段的共同选择的索引和码本提供原始向量的表示。
In order to better fit the online updating SLAM systems, we further improve the masking strategy by adding frustum culling and sliding window-based reset strategy, shown in Fig. 3. Our frustum culling strategy allows us to optimize only the mask within the current viewing frustum while keeping the rest of the 3D Gaussian ellipsoids fixed. It will not only preserve the previously reconstructed geometry but also significantly reduce the number of parameters during optimization. Different from the original densification strategy performed on every frame, we only perform mask on the keyframe (each ��ℎ frame) for efficiency and accuracy. We maintain a local sliding window and perform sliding window reset to avoid the continuous optimization and accumulated gradient of masks which will ultimately eliminate all Gaussian ellipsoids. The sliding window consists of the current frame, the most relevant keyframe, and �−2 previous keyframes, which have the highest overlap with the current frame. Overlap is evaluated by analyzing the point cloud of the current frame’s depth map and tallying points within the frustum of each keyframe. This can also ensure the consistency of the mask within the local sliding window. This approach allows us to continuously mask out unnecessary Gaussians during online SLAM system operation, effectively reducing computation overhead and ensuring efficient memory usage on GPU.
为了更好地适应在线更新的SLAM系统,我们通过添加截头体剔除和基于滑动窗口的重置策略来进一步改进掩蔽策略,如图3所示。我们的截头体剔除策略允许我们仅优化当前视锥体内的掩模,同时保持3D高斯椭球体的其余部分固定。它不仅保留了以前重建的几何形状,而且大大减少了优化过程中的参数数量。与原始的对每帧执行的致密化策略不同,为了效率和准确性,我们只对关键帧(每个 ��ℎ 帧)执行掩模。我们保持一个局部滑动窗口,并执行滑动窗口重置,以避免不断优化和累积梯度的面具,最终消除所有高斯椭球。滑动窗口由当前帧、最相关的关键帧和与当前帧重叠最多的 �−2 先前关键帧组成。 通过分析当前帧的深度图的点云并计算每个关键帧的截头锥体内的点来评估重叠。这也可以确保局部滑动窗口内的掩码的一致性。这种方法允许我们在在线SLAM系统操作期间不断屏蔽不必要的高斯,有效地减少计算开销并确保GPU上的高效内存使用。

Figure 5:The KL divergence distribution of the Gaussian ellipsoids with the online training of the SLAM system on different time steps (500, 1000, 1500, 2000). We can observe that the similarity in geometry consistently remains at a high level of GS-based SLAM system.
图5:在不同时间步长(500,1000,1500,2000)上,SLAM系统在线训练的高斯椭球的KL发散分布。我们可以观察到,几何形状的相似性始终保持在基于GS的SLAM系统的高水平。
3.3Geometry Codebook 3.3几何代码手册
In this section, we analyze and observe the geometry similarities of the Gaussian ellipsoids created by SLAM systems. Then, we propose a learnable codebook and employ a residual vector quantization method to reduce computational complexity and memory usage and further improve the training and rendering speed.
