- Scrapy框架基础
- Scrapy框架进阶
【五】持久化存储
- 命令行:json、csv等
- 管道:什么数据类型都可以
【1】命令行简单存储
(1)语法
- Json格式
scrapy crawl 自定义爬虫程序文件名 -o 文件名.json
- CSV格式
scrapy crawl 自定义爬虫程序文件名 -o 文件名.csv -t csv
(2)示例
- 重点是parse函数需要返回保存的数据
# 假设从浏览器拿到了想保存的数据文件
def parse(self, response):
items = []
for i in range(5):
item[f"name{i}"] = f"value{i}"
items.append(item)
return items
- 保存为json格式文件
scrapy crawl test -o output.json
# output.json
[
{"name0": "value{0}"},
{"name1": "value{1}"},
{"name2": "value{2}"},
{"name3": "value{3}"},
{"name4": "value{4}"}
]
【2】管道存储
- 保存在数据库mysql中
- 保存在本地txt文件中
(1)第一步:从前端处理数据并返回
- 这里假设数据是从response中分析出来的
- 注意item要放在循环中
- 注意item要放在循环中
- 注意item要放在循环中
import scrapy
from ..items import ScrapyTestItem
class TestSpider(scrapy.Spider):
name = "test"
allowed_domains = ["www.test.com"]
start_urls = ["https://www.test.com/"]
def parse(self, response):
for i in range(5):
item = ScrapyTestItem()
item['name'] = f"bruce{i}"
item['avatar'] = f"avatar img src{i}"
item['introduce'] = f"long long introduce{i}"
yield item
(2)第一步:创建管道数据模型
- 需要在items.py文件中创建一个类
- 类似于Django的模型表
- 这个简单,无论是什么类型字段都是scrapy.Field()
import scrapy
class ScrapyTestItem(scrapy.Item):
name = scrapy.Field()
avatar = scrapy.Field()
introduce = scrapy.Field()
(3)第二步:定义管道数据处理类
-
在Scrapy中,
parse方法返回的数据(无论是Item对象还是其他数据结构)会被Scrapy引擎自动迭代、自动迭代、自动迭代,并逐个传递给Pipeline的process_item方法。 -
需要在pipline.py文件中创建一个类
- open_spider(self, spider):
- 当爬虫开始时,这里会执行一些初始化操作
- 例如,可以建立数据库连接、打开文件等
- spider参数不能少
- close_spider(self, spider):
- 当爬虫结束时,这里会执行一些清理操作
- 例如,可以关闭数据库连接、关闭文件等
- spider参数不能少
- process_item:
- 每次要保存一个对象时,这个方法会被触发
- 在这里可以对item进行进一步的处理,然后保存到数据库或者文件等
- open_spider(self, spider):
-
创建数据库和表
create database scrapy
CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
`avatar` varchar(255) DEFAULT NULL,
`introduce` text,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
- 创建数据库处理类
import pymysql
class ScrapyTestMysqlPipeline:
def open_spider(self, spider):
self.conn = pymysql.connect(
user='root',
password='000',
host='127.0.0.1',
port= 3306,
database='scrapy',
cursorclass=pymysql.cursors.DictCursor,
)
self.cursor = self.conn.cursor()
def close(self, spider):
# 关闭句柄
self.cursor.close()
# 关闭数据库链接
self.conn.close()
def process_item(self, item, spider):
sql_str = """
insert INTO
test(name, avatar, introduce)
values(%s, %s, %s);
"""
self.cursor.execute(sql_str, args=(
item.get('name'),
item.get('avatar'),
item.get('introduce'),
))
self.conn.commit()
return item
- 创建本地文件保存类
class ScrapyTestTxtPipeline:
def open_spider(self, spider):
self.fp = open('output.txt', 'wt', encoding='utf8')
def close_spider(self, spider):
self.fp.close()
def process_item(self, item, spider):
# 已经自动迭代
self.fp.write(str(item) + '\n')
return item
(4)第四步:配置文件中注册管道类
- Pipline的执行顺序会按照
ITEM_PIPELINES字典中的定义顺序执行- 数字越小,优先级越高,执行顺序越靠前
- 建议数字范围0-1000,没有强制规定
ITEM_PIPELINES = {
