AI目录:sheng的学习笔记-AI目录-CSDN博客
目录
什么是决策树
划分选择
信息增益
增益率
基尼指数
剪枝处理
预剪枝
后剪枝
连续值处理
另一个例子
基本步骤
排序
计算候选划分点集合
评估分割点
每个分割点都进行评估,找到最大信息增益的划分点
递归分割
缺失值处理
示例
多变量决策树
“斜决策树”(obliquedecision tree)
什么是决策树
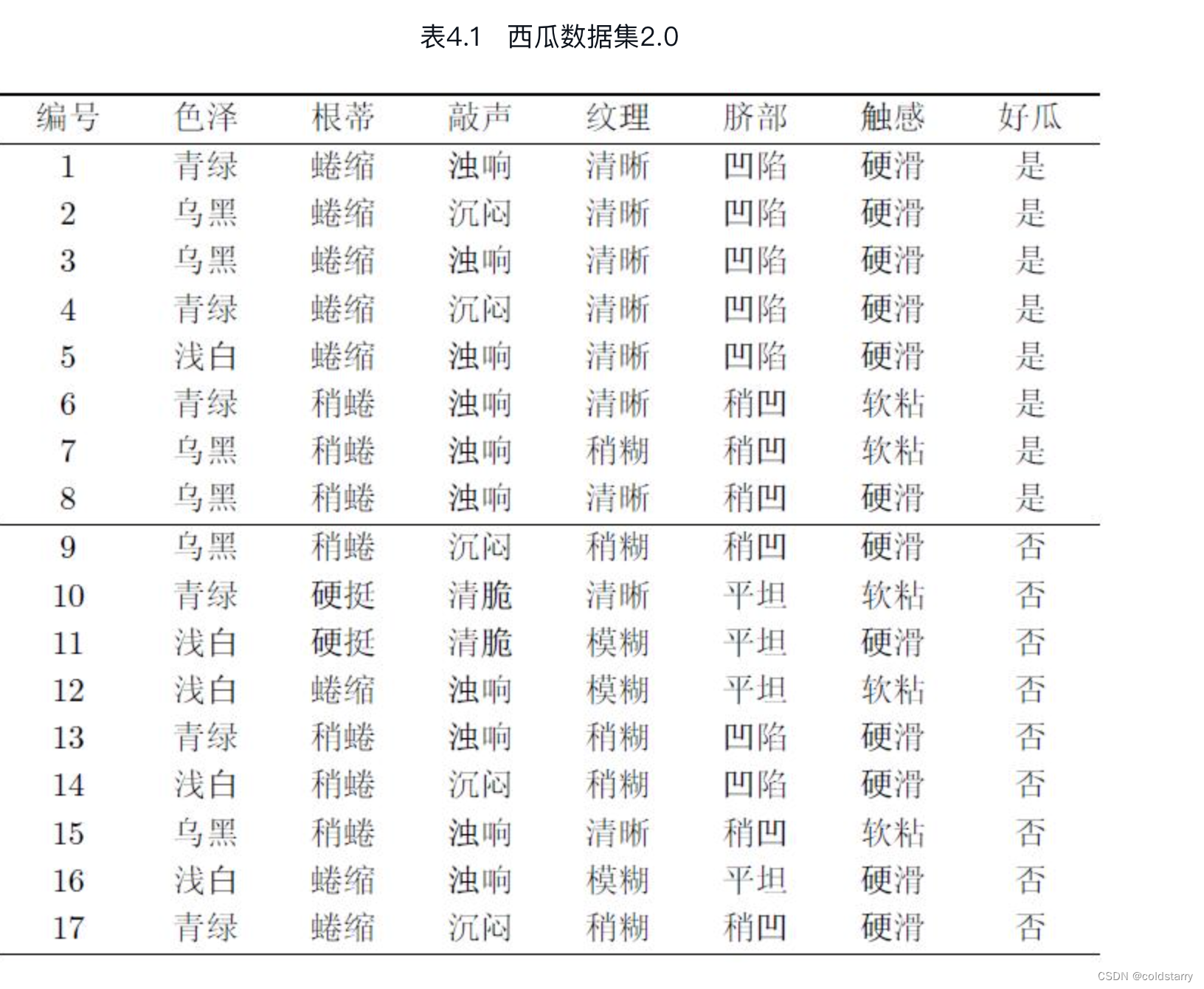
决策树(decision tree)是一类常见的机器学习方法。以二分类任务为例,我们希望从给定训练数据集学得一个模型用以对新示例进行分类,这个把样本分类的任务,可看作对“当前样本属于正类吗?”这个问题的“决策”或“判定”过程。顾名思义,决策树是基于树结构来进行决策的,这恰是人类在面临决策问题时一种很自然的处理机制。例如,我们要对“这是好瓜吗?”这样的问题进行决策时,通常会进行一系列的判断或“子决策”:我们先看“它是什么颜色?”,如果是“青绿色”,则我们再看“它的根蒂是什么形态?”,如果是“蜷缩”,我们再判断“它敲起来是什么声音?”,最后,我们得出最终决策:这是个好瓜。
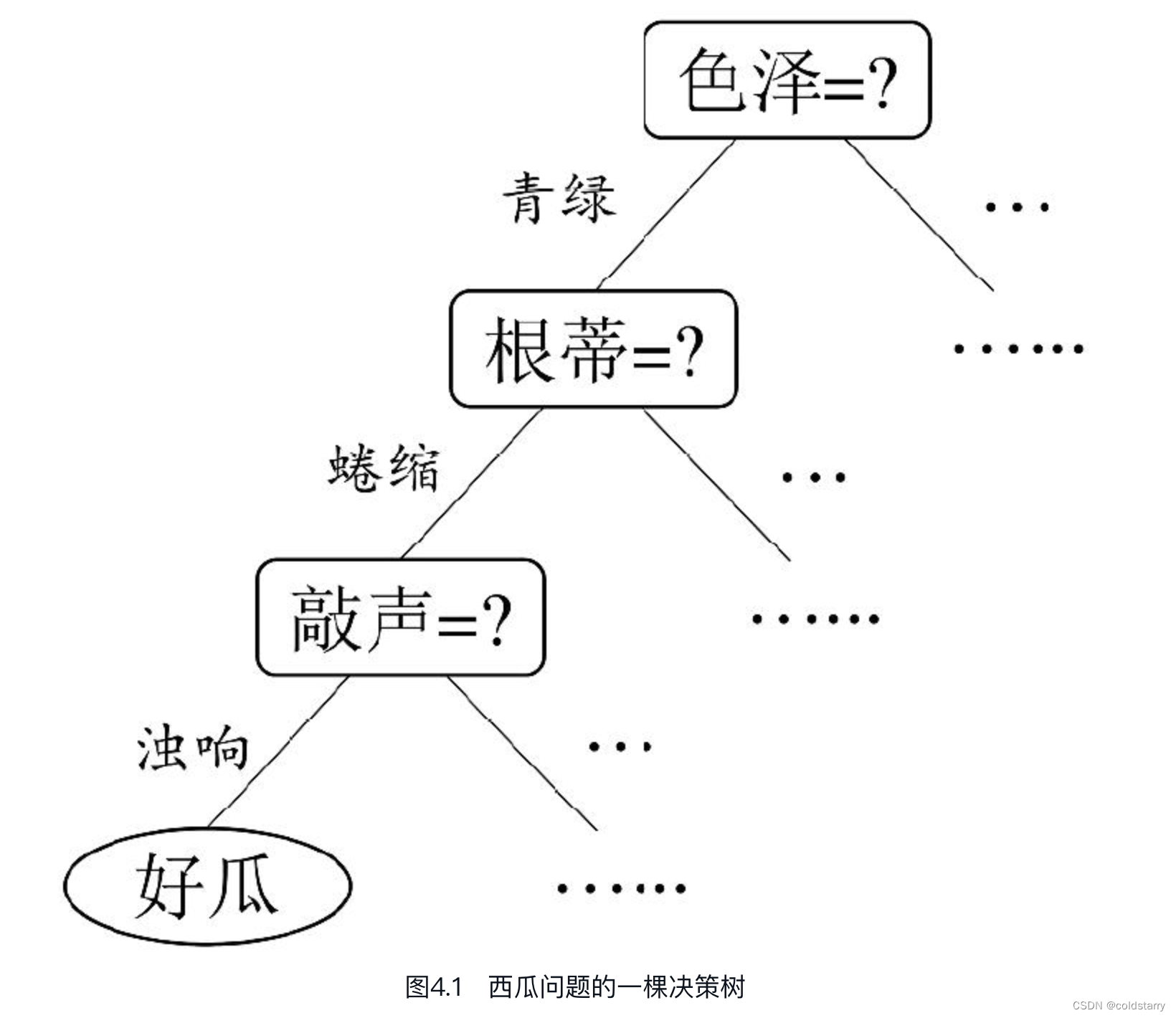
图4.1 西瓜问题的一棵决策树显然,决策过程的最终结论对应了我们所希望的判定结果,例如“是”或“不是”好瓜;决策过程中提出的每个判定问题都是对某个属性的“测试”,例如“色泽=?”“根蒂=?”;每个测试的结果或是导出最终结论,或是导出进一步的判定问题,其考虑范围是在上次决策结果的限定范围之内,例如若在“色泽=青绿”之后再判断“根蒂=?”,则仅在考虑青绿色瓜的根蒂。
