shigen坚持更新文章的博客写手,擅长Java、python、vue、shell等编程语言和各种应用程序、脚本的开发。记录成长,分享认知,留住感动。
个人IP:shigen
逛博客的时候,发现了一个很有意思的文章:数据库表结构导出工具。带着好奇,我也去DIY了一个,先看看效果:
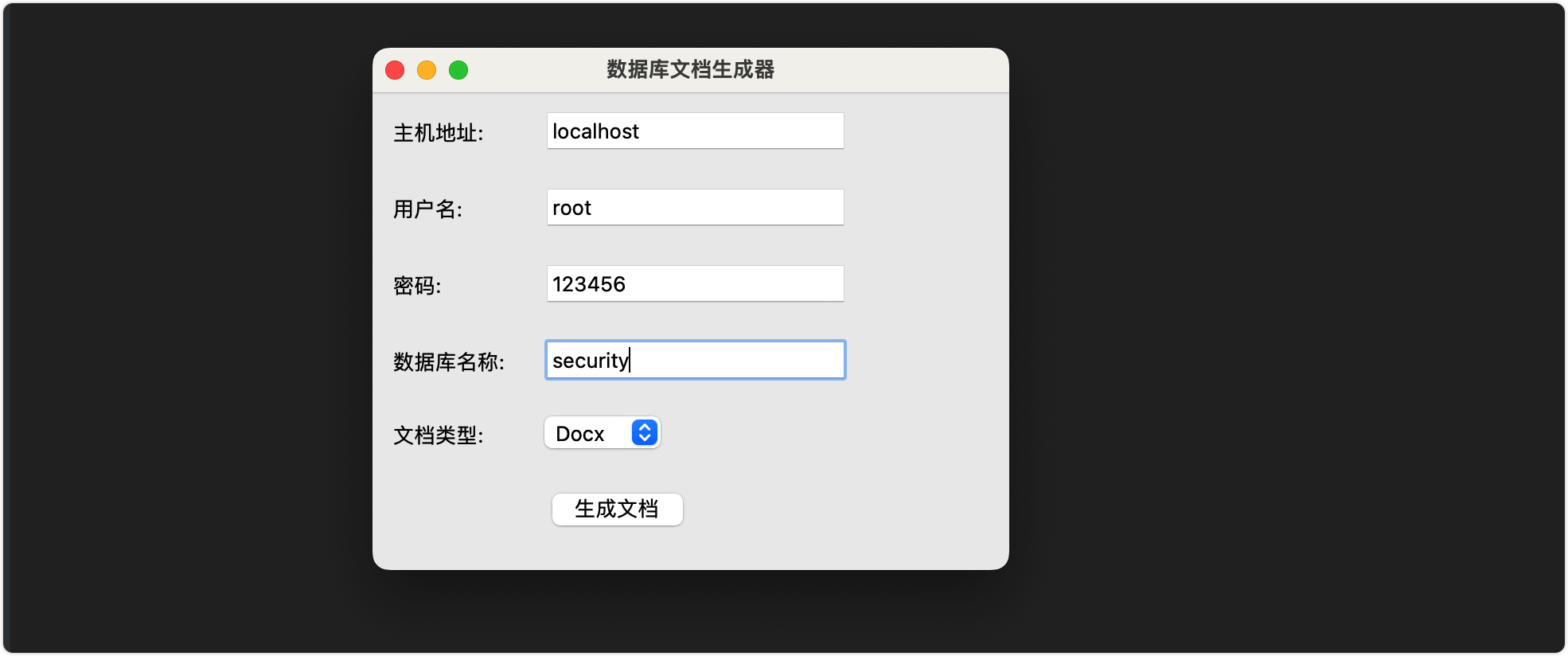
这个就是主要的程序界面,可以选择生成md文档或者docx文档。具体的文档内容如下:
md文档
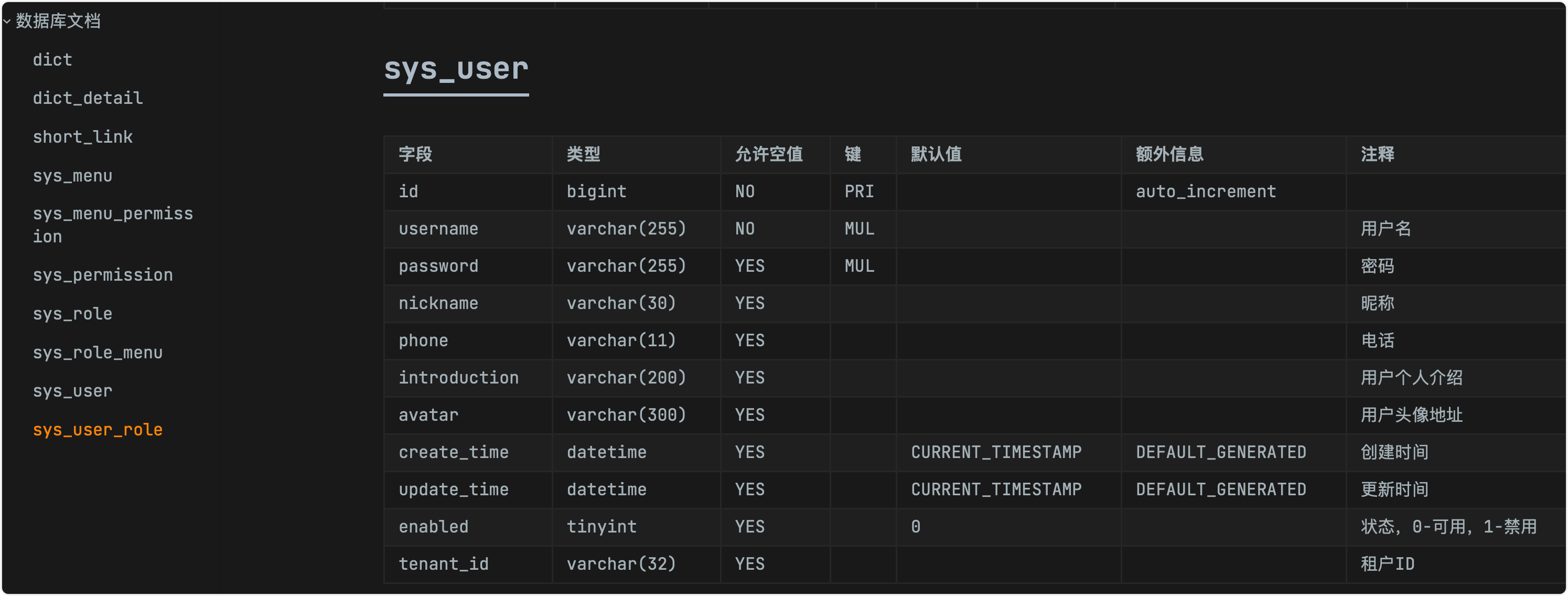
docx文档

功能可以成功的实现,现在我们来分析一下原理,核心就是几条sql语句:
use security;
show tables;
desc dict;
show full columns from dict where field = 'is_del';
原理分析
查看全部的表
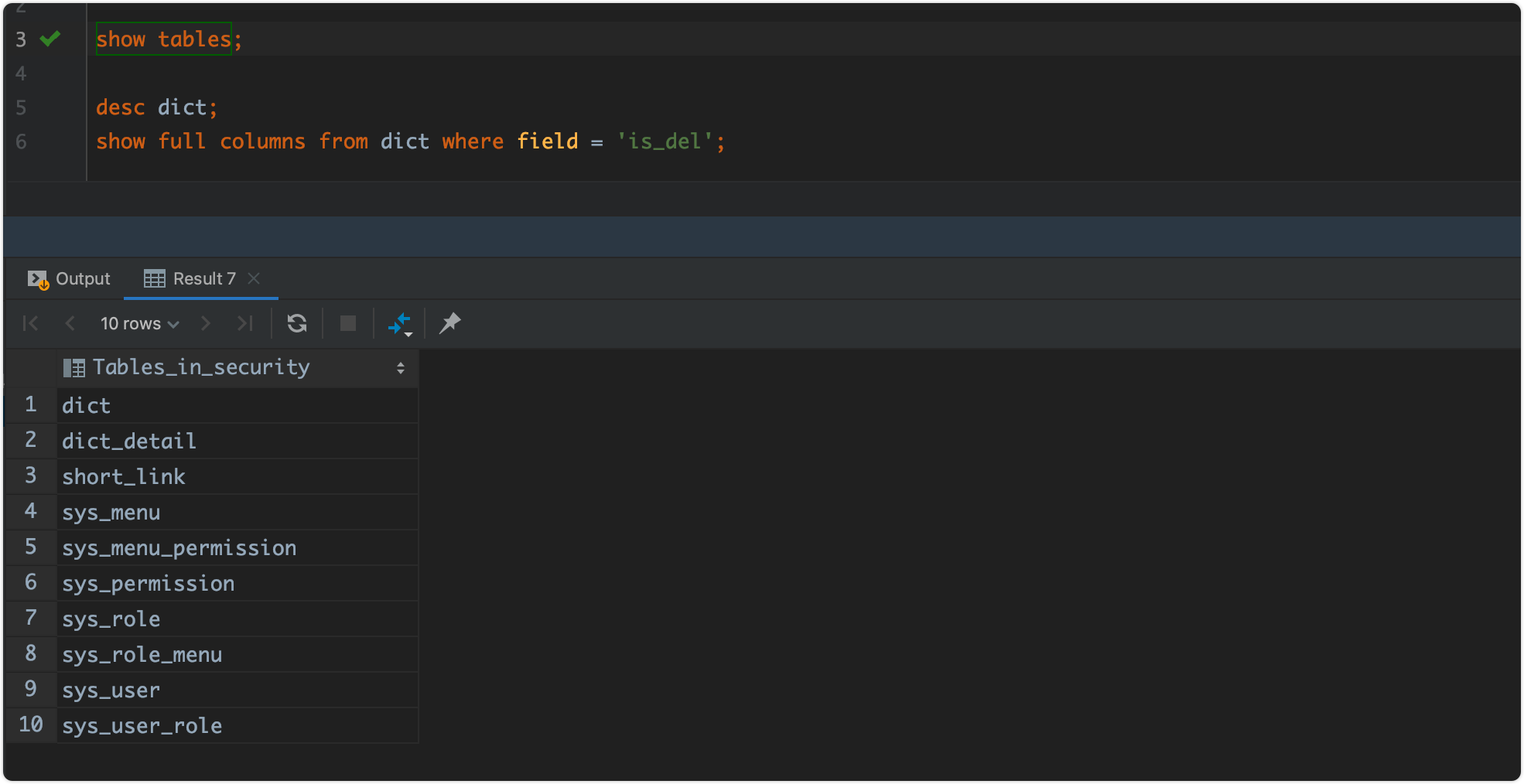
使用show tables就可以看到当前数据库下边的所有的数据表。
查看表结构
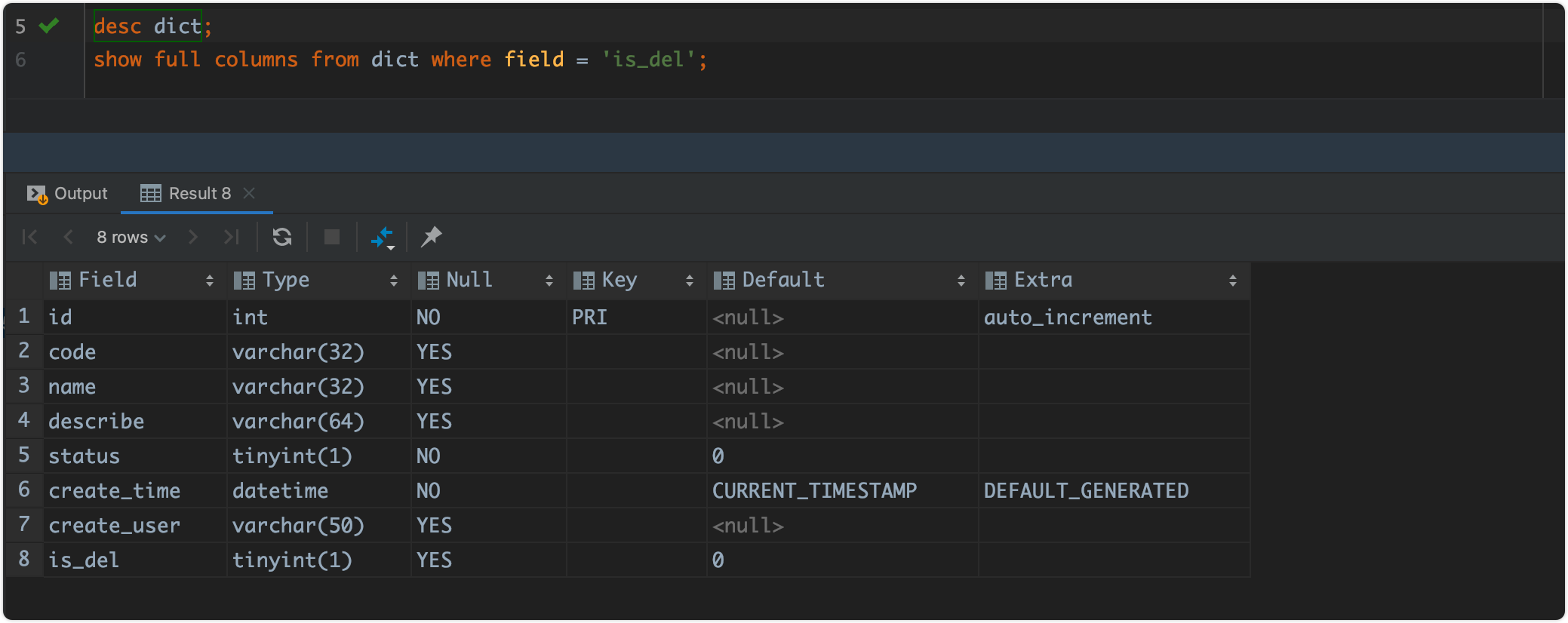
使用desc xxx即可查看表的详细结构,包含字段的全部信息。
查看字段注释
字段的注释需要额外的sql了:

当然,shigen也看到过连表查询出字段的注释的,可以进一步的改进。
总结
做一波小总结:其实数据库文档生成,就是用一些sql语句获得对应的表信息和字段信息,使用文本拼接写入到文件里。
代码分享
那本次设计的代码也在这里,欢迎大家学习交流:
from tkinter import *
from tkinter import messagebox
import mysql.connector
from docx import Document
from tabulate import tabulate
# 连接到MySQL数据库
def connect_to_database():
host = host_entry.get()
user = user_entry.get()
password = password_entry.get()
database = database_entry.get()
try:
conn = mysql.connector.connect(host=host,
port=3306,
user=user,
password=password,
