DePT: Decoupled Prompt Tuning 了论文阅读
- Abstract
- 1. Introduction
- 2. Methodology
- 2.1. Preliminaries
- 2.2. A Closer Look at the BNT Problem
- 2.3. Decoupled Prompt Tuning
- 3. Experiments
- 5. Conclusions
文章信息:

原文链接:https://arxiv.org/abs/2309.07439
源码:https://github.com/Koorye/DePT
Abstract
这项工作突破了提示调整中的基础-新任务权衡(BNT)困境,即调整后的模型对基础(或目标)任务的泛化效果越好,对新任务的泛化效果就越差,反之亦然。具体来说,通过对基础任务和新任务学到的特征进行深入分析,我们观察到BNT源于通道偏置问题 - 绝大多数特征通道被基础特定知识所占据,导致了对新任务重要的任务共享知识的崩溃。为了解决这个问题,我们提出了Decoupled Prompt Tuning (DePT) 框架,它在提示调整过程中将基础特定知识与特征通道分离到一个孤立的特征空间中,以便在原始特征空间中最大程度地保留任务共享知识,从而实现对新任务的更好的零样本泛化。重要的是,我们的DePT与现有的提示调整方法正交,可以在几乎没有额外计算成本的情况下增强它们。在多个数据集上的大量实验显示了DePT的灵活性和有效性。代码可在https://github.com/Koorye/DePT 找到。
1. Introduction
近年来,大型视觉语言预训练模型(VLPMs)取得了显著的进展。其中一个引人注目的成功是由对比语言-图像预训练(CLIP)[38]模型取得的,该模型将学习目标规定为对比损失,以在一个共同的特征空间中建立图像和它们的文本描述之间的对齐。尽管能够捕捉开放式视觉概念,但在上游训练数据和下游任务之间存在严重的类别转移、分布转移或域转移时,VLPMs的零样本泛化性能会大大降低。
受NLP中提示工程成功的启发,提示调整(或称为上下文优化[58])已经成为一种参数高效的学习范式,将强大的VLPMs适应于下游任务,通过优化一个任务特定的提示(即一组可训练向量),利用来自基础(目标)任务的少量训练数据,同时保持VLPMs的权重冻结。尽管这种方法的优势显著,但现有的提示调整方法通常无法摆脱基础-新任务权衡(BNT)困境,即调整/适应模型对基础任务的泛化能力越好,对新任务(具有未见类别)的泛化能力就越差,反之亦然。近年来,已经投入大量的努力[49, 57, 59]来减轻提示调整过程中调整模型在新任务上性能下降的问题,通过开发抗过拟合策略。然而,BNT问题仍然远未解决,其潜在机制也尚未得到充分理解。
在这项工作中,我们提出了Decoupled Prompt Tuning(DePT)框架,首次从特征解耦的角度解决了提示调整中的BNT问题,弥合了这一差距。具体来说,通过对标准的图像文本匹配(ITM)头学习的基础和新任务的特征通道进行深入分析,我们发现BNT源于通道偏置问题:绝大多数特征通道被基础特定知识(即基础任务的任务特定知识)所占据,导致了对新任务重要的任务共享知识的崩溃(第2.2节)。受此启发,解决BNT问题的直接策略是在提示调整过程中解耦特征通道中的基础特定知识和任务共享知识。为了实现这一点,我们引入了一个Channel Adjusted Transfer(CAT)头,以鼓励在一个孤立的特征空间中从特征通道中挖掘基础特定知识,从而促进在原始特征空间中保留任务共享知识,并提高在新任务上的零样本泛化性能(第2.3节)。此外,在推理过程中简单地融合两个特征空间中的基础特定知识和任务共享知识,我们显著提高了基础任务的性能(第3.2节)。
Flexibility and Effectiveness.