一般的,一棵决策树包含一个根结点、若干个内部结点和若干个叶结点;叶结点对应于决策结果,其他每个结点则对应于一个属性测试;每个结点包含的样本集合根据属性测试的结果被划分到子结点中;根结点包含样本全集。从根结点到每个叶结点的路径对应了一个判定测试序列。决策树学习的目的是为了产生一棵泛化能力强,即处理未见示例能力强的决策树,其基本流程遵循简单且直观的“分而治之”(divide-and-conquer)策略
划分选择
一般而言,随着划分过程不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的“纯度”(purity)越来越高。
选定分裂准则(比如基尼指数)之后,在进行节点分裂时,针对每个特征变量,首先寻找最优临界值(cut) ,并计算以该变量为分裂变量可带来节点不纯度函数之下降幅度。然后,选择可使节点不纯度下降最多的变量作为分裂变量
信息增益

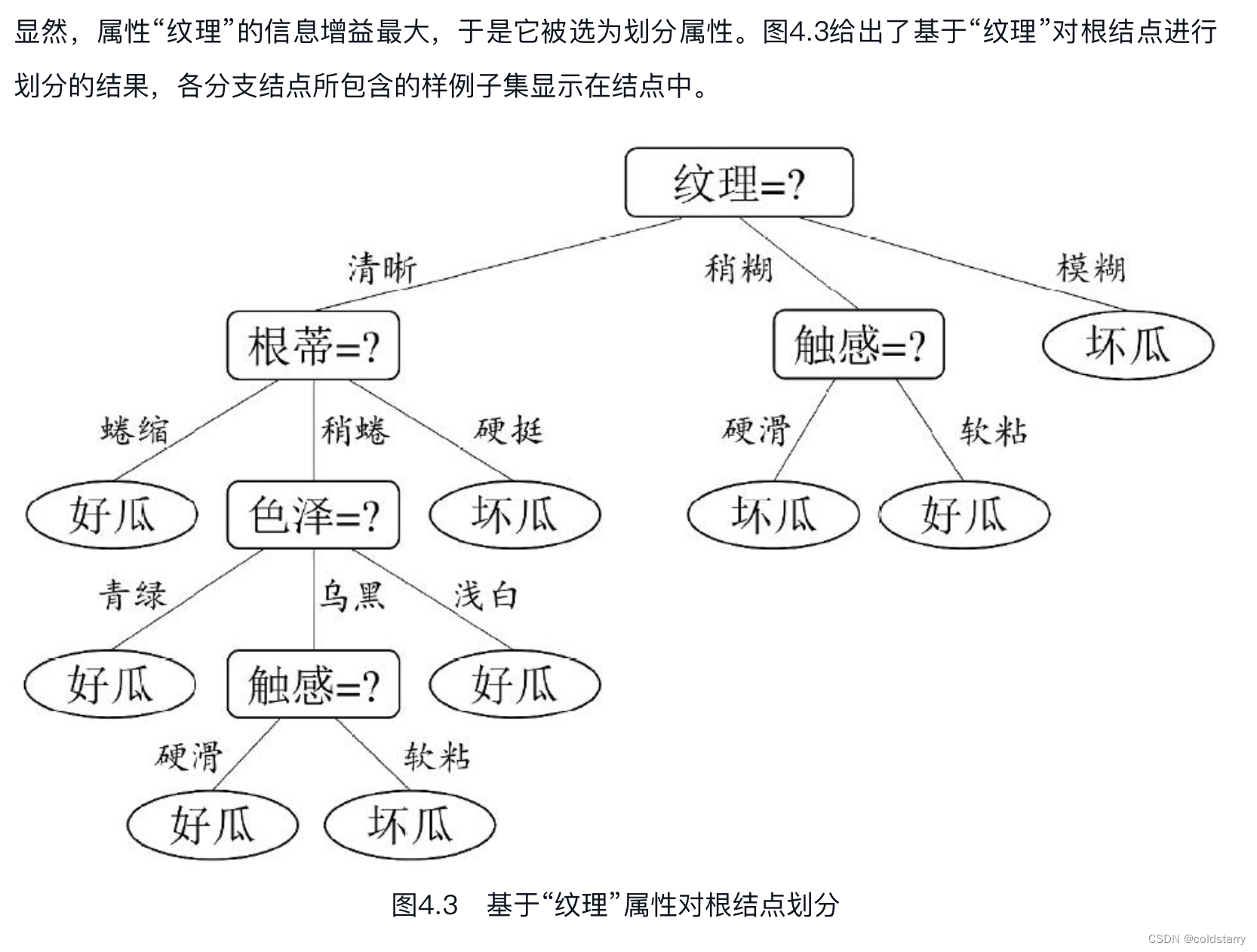
一般而言,信息增益越大,则意味着使用属性a来进行划分所获得的“纯度提升”越大。因此,我们可用信息增益来进行决策树的划分属性选择

然后,我们要计算出当前属性集合{色泽,根蒂,敲声,纹理,脐部,触感}中每个属性的信息增益。以属性“色泽”为例,它有3个可能的取值:{青绿,乌黑,浅白}。若使用该属性对D进行划分,则可得到3个子集,分别记为:D1(色泽=青绿),D2(色泽=乌黑),D3(色泽=浅白)。
然后,我们要计算出当前属性集合{色泽,根蒂,敲声,纹理,脐部,触感}中每个属性的信息增益。以属性“色泽”为例,它有3个可能的取值:{青绿,乌黑,浅白}。若使用该属性对D进行划分,则可得到3个子集,分别记为:D1(色泽=青绿),D2(色泽=乌黑),D3(色泽=浅白)。

