文章目录
- 前言
- OLTP 和 OLAP
- SMP 和 MPP
- lambda 架构
- Kappa 架构
前言
本文我们将研究不同类型的大数据架构设计,将讨论 OLTP 和 OLAP 的系统设计,以及有效处理数据的策略包括 SMP 和 MPP 等概念。然后我们将了解经典的 Lambda 架构和 Kappa 架构。
OLTP 和 OLAP
在线事务处理(Online transaction processing)是一种用于在实时环境中处理CRUD 事务的系统,旨在支持高并发,事务性以及低延迟请求,比如说电商网站等。
联机分析处理(online analytical processing)系统对查询性能做了优化,用户可以通过 OLAP 系统快速查询分析数据并生成报表,OLTP 可以与 OLAP 结合使用,作为 OLAP 的数据源,通过 ETL 加载源数据至数据仓库,如下图所示: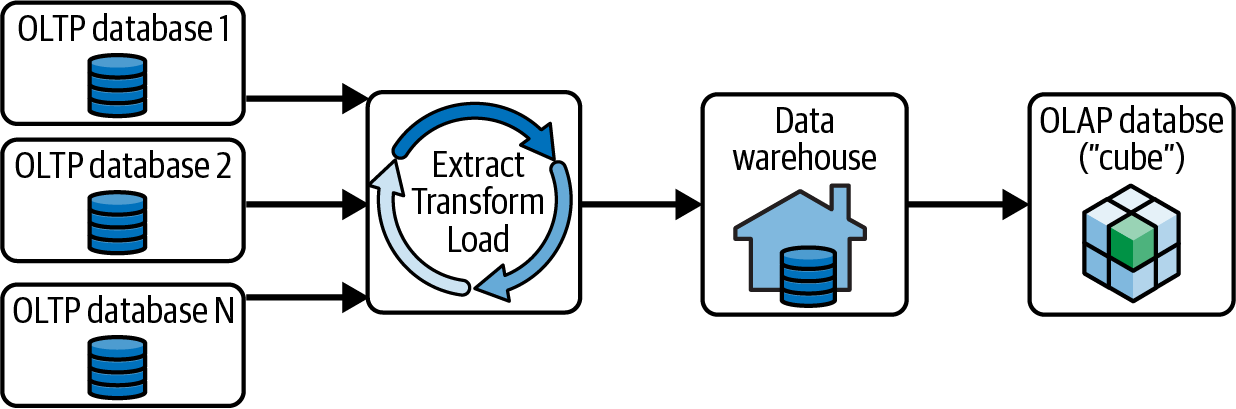
OLAP 数据集通常由多维数据组成,其中包含了事实表(Fact Table)和维度表(Dimension Table)。
事实表
- 事实表包含了业务过程中发生的事实或事件的详细数据,通常是数值型数据,如销售额、数量、利润等。事实表通常是一个大表,其行代表了每个事实事件的记录,而列则代表了与该事件相关的度量指标。每行数据都包含了一个或多个外键,用于连接到维度表,以提供更多关于事实的上下文信息。
维度表
- 维度表包含了描述事实表中数据的上下文信息,如时间、地点、产品、客户等。维度表是由唯一的、离散的值组成的,通常被用来对事实数据进行分类和分组。维度表的每一行代表一个维度的属性或值,而每一列代表一个特定的维度。维度表的关键属性是其主键,它与事实表中的外键相匹配,用于在事实表和维度表之间建立关联。
下表对比了 OLTP 与 OLAP:
| OLTP | OLAP | |
|---|---|---|
| 应用类型 | 事务型 | 分析型 |
| 数据性质 | 运营数据 | 合并数据 |
| 定位 | 应用程序 | 主题分析 |
