索引创建后,要非常谨慎,创建不好后面会出现各种问题。
索引设计的重要性
索引创建后,索引分片只能通过_split和_shrink 接口对其进行成倍的增加和缩减。
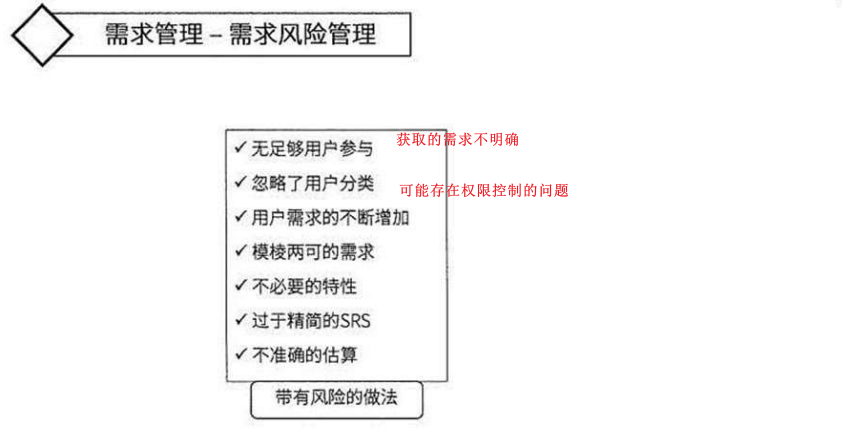
ES的数据是通过_routing分配到各个分片上的,所以本质上不推荐区改变索引的分片数量的,因为这样都会对数据进行重新移动。还有就是索引只能新增字段,不能对字段进行修改和删除,缺乏灵活性,所以每次都只能通过_reindex重建索引了,还有就是一个分片的大小以及所以分片数量的多少严重影响到了索引的查询和写入性能,所以可想而知,设计一个好的索引能够减少后期的运维管理和提高不少性能,所以前期对索引的设计是相当的重要的。
基于时间的索引设计
Index设计时要考虑的第一件事,就是基于时间对Index进行分割,即每隔一段时间产生一个新的Index。
因为现实世界的数据是随着时间的变化而不断产生的,切分管理可以获得足够的灵活性和更好的性能。

如果数据都存储在一个Index中,很难进行扩展和调整,因为Elasticsearch中Index的某些设置在创建时就设定好了,是不能更改的,比如Primary Shard的个数。而根据时间来切分Index,则可以实现一定的灵活性,既可以在数据量过大时及时调整Shard个数,也可以及时响应新的业务需求。
大多数业务场景下,客户对数据的请求都会命中在最近一段时间上,通过切分Index,可以尽可能的避免扫描不必要的数据,提高性能。
时间间隔
根据上面的分析,自然是时间越短越能保持灵活性,但是这样做就会导致产生大量的Index,而每个Index都会消耗资源来维护其元信息的,因此需要在灵活性、资源和性能上做权衡。
1)常见的间隔有小时、天、周和月:先考虑总共要存储多久的数据,然后选一个既不会产生大量Index又能够满足于定灵活性的间隔,比如你需要存储6个月的数据,那么一开始选择“周“这个间隔就会比较合适。
2)考虑业务增长速度:假如业务增长的特别快,比如上周产生了1亿数据,这周就增长到了10亿,那么就需要调低这个间隔来保证有足够的弹性能应对变化。
如何实现分割
切分行为是由客户端(数据的写不端)发起的,根据时间间隔与数据产生时间将数据写入不同的Index中,为了易于区分,会在Index的名字中加上对应的时间标识。
创建新Index这件事,可以是客户端主动发起一个创建的请求,带上具体的Settings、Mappings等信息,但是可能会有一个时间错位,即有新数据写入时新的ndex还没有建好,Elasticsearch提供了更优雅的方式来实现这个动作,即Index Template (索引模板)
使用索引模板
就是把已经创建好的某个索引的参数设置(settings)和索引映射(mapping)保存下来作为模板,在创建新索引时,指定要使用的模板名,就可以直接重用已经定义好的模板中的设置和映射。
Elasticsearch基于与索引名称匹配的通配符模式将模板应用于新索引,也就是说通过索引进行匹配,看看新建的索引是否符合索引模板,如果符合,就将索引模板的相关设置应用到新的索引,如果同时符合多个索引模板呢,这里需要对参数priority进行比较,这样会选择priority大的那个模板进行创建索引。
在创建索引模板时,如果匹配有包含的关系,或者相同,则必须设置priority为不同的值,否则会报错,索引模板也是只有在新创建的时候起到作用,修改索引模板对现有的索引没有影响,同样如果在索引中设置了一些设置或者mapping都会覆盖索引模板中相同的设置或者mapping。
索引模板的用途
如果你需要每间隔一定的时间就建立一次索引,你只需要配置好索引模板,以后就可以直接使用这个模板中的设置,不用每次都设置settings和mappings。
创建索引模板
PUT _index_template/logstash-village
{
"index_patterns": [
"logstash-village-*" // 可以通过"logstash-village-*"来适配创建的索引
],
"template": {
"settings": {