从上面的Ent(D)可以看出来,纯度可以理解为节点分类的确定性,比如属于第1类的概率为1,属于第0类的概率为0,显然这是的确定性是最高的,因而此时的纯度也是也是最高的;如果属于第1类的概率为0.5,属于第0类的概率也为0.5,显然,此时很难确定,因而纯度是最低的。D1在6个样本中占比是3:3,但D2的占比是4:2,所以D2的纯度高,Ent(D2)小
对于信息增益:类似的,我们可计算出其他属性的信息增益:
Gain(D,根蒂)=0.143;
Gain(D,敲声)=0.141;
Gain(D,纹理)=0.381;
Gain(D,脐部)=0.289;
Gain(D,触感)=0.006。

增益率
在上面的介绍中,我们有意忽略了表4.1中的“编号”这一列。若把“编号”也作为一个候选划分属性,则根据式(4.2)可计算出它的信息增益为0.998,远大于其他候选划分属性。这很容易理解:“编号”将产生17个分支,每个分支结点仅包含一个样本,这些分支结点的纯度已达最大。然而,这样的决策树显然不具有泛化能力,无法对新样本进行有效预测。
实际上,信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,著名的C4.5决策树算法[Quinlan,1993]不直接使用信息增益,而是使用“增益率”(gain ratio)来选择最优划分属性。采用与式(4.2)相同的符号表示,增益率定义为

基尼指数
CART是Classification and Regression Tree的简称,这是一种著名的决策树学习算法,分类和回归任务都可用。