database=database)
return conn
except mysql.connector.Error as err:
messagebox.showerror("错误", f"连接到MySQL数据库时出错:{err}")
return None
# 获取数据库中的表信息及字段注释
def get_table_info(conn):
tables_info = []
if conn:
cursor = conn.cursor()
cursor.execute("SHOW TABLES")
tables = cursor.fetchall()
for table in tables:
table_name = table[0]
cursor.execute(f"DESCRIBE {table_name}")
table_structure = cursor.fetchall()
tables_info.append({
"table_name": table_name,
"structure": table_structure
})
cursor.close()
return tables_info
# 获取字段注释
def get_field_comment(table_name, field_name):
cursor = conn.cursor()
cursor.execute(
f"SHOW FULL COLUMNS FROM {table_name} WHERE Field = '{field_name}'")
column_info = cursor.fetchone()
comment = column_info[8] # 注释信息在第9个元素中
cursor.close()
return comment
# 生成Markdown格式的数据库文档
def generate_markdown_documentation(tables_info):
documentation = "# 数据库文档\n\n"
documentation += f"数据库地址:{host_entry.get()}\n"
documentation += f"用户名:{user_entry.get()}\n"
documentation += f"数据库名称:{database_entry.get()}\n\n"
for table_info in tables_info:
table_name = table_info["table_name"]