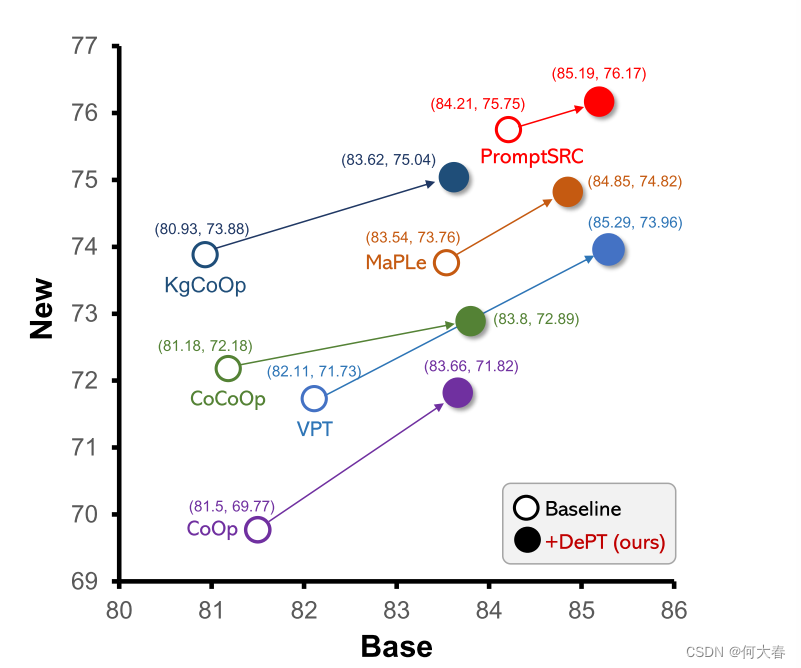
图1. 六种提示调整方法在基础(或已见)和新(或未见)任务上,经过11个数据集的平均分类准确率,使用或不使用我们的DePT框架。
我们的DePT框架与现有的提示调整方法正交,因此可以灵活地用于克服它们的BNT问题。我们使用广泛的基线方法对DePT进行评估,包括视觉提示调整方法VPT [21],文本提示调整方法CoOp [58],CoCoOp [57]和KgCoOp [49],以及多模型提示调整方法MaPLe [25],PromptSRC [26]。在11个不同的数据集上的实验结果表明,DePT始终提高了这些方法的性能,无论基础任务和新任务之间是否存在类别转移、分布转移或域转移,都表明了DePT的强大灵活性和有效性(第3.3节)。值得注意的是,DePT在不牺牲基础任务和新任务性能的情况下增强了这六个基线方法 - 在这11个数据集上,DePT在基础任务(新任务)上平均取得了1.31%∼3.17%(分别为0.71%∼2.23%)的绝对收益(图1)。
Contributions.我们的主要贡献有三个方面。
1)我们对提示调整中的BNT问题进行了深入分析,首次揭示了BNT源于通道偏置问题,这为我们提供了深刻的见解。
2)我们提出了DePT框架,从特征解耦的角度解决了BNT问题,并且DePT与现有的提示调整方法正交。
3)我们在11个不同的数据集上进行了实验,并展示了DePT始终提升了广泛基线方法的性能。
2. Methodology
在本节中,我们首先对提示调整中的BNT问题进行了深入的审视,随后详细阐述了我们提出的DePT框架。
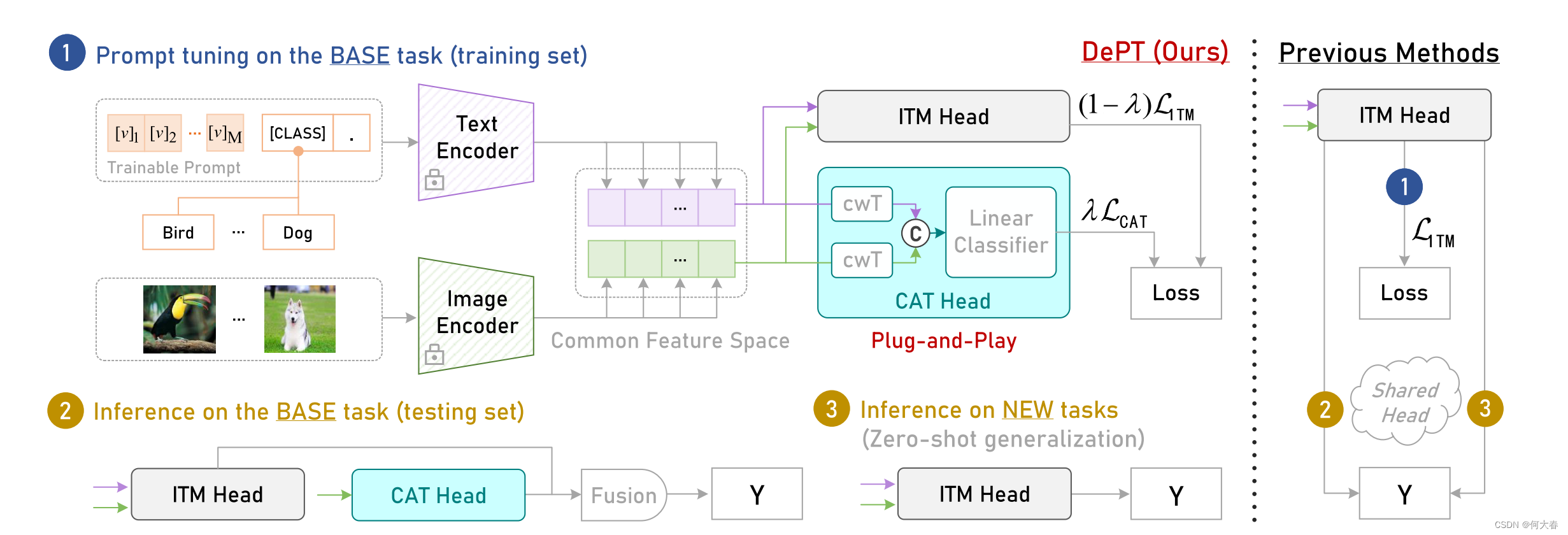
图2. 我们的DePT框架示意图(以CoOp [58]风格呈现)。与之前的方法(右侧)在基础任务的训练/推断和新任务的零样本泛化中使用相同的图像文本匹配(ITM)头不同,我们的DePT(左侧)采用通道调整传输(CAT)头在隔离的特征空间中捕获基础特定知识,从而最大限度地保留原始特征空间中的任务共享知识,以改善对新任务的零样本泛化。在推断阶段,我们通过简单地融合两个头获得的基础特定和任务共享知识,进一步提高了基础任务的性能。©表示连接操作。
2.1. Preliminaries
Contrastive Language-Image Pre-training (CLIP) [45].CLIP的目标是学习图像编码器和文本编码器分别生成的图像和文本特征之间的对齐。在看到了4亿个图像-文本关联对并在一个共同的特征空间中执行对比学习范式之后,CLIP捕获了各种开放式视觉概念,可以轻松地推广到下游应用中。例如,我们可以通过将分类任务规定为图像-文本匹配问题来实现零样本分类。具体来说,我们首先构建一个提示(例如,“一张照片”),通过将类扩展的提示(例如,“一张照片[CLASS]”)输入文本编码器,获得所有内部任务类别的文本特征。然后,我们使用图像编码器获得输入示例的图像特征,并通过比较图像特征和类别的文本特征之间的余弦距离来预测示例的类别。
