文章目录
- 前言
- 选择 Paimon 的原因
- Apache Paimon 功能
- 一致性保证
- Paimon 表类型
- 数据湖写入
- 标签和时间线回溯
- 捕获变更数据写入数据湖
- LSM 和分层文件重用
- 流处理案例
- 使用 Paimon 作为消息队列
前言
Apache Flink 自诞生以来经历了重大演变,如今,它不仅充当批处理和流数据处理的统一引擎,而且为迈向新时代铺平了道路:流式数据湖。
Apache Flink 的概念是动态表,与数据库中的物化视图类似,但是,动态表不能直接查询,因此社区提出使用中间表进行查询,就演变出了 Paimon。
选择 Paimon 的原因
为 Apache Flink 提供利用表格式的存储层,以便可以直接访问动态表中的中间数据的方式被称为 Lakehouse 的存储设计,已经成为了业界数据湖的标准。它将对象存储的廉价性与数仓的可扩展性和优化过查询的特性相结合,目前比较出名的有 Apache Iceberg, Delta Lake 和 Apache Hudi。
社区之所以重新创建一个 Paimon 项目,是因为 Paimon 是和 Flink 原生相结合的,可以和 FLink CDC 天然适配。
流式数据湖需要支持一下特性:
- 数据的快速写入
- 变更数据同步更新
- 高效的实时数据分析
而 Paimon 可以提供以下核心功能:
- 统一批处理和流处理: Paimon 支持批量读取和写入,以及流式写入变更数据和流式读取表 changelogs。
- 数据湖作为数据湖存储,Paimon 具有以下优势:低成本、高可靠性、可扩展的元数据。
- merge 引擎: Paimon支持丰富的合并引擎, 默认情况下,保留主键的最后一项。还可以使用“部分更新”或“聚合”引擎。
- Changelog 生成器: Paimon 支持丰富的 Changelog 生成器,例如“lookup”和“full-compaction”。正确的变更日志可以简化流管道的构建。
- Append Only Tables: Paimon支持Append Only表,自动压缩小文件,并提供有序的流读取。可以使用它来替换消息队列。
所有这些特性使 Lakehouse 能够以流优先设计的方式发展,从而产生了Streamhouse。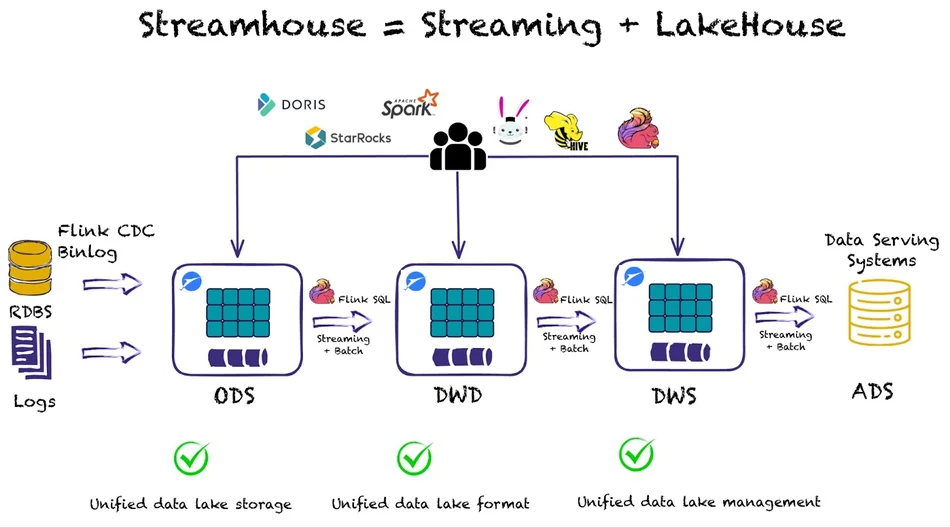
