目录
为什么有listpack?
listpack结构
listpack的节点entry
长度length
encoding编码方式
listpack的API
1.创建listpack
2.遍历操作
正向遍历
反向遍历
3.查找元素
4.插入/替换/删除元素
总结
为什么有listpack?
ziplist是存储在连续内存空间,节省内存空间。quicklist是个节点为ziplist的双向链表,其通过控制 quicklistNode 结构里的压缩列表的大小或者元素个数,来减少连锁更新带来的性能影响,但这并没有完全解决连锁更新的问题。这是因为压缩列表连锁更新的问题来源于它的结构设计。
从Redis 5.0版本开始,设计了一个新的数据结构叫做listpack ,目的是替代原来的压缩列表。在每个listpack节点中,不再保存前一个节点的长度,所以也就不存在出现连锁更新的情况了。
Redis7.0 才将 listpack 完整替代 ziplist。这里讲解的代码版本是7.0.4。
listpack结构
该结构没有使用结构体来表示,通过lpNew函数创建listpack可以看出其结构组成。

- num of entry为listpack中的元素个数,即Entry的个数,占用2个字节。注意:这并不意味着listpack最多只能存放65535个Entry,当Entry个数大于等于65535时,num of entry设置为65535,此时如果需要获取元素个数,需要遍历整个listpack(这个和ziplist一样的)。
- Entry为每个具体的节点。
- End为listpack结束标志,占用1个字节,内容为0xFF。
listpack的节点entry
entry就是listpack的节点,entry的data就是存储节点的元素值。
而为了避免ziplist引起的连锁更新问题,listpack的entry不再像ziplist中保存前一个entry的长度,它只包含三个内容:当前元素的编码类型(encoding)、元素数据(data)、编码类型和元数据这两部分的长度(length)。
其中 encoding和 length一定有值;有时 data 可能会缺失,因为对于一些小的元素可以直接将data放在encoding字段中。
长度length
- entry的length字段记录了该entry的长度(encoding+data),注意:并不包括 length字段自身的长度,其占用的字节数小于等于5。
- length所占用的每个字节的第一个bit(最高位)用于标识:0代表结束,1代表尚未结束,每个字节只有7bit有效。
- length主要用于从后向前遍历。当需要找到当前元素的前一个元素时,我们可以从后往前依次查找每个字节,找到上一个entry的length字段的结束标识,从而可以计算出上个元素的长度。
关于length的函数有lpDecodeBacklen和lpEncodeBacklen。
编码长度的函数lpEncodeBacklen
length字段的 每个字节的低 7 位,记录了实际的长度信息。这里你需要注意的是,length字段 每个字节的低 7 位采用了大端模式存储,也就是说,length字段 的低位字节保存在内存高地址上。

//返回存储l所需的字节数,并把l存储在buf中
static inline unsigned long lpEncodeBacklen(unsigned char *buf, uint64_t l) {
if (l <= 127) {
if (buf) buf[0] = l;
return 1;
} else if (l < 16383) {
if (buf) {
buf[0] = l>>7;
buf[1] = (l&127)|128;
}
return 2;
} else if (l < 2097151) {
if (buf) {
buf[0] = l>>14;
buf[1] = ((l>>7)&127)|128;
buf[2] = (l&127)|128;
}
return 3;
} else if (l < 268435455) {
if (buf) {
buf[0] = l>>21;
buf[1] = ((l>>14)&127)|128;
buf[2] = ((l>>7)&127)|128;
buf[3] = (l&127)|128;
}
return 4;
} else {
if (buf) {
buf[0] = l>>28;
buf[1] = ((l>>21)&127)|128;
buf[2] = ((l>>14)&127)|128;
buf[3] = ((l>>7)&127)|128;
buf[4] = (l&127)|128;
}
return 5;
}
}解码长度的函数lpDecodeBacklen
其结果返回节点的字段length值。这个时候p是一直往左移动,等到完全获取了length值,p也移动到了length字段的首地址。之后再通过length值就可以移动到上一节点的尾地址。

/* Decode the backlen and returns it. If the encoding looks invalid (more than
* 5 bytes are used), UINT64_MAX is returned to report the problem. */
static inline uint64_t lpDecodeBacklen(unsigned char *p) {
uint64_t val = 0;
uint64_t shift = 0;
//127的二进制是01111 1111, 128的二进制是1000 0000