"scrapy_test.pipelines.ScrapyTestMysqlPipeline": 100,
"scrapy_test.pipelines.ScrapyTestJsonPipeline": 300,
}
(5)最后:启动项目
- 命令行
scrapy crawl test
- py文件
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', 'test'])
【六】中间件
【1】爬虫中间件
# 爬虫中间件
class Day06StartSpiderMiddleware:
@classmethod
def from_crawler(cls, crawler):
# 这是一个类方法,Scrapy使用它来创建爬虫中间件实例。
# 这个方法通常用于连接中间件到Scrapy的信号。
# 在这个例子中,它将spider_opened方法连接到spider_opened信号。
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# 这个方法在每次响应通过爬虫中间件并进入爬虫时被调用。
# 它允许修改响应或执行其他操作。
# 如果不想修改响应,可以返回None;
# 如果想阻止响应继续传递给爬虫,可以抛出一个异常。
return None
def process_spider_output(self, response, result, spider):
# 这个方法在爬虫处理完响应并返回结果后被调用。
# 它允许处理或修改爬虫的输出。
# 必须返回一个包含请求或项目对象的可迭代对象。
# 在这个例子中,它只是简单地返回了原始结果。
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# 当爬虫或其他爬虫中间件中的process_spider_input方法抛出异常时,这个方法会被调用。
# 它允许处理异常,例如记录错误或生成新的请求。
# 可以返回None或包含请求或项目对象的可迭代对象。
# 在这个例子中,这个方法没有做任何事情。
pass
def process_start_requests(self, start_requests, spider):
# 这个方法在爬虫的起始请求被发送之前被调用。
# 它与process_spider_output方法类似,
# 但不同之处在于它不与特定的响应相关联。
# 必须只返回请求(而不是项目)。
# 在这个例子中,它只是简单地返回了原始的起始请求。
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
# 这是一个当爬虫被打开时由Scrapy信号触发的方法。
# 在这个例子中,它使用爬虫的日志记录器记录一条信息,说明哪个爬虫被打开了。
spider.logger.info("Spider opened: %s" % spider.name)
【2】下载中间件
class ScrapyTestDownloaderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# 这个类方法由Scrapy调用,用于创建下载器中间件实例。
# 在这个方法中,可以连接中间件到Scrapy的信号,
# 例如连接spider_opened信号到spider_opened方法。
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# 当每个请求通过下载器中间件时,这个方法会被调用。
# 可以在这个方法中修改请求,或者返回一个新的请求或响应对象。
# 如果返回None,则请求会继续被处理。
# 如果返回Request对象,Scrapy会停止处理当前的请求,并开始处理新的请求。
# 如果返回Response对象,Scrapy将不会发送请求,而是直接将该响应传递给process_response方法。
# 如果抛出IgnoreRequest异常,Scrapy将不会发送请求,并且会调用所有已安装的下载器中间件的process_exception方法。f
# installed downloader middleware will be called
return None
def process_response(self, request, response, spider):
# 当下载器返回响应时,这个方法会被调用。
# 可以在这里修改响应,或者返回一个新的请求或响应对象。
# 如果返回Response对象,该响应将被传递给爬虫。
# 如果返回Request对象,Scrapy将停止处理当前的响应,并开始处理新的请求。
# 如果抛出IgnoreRequest异常,Scrapy将不会将响应传递给爬虫,并且会调用所有已安装的下载器中间件的process_exception方法。
return response
def process_exception(self, request, exception, spider):
# 当下载处理器或process_request方法(来自其他下载器中间件)抛出异常时,这个方法会被调用。
# 可以在这里处理异常,例如记录错误、返回一个新的请求或响应对象,或者简单地忽略异常。
# 如果返回None,异常会继续被处理。
# 如果返回Response或Request对象,Scrapy将停止处理当前的异常,并继续处理返回的响应或请求。
pass
def spider_opened(self, spider):
# 当爬虫被打开时,这个方法会被Scrapy的信号机制调用。
# 可以在这里执行一些初始化的工作,或者记录关于哪个爬虫被打开的信息。
spider.logger.info("Spider opened: %s" % spider.name)
【3】配置文件中注册
SPIDER_MIDDLEWARES = {
"scrapy_test.middlewares.ScrapyTestSpiderMiddleware": 543,
}
DOWNLOADER_MIDDLEWARES = {
"scrapy_test.middlewares.ScrapyTestDownloaderMiddleware": 543,
}
【4】下载中间件案例–修改请求头
class ScrapyTestDownloaderMiddleware:
# 从代理池中获取可用代理
@staticmethod
def get_proxy(flag):
if flag:
res = requests.get('http://代理池地址/get/?type=https').json()
return "https://" + res.get('proxy')
else:
res = requests.get('http://代理池地址/get/').json()
return "http://" + res.get('proxy')
def process_request(self, request, spider):
# 自定义代理,根据request.url判断是https还是http
flag = 'https' in request.url
proxy_url = self.get_proxy(flag)
if proxy_url:
request.meta['proxy'] = proxy_url
print(f"Using proxy: {proxy_url}")
# 添加指定cookie
request.cookies['name'] = 'value'
# 或cookies字符串
request.headers['Cookie'] = 'name=value; anothername=anothervalue'
# 添加源页面地址
request.headers['referer'] = 'https://example.com'
# 添加随机UA验证
from fake_useragent import UserAgent
request.headers['User-Agent'] = str(UserAgent().random)
return None
def process_exception(self, request, exception, spider):
# 处理由于代理问题引发的异常
print(f'下载中间异常: {exception}')
# 这里可以添加逻辑来重试请求或更换代理
return None
【八】CrawlSpider
【1】介绍
(1)简介
- CrawlSpider是Spider的一个派生类,它继承自Spider类,并在此基础上增加了新的属性和方法。
- 这意味着CrawlSpider拥有Spider的所有功能和特性,并具备一些额外的独特功能。
(2)作用
- 自动跟踪链接:
- CrawlSpider能够自动解析页面中的链接,并根据设定的规则跳转到其他页面,以便爬取整个网站的所有页面。
- 这使得CrawlSpider在处理大型网站或需要深度爬取的场景时非常有效。
- 数据提取规则:
- CrawlSpider提供了一种方便的方式来定义如何从页面中提取数据。
- 通过使用基于XPath或CSS选择器的规则,用户可以轻松地提取所需的目标数据。
- 避免重复爬取:
- CrawlSpider会自动管理已经爬取过的链接,从而避免在爬取过程中重复访问同一个页面。
- 这有助于减少不必要的网络请求和提高爬取效率。
(3)特别之处
- 规则定义:
- CrawlSpider通过其特有的属性“rules”来定义爬取规则。
- 这些规则包括链接提取器(LinkExtractor)和回调函数(callback),它们共同决定了如何提取和处理页面上的链接。
- 这使得CrawlSpider在处理具有特定结构和链接模式的网站时更加灵活和高效。
- 链接提取器:
- CrawlSpider中的链接提取器(LinkExtractor)是其特别之处之一。
- 这个提取器可以自动从页面中识别并提取出符合特定模式的链接,从而极大地简化了链接提取的过程。
- 这使得CrawlSpider在处理大型、复杂的网站时具有更高的效率和准确性。
【2】使用
- 方法名不建议使用parse,用其他名字
(1)创建CrawlSpider
- 和普通的spider差不多
- 这里指定使用crawl基础模板
scrapy genspider -t crawl 自定义爬虫程序文件名 目标地址
(2)使用自定义规则
Rule(LinkExtractor(allow=r"地址正则表达式"), callback="回调函数", follow=False)LinkExtractor:用于从响应中(response)中自动根据allow的正则表达式提取链接callback:回调函数的字符串follow:是否从匹配到的链接继续递归提取链接,即只是爬取一页中可以看到的链接,还是继续递归爬取
- 可以使用多条规则,rules是个元组或者列表
rules = (
# 多页资源匹配,提取分页链接,但不跟进
Rule(LinkExtractor(allow=r"https://www.example.com/p/\d+"), callback="parse_page", follow=False),
# 详情页面链接匹配,提取详情链接,也不跟进
Rule(LinkExtractor(allow=r"https://www.example.com/\w+/p/\d+"), callback="parse_detail", follow=False),
)
(3)多页数据,方法传递
yield scrapy.Request(url=detail_url, callback=self.detail_parse, meta={'item': item})- 这个是将详情页的url地址携带数据meta发送给callback回调函数
url:要爬取的网页内容callback:处理爬取url的响应meta:在请求的生命周期中传递数据
import scrapy
class MySpider(CrawlSpider):
name = 'test'
allowed_domains = ["www.example.com"]
start_urls = ['https://example.com']
rules = [
Rule(LinkExtractor(allow=r"https://www.example.com/sitehome/p/\d+"), callback="parse_page", follow=False),
]
def parse_page(self, response):
# 获得每个需要的div
div_list = response.xpath('')
for div in div_list:
# 假设有一个item对象,用于存储数据
item = MyItem()
# 保存这里获得的数据
item['title'] = div.xpath('').extract()[0]
...