| 目的 | 处理正在进行的业务任务 | 有助于决策 |
| 事务频率 | 频繁 | 偶尔 |
| 操作类型 | CRUD | 读取大量数据 |
| 数据设计 | 三范式 | 非三范式 |
| 常见用法 | 用于零售销售和其他金融交易系统 | 常用于数据挖掘、销售和营销 |
| 响应时间 | 响应时间是即时的 | 响应时间从几秒到几小时不等 |
| 查询复杂度 | 简单即时的查询 | 复杂查询 |
| 使用模式 | 重复使用 | 临时使用 |
| 事务性质 | 事务时间短、简单 | 复杂查询 |
| 数据库大小 | 千兆字节数据库大小 | TB 数据库大小 |
OLAP 数据库提供了一种分析存储在 DW 中的数据的方法,这种方式比在包含大量数据的 DW 上执行传统的基于 SQL 的查询更加灵活和有交互性。
运营产生和用于分析的数据
运营产生的数据是公司业务线正常运行产生的数据,存储在 OLTP 系统中。
分析所用的数据来自运营数据的采集和转换后的数据,存储在数据仓库中,通过 OLAP 系统查询分析,生成报表。
SMP 和 MPP
在大数据领域中,对称多处理(Symmetric Multiprocessing,SMP)和大规模并行处理(Massively Parallel Processing,MPP)是两种常见的处理架构,用于处理和分析大规模数据集。
对称多处理(SMP)
- 对称多处理是一种共享存储器的处理架构,其中包含多个处理器核心(通常是对称的),这些核心共享系统的内存和其他资源。在SMP系统中,所有处理器核心可以访问相同的存储器和数据,因此可以同时处理和操作相同的数据集。这种架构适用于对数据进行并发处理和分析,但可能会受到内存带宽和共享资源的限制。
大规模并行处理(MPP)
- 大规模并行处理是一种分布式处理架构,其中包含多个处理节点(通常是非对称的),每个节点都具有自己的处理器、内存和存储器。在MPP系统中,数据被分割成多个部分,并分配到不同的处理节点上并行处理。每个节点独立地处理其分配的数据部分,然后将结果合并以生成最终的分析结果。MPP系统通常具有良好的可扩展性和性能,适用于处理大规模数据集和复杂的分析任务。