do {
val |= (uint64_t)(p[0] & 127) << shift;
if (!(p[0] & 128)) break; //表示该字节的最高位是0,结束标识
shift += 7;
p--;
if (shift > 28) return UINT64_MAX;
} while(1);
return val;
}encoding编码方式
为了节省内存空间,listpack针对不同的数据做了不同的编码,其数据内容是整数和字符串。
encoding由两部分组成:区分整数和字符串的标识和data长度。

所以通过encoding是可以得出data的长度。
整数编码
#define LP_ENCODING_7BIT_UINT 0
#define LP_ENCODING_13BIT_INT 0xC0
#define LP_ENCODING_16BIT_INT 0xF1
#define LP_ENCODING_24BIT_INT 0xF2
#define LP_ENCODING_32BIT_INT 0xF3
#define LP_ENCODING_64BIT_INT 0xF4
整数编码对应的占用字节数和可以存储的值如下图。
整数编码的,通过encoding的首字节的几bit或者整个字节,可以知道其储存的整数值的长度。
 该图片来自https://segmentfault.com/a/1190000041670843
该图片来自https://segmentfault.com/a/1190000041670843
字符串编码
3种字符串编码,分别根据不同的字符串长度,采取不同的编码方式。
#define LP_ENCODING_6BIT_STR 0x80
#define LP_ENCODING_12BIT_STR 0xE0
#define LP_ENCODING_32BIT_STR 0xF0通过encoding字段的首字节就可以获取字符串的data长度。紫色部分的就是存储data的长度。
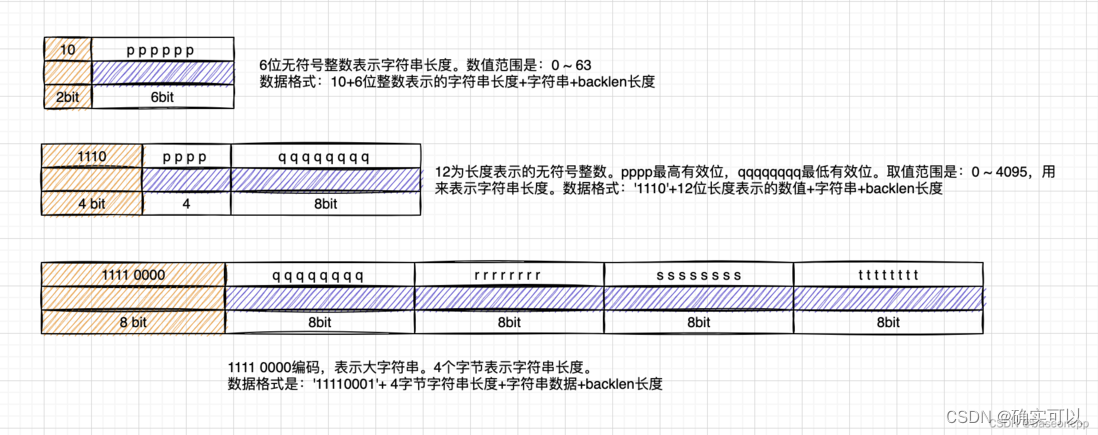
该图片来自https://segmentfault.com/a/1190000041670843
所以,entry的encoding字段可以获取到entry的data的长度,而length字段可以获取到(encoding+data)的长度。
listpack有个有结构体listpackEntry。应该是在使用listpack的结构(比如zset)中会创建调用其。目前看该文章可以不用了解listpackEntry。
/* Each entry in the listpack is either a string or an integer. */
typedef struct {
/* When string is used, it is provided with the length (slen). */
unsigned char *sval;
uint32_t slen;
/* When integer is used, 'sval' is NULL, and lval holds the value. */
long long lval;
} listpackEntry;
void lpRandomPairs(unsigned char *lp, unsigned int count, listpackEntry *keys, listpackEntry *vals);
unsigned int lpRandomPairsUnique(unsigned char *lp, unsigned int count, listpackEntry *keys, listpackEntry *vals);
//t_zset.c
//代码片段,关于listpackEntry 的使用
listpackEntry *keys, *vals = NULL;
keys = zmalloc(sizeof(listpackEntry)*count);
if (withscores)
vals = zmalloc(sizeof(listpackEntry)*count);listpack的API
1.创建listpack
#define LP_HDR_SIZE 6 /* 32 bit total len + 16 bit number of elements. */
unsigned char *lpNew(size_t capacity) {
unsigned char *lp = lp_malloc(capacity > LP_HDR_SIZE+1 ? capacity : LP_HDR_SIZE+1);
if (lp == NULL) return NULL;
lpSetTotalBytes(lp,LP_HDR_SIZE+1);
lpSetNumElements(lp,0); //设置元素个数
lp[LP_HDR_SIZE] = LP_EOF;
return lp; //lp[6]即第7个字节,尾部,设置为0XFF
}要注意的一点:不管分配的capacity多大,其创建listpack时候,初始化使用的长度就是只用了7字节而已,剩余的内存空间,是暂时不用。
2.遍历操作
在listpack 中,因为每个节点只记录了自己的长度,而不会像ziplist那样记录前一节点的长度。所以,在对listpack进行新增和修改元素时候,实际上只会涉及到对自己节点的操作,而不会影响后续节点的长度变化,这样就避免了连锁更新。
那没有了prelen,那listpack还支持正向或反向遍历吗?这当然支持的。