# 获得详情页地址
detail_url = div.xpath('/@herf').extract()[0]
# 生成Request对象,并传递item通过meta
yield scrapy.Request(url=detail_url, callback=self.parse_detail, meta={'item': item})
def parse_detail(self, response):
# 从meta中获取之前传递的item对象
item = response.meta['item']
# 从响应中继续提取信息
item['detail'] = response.xpath('h1::text').extract_first()
...
# 返回item,准备交给pipeline处理
yield item
【九】集成selenium
【1】介绍
- scrapy默认使用的是requests模块发送请求
- 无法执行js
- 所以需要使用selenium模块
- 根据scrapy框架可知
- 需要修改下载中间件的入口
- 将需要特殊处理的地址发送给selenium
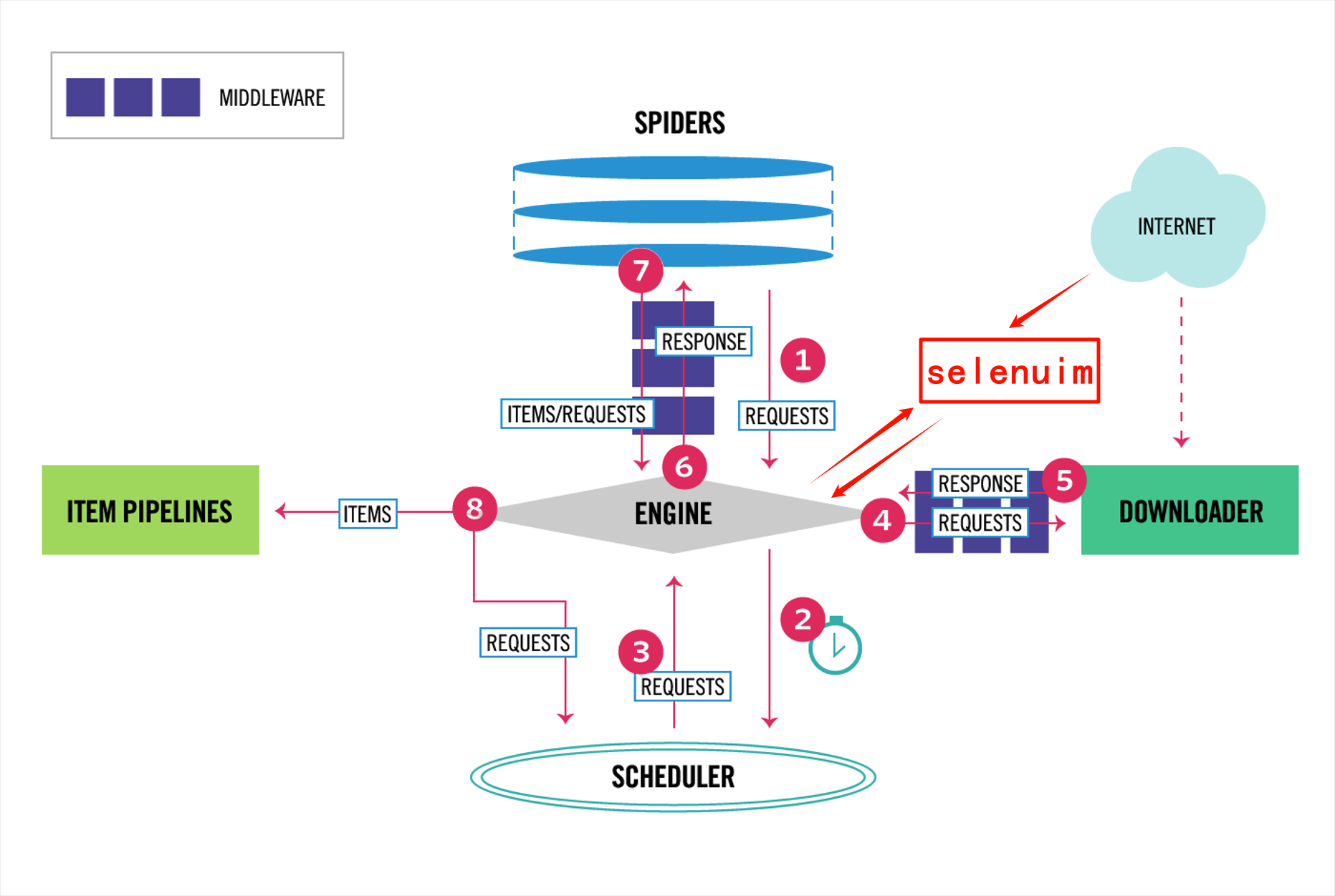
【2】使用方法
-
假设
- 正常请求通过scrapy默认requests获取
- 详情页面需要使用selenium获取
-
如何区分不同的请求
- 根据不同的地址参数,判断是否使用selenium
- 根据request.meta[‘is_selenium’]给定的参数进行判断
- 添加参数:
yield Request(url=url, callback=self.detail_parse, meta={'item': item,'is_selenium':True}) - 获取参数:
request.meta.get('is_selenium')
- 添加参数:
(1)添加自定义的selenium中间件
from scrapy import signals
class SeleniumMiddleWare:
def __init__(self):
from selenium import webdriver
from selenium.webdriver.edge.service import Service
browser_path = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'msedgedriver.exe')
self.browser = webdriver.Edge(service=Service(browser_path), options=self.make_options())
self.browser.implicitly_wait(10)
@classmethod
def from_crawler(cls, crawler):
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
crawler.signals.connect(s.spider_closed, signal=signals.spider_closed)
return s
@staticmethod
def make_options():
from selenium.webdriver.edge.options import Options
options = Options()
options.add_argument("window-size=1920x1080")
# options.add_argument('--headless')
options.add_argument('--disable-gpu')
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
return options
def spider_opened(self, spider):
spider.logger.info("Browser Opened")
# 将浏览器实例绑定到spider上,方便process_request使用
spider.browser = self.browser
def spider_closed(self, spider):