structure = table_info["structure"]
documentation += f"## {table_name}\n\n"
headers = ["字段", "类型", "允许空值", "键", "默认值", "额外信息", "注释"] # 添加注释列
rows = []
for field_info in structure:
rows.append(
list(field_info) +
[get_field_comment(table_name, field_info[0])]) # 获取字段注释并添加到行中
documentation += tabulate(rows, headers, tablefmt="pipe") + "\n\n"
return documentation
# 生成docx格式的数据库文档
def generate_docx_documentation(tables_info):
doc = Document()
doc.add_heading('数据库文档', 0)
doc.add_paragraph(f"数据库地址:{host_entry.get()}")
doc.add_paragraph(f"用户名:{user_entry.get()}")
doc.add_paragraph(f"数据库名称:{database_entry.get()}")
for table_info in tables_info:
table_name = table_info["table_name"]
structure = table_info["structure"]
doc.add_heading(table_name, level=1)
# 创建带边框的表格
table = doc.add_table(rows=1, cols=7)
table.style = 'Table Grid' # 设置表格样式为带边框的样式
table.autofit = False # 禁止自动调整列宽
hdr_cells = table.rows[0].cells
hdr_cells[0].text = '字段'
hdr_cells[1].text = '类型'
hdr_cells[2].text = '允许空值'
hdr_cells[3].text = '键'
hdr_cells[4].text = '默认值'
hdr_cells[5].text = '额外信息'
