1. 概述
在过去的几年中,卷积神经网络(CNN)在医学图像分析领域取得了显著的成就,特别是在图像分割任务上。U-Net作为一种特别为医学图像分割设计的深度学习架构,因其优秀的性能而被广泛采用。然而,CNN的卷积操作本质上是局部的,这限制了它在捕捉图像全局特征方面的能力。
与此同时,Transformer架构因其能够学习全局依赖关系而受到了关注。Transformer通过自注意力机制(Self-Attention Mechanism)能够处理序列数据中的长距离依赖问题,这使得它在处理图像全局特征方面具有潜在优势。
为了结合CNN的局部感知能力和Transformer的全局感知能力,研究者们提出了一种新的架构——基于Transformer的U-Net,称为Swin-Unet。Swin-Unet结合了Swin Transformer的全局特征学习能力和U-Net的优秀分割性能,特别适用于多器官的医学图像分割任务。
在这项研究中,Swin-Unet的性能被与纯CNN和结合了CNN的Transformer方法进行了比较。实验结果表明,Swin-Unet在多器官分割任务上取得了优于其他方法的性能。这可能是因为Swin-Unet能够有效地结合局部和全局信息,从而更好地理解医学图像中的复杂结构。
论文地址:https://arxiv.org/abs/2105.05537
源码地址:https://github.com/HuCaoFighting/Swin-Unet
2. 研究背景
近年来,自然语言处理领域中出现了一种名为Transformer的网络架构,它因其卓越的性能而迅速流行起来。Transformer的核心机制是注意力机制(Attention Mechanism),这一机制能够确定在翻译任务中,输入句子中的哪些词与输出句子中的哪些词相关联,并计算这些词在句子中的重要性。注意力机制使得Transformer能够捕捉全局上下文信息,因为每个词的输出都是基于该词在整个句子中的重要性来计算的。
相比之下,卷积神经网络(CNN)在图像处理领域中的核心思想是卷积操作。卷积操作通过对图像中的像素群进行信息汇总,类似于将图像折叠以减小其尺寸的过程。CNN通过聚合局部区域的形状、颜色等信息来生成输出,因此它擅长捕捉局部特征,但在捕捉图像中远距离区域的信息方面存在局限。
尽管CNN和Transformer在处理数据的方式上存在显著差异,但Transformer中的注意力机制后来也被引入到图像处理领域。Vision Transformer(ViT)的基本思想是将图像分割成多个小块(patches),并将这些小块视作自然语言处理中的词汇。这样,图像就被当作句子一样进行处理,ViT成功地学习了图像中的全局信息。