spider.logger.info("Browser Closed")
spider.browser.quit()
def process_request(self, request, spider):
# 根据标志判断是否使用selenium
# if request.meta.get('is_selenium'):
# 根据地址区分是否使用selenium
if 'article' not in request.url:
spider.logger.info(f"Using Selenium for Url: {request.url}")
spider.browser.get(request.url)
from scrapy.http.response.html import HtmlResponse
response = HtmlResponse(url=request.url, body=bytes(spider.browser.page_source, encoding='utf8')) # 编码可能要调整
return response
# 使用scrapy默认处理请求
return None
(2)注册中间件
- 在配置文件settings中
DOWNLOADER_MIDDLEWARES = {
"scrapy_test.middlewares.SeleniumMiddleWare": 555,
}
【十】去重过滤器
- 在scrapy框架中,
- 为了确保爬取到的数据是唯一的
- 避免重复爬取相同的页面或数据
- scrapy默认使用了基于Request指纹的去重机制
- 除了默认的去重规则,scrapy还支持自定义去重规则
【1】基于Request指纹的去重
(1)去重核心代码
- 位置:
from scrapy.core.scheduler import Schedulerdef enqueue_request(self, request: Request) -> bool:def request_seen(self, request: Request) -> bool:class RFPDupeFilter(BaseDupeFilter):def request_seen(self, request: Request) -> bool:
self.fingerprints: Set[str] = set()
def request_fingerprint(self, request: Request) -> str:
return self.fingerprinter.fingerprint(request).hex()
def request_seen(self, request: Request) -> bool:
fp = self.request_fingerprint(request)
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)
if self.file:
self.file.write(fp + "\n")
return False
- 讲解:
- 在类中定义了一个实例变量
fingerprints- 是一个集合,集合具有去重的功能
- 用于存储已经发送过的
request指纹
- 在类中定义了一个方法
request_fingerprint- 使用fingerprinter对象的fingerprint方法,对request进行计算
- 计算指纹,并将指纹转换为十六进制的字符串
- 在类中定义了方法
request_seen- 首先计算request的指纹
- 判断指纹是否在访问过的集合中
- 为真,那么久说明是已经访问过
- 添加这个请求的指纹到指纹集合中
- 检查
self.file是否存在(打开的文件句柄,用于持久化存储指纹)- 存在就将指纹写入这个文件,并换行
- 最终返回False,说明是一个新的request
- 在类中定义了一个实例变量
(2)测试指纹
-
我们对两个相同请求结果但是不同url进行测试
-
例如:
-
https://www.example.com?keys=154623&value=qbz -
https://www.example.com?value=qbz&keys=154623 -
这两个的地址虽然不同,传递给后端的结果却相同