Prompt Tuning with the Image-Text Matching Head.与使用手工制作的提示(例如,“一张照片”)不同,提示调整旨在使用来自基础(或目标)任务的少量训练数据学习一个任务特定的提示。设
[
v
]
1
[
v
]
2
.
.
.
[
v
]
l
[v]_1[v]_2...[v]_l
[v]1[v]2...[v]l表示
l
l
l个可训练向量,我们将类扩展的提示
c
i
=
[
v
]
1
[
v
]
2
.
.
.
[
v
]
l
[
c_i=[v]_1[v]_2...[v]_l[
ci=[v]1[v]2...[v]l[CLASS]输入文本编码器
g
(
⋅
)
g(\cdot)
g(⋅)以获得第
i
i
i个类别的文本特征:
g
(
c
i
)
g(\boldsymbol{c}_i)
g(ci)。设
f
\boldsymbol{f}
f表示通过图像编码器获得的示例
x
x
x的图像特征,则可以使用一个无参数的图像-文本匹配(ITM)头来优化任务特定的提示,其将学习目标规定为:
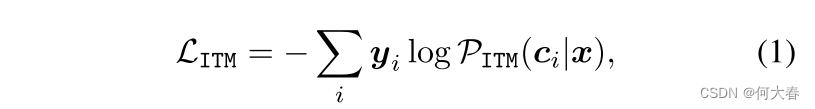
其中,
y
y
y是一个one-hot label
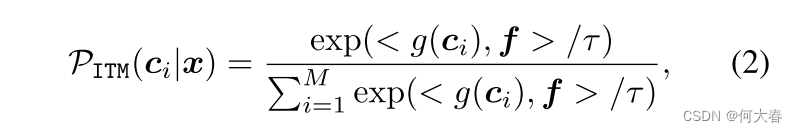
<
⋅
>
<\cdot>
<⋅>表示余弦相似度,
M
M
M是类别的数量,
τ
\tau
τ是由CLIP学习的温度。在训练过程中,ITM头中计算的梯度可以通过文本编码器
g
(
⋅
)
g(\cdot)
g(⋅)一直反向传播,以优化提示中的可训练向量。
2.2. A Closer Look at the BNT Problem
由于BNT问题,将预训练模型调整到基础任务 T b a s e \mathcal{T}_\mathrm{base} Tbase会降低模型在新任务 T n e w \mathcal{T}_\mathrm{new} Tnew上的泛化能力,反之亦然。在这部分中,我们提供了一个深入的视角来分析BNT问题。
Deriving an Oracle Model on T b a s e \mathcal{T}_\mathrm{base} Tbase and T n e w \mathcal{T}_\mathrm{new} Tnew.我们通过在提示调整期间将预训练模型联合训练到两个任务的数据上,从而开始研究BNT问题。因此,得到的Oracle模型可以被视为一个不受BNT影响的模型的近似,因为它避免了对 T b a s e \mathcal{T}_\mathrm{base} Tbase或 T n e w \mathcal{T}_\mathrm{new} Tnew的过拟合。这里我们使用“oracle”这个词,因为该模型是通过利用新任务的数据来推导的,而这些数据在提示调整中是不可访问的。
Calculating Channel Importance for
T
b
a
s
e