提供了正向遍历和反向遍历,参数lp是listpack的首地址,p是要要查找的entry。
unsigned char *lpFirst(unsigned char *lp);
unsigned char *lpLast(unsigned char *lp);
unsigned char *lpNext(unsigned char *lp, unsigned char *p);
unsigned char *lpPrev(unsigned char *lp, unsigned char *p);正向遍历
- 根据当前节点的第1个字节获取到当前节点的编码类型(是整数还是字符串),并根据编码类型计算当前entry的存储encoding所用的字节数和data的长度
- 再通过lpEncodeBacklen函数获取存储length所占用的字节数,这样就知道整个entry的长度了。
//返回值是下一节点的首地址,参数p是当前节点的首地址,
unsigned char *lpNext(unsigned char *lp, unsigned char *p) {
assert(p);
p = lpSkip(p);
if (p[0] == LP_EOF) return NULL;
//这个就是判断p是否还在listpack的内存范围内,不然就报错
lpAssertValidEntry(lp, lpBytes(lp), p);
return p;
}
unsigned char *lpSkip(unsigned char *p) {
//该函数是返回entry的length字段的值,不是返回存储length字段所占用的字节数
unsigned long entrylen = lpCurrentEncodedSizeUnsafe(p);
entrylen += lpEncodeBacklen(NULL,entrylen); //返回存储length字段所占用的字节数,讲解length字段时候有讲解了
p += entrylen; //p+当前entry的整个entry的长度,即到达下一entry
return p;
}需要讲解下lpCurrentEncodedSizeUnsafe和lpCurrentEncodedSizeBytes,这两个函数很相似,但需要弄清楚各自的作用。
- lpCurrentEncodedSizeUnsafe是返回entry的length字段的值。
- lpCurrentEncodedSizeBytes是返回存储entry的encoding字段所需的字节数。
static inline uint32_t lpCurrentEncodedSizeUnsafe(unsigned char *p) {
if (LP_ENCODING_IS_7BIT_UINT(p[0])) return 1;
if (LP_ENCODING_IS_6BIT_STR(p[0])) return 1+LP_ENCODING_6BIT_STR_LEN(p);
if (LP_ENCODING_IS_13BIT_INT(p[0])) return 2;
if (LP_ENCODING_IS_16BIT_INT(p[0])) return 3;
if (LP_ENCODING_IS_24BIT_INT(p[0])) return 4;
if (LP_ENCODING_IS_32BIT_INT(p[0])) return 5;
if (LP_ENCODING_IS_64BIT_INT(p[0])) return 9;
if (LP_ENCODING_IS_12BIT_STR(p[0])) return 2+LP_ENCODING_12BIT_STR_LEN(p);
if (LP_ENCODING_IS_32BIT_STR(p[0])) return 5+LP_ENCODING_32BIT_STR_LEN(p);
if (p[0] == LP_EOF) return 1;
return 0;
}
static inline uint32_t lpCurrentEncodedSizeBytes(unsigned char *p) {
if (LP_ENCODING_IS_7BIT_UINT(p[0])) return 1;
if (LP_ENCODING_IS_6BIT_STR(p[0])) return 1;
if (LP_ENCODING_IS_13BIT_INT(p[0])) return 1;
if (LP_ENCODING_IS_16BIT_INT(p[0])) return 1;
if (LP_ENCODING_IS_24BIT_INT(p[0])) return 1;
if (LP_ENCODING_IS_32BIT_INT(p[0])) return 1;
if (LP_ENCODING_IS_64BIT_INT(p[0])) return 1;
if (LP_ENCODING_IS_12BIT_STR(p[0])) return 2;
if (LP_ENCODING_IS_32BIT_STR(p[0])) return 5;
if (p[0] == LP_EOF) return 1;
return 0;
}反向遍历
//参数p是当前entry的首地址
unsigned char *lpPrev(unsigned char *lp, unsigned char *p) {
assert(p);
//若是前面没有节点了,就返回NULL
if (p-lp == LP_HDR_SIZE) return NULL;
p--; /* Seek the first backlen byte of the last element. */