Streamhouse 架构结合了用于流处理的 Apache Flink 和作为流存储层的 Apache Paimon。
Streamhouse 的核心思想是使用一行语句以一种轻松简单的方式,将来自 CDC 的 ETL 的数据或者日志数据,以流式传输的方式加载至廉价的对象存储中。
当数据进入数据湖时,用户可以创建不同的作业来创建不同的业务层 - 即 ODS、DWD、DWS 和 ADS - 在数据流动时负责更新。
同时,因为数据湖中的数据可以直接访问,我们可以在上层应用中添加任何想要的查询引擎——OLAP 系统(如 Apache Doris 和 StarRocks)或查询引擎(如 Flink SQL、Spark、Trino 或 Hive)—— 来运行批量或增量查询动态表快照的任务。
Apache Paimon 功能
我们需要先了解一些 Paimon 的基本概念,才能更好的理解 Paimon 功能:
快照
- 快照捕获表在某个时间点的状态。用户可以通过最新的快照访问表的最新数据,并利用时间线回溯通过较早的快照访问表的先前状态。
分区
- Paimon 采用与 Apache Hive 相同的分区概念来分离数据。
- 分区是一种可选方法,可根据日期、城市和部门等特定列的值将表划分为相关部分。每个表可以有一个或多个分区键来标识特定分区。
- 通过分区,用户可以高效地操作表中的一片记录。
桶
- 未分区表或分区表中的分区被细分为存储桶,为数据提供额外的结构,以便更有效地查询。
- 桶是读写的最小存储单元,因此桶的数量决定了最大处理并行度。
一致性保证
Paimon 写入使用两阶段提交协议以原子方式将一批记录提交到表中,每次提交最多产生两个快照。
对于任意多个同时修改表的写入任务,只要不修改同一个桶,任务可以并行提交写入数据。如果修改同一个桶,则仅保证快照隔离。最终表状态可能是两次提交的混合结果,但不会丢失任何更改。
Paimon 使用快照提供对任何表的不同版本的访问,并将数据文件分组到分区和存储桶中,并保证一致性。
它利用了一个LSM(Log-Structured Merge Tree)数据结构实现流数据的性能。每个存储桶基本上包含一个 LSM 树及其变更日志文件。