\mathcal{T}_\mathrm{base}
Tbase and
T
n
e
w
\mathcal{T}_\mathrm{new}
Tnew.将
x
j
x_j
xj示例在学习特征空间中的
d
d
d维图像特征和文本特征表示为
f
j
f_j
fj和
e
∗
∈
{
e
i
=
g
(
c
i
)
}
i
=
1
M
e_*\in\{e_i=g(\boldsymbol{c}_i)\}_{i=1}^M
e∗∈{ei=g(ci)}i=1M,分别。我们计算每个任务的
T
b
a
s
e
\mathcal{T}_\mathrm{base}
Tbase和
T
n
e
w
\mathcal{T}_\mathrm{new}
Tnew的第
r
r
r个
(
r
=
1
,
.
.
.
,
d
)
(r=1,...,d)
(r=1,...,d)特征通道的通道重要性(CI),如下所示:
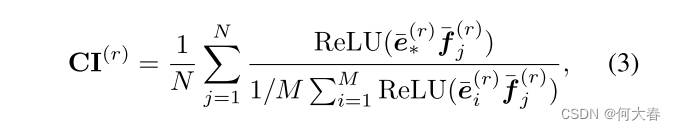
其中
⋅
ˉ
=
⋅
/
∣
∣
⋅
∣
∣
2
,
N
\bar{\cdot}=\cdot/||\cdot||_2,N
⋅ˉ=⋅/∣∣⋅∣∣2,N是任务中的样本数。
ReLU[1]用于避免分母等于0。
得到的方程(3)具有直观的解释:如果一个特征通道能更好地区分任务中的类别,即图像特征与实际文本特征接近,并且与该通道上其他类别的文本特征相距较远,则该特征通道的重要性更高。
Analysis.通过标准的提示调整范式学习的模型与通过推导的Oracle模型在计算的Tbase和Tnew的CI分布方面有什么区别?为了回答这个问题,我们以CoOp [58]作为基线方法,绘制了FGVCAircraft [32]和EuroSAT [14]数据集上CoOp和Oracle模型的测试数据的 T b a s e \mathcal{T}_\mathrm{base} Tbase和 T n e w \mathcal{T}_\mathrm{new} Tnew的CI分布图(详见补充资料(A))。从图中观察到,与CoOp获得的CI分布相比,Oracle模型获得的基础任务和新任务的CI分布显示出更大的一致性。具体来说,从CoOp在( a)( c)中的结果可以看出,在绝大多数特征通道上,新任务的CI值明显低于基础任务的CI值,在(b)(d)中进一步证实了这一点,在这些情况下,“CI-Base: CI-New”的计算值对于CoOp(相对应的)大多数情况下大于1.0。在(b)(d)中,我们展示了CoOp和Oracle模型在新任务上的分类准确率,其中Oracle模型的性能明显优于CoOp,这表明Oracle模型产生的大多数特征通道包含了对新任务泛化至关重要的任务共享知识。简而言之,在提示调整后,大多数学习到的特征通道被基础特定知识所占据,导致了对新任务重要的任务共享知识的崩溃(或灾难性遗忘)-我们在这项工作中将这称为通道偏置问题。受上述观察的启发,我们提出了以下问题:
我们能否同时保留基础特定和任务共享知识在特征通道中,以克服提示调整中的BNT问题?