hdr_cells[6].text = '注释' # 添加注释列
for field_info in structure:
row_cells = table.add_row().cells
row_cells[0].text = field_info[0]
row_cells[1].text = field_info[1]
row_cells[2].text = field_info[2]
row_cells[3].text = field_info[3]
row_cells[
4].text = field_info[4] if field_info[4] is not None else ""
row_cells[5].text = field_info[5]
row_cells[6].text = get_field_comment(table_name,
field_info[0]) # 获取并显示字段注释
return doc
# 创建标签和输入框
def create_input_fields(root, fields):
entries = {}
for row, (label_text, entry_text) in enumerate(fields):
label = Label(root, text=label_text)
label.grid(row=row, column=0, padx=10, pady=10, sticky="w")
entry = Entry(root)
entry.grid(row=row, column=1, padx=10, pady=10)
entry.insert(0, entry_text)
entries[label_text] = entry
# 添加文档类型选择器
label = Label(root, text="文档类型:")
label.grid(row=len(fields), column=0, padx=10, pady=10, sticky="w")
doc_type = StringVar(root)
doc_type.set("Markdown") # 默认选择 Markdown
doc_type_menu = OptionMenu(root, doc_type, "Markdown", "Docx")
doc_type_menu.grid(row=len(fields), column=1, padx=10, pady=10, sticky="w")
