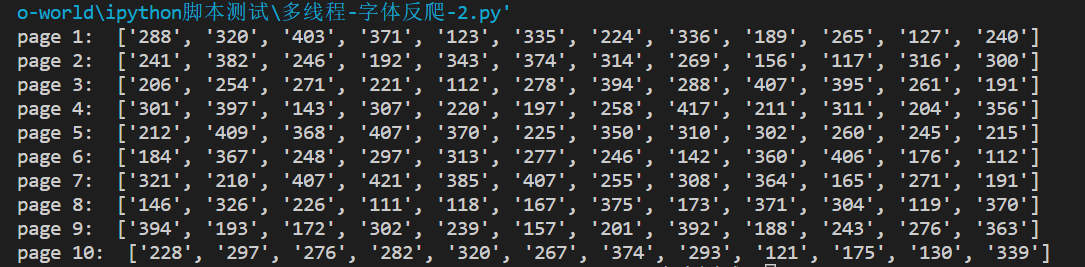
趁热打铁来写字体反爬的第二篇,首先是题目

网页上显示的不是常规的数字,源码里面也是一些汉字
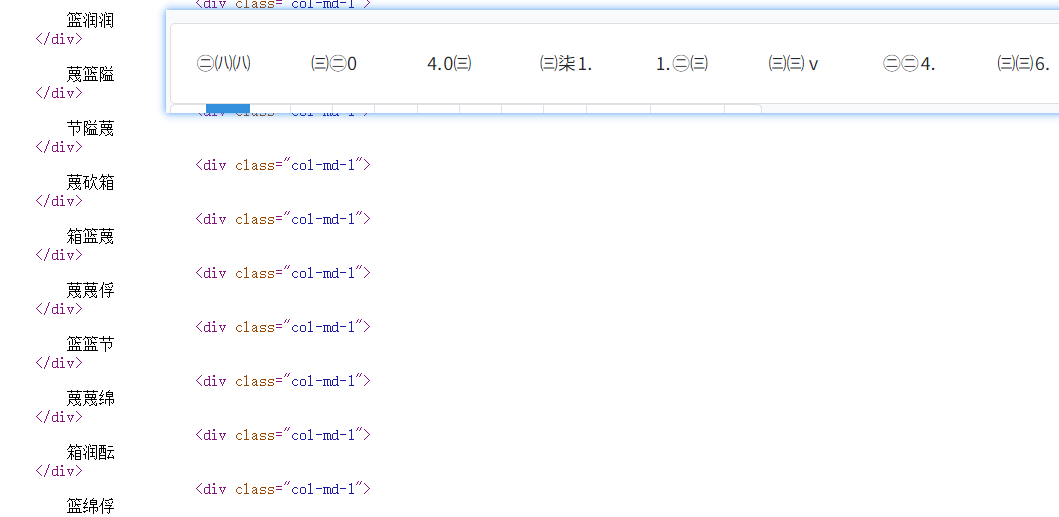
虽然看上去很乱,但是仔细观察还是能发现一些规律,比如:长 对应 2,思对应 1
所以这里的解题思路,也是先找到这些汉字的映射表
还是像第一题那样,把网页里面的base64保存成本地的ttf文件,然后打开查看:

这里不再是像第一题的英文单词,而是 uni601D 这样形似 unicode 编码的,解码一下试试
In [10]: a
Out[10]: '\\u601D'
In [11]: a.encode("latin-1").decode("unicode_escape")
Out[11]: '思'
unicode_escape是一种编码集,类似utf-8,这种编码集直接将unicode内存编码存储进文件。参考:https://blog.csdn.net/qq_40728667/article/details/122282693
各个编码单字节的外围:ASCII(0-127), LATIN1(0-255), UTF8(0-253)
参考:https://blog.csdn.net/liuhhaiffeng/article/details/80162033
和源码中的汉字是一致的,那么我们只要拿到前面十个unicode编码,解码出它们对应的汉字,然后就能根据顺序得出每个汉字对应的数字
def parse_ttf():
"""
构造汉字到数字的映射
"""
font = TTFont("page-1.ttf")
name_list = font["cmap"].tables[0].ttFont.getGlyphOrder()
unicode_list = ["\\u" + c[-4:] for c in name_list[1:11]]
cha2num = {}
for index, u in enumerate(unicode_list):
c = u.encode("latin-1").decode("unicode_escape")
cha2num[c] = str(index)
return cha2num
同一个汉字不同unicode?