CART决策树[Breiman et al.,1984]使用“基尼指数”(Gini index)来选择划分属性.采用与式(4.1)相同的符号,数据集D的纯度可用基尼值来度量

剪枝处理
剪枝(pruning)是决策树学习算法对付“过拟合”的主要手段.在决策树学习中,为了尽可能正确分类训练样本,结点划分过程将不断重复,有时会造成决策树分支过多,这时就可能因训练样本学得“太好”了,以致于把训练集自身的一些特点当作所有数据都具有的一般性质而导致过拟合。因此,可通过主动去掉一些分支来降低过拟合的风险。
决策树剪枝的基本策略有“预剪枝”(prepruning)和“后剪枝”(postpruning)。
- 预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点;
- 后剪枝则是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
预剪枝
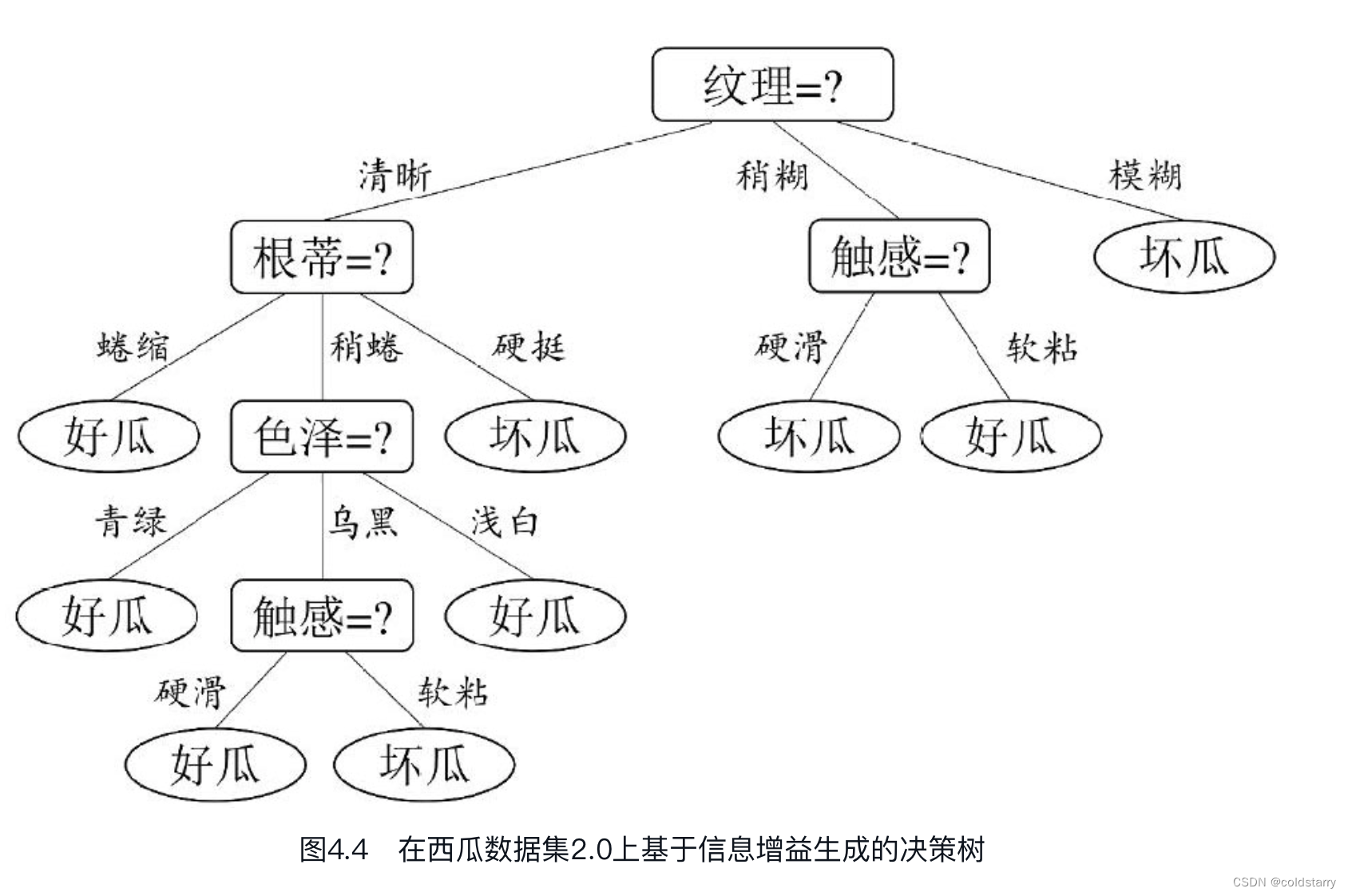
基于信息增益准则,我们会选取属性“脐部”来对训练集进行划分,并产生3个分支,如图4.6所示。然而,是否应该进行这个划分呢?预剪枝要对划分前后的泛化性能进行估计。
通过对划分前后的验证集的精度比对,判断是否需要划分
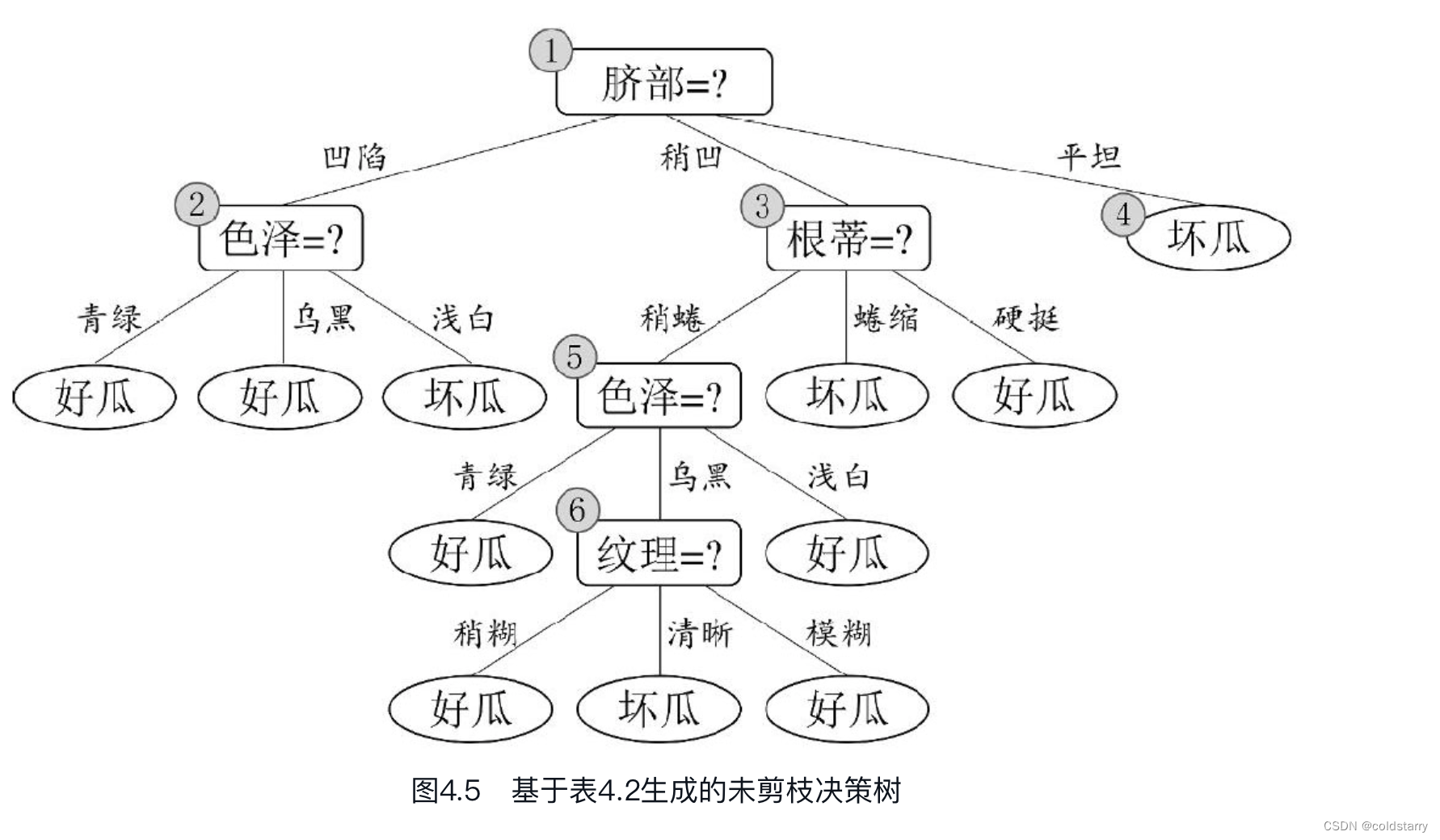

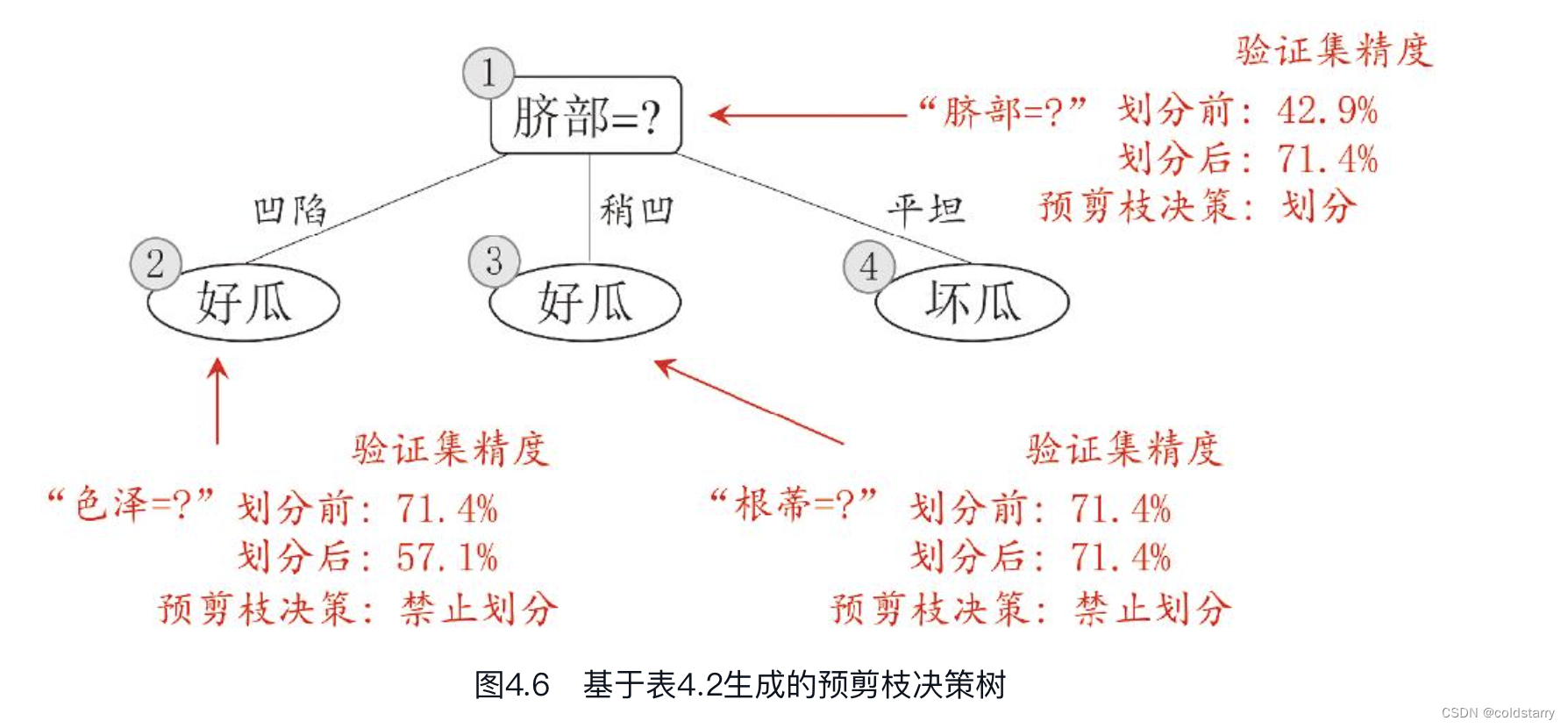