//p--是重点,要结合前面讲解的lpDecodeBacklen函数的配图来看
uint64_t prevlen = lpDecodeBacklen(p); //获取当前entry的encoding的占用字节数和data的长度
prevlen += lpEncodeBacklen(NULL,prevlen); //获取length字段所占用的字节数
//这是prevlen就是当前entry的总长度了,p-prevlen就到达上一节点的尾地址
//这里的-1,即是p+1,是因为前面p--,所以需要+1回去
p -= prevlen-1; /* Seek the first byte of the previous entry. */
lpAssertValidEntry(lp, lpBytes(lp), p); //进行校验
return p;
}3.查找元素
其是在一个while循环中查找。 我们可以先跳过参数skip和函数内变量skipcnt那部分,这样我们就可以很好理解主体了。
while循环中,调用lpGetWithSize(p, &ll, NULL, &entry_size)来获取p位置的元素,之后进行比较,若符合条件就返回结果。(其中有很多校验的代码)
//从位置p开始查找元素s,s的长度是slen
unsigned char *lpFind(unsigned char *lp, unsigned char *p, unsigned char *s,
uint32_t slen, unsigned int skip) {
int skipcnt = 0;
unsigned char vencoding = 0;
unsigned char *value;
int64_t ll, vll;
uint64_t entry_size = 123456789; /* initialized to avoid warning. */
uint32_t lp_bytes = lpBytes(lp); //获取listpack的总长度
assert(p);
while (p) {
if (skipcnt == 0) {
//该函数是返回p位置的元素值,ll是该元素的长度,entry_size是整个entry的长度
value = lpGetWithSize(p, &ll, NULL, &entry_size);
if (value) {
/* check the value doesn't reach outside the listpack before accessing it */
assert(p >= lp + LP_HDR_SIZE && p + entry_size < lp + lp_bytes);
if (slen == ll && memcmp(value, s, slen) == 0) {
return p;
}
} else {
/* Find out if the searched field can be encoded. Note that
* we do it only the first time, once done vencoding is set
* to non-zero and vll is set to the integer value. */
if (vencoding == 0) {
/* If the entry can be encoded as integer we set it to
* 1, else set it to UCHAR_MAX, so that we don't retry
* again the next time. */
if (slen >= 32 || slen == 0 || !lpStringToInt64((const char*)s, slen, &vll)) {
vencoding = UCHAR_MAX;
} else {
vencoding = 1;
}
}
/* Compare current entry with specified entry, do it only
* if vencoding != UCHAR_MAX because if there is no encoding
* possible for the field it can't be a valid integer. */
if (vencoding != UCHAR_MAX && ll == vll) {
return p;
}
}
/* Reset skip count */
skipcnt = skip;
p += entry_size;
} else {
/* Skip entry */
skipcnt--;
p = lpSkip(p);
}
/* The next call to lpGetWithSize could read at most 8 bytes past `p`
* We use the slower validation call only when necessary. */
if (p + 8 >= lp + lp_bytes)
lpAssertValidEntry(lp, lp_bytes, p);
else
assert(p >= lp + LP_HDR_SIZE && p < lp + lp_bytes);
if (p[0] == LP_EOF) break;
}
return NULL;
}lpGetWithSize函数
根据当前节点的第1个字节获取到当前节点的编码类型(是整数还是字符串),并根据编码类型计算当前entry的存储encoding所用的字节数和data的长度,若是字符串就直接返回字符串。