-
所以这两个的指纹应该是一样的
-
-
示例
from scrapy.utils.request import RequestFingerprinter
from scrapy import Request
finger_printer = RequestFingerprinter()
request1 = Request(url="https://www.example.com?value=qbz&keys=154623")
request2 = Request(url="https://www.example.com?keys=154623&value=qbz")
res1 = finger_printer.fingerprint(request1).hex()
res2 = finger_printer.fingerprint(request2).hex()
print(res2 == res1)
# True
【2】自定义过滤器
(1)布隆过滤器(Bloom Filter)
- 优点:
- 空间效率高:
- 使用位数组存储信息
- 比传统的哈希表或集合数据结构更小
- 时间效率高:
- 查找元素,通过几次简单的位运算
- 适用于大规模数据:
- 高空间和时间效率,所以适用于处理大规模数据
- 支持集合运算:
- 支持并集、交集等集合运算
- 这使得它在某些场景下非常有用
- 具有一定容错能力:
- 布隆过滤器是概率型数据结构,即存在哈希冲突
- 但误报率可以通过调整参数进行控制
- 空间效率高:
- 原理:
- 布隆过滤器主要由一个位数组和k个哈希函数组成。
- 当需要插入一个元素时,该元素会被k个哈希函数映射到位数组的k个不同位置,并将这些位置上的位设置为1。
- 当需要查询一个元素是否存在于集合中时,同样使用这k个哈希函数找到对应的位,并检查这些位是否都为1。
- 如果都为1,则认为该元素可能存在于集合中;如果有任何一个位为0,则确定该元素不在集合中。
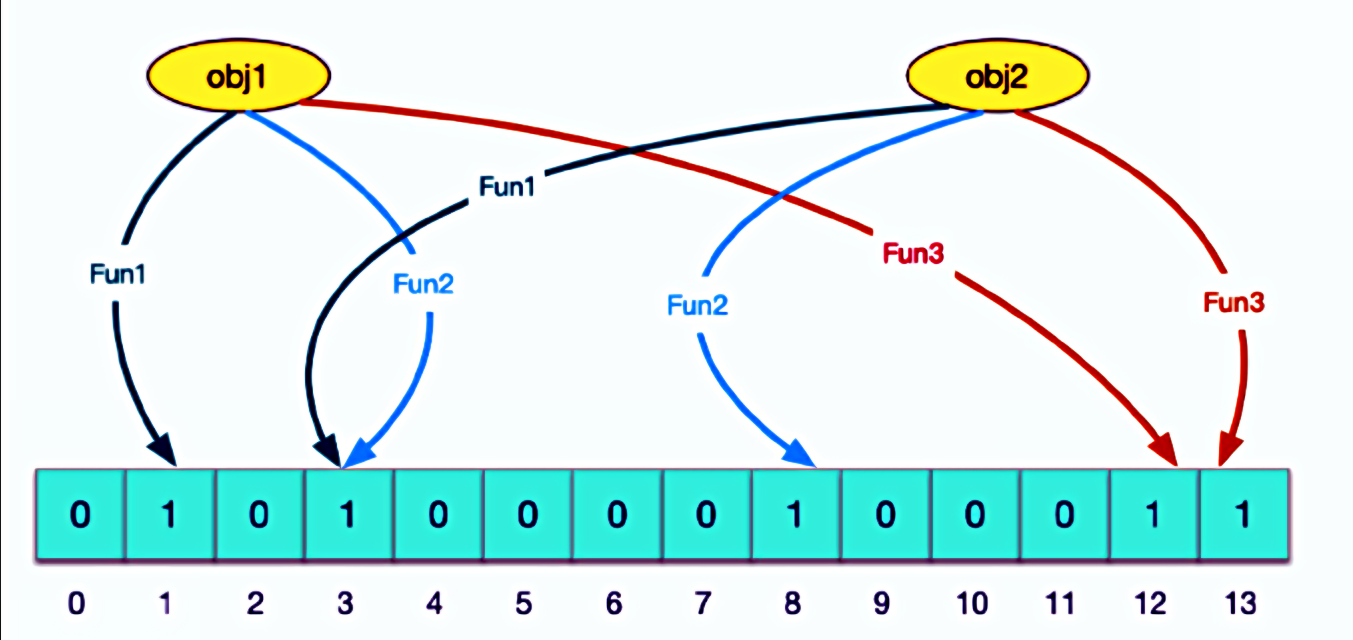
(2)简单使用布隆过滤器
- 首先安装模块
pip install pybloom_live
- 使用示例
from pybloom_live import ScalableBloomFilter, BloomFilter
# 创建一个可扩容的布隆过滤器
# initial_capacity容量
# error_rate错误率
bloom = ScalableBloomFilter(initial_capacity=100, error_rate=0.001, mode=ScalableBloomFilter.LARGE_SET_GROWTH)
# 添加元素
url1 = "https://www.example.com?keys=154623&value=qbz"
url2 = "https://www.example.com?value=qbz&keys=154623"
bloom.add(url1)
bloom.add(url2)
# 检测结果
print(len(bloom)) # 2
print(url1 in bloom) # True
print(url2 in bloom) # True
- 错误率测试
from pybloom_live import ScalableBloomFilter
bloom = ScalableBloomFilter(initial_capacity=1000, error_rate=0.01)
for i in range(100000):
data = f'example{i}'
bloom.add(data)
false_list = []
for i in range(1000):
data = f'exist{i}'
if bloom.__contains__(data):
false_list.append(data)
print(false_list)
print(f"错误率:>>>{len(false_list)/100}%")