entries["文档类型:"] = doc_type
return entries
# 生成文档
def generate_document():
global conn # 在函数内部使用全局变量 conn
conn = connect_to_database()
if conn:
tables_info = get_table_info(conn)
if entries["文档类型:"].get() == "Markdown": # 获取文档类型
documentation = generate_markdown_documentation(tables_info)
with open("数据库文档.md", "w", encoding="utf-8") as file:
file.write(documentation)
messagebox.showinfo("成功", "Markdown文档生成成功!")
elif entries["文档类型:"].get() == "Docx":
doc = generate_docx_documentation(tables_info)
doc.save("数据库文档.docx")
messagebox.showinfo("成功", "Docx文档生成成功!")
# 创建主窗口
root = Tk()
root.title("数据库文档生成器")
root.geometry("400x300")
# 标签和输入框的内容
fields = [("主机地址:", ""), ("用户名:", ""), ("密码:", ""), ("数据库名称:", "")]
# 创建标签和输入框
entries = create_input_fields(root, fields)
# 获取输入框的内容
host_entry = entries["主机地址:"]
user_entry = entries["用户名:"]
password_entry = entries["密码:"]
database_entry = entries["数据库名称:"]
# 生成文档按钮
generate_button = Button(root, text="生成文档", command=generate_document)
generate_button.grid(row=len(fields) + 1, columnspan=2, padx=10, pady=10)
root.mainloop()
与shigen一起,每天不一样!