//count是p指向的entry的字段data的长度,entry_size是整个entry的长度
static inline unsigned char *lpGetWithSize(unsigned char *p, int64_t *count, unsigned char *intbuf, uint64_t *entry_size) {
int64_t val;
uint64_t uval, negstart, negmax;
//uval用来存储元素,当元素是整数时候
assert(p); /* assertion for valgrind (avoid NPD) */
if (LP_ENCODING_IS_7BIT_UINT(p[0])) { //表明是整数
negstart = UINT64_MAX; /* 7 bit ints are always positive. */
negmax = 0;
uval = p[0] & 0x7f;
if (entry_size) *entry_size = LP_ENCODING_7BIT_UINT_ENTRY_SIZE;
} else if (LP_ENCODING_IS_6BIT_STR(p[0])) { //字符串
*count = LP_ENCODING_6BIT_STR_LEN(p);
if (entry_size) *entry_size = 1 + *count + lpEncodeBacklen(NULL, *count + 1);
return p+1;
} else if (LP_ENCODING_IS_13BIT_INT(p[0])) { //表明是整数
uval = ((p[0]&0x1f)<<8) | p[1];
negstart = (uint64_t)1<<12;
negmax = 8191;
if (entry_size) *entry_size = LP_ENCODING_13BIT_INT_ENTRY_SIZE;
} else if (LP_ENCODING_IS_16BIT_INT(p[0])) { //表明是整数
uval = (uint64_t)p[1] |
(uint64_t)p[2]<<8;
negstart = (uint64_t)1<<15;
negmax = UINT16_MAX;
if (entry_size) *entry_size = LP_ENCODING_16BIT_INT_ENTRY_SIZE;
} else if (LP_ENCODING_IS_24BIT_INT(p[0])) { //表明是整数
uval = (uint64_t)p[1] |
(uint64_t)p[2]<<8 |
(uint64_t)p[3]<<16;
negstart = (uint64_t)1<<23;
negmax = UINT32_MAX>>8;
if (entry_size) *entry_size = LP_ENCODING_24BIT_INT_ENTRY_SIZE;
} else if (LP_ENCODING_IS_32BIT_INT(p[0])) { //表明是整数
uval = (uint64_t)p[1] |
(uint64_t)p[2]<<8 |
(uint64_t)p[3]<<16 |
(uint64_t)p[4]<<24;
negstart = (uint64_t)1<<31;
negmax = UINT32_MAX;
if (entry_size) *entry_size = LP_ENCODING_32BIT_INT_ENTRY_SIZE;
} else if (LP_ENCODING_IS_64BIT_INT(p[0])) { //表明是整数
uval = (uint64_t)p[1] |
(uint64_t)p[2]<<8 |
(uint64_t)p[3]<<16 |
(uint64_t)p[4]<<24 |
(uint64_t)p[5]<<32 |
(uint64_t)p[6]<<40 |
(uint64_t)p[7]<<48 |
(uint64_t)p[8]<<56;
negstart = (uint64_t)1<<63;
negmax = UINT64_MAX;
if (entry_size) *entry_size = LP_ENCODING_64BIT_INT_ENTRY_SIZE;
} else if (LP_ENCODING_IS_12BIT_STR(p[0])) { //字符串
*count = LP_ENCODING_12BIT_STR_LEN(p);
if (entry_size) *entry_size = 2 + *count + lpEncodeBacklen(NULL, *count + 2);
return p+2;
} else if (LP_ENCODING_IS_32BIT_STR(p[0])) { //字符串
*count = LP_ENCODING_32BIT_STR_LEN(p);
if (entry_size) *entry_size = 5 + *count + lpEncodeBacklen(NULL, *count + 5);
return p+5;
} else {
uval = 12345678900000000ULL + p[0];
negstart = UINT64_MAX;
negmax = 0;
}
//存储的是负数的一些操作
/* We reach this code path only for integer encodings.