对比图4.6和图4.5可看出,预剪枝使得决策树的很多分支都没有“展开”,这不仅降低了过拟合的风险,还显著减少了决策树的训练时间开销和测试时间开销。但另一方面,有些分支的当前划分虽不能提升泛化性能、甚至可能导致泛化性能暂时下降,但在其基础上进行的后续划分却有可能导致性能显著提高;预剪枝基于“贪心”本质禁止这些分支展开,给预剪枝决策树带来了欠拟合的风险。
后剪枝

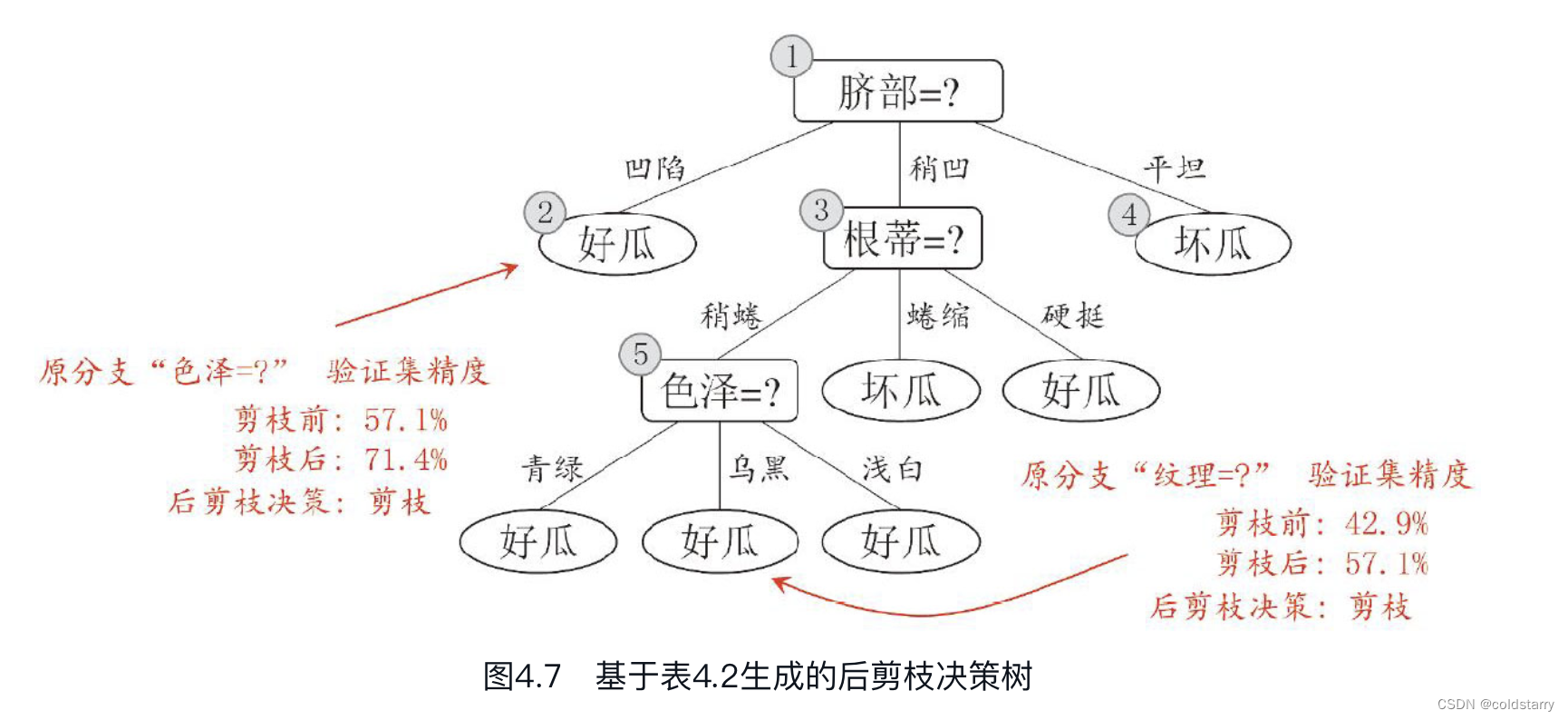
对比图4.7和图4.6可看出,后剪枝决策树通常比预剪枝决策树保留了更多的分支。一般情形下,后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝决策树。但后剪枝过程是在生成完全决策树之后进行的,并且要自底向上地对树中的所有非叶结点进行逐一考察,因此其训练时间开销比未剪枝决策树和预剪枝决策树都要大得多
连续值处理
到目前为止我们仅讨论了基于离散属性来生成决策树。现实学习任务中常会遇到连续属性,有必要讨论如何在决策树学习中使用连续属性
由于连续属性的可取值数目不再有限,因此,不能直接根据连续属性的可取值来对结点进行划分。此时,连续属性离散化技术可派上用场。最简单的策略是采用二分法(bi-partition)对连续属性进行处理

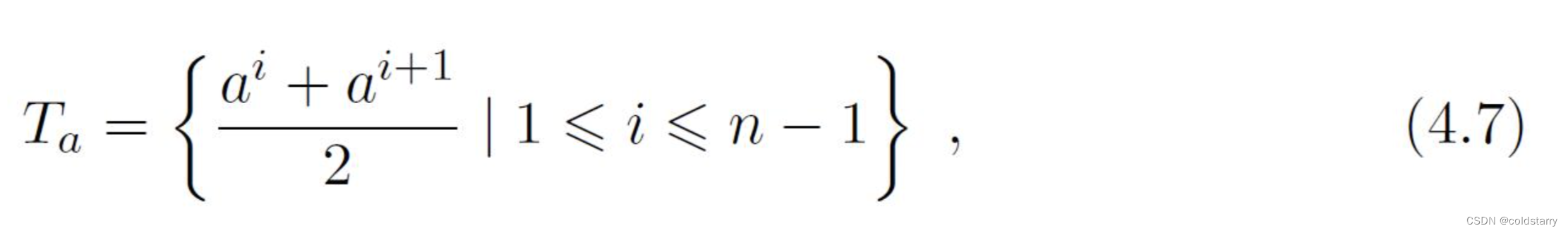
可将划分点设为该属性在训练集中出现的不大于中位点的最大值,从而使得最终决策树使用的划分点都在训练集中出现过
其中Gain(D,a,t)是样本集D基于划分点t二分后的信息增益。于是,我们就可选择使Gain(D,a,t)最大化的划分点。
作为一个例子,我们在表4.1的西瓜数据集2.0上增加两个连续属性“密度”和“含糖率”,得到表4.3所示的西瓜数据集3.0。下面我们用这个数据集来生成一棵决策树。