在本节中,我们分析和观察由SLAM系统创建的高斯椭球的几何相似性。然后,我们提出了一个可学习的码书,并采用残差矢量量化方法,以减少计算复杂度和内存的使用,进一步提高训练和渲染速度。
For the GS-based SLAM system, a scene is composed of a number of small Gaussian ellipsoids with 3D geometry attributes (scale and rotation matrix 𝑺,𝑹). Consider that the 3D Gaussian ellipsoids �1,�2 conform to an unbiased Gaussian distribution 𝒩(0,𝚺1),𝒩(0,𝚺2), we adopt the Kullback-Leibler divergence [15] to analysis the geometry similarities of 3D Gaussian ellipsoids:
对于基于GS的SLAM系统,场景由具有3D几何属性(缩放和旋转矩阵 𝑺,𝑹 )的多个小的高斯椭圆体组成。考虑到3D高斯椭球 �1 、 �2 符合无偏高斯分布 𝒩(0,𝚺1),𝒩(0,𝚺2) ,我们采用Kullback-Leibler散度[ 15]来分析3D高斯椭球的几何相似性:
| ���=12���(𝚺1−1𝚺2)−12+12������(𝚺1−1𝚺2) | (9) |
where � is the dimension of the covariance matrix. We conduct extensive experiments and present our results on Tab. 1 and Fig. 5. We can see that the percentage of 3D Gaussian ellipsoids is significantly elevated in a small range of KL divergence, which demonstrates the similarities of the 3D Gaussian ellipsoids shared across the scene. Our experiments also show that the similarities of 3D Gaussians of the GS-based SLAM system are greater than the original 3DGS. This is probably due to the online optimization strategy that the SLAM system only uses the current frame and history keyframes to optimize the 3D Gaussian attributes, which will exacerbate the geometry similarity. Based on the similarity, we propose a learnable codebook to compress the geometry attributes (scale and rotation), shown in Fig. 4. Inspired by SoundStream [43] and Encodec [8], we incorporate the residual vector quantization (R-VQ) to compress the scale and rotation. It cascades L stages of VQ and is formulated as follows:
其中 � 是协方差矩阵的维度。我们进行了广泛的实验,并提出了我们的结果在Tab。1和图5。我们可以看到,3D高斯椭球的百分比在KL发散的小范围内显著升高,这证明了场景中共享的3D高斯椭球的相似性。我们的实验还表明,基于GS的SLAM系统的三维高斯的相似性大于原始的3DGS。这可能是由于SLAM系统仅使用当前帧和历史关键帧来优化3D高斯属性的在线优化策略,这将加剧几何相似性。基于相似性,我们提出了一个可学习的码本来压缩几何属性(缩放和旋转),如图4所示。受SoundStream [ 43]和Encodec [ 8]的启发,我们结合了残差矢量量化(R-VQ)来压缩缩放和旋转。 它级联VQ的L级,公式如下:
| �^�� | =∑�=1�𝒞�[��],�∈{1,…,�}, | (10) | ||
| ��� | =argmin𝑘‖𝒞�[�]−(��−�^��−1)‖22,�^�0=0→ |
where �∈ℛ�×4 is the scale vector, �^�∈ℛ�×4 is the output scale vector after � stages quantization. � denotes the index of the Gaussian ellipsoids. 𝒞� denotes the codebook at the stage l. 𝒞� represents the vector at index i of the codebook 𝒞. The formulation of the rotation vector is the same. Then, the loss function is defined as:
其中, �∈ℛ�×4 是尺度矢量, �^�∈ℛ�×4 是经过 � 级量化后的输出尺度矢量。 � 表示高斯椭球的索引。 𝒞� 表示在阶段l的码本。 𝒞� 表示码本 𝒞 的索引i处的向量。旋转矢量的公式是相同的。然后,损失函数被定义为:
| ��=1��∑�=1�∑�=1�‖sg[��−�^��−1]−𝒞�[���]‖22 | (11) |
where � is the size of codebook, ��[⋅] is the stop gradient operator. After this, we can only store the codebook compressed scale and rotation vector, which can significantly reduce storage and memory usage.
其中 � 是码本的大小, ��[⋅] 是停止梯度算子。在此之后,我们可以只存储码本压缩的尺度和旋转向量,这可以大大减少存储和内存使用。
Table 1:The KL divergence analysis of GS-based SLAM and original 3DGS.