下图显示了 Paimon 的文件布局以及所有文件内容是如何组合在一起: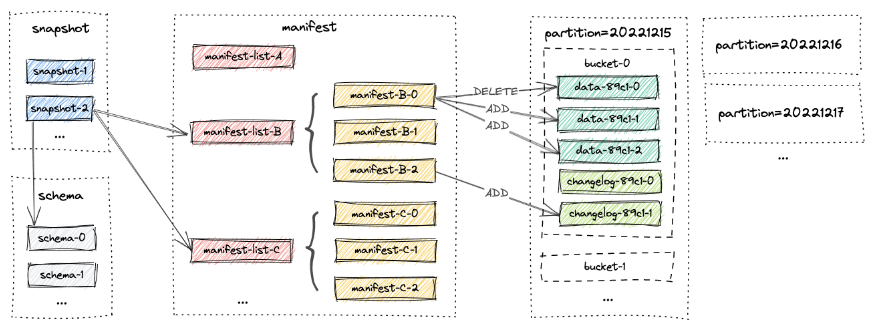
Paimon 表类型
主键表
这是一个基本的 cahngelog 表,默认表类型,用户可以在表中插入、更新或删除记录。
主键由一组包含每个记录的唯一值的列组成,Paimon 通过对每个存储桶内的主键进行排序来强制数据排序,允许用户通过对主键应用过滤条件来实现高性能查询。
由于该表用于存储changelogs 流,因此当具有相同主键的两个或多个记录到达时, Paimon 提供各种 Merge 引擎。
仅追加表
仅追加表是没有主键的表。该表只允许插入操作。不支持删除或更新操作。此类表适合不需要更新的用例,例如日志数据同步。
外部日志系统
除了上述的表类型之外,Paimon 还支持外部日志系统。当使用外部日志系统并将数据写入数据湖时,数据也会写入到Kafka等系统中。如果使用外部日志系统,表文件和日志系统会记录所有写入,但流式查询产生的更改将来自日志系统而不是表文件。
数据湖写入
掌握了一些核心概念后,让我们换个角度来看看 Apache Paimon 的核心功能。
正如已经提到的,Paimon 通过利用分区和存储桶将数据写入数据湖,其中每个存储桶都包含一个 LSM 树。写入数据时,它允许创建标签(我们将在稍后详细解释),并且 LSM 分层结构允许文件重用,以优化性能并减少许多文件的创建。与其他架构相比,它不需要定义分区表,只需要一个主键。
这些表可以低延迟地实时流式传输,并允许实时查询、批量查询和增量查询。数据湖写入的参数调整具有很大的灵活性,允许用户在写入性能、查询性能和存储放大之间取得平衡。
例如,当知道任务执行存在资源压力时,可以选择Paimon的动态桶模式或设置合适的桶大小。如果资源压力持续存在,可以调整 checkpoint 间隔,或调整 Paimon 压缩参数,这样就不会阻塞,并确保更好的写入性能。
总体而言,Paimon 的可配置性很高,允许用户根据流式读取、批量读取和更新场景进行权衡。
标签和时间线回溯
Apache Paimon 利用标签的概念来允许访问不同的离线视图。离线视图基本上是表在某个时间点的快照,允许历史数据查询。标签允许用户及时回溯到表的先前版本。
标签可以自动创建和过期,并且基于快照。该标签将维护快照的清单和数据文件。