U-Net是一种在医学图像分割任务中非常成功的网络架构,它的各种改进版本,如3D U-Net、Res-Unet和U-Net++,也已被广泛报道。然而,由于U-Net本质上是基于CNN的,它在聚合全局信息方面存在局限。在本研究中,将ViT的概念应用于U-Net,提出了一种新的网络架构,称为Swin-Unet。
Swin-Unet的输入图像首先被送入一个基于Transformer的编码器,该编码器能够学习图像中的广泛空间特征。在多器官分割和心脏分割等任务中,Swin-Unet展现了出色的分割精度和强大的泛化能力。通过结合Transformer的全局感知能力和U-Net的有效分割特性,Swin-Unet在医学图像分析领域中开辟了新的可能性。
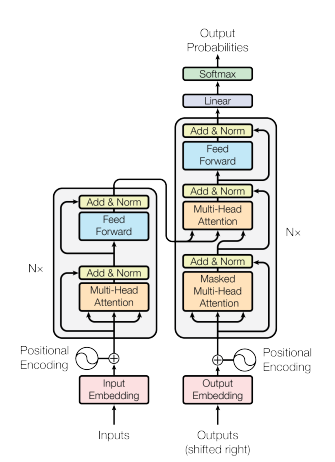
3. 相关研究
早期的医学图像分割方法主要依赖于轮廓(contour)信息和传统的机器学习技术。随着深度学习特别是卷积神经网络(CNN)的发展,U-Net架构被提出,并迅速成为医学图像分割领域的一个标杆。U-Net以其高效的上下文信息整合和精确的分割性能而受到广泛欢迎。
随着时间的推移,为了进一步提高分割效果和解决特定问题,U-Net的多种改进版本相继被提出。这些改进版本包括但不限于Res-UNet、Dense-UNet、U-Net++、UNet3+、3D-Unet和V-Net等。每一种改进都是在原始U-Net的基础上针对特定问题进行了优化,比如增加跳跃连接(skip connections)来提高特征传递,或者引入密集连接(dense connections)来增强特征重用,以及扩展到三维图像分割等。
与此同时,Transformer架构作为一种补充CNN的方法被提出,特别是在自然语言处理领域取得了巨大成功。Transformer引入了自注意力(self-attention)机制,能够捕捉序列中的长距离依赖关系。在图像处理领域,Transformer也被证明是一种强大的工具,因为它能够处理全局上下文信息,而不仅仅是局部区域。
然而,尽管Transformer在处理全局信息方面具有优势,但它的设计理念与本文介绍的Swin-Unet有所不同。Swin-Unet是一种结合了Transformer的全局感知能力和CNN的局部感知能力的新型网络架构。它通过在U-Net的基础上引入Transformer的自注意力机制,使得网络能够更好地捕捉全局和局部特征,从而在医学图像分割任务中取得更好的性能。