从ttf提取的汉字,可能会出现和网页的汉字对不上的情况
比如网页的是 鼻 ,ttf的是 ⿐,两者看起来相似,但是unicode码是不同的
In [1]: '鼻'.encode('unicode_escape')
Out[1]: b'\\u9f3b'
In [2]: '⿐'.encode('unicode_escape')
Out[2]: b'\\u2fd0'
这里有解释这种现象
产生的具体原因我找了很久也没找到,猜测是网页在自动utf8解码的时候,把汉字转换错了
为了应对这种情况,我之前有专门整理大部分这些生僻字的映射,基本可以解决这道题出现的所有情况
Unicode基本汉字、部首扩展、康熙部首对照字典_银古 | cxs的博客-CSDN博客_unicode 常用汉字
{
"⼀": "一",
"⼄": "乙",
"⼆": "二",
"⼈": "人",
"⼉": "儿",
"⼊": "入",
"⼋": "八",
"⼏": "几",
"⼑": "刀",
"⼒": "力",
"⼔": "匕",
"⼗": "十",
"⼘": "卜",
"⼚": "厂",
"⼜": "又",
"⼝": "口",
"⼞": "口",
"⼟": "土",
"⼠": "士",
"⼤": "大",
"⼥": "女",
"⼦": "子",
"⼨": "寸",
"⼩": "小",
"⼫": "尸",
"⼭": "山",
"⼯": "工",
"⼰": "己",
"⼲": "干",
"⼴": "广",
"⼸": "弓",
"⼼": "心",
"⼽": "戈",
"⼿": "手",
"⽀": "支",
"⽂": "文",
"⽃": "斗",
"⽄": "斤",
"⽅": "方",
"⽆": "无",
"⽇": "日",
"⽈": "曰",
"⽉": "月",
"⽊": "木",
"⽋": "欠",
"⽌": "止",
"⽍": "歹",
"⽏": "毋",
"⽐": "比",
"⽑": "毛",
"⽒": "氏",
"⽓": "气",
"⽔": "水",
"⽕": "火",
"⽖": "爪",
"⽗": "父",
"⽚": "片",
"⽛": "牙",
"⽜": "牛",
"⽝": "犬",
"⽞": "玄",
"⽟": "玉",
"⽠": "瓜",
"⽡": "瓦",
"⽢": "甘",
"⽣": "生",
"⽤": "用",
"⽥": "田",
"⽩": "白",
"⽪": "皮",
"⽫": "皿",
"⽬": "目",
"⽭": "矛",
"⽮": "矢",
"⽯": "石",
"⽰": "示",
"⽲": "禾",
"⽳": "穴",
"⽴": "立",
"⽵": "竹",
"⽶": "米",
"⽸": "缶",
"⽹": "网",
"⽺": "羊",
"⽻": "羽",
"⽼": "老",
"⽽": "而",
"⽿": "耳",
"⾁": "肉",
"⾂": "臣",
"⾃": "自",
"⾄": "至",
"⾆": "舌",
"⾈": "舟",
"⾉": "艮",
"⾊": "色",
"⾍": "虫",
"⾎": "血",
"⾏": "行",
"⾐": "衣",
"⾒": "儿",
"⾓": "角",
"⾔": "言",
"⾕": "谷",
"⾖": "豆",
"⾚": "赤",
"⾛": "走",
"⾜": "足",
"⾝": "身",
"⾞": "车",
"⾟": "辛",
"⾠": "辰",
"⾢": "邑",
"⾣": "酉",
"⾤": "采",
"⾥": "里",
"⾦": "金",
"⾧": "长",
"⾨": "门",
"⾩": "阜",
"⾪": "隶",
"⾬": "雨",
"⾭": "青",
"⾮": "非",
"⾯": "面",
"⾰": "革",
"⾲": "韭",
"⾳": "音",
"⾴": "页",
"⾵": "风",
"⾶": "飞",
"⾷": "食",
"⾸": "首",
"⾹": "香",
"⾺": "马",
"⾻": "骨",
"⾼": "高",
"⿁": "鬼",
"⿂": "鱼",
"⿃": "鸟",
"⿄": "卤",
"⿅": "鹿",
"⿇": "麻",
"⿉": "黍",
"⿊": "黑",
"⿍": "鼎",
"⿎": "鼓",
"⿏": "鼠",
"⿐": "鼻",
"⿒": "齿",
"⿓": "龙",
"⼣": "夕",
"⺁":"厂",
"⺇":"几",
"⺌":"小",
"⺎":"兀",
"⺏":"尣",
"⺐":"尢",
"⺑":"𡯂",
"⺒":"巳",
"⺓":"幺",
"⺛":"旡",
"⺝":"月",
"⺟":"母",
"⺠":"民",
"⺱":"冈",
"⺸":"芈",
"⻁":"虎",
"⻄":"西",
"⻅":"见",
"⻆":"角",
"⻇":"𧢲",