表1:基于GS的SLAM和原始3DGS的KL发散分析。
| SplaTAM [12] | 3DGS [13] | ||
|---|---|---|---|
| Range | Percentage | Range | Percentage |
| (-2.5%,2.5%) | 87.67% | (-2.5%,2.5%) | 20.07% |
| (-5.0%,5.0%) | 97.86% | (-5.0%,5.0%) | 37.04% |
| (-7.5%,7.5%) | 99.16% | (-7.5%,7.5%) | 47.69% |
| (-10.0%,10.0%) | 99.52% | (-10.0%,10.0%) | 52.16% |
3.4Tracking and Global Bundle Adjustment
3.4跟踪和全局光束平差
Our tracking and bundle adjustment are performed via minimizing our objective functions. The camera pose is initialized for a new time step by a constant velocity forward projection of the pose parameters. The color and depth loss is defined as:
我们的跟踪和光束调整是通过最小化我们的目标函数来执行的。通过姿态参数的恒定速度前向投影,针对新的时间步长初始化相机姿态。颜色和深度损失定义为:
| ℒ�=1�∑�=1�(𝐂^�−𝐂𝐢)2,ℒ�=1|��|∑�∈��(𝐃𝐢^−𝐃𝐢)2 | (12) |
where �� is the set of rays that have a valid depth observation. The reprojection error is common in traditional SLAM methods based on sparse point clouds [25]. Since 3D Gaussian is also based on a point cloud representation, we introduce this loss for the first time to improve the scene’s geometric representation and consistency further. We formulate reprojection errors with SIFT features:
其中 �� 是具有有效深度观测的射线集合。重投影误差在基于稀疏点云的传统SLAM方法中很常见[ 25]。由于3D高斯也是基于点云表示的,我们首次引入这种损失,以进一步提高场景的几何表示和一致性。我们用SIFT特征公式化重投影误差:
| ℒ��=∑�=1�‖(��′,��′)−Π(��→�′��+��→�′)‖ | (13) |
where Π(��→�′��+��→�′) represents the reprojection of 3D point �� to the corresponding pixel (��′,��′) in image �′. The tracking loss is formulated as follows:
其中 Π(��→�′��+��→�′) 表示3D点 �� 到图像 �′ 中的对应像素 (��′,��′) 的再投影。跟踪损失公式如下:
| �t=∑𝐩(�(𝐩)>0.99)(ℒ�+�1ℒ�+�2ℒ��) | (14) |
We use the rendered visibility silhouette to select the well-optimized pixels for camera tracking, which can improve the tracking accuracy for the new frames.
我们使用渲染的可见性轮廓来选择用于相机跟踪的优化像素,这可以提高新帧的跟踪精度。
Global Bundle Adjustment. For global consistency and accuracy, our system maintains a significantly larger global keyframe database than other GS-based SLAM systems. We randomly sample a total number of N rays from our global keyframe database to optimize our scene representation as well as camera poses. This phase optimizes a loss similar to tracking loss, and we also add an SSIM loss to RGB rendering. The global bundle adjustment is performed to optimize the scene representation with the camera pose. Our global BA method can effectively reduce cumulative errors and enhance the robustness of pose estimation, especially for long sequences and large scenes.
全球捆绑调整。为了全局一致性和准确性,我们的系统维护了比其他基于GS的SLAM系统大得多的全局关键帧数据库。我们从全局关键帧数据库中随机抽取N条光线,以优化场景表示和相机姿势。此阶段优化了类似于跟踪损失的损失,并且我们还将SSIM损失添加到RGB渲染中。执行全局光束法平差以优化具有相机姿态的场景表示。我们的全局BA方法可以有效地减少累积误差,提高姿态估计的鲁棒性,特别是对于长序列和大场景。

Figure 6:The rendering visualization results on the Replica dataset [30] of the proposed GS-based SLAM system compared with other SOTA methods. We present the rendering PSNR and FPS on the image. Our method can achieve faster rendering speed and high-quality image reconstruction performance compared with other methods.
图6:与其他SOTA方法相比,所提出的基于GS的SLAM系统的渲染可视化结果。我们提出了渲染的PSNR和FPS的图像。与其他方法相比,该方法可以获得更快的绘制速度和高质量的图像重建性能。