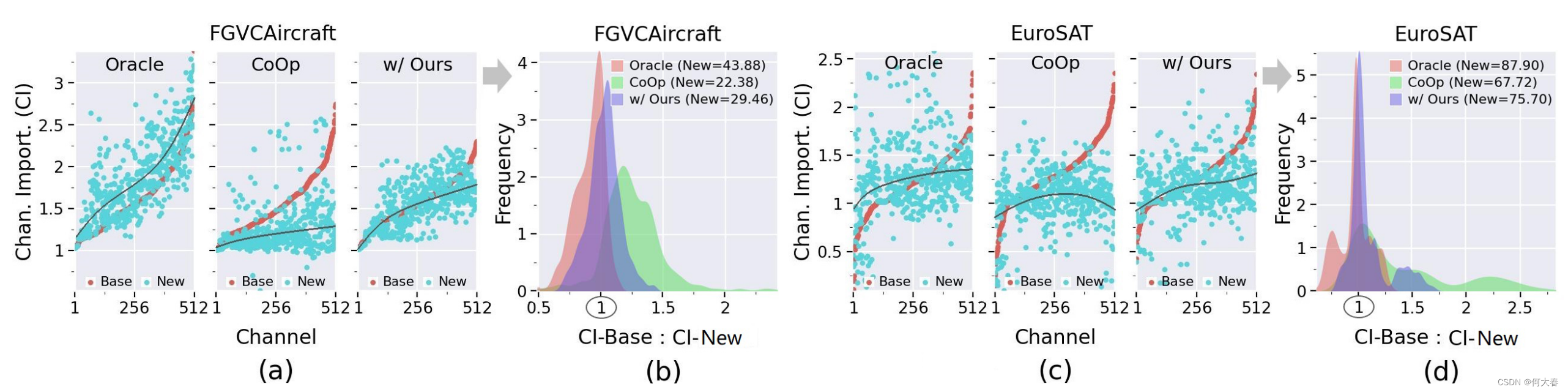
图3. 基于数据集FGVCAircraft [32]和EuroSAT [14],由Oracle模型和CoOp [58]使用或不使用我们的DePT学到的基础任务和新任务的通道重要性(CI)分布。在(a)(c)中,x轴上的通道索引根据基础任务的CI重新排序,蓝色/红色点表示一个通道。在(b)(d)中,展示了CI-Base:CI-New的频率分布,其中CI-Base和CI-New分别是基础任务和新任务的CI;“H”表示基础任务和新任务准确率的谐波均值[57]。
2.3. Decoupled Prompt Tuning
在这项工作中,我们通过提出Decoupled Prompt Tuning(DePT)来回答上述问题,这是一个从特征解耦的角度克服提示调整中BNT问题的第一个框架。DePT框架的概述如图2所示。
A Plug-and-play Channel Adjusted Transfer Head.一个即插即用的通道调整传输头。由于通道偏置问题,努力在提示调整期间获得基础特定知识将不可避免地触发在学习到的特征通道中任务共享知识的灾难性遗忘。为了解决这个问题,DePT采用了一个通道调整传输(CAT)头,将基础特定知识从特征通道解耦到一个孤立的特征空间中,以最大程度地保留原始特征空间中的任务共享知识。记
S
i
m
g
=
{
f
j
}
j
=
1
J
S_{\mathrm{img}}=\{\boldsymbol{f}_j\}_{j=1}^J
Simg={fj}j=1J和
S
t
e
x
t
=
{
e
j
}
j
=
1
J
\mathcal{S}_{\mathrm{text}}=\{e_{j}\}_{j=1}^{J}
Stext={ej}j=1J分别为一个批次训练样本的图像和文本特征集,
f
j
,
e
j
∈
R
d
f_j,e_j\in\mathbb{R}^d
fj,ej∈Rd。首先,CAT头利用一个逐通道的变换(cwT)层将
S
i
m
g
S_\mathrm{img}
Simg和
S
t
e
x
t
S_\mathrm{text}
Stext转换到一个新的特征空间。形式上,
S
i
m
g
′
=
{
f
j
′
}
j
=
1
J
S_\mathrm{img}^{\prime}=\{f_j^{\prime}\}_{j=1}^J