4.Swin-Unet架构
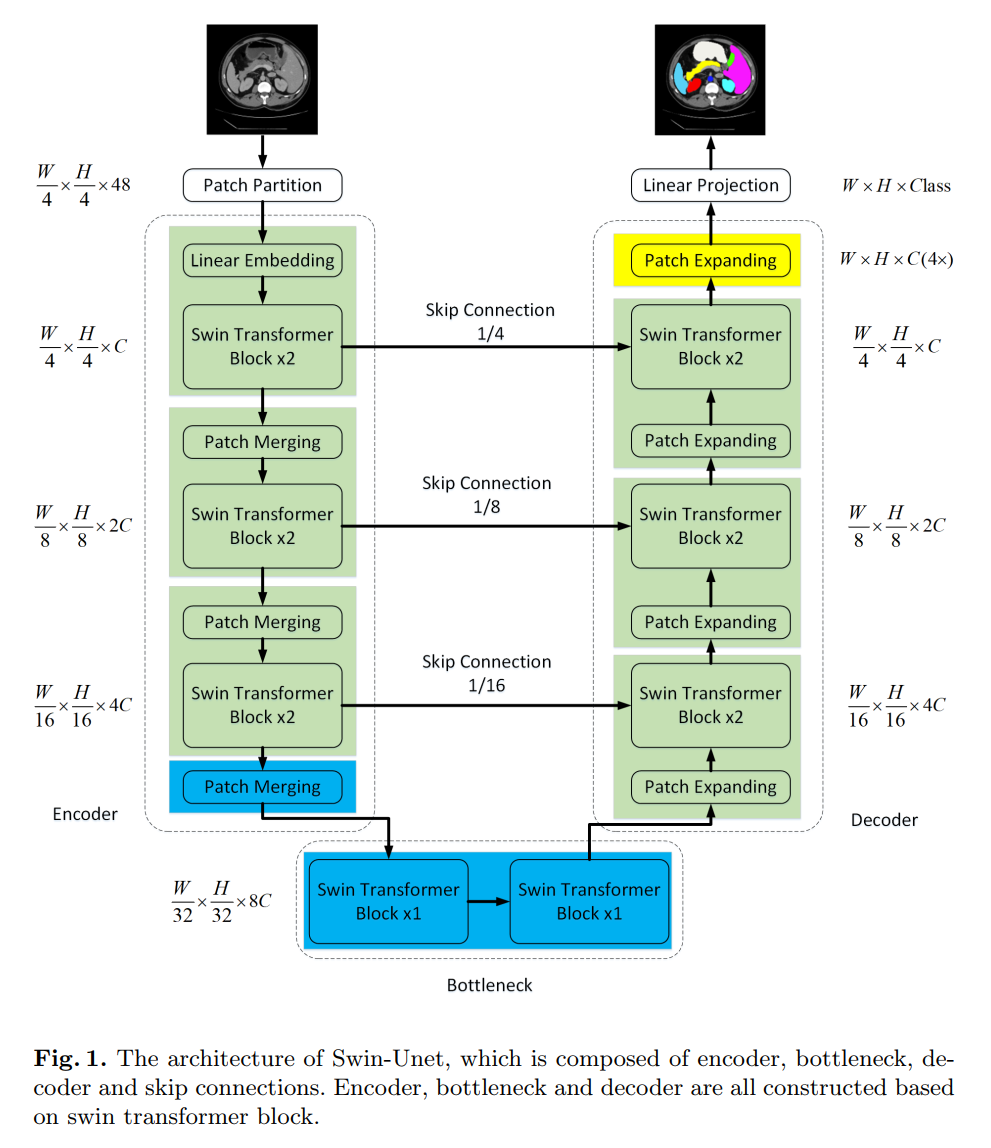
Encoder, Bottleneck以及Decoder都是基于Swin-Transformer block构造的实现。
4.1 Swin Transformer block
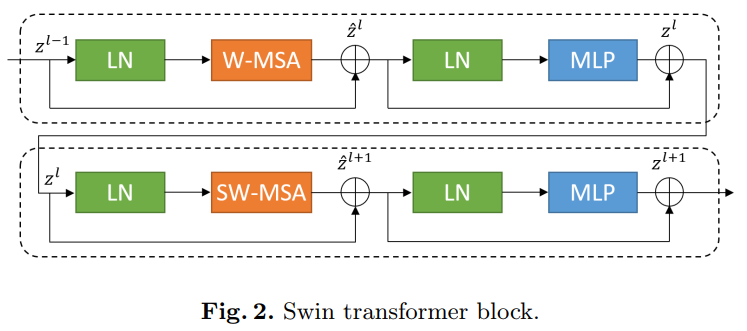
与传统的multi-head self attention(MSA)模块不同,Swin Transformer是基于平移窗口构造的。在图2中,给出了2个连续的Swin Transformer Block。每个Swin Transformer由LayerNorm(LN)层、multi-head self attention、residual connection和2个具有GELU的MLP组成。在2个连续的Transformer模块中分别采用了windowbased multi-head self attention(W-MSA)模块和 shifted window-based multi-head self attention (SW-MSA)模块。基于这种窗口划分机制的连续Swin Transformer Block可表示为:
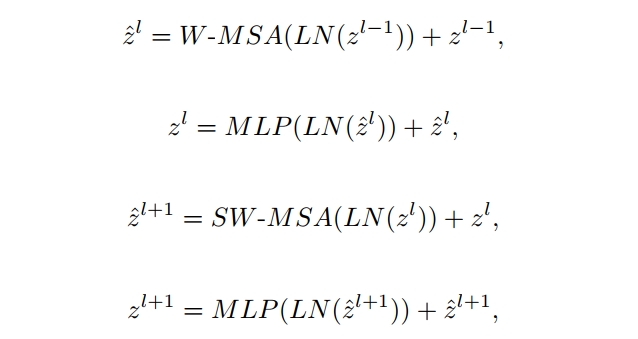
其中,和分别表示(S)W-MSA模块和第块的MLP模块的输出。
与前面的研究ViT类似,self attention的计算方法如下:
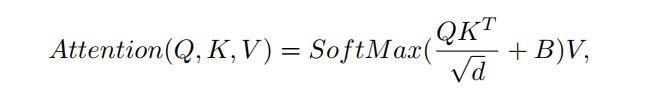
其中,表示query、key和value矩阵。和分别表示窗口中patch的数量和query或key的维度。value来自偏置矩阵。
4.2 Encoder
在Encoder中,将分辨率为的维tokenized inputs输入到连续的2个Swin Transformer块中进行表示学习,特征维度和分辨率保持不变。同时,patch merge layer会减少Token的数量(2×downsampling),将特征维数增加到2×原始维数。此过程将在Encoder中重复3次。
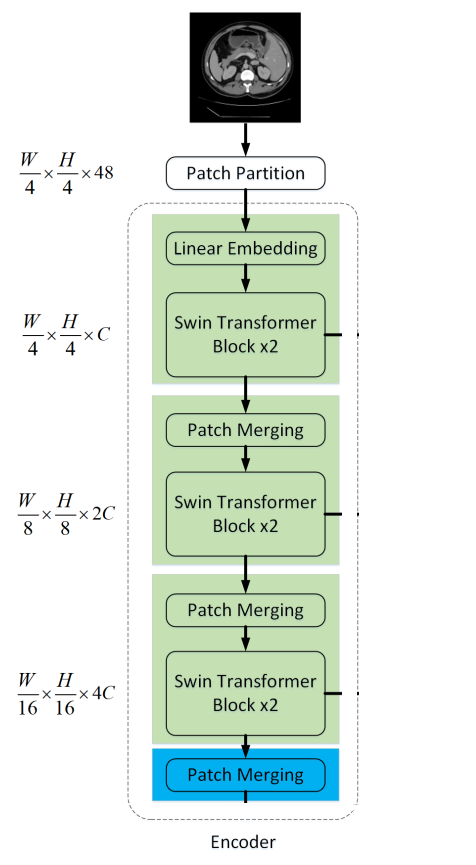