总的来说,SMP适用于对数据进行并发处理和分析,而MPP则适用于处理大规模数据集和复杂的分析任务,具有更好的可扩展性和性能。在选择处理架构时,需要考虑数据规模、处理需求、性能要求以及系统成本等因素。
下图是 SMP 和 MPP 数据库设计的对比: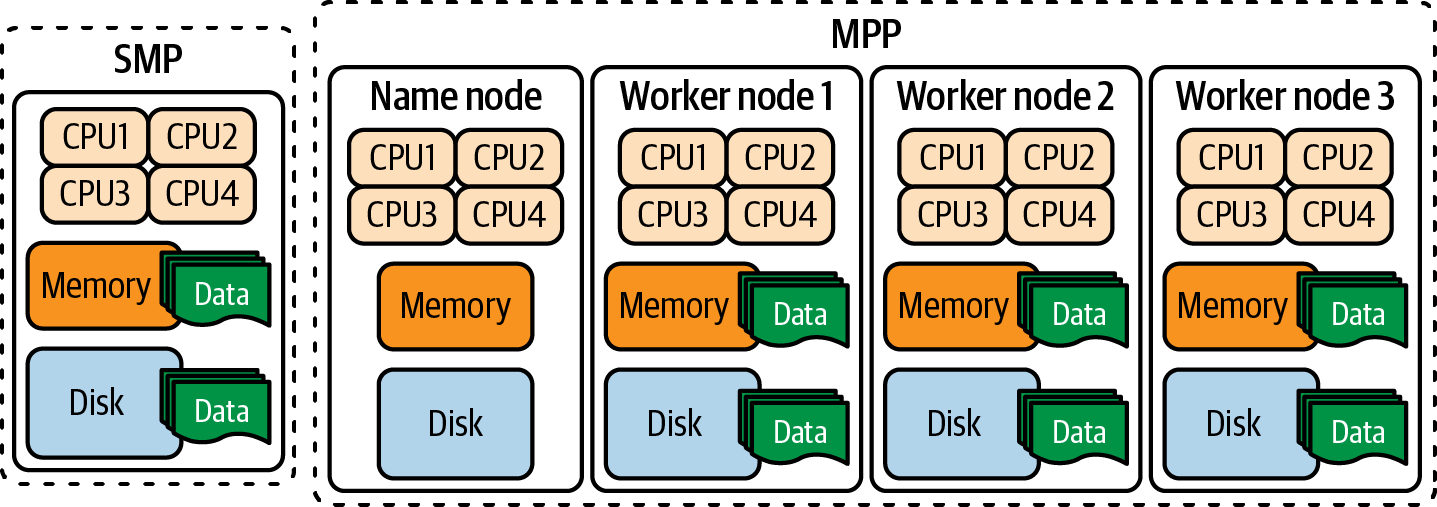
lambda 架构
Lambda架构是一种大数据处理架构,旨在通过使用批处理和实时流处理方法来处理海量数据。其想法是通过使用批处理获得全面、准确的批量数据视图,并平衡延迟、吞吐量、扩展和容错能力,同时使用实时流处理提供在线数据的视图(例如物联网设备、 Twitter 源或计算机日志文件)。
该架构通过包含批处理和流处理来同时满足查询历史数据和实时数据的需求,架构设计的三个关键原则如下:
双数据模型
- Lambda 架构使用一种模型进行批处理(批处理层),另一种模型进行实时处理(流层)。这使得系统能够处理批量和实时数据,并以可扩展和容错的方式执行这两种类型的处理。
单一统一视图
- Lambda 架构使用单个统一视图(称为应用层)向最终用户呈现批处理和实时处理的结果。这使得用户可以看到完整且最新的数据视图,即使数据正在由两个不同的系统处理。
解耦处理层
- Lambda 架构将批处理层和实时处理层解耦,使它们可以独立扩展、单独开发和维护,从而实现灵活性和易于开发。
下图是 lambda 架构的概述: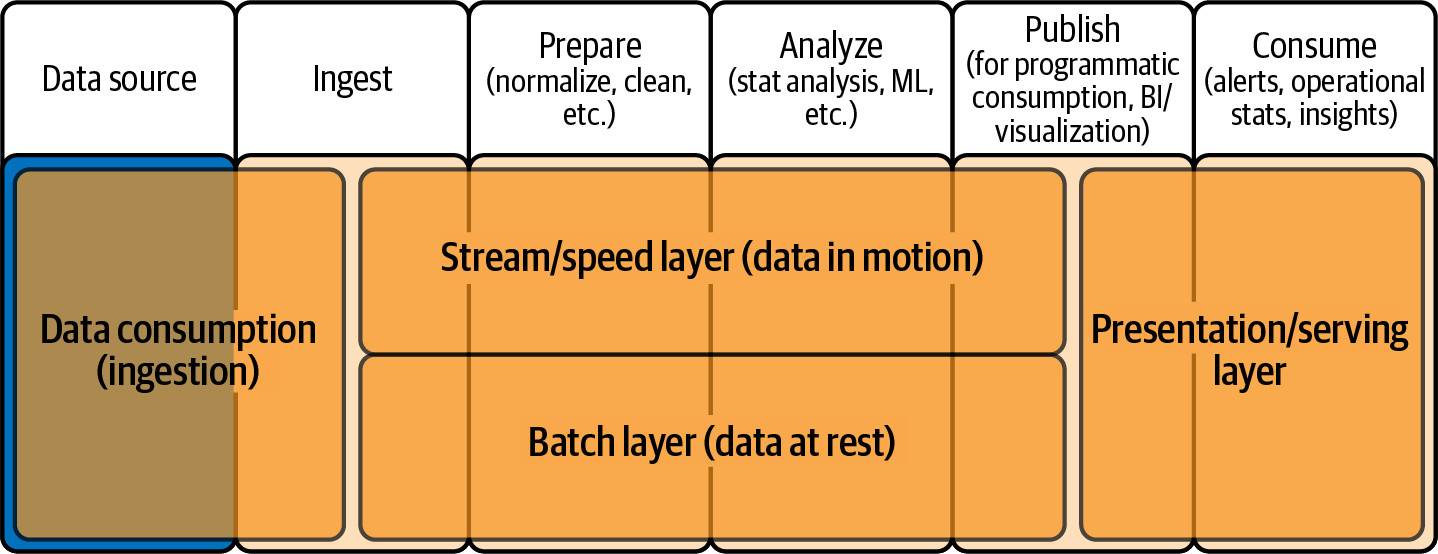
- 数据消费层:接入多个数据源的数据,包括属实时流数据和批数据
- 流处理层:增量更新流数据,该层的数据可能存在数据质量问题
- 批处理层:批处理层的数据是真实可靠的,会对流处理层的数据进行校验,批处理层的数据会进行大量的 ETL 任务。
- 应用层:可以同时对外提供实时的可能存在数据质量问题的流数据和准确的批处理数据,默认对外提供批数据。
lambda 架构的缺点
- **复杂:**需要同时维护实时和批处理两套系统
- 实时处理性能有限:对于大量数据的实时处理不如 Kappa 架构