"number_of_shards": "3", //指定模板分片数量
"number_of_replicas": "2" //指定模板副本数量
},
"aliases": {
"logstash-village": {} //指定模板索引别名
},
"mappings": { //设置映射
"dynamic": "strict", //禁用动态映射
"properties": {
"@timestamp": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis||yyyy-MM-dd HH:mm:ss"
},
"@version": {
"doc_values": false,
"index": "false",
"type": "integer"
},
"name": {
"type": "keyword"
},
"province": {
"type": "keyword"
},
"city": {
"type": "keyword"
},
"area": {
"type": "keyword"
},
"addr": {
"type": "text",
"analyzer": "ik_smart"
},
"location": {
"type": "geo_point"
},
"property_type": {
"type": "keyword"
},
"property_company": {
"type": "text",
"analyzer": "ik_smart"
},
"property_cost": {
"type": "float"
},
"floorage": {
"type": "float"
},
"houses": {
"type": "integer"
},
"built_year": {
"type": "integer"
},
"parkings": {
"type": "integer"
},
"volume": {
"type": "float"
},
"greening": {
"type": "float"
},
"producer": {
"type": "keyword"
},
"school": {
"type": "keyword"
},
"info": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
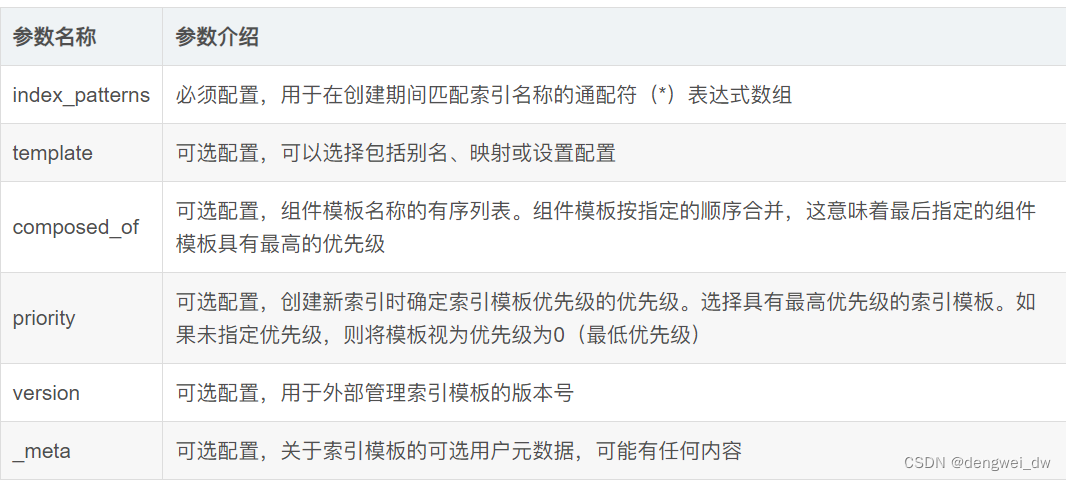
}模板参数
分片设计
所谓分片设计,就是如何设定主分片的个数。看上去只是一个数字而已,也许在很多场景下,即使不设定也不会有问题(ES7默认是1个主分片一个副本分片),但是如果不提前考虑,一旦出问题就可能导致系统性能下降、不可访问、甚至无法恢复,换句话说,即使使用默认值,也应该是通过足够的评估后作出的决定,而非拍脑袋定的。
限制分片大小
单个Shard的存储大小不超过30GB。Elastic专家根据经验总结出来大家普遍认为30GB是个合适的上限值,实践中发现单个Shard过大(超过30GB)会导致系统不稳定。
为什么不能超过30GB?主要是考虑Shard Relocate过程的负载,我们知道,如果Shard不均衡或者部分节点故障,Elasticsearch会做Shard Relocate,在这个过程中会搬移Shard,如果单个Shard过大,会导致CPU、IO负载过高进而影响系统性能与稳定性。
评估分片数量
单个Index的Primary Shard个数 = k * 数据节点个数
在保证第一点的前提下,单个Index的Primary Shard个数不宜过多,否则相关的元信息与缓存会消耗过多的系统资源,这里的k,为一个较小的整数值,建议取值为1,2等,整数倍的关系可以让Shard更好地均匀分布,可以充分的将请求分散到不同节点上。
小索引设计
对于很小的Index,可以只分配1~2个Primary Shard的
有些情况下,Index很小,也许只有几十、几百MB左右,那么就不用按照第二点来分配了,只分配1~2个Primary Shard是可以的。