对属性“密度”,在决策树学习开始时,根结点包含的17个训练样本在该属性上取值均不同。根据式(4.7),该属性的候选划分点集合包含16个候选值:T密度={0.244,0.294,0.351,0.381,0.420,0.459,0.518,0.574,0.600,0.621,0.636,0.648,0.661,0.681,0.708,0.746}。由式(4.8)可计算出属性“密度”的信息增益为0.262,对应于划分点0.381。
对属性“含糖率”,其候选划分点集合也包含16个候选值:T含糖率={0.049,0.074,0.095,0.101,0.126,0.155,0.179,0.204,0.213,0.226,0.250,0.265,0.292,0.344,0.373,0.418}。类似的,根据式(4.8)可计算出其信息增益为0.349,对应于划分点0.126。
再由4.2.1节可知,表4.3的数据上各属性的信息增益为
Gain(D,色泽)=0.109;Gain(D,根蒂)=0.143;
Gain(D,敲声)=0.141;Gain(D,纹理)=0.381;
Gain(D,脐部)=0.289;Gain(D,触感)=0.006;
Gain(D,密度)=0.262;Gain(D,含糖率)=0.349。
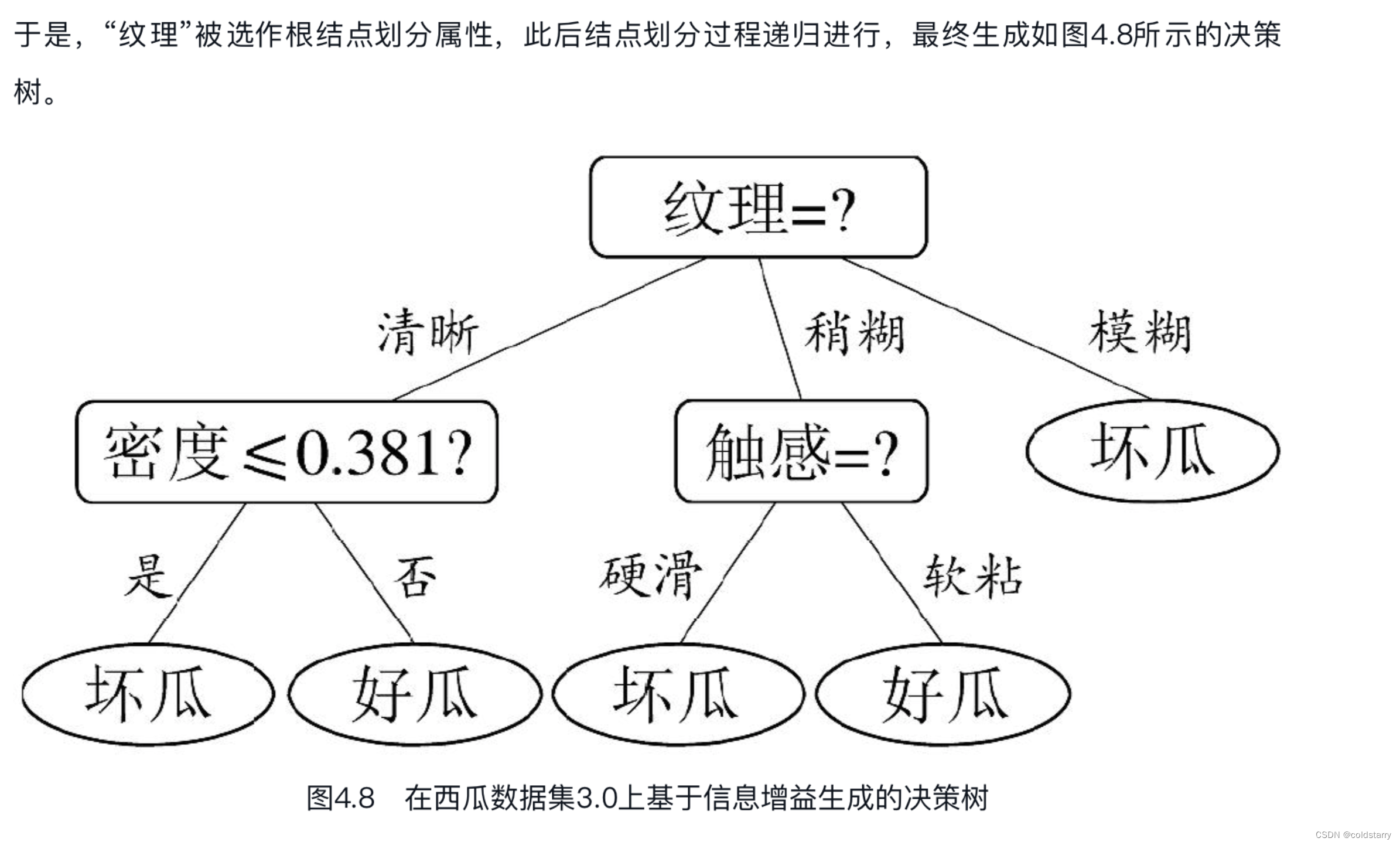
与离散属性不同,若当前结点划分属性为连续属性,该属性还可作为其后代结点的划分属性。
另一个例子
感觉书里写的不是很清楚,用另一个例子来说明一下
基本步骤
- 特征排序:首先,对每个连续型特征的所有可能值进行排序。
- 选择分割点:在排序后的值之间寻找可能的分割点,通常是相邻两个值的中点。