- 对状态处理的支持有限:Lambda 架构专为无状态处理而设计,可能不太适合需要跨多个事件维护状态的应用程序。例如,一家零售商店,其推荐系统根据客户的浏览和购买行为推荐产品。如果该系统使用 Lambda 架构,单独处理每个事件而不维护状态,则可能会错过客户的购物旅程和意图。如果客户浏览鞋子,然后浏览袜子,然后浏览鞋油,无状态系统可能无法正确推荐相关商品,因为它不考虑事件的顺序。它还可能会推荐客户购物车中已有的商品。
总的来说,如果需要构建一个既可以处理批量数据又可以处理实时数据但需要提供单一统一数据视图的分布式系统,应该考虑 Lambda 架构。如果需要有状态处理或处理大量实时数据,您可能需要考虑 Kappa 架构。
Kappa 架构
与旨在处理实时和批量数据的 Lambda 架构不同,Kappa 旨在仅处理实时数据,该架构的三个关键原则:
实时处理
- Kappa 架构专为实时处理而设计,这意味着事件在收到后立即进行处理,而不是稍后进行批量处理。这减少了延迟并使系统能够快速响应不断变化的条件。
单一事件流
- Kappa 架构使用单个事件流来存储流经系统的所有数据。这有很好的可扩展性和容错能力,因为数据可以轻松地分布在多个节点上。
无状态处理
- 在Kappa架构中,所有处理都是无状态的。这意味着每个事件都是独立处理的,不依赖于先前事件的状态。这使得扩展系统变得更容易,因为不需要跨多个节点维护状态。
下图是对 Kappa 架构的一个概述:
Kappa 架构的缺点
复杂
- Kappa 架构涉及单个事件流和无状态处理,这比其他架构的实现和维护更加复杂。
批处理支持有限
- Kappa架构是为实时处理而设计的,不容易支持历史数据的批量处理。如果需要执行批处理,可能需要考虑 Lambda 架构。
对即席查询的支持有限
- 由于 Kappa 架构是为实时处理而设计的,因此它可能不太适合需要处理大量历史数据的即席查询。
总的来说,Kappa 架构是构建需要实时处理大量数据、需要可扩展、容错和低延迟的分布式系统的绝佳选择,比如说流媒体平台和金融交易系统。但是,如果需要执行批处理或支持即席查询,那么 Lambda 架构可能是更好的选择。