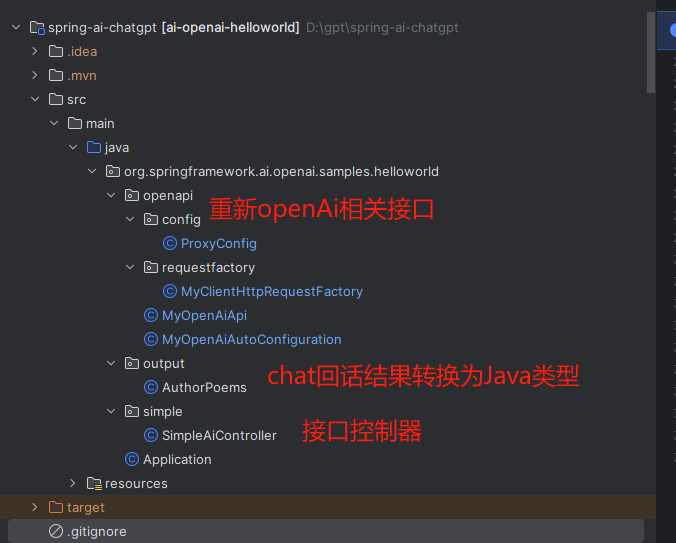
这是一个手机目标检测的数据集,数据集的标注工具是labelimg,数据格式是voc格式,要训练yolo模型的话,可以使用脚本改成txt格式,数据集标注了手机,标签名:telephone,数据集总共有1960张,有一部分是直实数据,有一部分是是真实数据。
数据集地址:https://download.csdn.net/download/matt45m/89136478
数据标注如下:



数据保存目录如下:
xml标签文件:
<annotation>
<folder>JPEGImages</folder>
<filename>bs001783.jpg</filename>
<path>JPEGImages\bs001783.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>1920</width>
<height>1080</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>telephone</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>1058</xmin>
<ymin>936</ymin>
<xmax>1123</xmax>
<ymax>977</ymax>
</bndbox>
</object>
</annotation>
python代码实现可视化:
import xml.etree.ElementTree as ET
import os
import cv2
# ******************************************
src_XML_dir = r'labels' # xml源路径
src_IMG_dir = r'images' # IMG原路径
IMG_format = '.jpg' # IMG格式
out_dir = 'out' # 输出路径
# ******************************************
if not os.path.exists(out_dir):
os.makedirs(out_dir)
xml_file = os.listdir(src_XML_dir) # 只返回文件名称,带后缀
for each_XML in xml_file: # 遍历所有xml文件
# 读入IMG
xml_FirstName = os.path.splitext(each_XML)[0]
img_save_file = os.path.join(out_dir, xml_FirstName+IMG_format)
img_src_path = os.path.join(src_IMG_dir, xml_FirstName+IMG_format)
img = cv2.imread(img_src_path)
# 解析XML
each_XML_fullPath = src_XML_dir + '/' + each_XML # 每个xml文件的完整路径
tree = ET.parse(each_XML_fullPath) # ET.parse()内要为完整相对路径
root = tree.getroot() # 类型为element
# 画框
for obj in root.findall('object'):
if obj.find('bndbox'):
bndbox = obj.find('bndbox')
xmin = int(bndbox.find('xmin').text)
xmax = int(bndbox.find('xmax').text)
ymin = int(bndbox.find('ymin').text)
ymax = int(bndbox.find('ymax').text)
cv2.rectangle(img=img,
pt1=(xmin,ymin),
pt2=(xmax,ymax),
color=(255,0,0),
thickness=2)
cv2.imwrite(filename=img_save_file, img=img)
print('保存结果{}'.format(xml_FirstName))