- 评估分割点:对于每个可能的分割点,评估分割后数据的纯度或信息增益,常用的评估标准包括基尼不纯度、信息增益或均方误差。
- 选择最佳分割点:针对每个连续型特征,选择使得分割后数据纯度最高或信息增益最大的分割点,这个点将被用来定义决策树的一个节点,将数据划分为两个子集。
- 递归分割:在分割数据后,算法会在两个生成的数据子集上重复以上过程,继续选择最佳分割点,直到满足停止条件,如达到预设的最大深度、节点中的数据点数目下降到某个阈值、分割后的纯度改进不显著等。
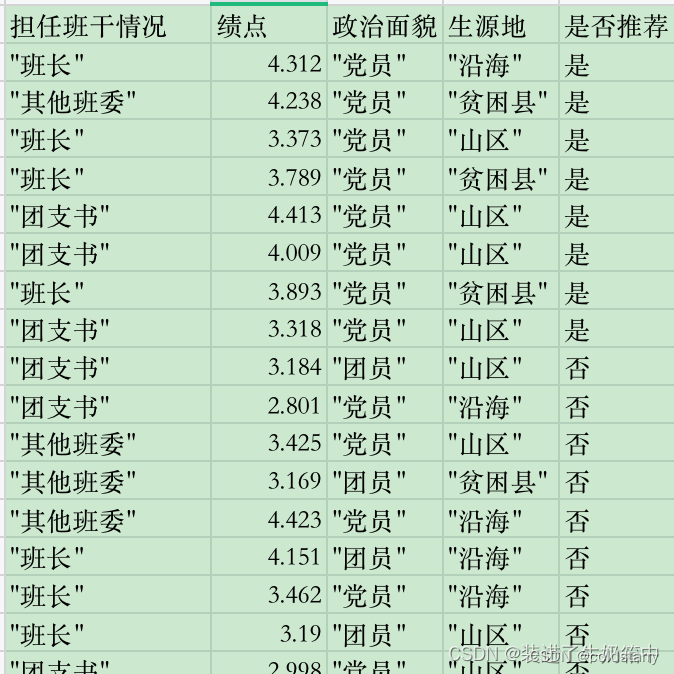
数据集合:
排序
将连续属性a在样本集D上出现的n个不同的取值从小到大排列,记为。基于划分点t,可将D分为子集
和
,其中
包含那些在属性a上取值不大于t的样本,
包含那些在属性a上取值大于t的样本。考虑包含n-1个元素的候选划分点集合
即把区间[)的中位点
作为 候选划分点
将连续属性绩点在样本集D上出现的17个不同的取值从小到大排序
2.801 2.998 3.169 3.184 3.190 3.318 3.373 3.425 3.462
3.789 3.893 4.009 4.151 4.238 4.312 4.413 4.423
计算候选划分点集合
2.900 3.083 3.176 3.187 3.254 3.346 3.399 3.444
3.630 3.845 3.951 4.080 4.194 4.275 4.363 4.418
评估分割点
采用离散属性值方法,计算这些划分点的增益,选取最优的划分点进行样本集合的划分 :
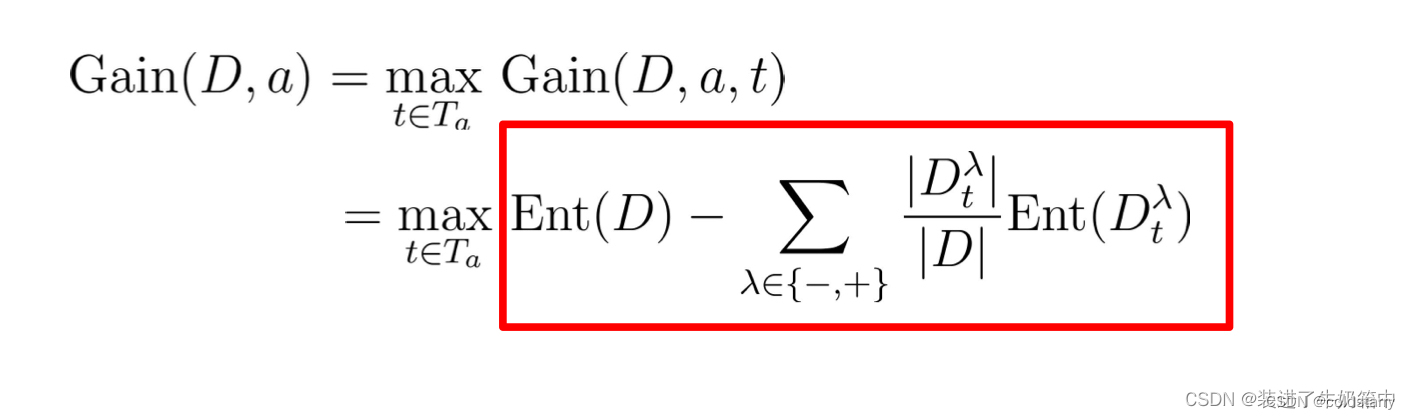