输入patch分为4部分,通过Patch merging layer连接在一起。这样的处理会使特征分辨率下降2倍。并且,由于拼接操作的结果是特征维数增加了4倍,因此在拼接的特征上加一个线性层,将特征维数统一为原始维数的2倍。
4.3 Decoder
与Encoder相对应的是基于Swin Transformer block的Symmetric Decoder。为此,与编码器中使用的patch merge层不同,我们在解码器中使用patch expand层对提取的深度特征进行上采样。patch expansion layer将相邻维度的特征图重塑为更高分辨率的特征图(2×上采样),并相应地将特征维数减半。
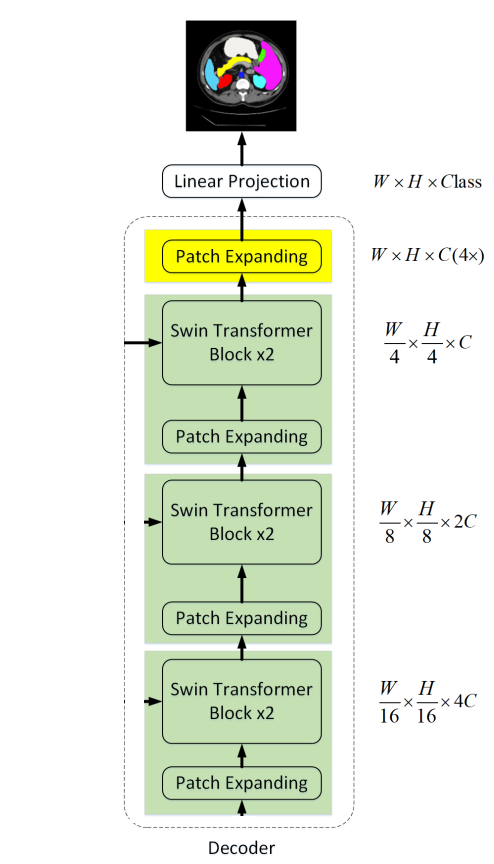
以第1个Patch expanding layer为例,在上采样之前,对输入特征加一个线性层,将特征维数增加到原始维数的2倍。然后,利用rearrange operation将输入特征的分辨率扩大到输入分辨率的2倍,将特征维数降低到输入维数的1/4,即。
针对Encoder中的patch merge层,作者在Decoder中专门设计了Patch expanding layer,用于上采样和特征维数增加。为了探索所提出Patch expanding layer的有效性,作者在Synapse数据集上进行了双线性插值、转置卷积和Patch expanding layer的Swin-Unet实验。实验结果表明,本文提出的Swin-Unet结合Patch expanding layer可以获得更好的分割精度。

5、实验
分割任务是使用Synapse多器官分割数据集(以下简称Synapse)进行的,其中包含30个病例(注意:每个病例大约有3800张图像,因为它们是CT)。结果显示在前面。
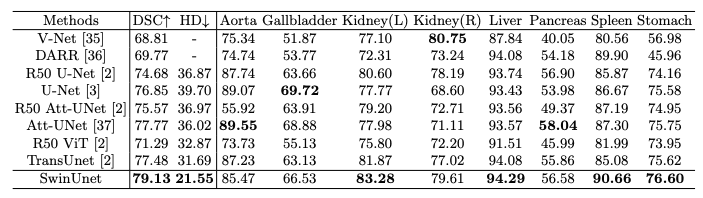
实际使用了八个腹部器官(主动脉、胆囊、脾脏、左肾和右肾、肝脏、胰腺和胃),评估的依据是平均水平。Dice系数(DSC)和平均Hausdorff距离(HD),黑体字的模型是获得最高分的模型,例如Att-UNet在主动脉(Aorta)中表现最好。提出的Swin Unet在左肾、肝脏、脾脏和胃方面取得了最高分,总体平均水平优于现有方法。.
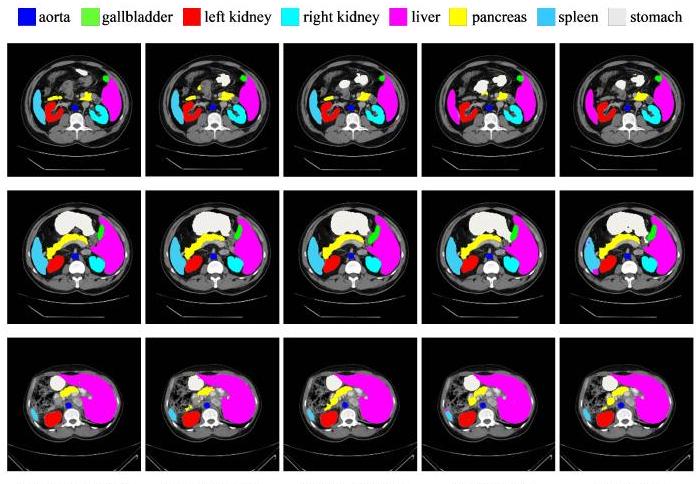
分段的例子如上图所示,从左到右:正确的标签、Swin Unet、TransUNet、AttUnet 和UNet,其中黄色的胰腺由于其平坦性,是一个难以检测的器官;底排显示了胰腺分割的巨大差异。