Simg′={fj′}j=1J,并且
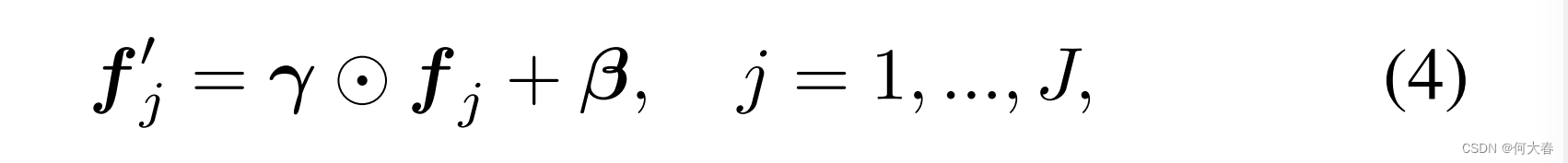
其中,
γ
,
β
∈
R
d
\gamma,\beta\in\mathbb{R}^d
γ,β∈Rd是可训练的缩放和位移向量。
类似地,记
S
t
e
x
t
′
=
{
e
j
′
}
j
=
1
J
S_\mathrm{text}^{\prime}=\{e_j^{\prime}\}_{j=1}^J
Stext′={ej′}j=1J。接下来,一个线性分类器以
S
∪
S_\mathrm{\cup}
S∪和
γ
∪
\gamma_\mathrm{\cup}
γ∪作为输入,以鼓励在孤立特征空间中挖掘基础特定知识,其中
S
∪
=
S
i
m
g
′
∪
S
t
e
x
t
′
=
{
s
j
}
j
=
1
2
J
S_{\cup }= S_{\mathrm{img}}^{\prime}\cup S_{\mathrm{text}}^{\prime}= \{ s_{j}\} _{j= 1}^{2J}
S∪=Simg′∪Stext′={sj}j=12J,
Y
∪
=
{
y
j
}
j
=
1
2
J
,
y
j
∈
R
M
\mathcal{Y} _{\cup }= \{\boldsymbol{y}_j\}_{j=1}^{2J},\boldsymbol{y}_j\in\mathbb{R}^M
Y∪={yj}j=12J,yj∈RM是
s
j
s_j
sj的一个独热标签,
M
M
M是任务的类别数。对于每对
(
s
,
y
)
(s,y)
(s,y),CAT头最小化以下交叉熵损失:
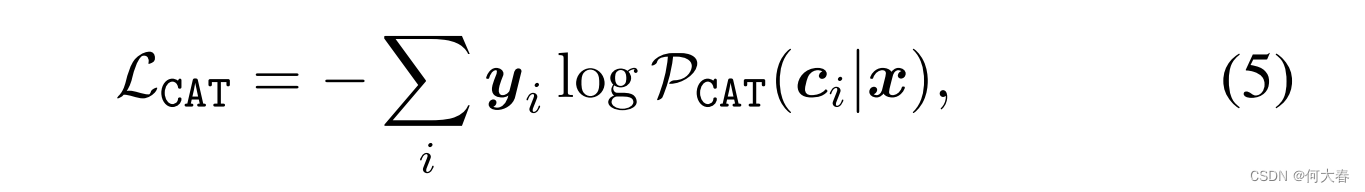
其中,
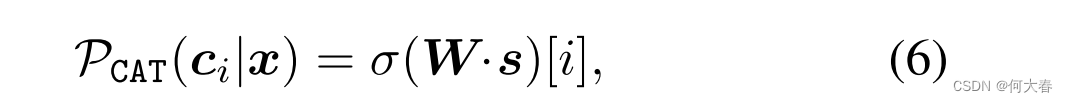
其中,
W
∈
R
M
×
d
\boldsymbol{W}\in\mathbb{R}^{M\times d}
W∈RM×d表示用于分类的投影矩阵,
σ
\sigma
σ表示softmax操作。在训练过程中,由
L
C
A
T
\mathcal{L}_\mathrm{CAT}
LCAT计算的梯度被反向传播以更新CAT头中的权重(即
γ
,
β
,
W
\gamma,\beta,W
γ,β,W),以及可训练提示(即
[
v
]
1
[
v
]
2
.
.
.