以下代码片段演示了在创建表时,用户可以指定自动创建的标签,例如每天生成一个标签,标签过期时间90天:
CREATE TABLE MyTable (
id INT PRIMARY KEY NOT ENFORCED,
...
) WITH (
'tag.automatic-creation' = 'processing-time',
'tag.creation-period' = 'daily',
'tag.creation-delay' = '10 m',
'tag.num-retained-max' = '90'
);
INSERT INTO MyTable SELECT * FROM kafkaTable;
-- Read latest snapshot
SELECT * FROM MyTable;
-- Read Tag snapshot
SELECT * FROM MyTable VERSION AS OF '2023-07-26';
-- Read Incremental data between Tags
SELECT * FROM MyTable paimon_incremental_query ('2023-07-25', '2023-07-26');
当在快照上创建这些标签时,它们将一直保留到过期策略生效(如果指定)。
捕获变更数据写入数据湖
Apache Paimon 最重要的功能之一是捕获变更数据写入数据湖,Paimon 集成了Flink CDC, 支持多种数据源的变更数据捕获。
一般在捕获变更数据写入时,很难同时从大型表中读取历史数据以及增量变更数据。
同时,我们需要一种增量读取大表的方法,并且当数据库包含数百或数千个表时,最大限度地减少与数据库的连接,才不会给系统带来太大压力。
Flink CDC 可以利用项目独有的增量快照算法来实现这一目标: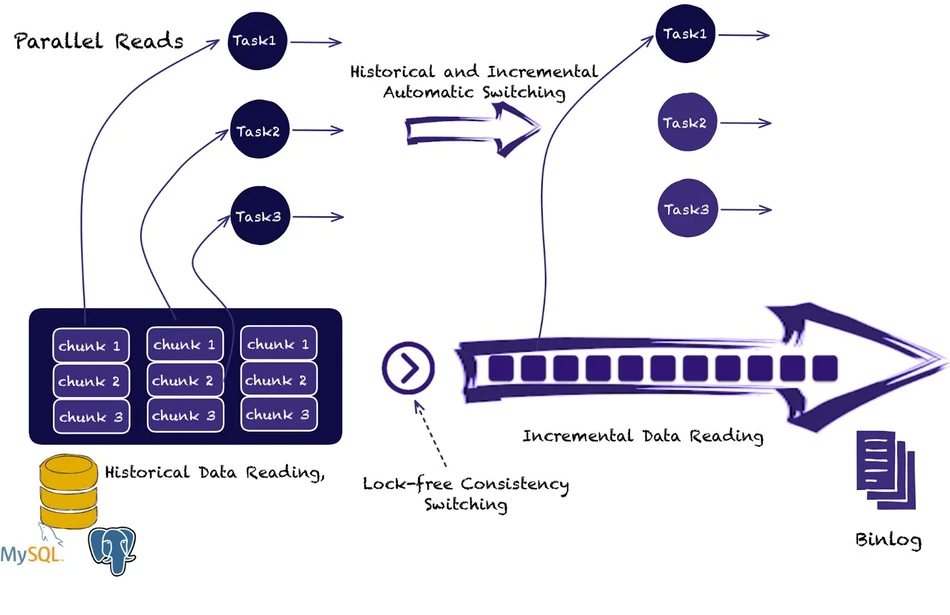
它读取历史数据,然后在不锁定数据库的情况下自动从Binlog中继续读取增量更改。如图所示,增量快照算法允许将大表分割成更小的块并并行读取它们。当自动切换发生时,只需要一项任务来读取增量变化。
目前 Paimon 已经支持 MySQL 和 MongoDB, Kafka 的 CDC。
LSM 和分层文件重用
接下来我们看一下Paimon LSM文件存储的复用: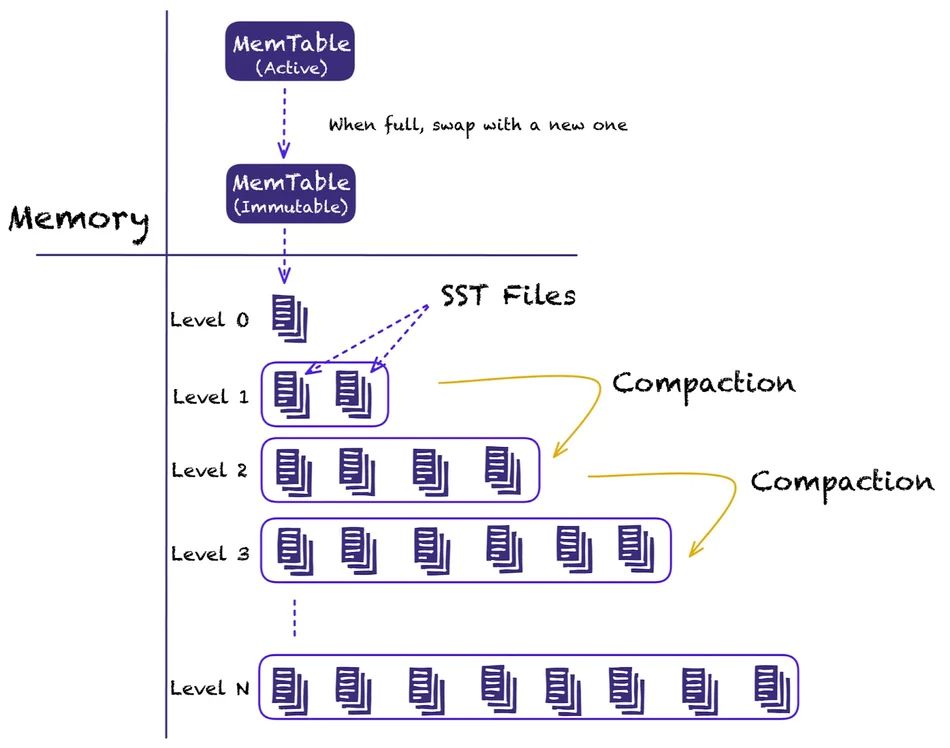