* Convert the unsigned value to the signed one using two's complement
* rule. */
if (uval >= negstart) {
/* This three steps conversion should avoid undefined behaviors
* in the unsigned -> signed conversion. */
uval = negmax-uval;
val = uval;
val = -val-1;
} else {
val = uval;
}
/* Return the string representation of the integer or the value itself
* depending on intbuf being NULL or not. */
if (intbuf) {
*count = ll2string((char*)intbuf,LP_INTBUF_SIZE,(long long)val);
return intbuf;
} else {
*count = val;
return NULL;
}
}4.插入/替换/删除元素
删除,替换,插入都是该函数lpInsert
unsigned char *lpInsertString(unsigned char *lp, unsigned char *s, uint32_t slen,
unsigned char *p, int where, unsigned char **newp)
{
return lpInsert(lp, s, NULL, slen, p, where, newp);
}
unsigned char *lpInsertInteger(unsigned char *lp, long long lval, unsigned char *p, int where, unsigned char **newp) {
uint64_t enclen; /* The length of the encoded element. */
unsigned char intenc[LP_MAX_INT_ENCODING_LEN];
lpEncodeIntegerGetType(lval, intenc, &enclen);
return lpInsert(lp, NULL, intenc, enclen, p, where, newp);
}
unsigned char *lpReplace(unsigned char *lp, unsigned char **p, unsigned char *s, uint32_t slen) {
return lpInsert(lp, s, NULL, slen, *p, LP_REPLACE, p);
}
unsigned char *lpDelete(unsigned char *lp, unsigned char *p, unsigned char **newp) {
return lpInsert(lp,NULL,NULL,0,p,LP_REPLACE,newp);
}主要步骤:
1.先通过where判断插入的位置是p的前面还是后面,要是后插,就使用lpSkip函数把p移动下一接点,插入的就可以统一是前插;要是删除就使用零长度元素替换。所以实际上只处理两个情况:前插和替换。
2.判断插入的元素是字符串还是整数,若字符串中存储的是整数,尝试用整数保存。获取待插入entry的length字段的值和存储length占用的字节数。还有替换的情况。
3.根据前面计算的,算出新listpack的总长度,进行内存分配,之后根据是前插还是替换,使用memmove函数把内存空间挪移到合适的位置
//源码注释的翻译
/*listpack和其他数据结构非常不一样的地方就在于,无论是增还是删还是改,都用这同一个函数!
我们要操作的位置在元素p处,操作的对象是一个大小为size的字符串elestr或者整数eleint,
其中元素p的位置可以通过lpFirst(),lpLast(), lpNext(), lpPrev() or lpSeek() 找到。
通过where参数,元素会被插入到p指向的元素前面、后面或者替换该元素。并且如果elestr和elein都为空,
那么函数会删除p指向的元素。
如果eleint不为空,size就为eleint的长度,函数会在p元素处插入或者替换一个64位的整数,
而如果elestr不为空,size则表示elestr的长度,函数会再p元素处插入或者替换一个字符串。
*/
unsigned char *lpInsert(unsigned char *lp, unsigned char *elestr, unsigned char *eleint,
uint32_t size, unsigned char *p, int where, unsigned char **newp)
{
unsigned char intenc[LP_MAX_INT_ENCODING_LEN];
unsigned char backlen[LP_MAX_BACKLEN_SIZE];
//1
uint64_t enclen; /* The length of the encoded element. */
int delete = (elestr == NULL && eleint == NULL); //如果elestr和eleint都是空,那就是删除p处的元素
if (delete) where = LP_REPLACE; //当删除时,它在概念上用零长度元素替换元素
if (where == LP_AFTER) { //如果是后插入,就让p移动到下一节点,这样就变成前插。所以函数实际上只处理两个情况:LP_BEFORE和LP_REPLACE。
p = lpSkip(p);
where = LP_BEFORE;
ASSERT_INTEGRITY(lp, p);
}
unsigned long poff = p-lp; //获取偏移量
//2
int enctype;
if (elestr) {
enctype = lpEncodeGetType(elestr,size,intenc,&enclen); //返回元素的类型(字符串或整数),把encoding字段存储在intenc中,enclen是length字段的值
if (enctype == LP_ENCODING_INT) eleint = intenc;
} else if (eleint) {
enctype = LP_ENCODING_INT;
enclen = size; /* 'size' is the length of the encoded integer element. */
} else {
enctype = -1;
enclen = 0;
}
unsigned long backlen_size = (!delete) ? lpEncodeBacklen(backlen,enclen) : 0;//返回存储length字段所占用的字节数
uint64_t old_listpack_bytes = lpGetTotalBytes(lp);