[
v
]
l
[\boldsymbol{v}]_1[\boldsymbol{v}]_2...[\boldsymbol{v}]_l
[v]1[v]2...[v]l)。在第
3.2
\color{red}{3.2}
3.2节的消融研究中表明,使用两个独立的cwT层(每个模态一个)比在CAT头中使用共享的cwT层更有效。
Prompt Tuning with Dual Heads.与仅仅使用设计的CAT头来促进在提示调整期间保留任务共享知识不同,我们的DePT还保留了标准的ITM头,以在原始特征空间中学习图像-文本对的对齐,这对于在新任务上建立更好的零样本泛化是非常重要的(正如在第3.2节证明的那样)。因此,DePT的总体学习目标表示为:
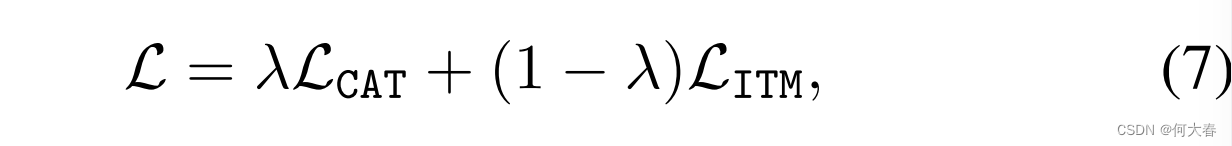
其中λ是控制两个损失的相对重要性的平衡权重。
Test-time Knowledge Fusion for the Base Task.在推断阶段,标准的ITM头用于在原始特征空间中对新任务进行零样本泛化/预测。对于基础任务,我们的CAT头直接将测试示例的图像特征作为输入,通过线性分类器来预测分布内的类别标签。值得注意的是,我们可以通过在推断时简单地将CAT头中的基础特定知识与ITM头中的任务共享知识融合来进一步提高基础任务的性能。通过连接方程(2)和方程(6),可以计算出分布内测试示例