# ['exist29', 'exist49', 'exist53', 'exist118', 'exist144', 'exist196', 'exist215', 'exist219', 'exist235', 'exist259', 'exist293', 'exist331', 'exist339', 'exist377', 'exist404', 'exist421', 'exist451', 'exist494', 'exist551', 'exist615', 'exist665', 'exist750', 'exist760', 'exist821', 'exist831', 'exist832', 'exist983']
# 错误率:>>>0.27%
(3)scrapy自定义过滤器(没有关闭默认的)
- 创建布隆过滤器中间件
from scrapy import signals
from pybloom_live import ScalableBloomFilter
from scrapy.exceptions import IgnoreRequest
import hashlib
class BloomFilterMiddleware:
def __init__(self, crawler):
self.crawler = crawler
# 从Scrapy设置中读取布隆过滤器的配置
self.initial_capacity = crawler.settings.getint('BLOOM_FILTER_INITIAL_CAPACITY', 100000)
self.error_rate = crawler.settings.getfloat('BLOOM_FILTER_ERROR_RATE', 0.001)
# 初始化布隆过滤器
self.bloom_filter = ScalableBloomFilter(initial_capacity=self.initial_capacity, error_rate=self.error_rate)
@classmethod
def from_crawler(cls, crawler):
s = cls(crawler)
# 连接信号
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
crawler.signals.connect(s.spider_closed, signal=signals.spider_closed)
crawler.signals.connect(s.process_request, signal=signals.request_scheduled)
return s
def spider_opened(self, spider):
# 可以在这里加载之前保存的布隆过滤器状态(如果需要的话)
pass
def spider_closed(self, spider):
# 可以在这里保存布隆过滤器的当前状态(如果需要的话)
pass
def process_request(self, request, spider):
# 对URL进行哈希处理
url_hash = hashlib.sha256(request.url.encode()).hexdigest()
# 检查URL是否已经在布隆过滤器中
if url_hash in self.bloom_filter:
# 如果可能在布隆过滤器中,则忽略请求
raise IgnoreRequest("URL already processed")
def process_response(self, request, response, spider):
# 检查响应是否成功
if response.status == 200:
# 对URL进行哈希处理
url_hash = hashlib.sha256(request.url.encode()).hexdigest()
# 将URL添加到布隆过滤器中
self.bloom_filter.add(url_hash)
return response
- 在配置文件中注册
# 添加自定义中间件
MIDDLEWARES = {
'your_project_name.middlewares.BloomFilterMiddleware': 542,
}
# 布隆过滤器设置
BLOOM_FILTER_INITIAL_CAPACITY = 10000 # 根据你的需求设置容量
BLOOM_FILTER_ERROR_RATE = 0.01 # 设置误报率