uint32_t replaced_len = 0;
if (where == LP_REPLACE) { //计算出替换所需的大小
replaced_len = lpCurrentEncodedSizeUnsafe(p); //获取p位置节点的(encoding+data)的长度
replaced_len += lpEncodeBacklen(NULL,replaced_len); //获取存储replaced_len所占用的字节数
ASSERT_INTEGRITY_LEN(lp, p, replaced_len); //校验用的
//若是替换的话,这时,replaced_len就是p位置整个节点的长度
}
//3
//设置新listpack的总长度
uint64_t new_listpack_bytes = old_listpack_bytes + enclen + backlen_size
- replaced_len;
if (new_listpack_bytes > UINT32_MAX) return NULL;
//通过偏移量,找到原来操作元素p的位置
unsigned char *dst = lp + poff; /* May be updated after reallocation. */
//如果需要分配更多的空间,那就分配这个空间,如果分配失败直接返回NULL
/* Realloc before: we need more room. */
if (new_listpack_bytes > old_listpack_bytes &&
new_listpack_bytes > lp_malloc_size(lp)) {
if ((lp = lp_realloc(lp,new_listpack_bytes)) == NULL) return NULL;
dst = lp + poff;
}
/* Setup the listpack relocating the elements to make the exact room
* we need to store the new one. */
if (where == LP_BEFORE) { //如果是在这个位置之前插入,就调用memmove函数,把内存空间挨个的向后移动要插入的这个元素的空间
memmove(dst+enclen+backlen_size,dst,old_listpack_bytes-poff);
} else { /* LP_REPLACE. */ /*如果是替换,还是先移动出原来元素和新元素的内存差值 */
long lendiff = (enclen+backlen_size)-replaced_len;
memmove(dst+replaced_len+lendiff,
dst+replaced_len,
old_listpack_bytes-poff-replaced_len);
}
/* Realloc after: we need to free space. */
// 如果新插入元素后listpack要用的字节数比原来的字节数少
if (new_listpack_bytes < old_listpack_bytes) {
if ((lp = lp_realloc(lp,new_listpack_bytes)) == NULL) return NULL;
dst = lp + poff;
}
//未完待续......................
}
4.把新listpack中原来p节点位置的节点赋值给newp
5.更新listpack的头部,即是更新总长度和元素个数
unsigned char *lpInsert(unsigned char *lp, unsigned char *elestr, unsigned char *eleint,
uint32_t size, unsigned char *p, int where, unsigned char **newp)
{
//该函数太长了,就分成两部分。接着上面的讲解
/* Store the entry. */
//把新listpack中原来p节点位置的节点赋值给newp
if (newp) {
*newp = dst;
/* In case of deletion, set 'newp' to NULL if the next element is
* the EOF element. */
if (delete && dst[0] == LP_EOF) *newp = NULL;
}
//这个才是进行拷贝插入的数据
if (!delete) {
if (enctype == LP_ENCODING_INT) {
memcpy(dst,eleint,enclen);
} else {
lpEncodeString(dst,elestr,size);
}
dst += enclen;
memcpy(dst,backlen,backlen_size);
dst += backlen_size;
}
/* Update header. */
//更新listpack头部,即是总长度和entry个数
if (where != LP_REPLACE || delete) {
uint32_t num_elements = lpGetNumElements(lp);
if (num_elements != LP_HDR_NUMELE_UNKNOWN) {
if (!delete)
lpSetNumElements(lp,num_elements+1);
else
lpSetNumElements(lp,num_elements-1);
}
}
lpSetTotalBytes(lp,new_listpack_bytes);
return lp;
}
总结
从 ziplist 到 quicklist,再到 listpack,Redis中设计实现是不断迭代优化的。
ziplist中元素个数多了,其查找效率就降低。若是在ziplist里新增或修改数据,ziplist占用的内存空间还需要重新分配;更糟糕的是,ziplist新增或修改元素时候,可能会导致后续元素的previous_entry_length占用空间都发生变化,从而引起连锁更新,导致每个元素的空间都需要重新分配,更加导致其访问性能下降。
为了应对这些问题,Redis先是在3.0版本实现了quicklist结构。其是在ziplist基础上,使用链表将多个ziplist串联起来,即链表的每个元素是一个ziplist。这样可以减少数据插入时内存空间的重新分配及内存数据的拷贝。而且,quicklist也限制了每个节点上ziplist的大小,要是某个ziplist的元素个数多了,会采用新增节点的方法。
但是因为quicklist使用节点结构指向了每个ziplist,这又增加了内存开销。而为了减少内存开销,并进一步避免ziplist连锁更新的问题,所以就有了listpack结构。
listpack是沿用了ziplist紧凑型的内存布局。而listpack中每个节点不再包含前一节点的长度,所以当某个节点中的数据发生变化时候,导致节点的长度变化也不会影响到其他节点,这就可以避免连锁更新的问题了。