"⻉":"贝",
"⻋":"车",
"⻒":"镸",
"⻓":"长",
"⻔":"门",
"⻗":"雨",
"⻘":"青",
"⻙":"韦",
"⻚":"页",
"⻛":"风",
"⻜":"飞",
"⻝":"食",
"⻡":"𩠐",
"⻢":"马",
"⻣":"骨",
"⻤":"鬼",
"⻥":"鱼",
"⻦":"鸟",
"⻧":"卤",
"⻨":"麦",
"⻩":"黄",
"⻬":"齐",
"⻮":"齿",
"⻯":"竜",
"⻰":"龙",
"⻳":"龟",
"⾅":"臼",
"⼝":"口",
"⼾":"户",
"⼉":"儿",
"⼱":"巾"
}
代码整理
# -*- coding:utf-8 -*-
from io import BytesIO
from hanzi_mappings import hz_maps
import requests
import base64
from parsel import Selector
from fontTools.ttLib import TTFont
def parse_ttf(b64_str):
"""
构造汉字到数字的映射
"""
content = base64.b64decode(b64_str)
# with open("page.ttf", "wb") as f:
# f.write(content)
font = TTFont(BytesIO(content))
name_list = font["cmap"].tables[0].ttFont.getGlyphOrder()
unicode_list = ["\\u" + c[-4:] for c in name_list[1:11]]
cha2num = {}
for index, u in enumerate(unicode_list):
c = u.encode("latin-1").decode("unicode_escape")
cha2num[c] = str(index)
return cha2num
def parse_html(html_text):
dom = Selector(text=html_text)
b64_str = dom.css("style::text").re_first(r"base64,(.+?)\)")
mappings = parse_ttf(b64_str)
fake_strings = dom.css(".col-md-1::text").re(r"\s+(.+)\s+")
for string in fake_strings:
real_num = ""
for c in string:
try:
n = mappings[c]
except KeyError as e:
n = mappings[hz_maps[c]]
real_num += n
yield real_num
def glidedsky_login():
"""
网站登录,才能看到题目
注意题目域名也必须是 www.glidedsky.com
"""
EMAIL = ""
PASSWORD = ""
LOGIN_URL = "http://www.glidedsky.com/login"
session = requests.session()
resp = session.get(LOGIN_URL)
dom = Selector(resp.text)
_token = dom.css("meta[name='csrf-token']::attr(content)").get()
form_data = {
"_token": _token,
"email": EMAIL,
"password": PASSWORD,
}
session.post(LOGIN_URL, data=form_data)
return session
def main():
session = glidedsky_login()
for page in range(1, 11):
url = "http://www.glidedsky.com/level/web/crawler-font-puzzle-2?page=" + str(
page
)
resp = session.get(url)
print(
f"page {page}: ",
[num for num in parse_html(resp.content.decode())],
)
if __name__ == "__main__":
main()
-
直接从源码截取的base64,可能会长度不够,报错:Incorrect padding,需要补齐成4的整倍数
-
hz_maps即是上面整理的那个汉字映射
运行结果