Paimon 利用 LSM(日志结构化合并树)进行文件存储,并使用类似于 RocksDB 的分级压缩。 LSM数据结构的一个特点是,当增量数据到达时,并不一定需要合并到下层。
这允许较低级别的文件在两个标签之间重用,因为它们并不会总是受到压缩的影响。
流处理案例
Paimon 有三种流连接方式,双流连接、查询连接和增量更新(利用序列组):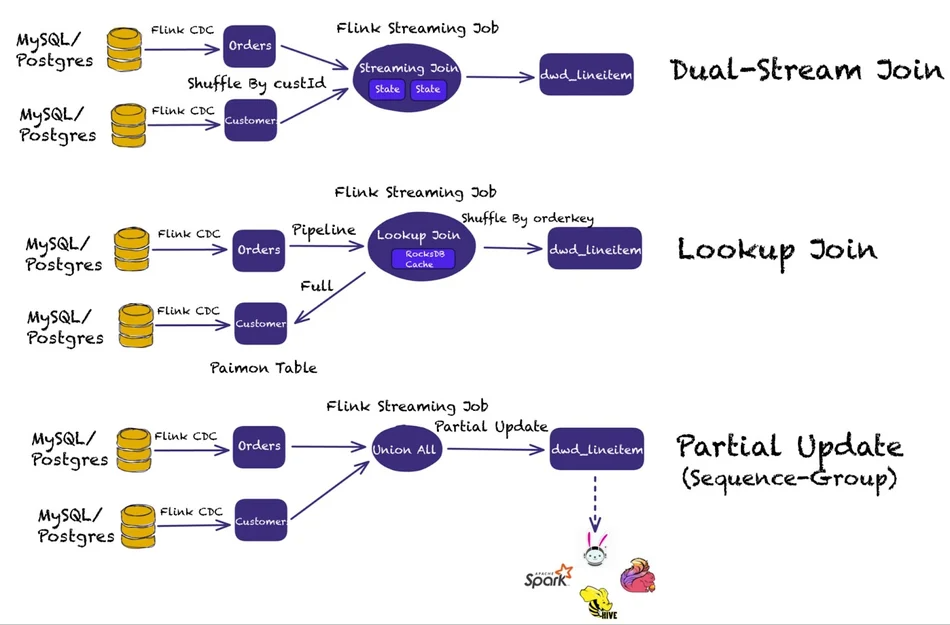
双流连接要求流连接查询的两侧都保存在内存中,当状态变得太大时,运行连接的成本也会增加。 Paimon 一般直接从数据湖存储中查询数据。
Lookup Join允许通过 Flink Lookup Join 执行 Paimon 表的查找。使用查找连接时要记住的一件事是,更新维度表时,更改不会反映到下游。
部分增量更新 使用Sequence-Groups,使每个字段能够使用不同的更新方法,并且还支持各种合并引擎。它提供高吞吐量和近实时级别的延迟。
例如,假设 Paimon 收到三个记录:
- <1, 23.0, 10, NULL>
- <1,NULL,NULL,‘这是一本书’>
- <1、25.2、NULL、NULL>
假设第一列为主键,则最终结果为:
<1, 25.2, 10, ‘这是一本书’>
使用 Paimon 作为消息队列

由于Paimon是面向实时处理的,所以有人难免会比较Paimon和Kafka架构,毕竟 Paimon在这方面也做了很多工作。
例如,它支持Append-only表,允许创建没有主键的表,只指定桶号。
桶类似于 Kafka 中的分区,它们提供严格的顺序保存,与Kafka的消息排序相同,但它们也支持Watermarks和Watermark对齐。同时,还支持Consumer ID。
写入过程中,可以自动合并小文件。
因此,从上图可以看出,其整体架构允许用户在某些用例下用Paimon替换Kafka。
Kafka 的真正能力是提供秒级的延迟。当业务用例不需要秒级延迟时,可以考虑使用Paimon来实现消息队列功能。
Apache Paimon 通常以分钟级延迟运行,因为写入数据湖取决于checkpoint 间隔。建议的checkpoint 间隔通常为一分钟,以避免生成许多影响查询性能的小文件。