x
x
x属于第
i
i
i类的预测概率:
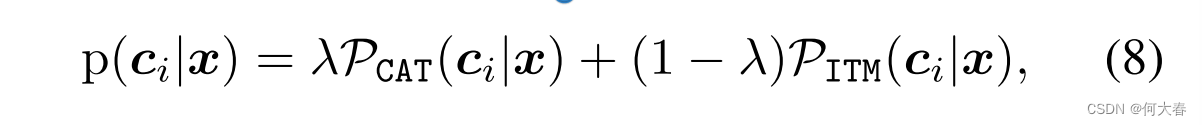
其中,Eq.(7)直接用于控制两个头的贡献以简化。用于实现DePT的类似Pytorch的伪代码在Sup.Mat.(B)。
3. Experiments
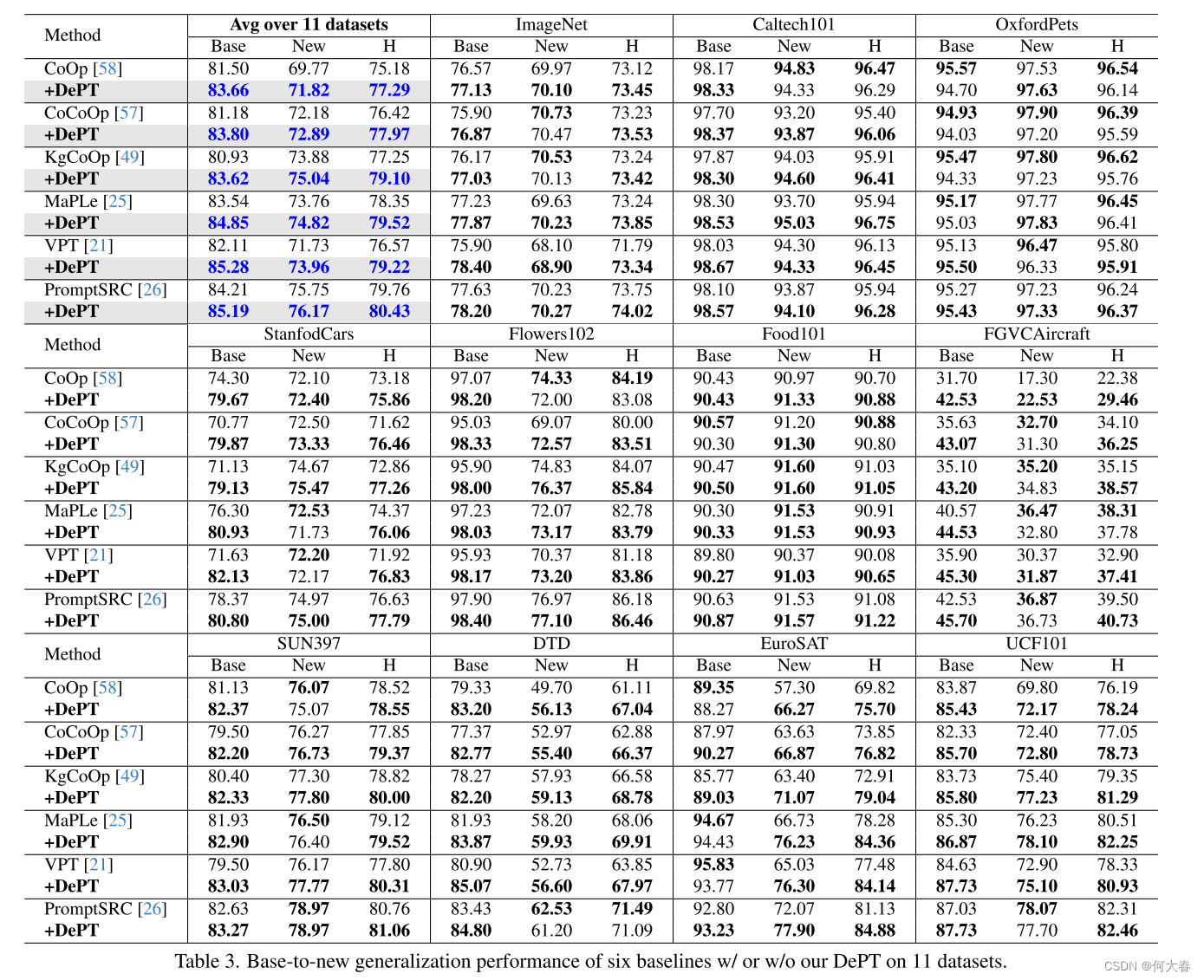
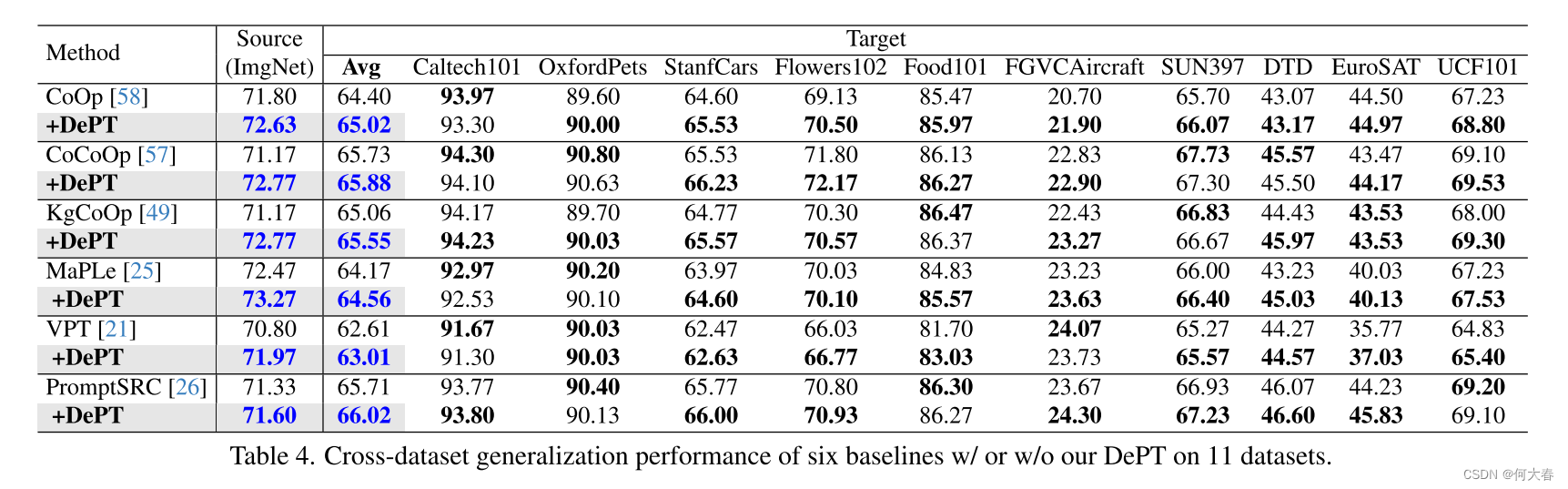
5. Conclusions
在这项工作中,我们提出了Decoupled Prompt Tuning(DePT)框架,以解决提示调整中的基础-新任务权衡(BNT)问题。首先,我们提供了一个富有洞察力的视角来分析BNT问题,并揭示了BNT问题源自通道偏差问题。其次,我们提出了DePT框架来解决BNT问题,并且DePT与现有的提示调整方法是正交的。第三,我们将DePT应用于广泛的基线方法,并在11个数据集上的结果证明了DePT的强大灵活性和有效性。我们希望这项工作能给相关领域带来一些启发。







![[MySQL]数据库原理8——喵喵期末不挂科](https://img-blog.csdnimg.cn/direct/03e367a251574527ba182ce281cd459b.png)