每个分割点都进行评估,找到最大信息增益的划分点
递归分割
缺失值处理
现实任务中常会遇到不完整样本,即样本的某些属性值缺失。例如由于诊测成本、隐私保护等因素,患者的医疗数据在某些属性上的取值(如HIV测试结果)未知;尤其是在属性数目较多的情况下,往往会有大量样本出现缺失值.如果简单地放弃不完整样本,仅使用无缺失值的样本来进行学习,显然是对数据信息极大的浪费。例如,表4.4是表4.1中的西瓜数据集2.0出现缺失值的版本,如果放弃不完整样本,则仅有编号{4,7,14,16}的4个样本能被使用
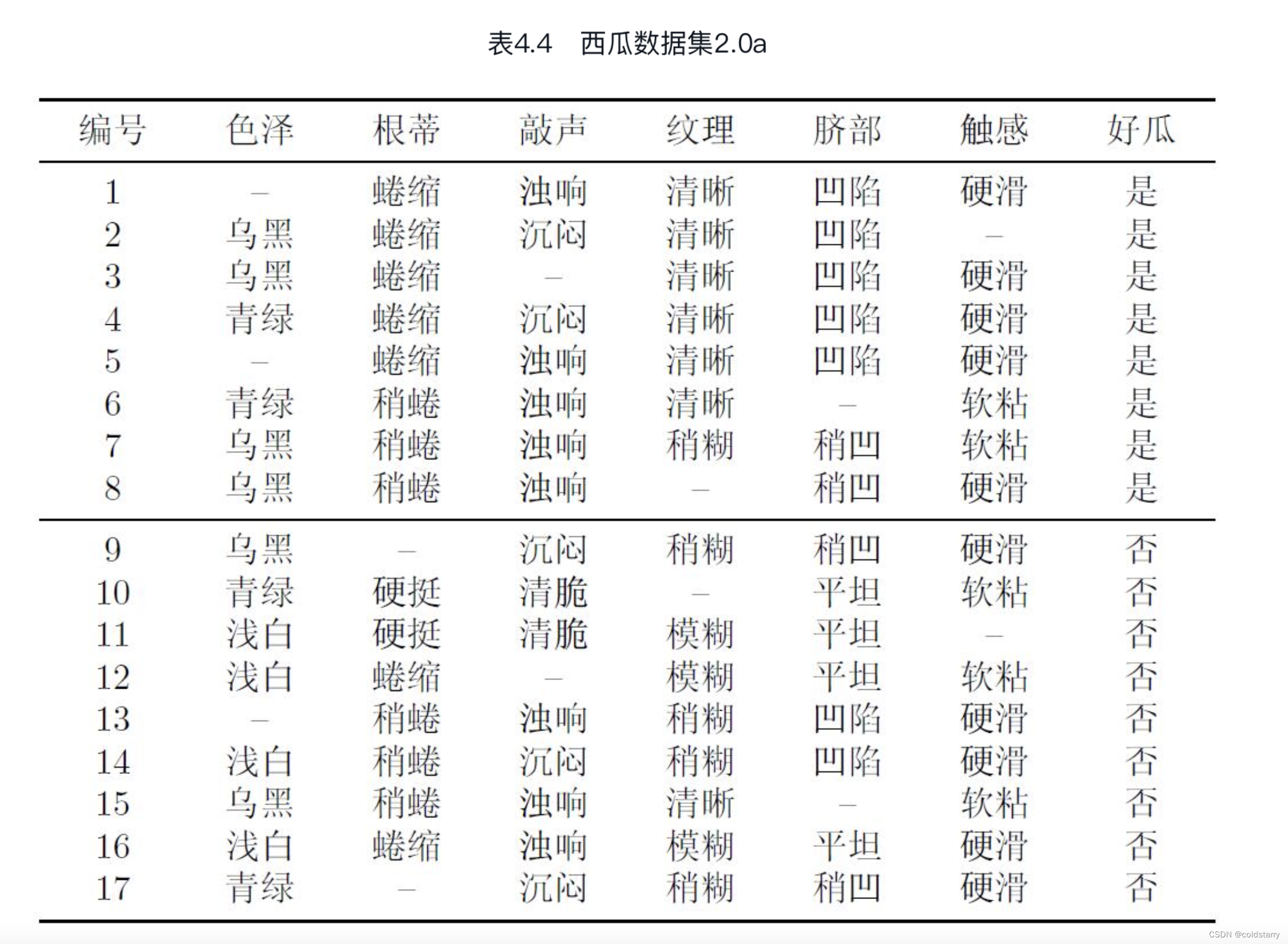
我们需解决两个问题:
(1)如何在属性值缺失的情况下进行划分属性选择?
(2)给定划分属性,若样本在该属性上的值缺失,如何对样本进行划分?
在决策树学习开始阶段,根结点中各样本的权重初始化为1。


示例


“纹理”在所有属性中取得了最大的信息增益,被用于对根结点进行划分.划分结果是使编号为{1,2,3,4,5,6,15}的样本进入“纹理=清晰”分支,编号为{7,9,13,14,17}的样本进入“纹理=稍糊”分支,而编号为{11,12,16}的样本进入“纹理=模糊”分支,且样本在各子结点中的权重保持为1。需注意的是,编号为{8}的样本在属性“纹理”上出现了缺失值,因此它将同时进入三个分支中,但权重在三个子结点中分别调整为7/15、5/15和3/15.编号为{10}的样本有类似划分结果。
多变量决策树
若我们把每个属性视为坐标空间中的一个坐标轴,则d个属性描述的样本就对应了d维空间中的一个数据点,对样本分类则意味着在这个坐标空间中寻找不同类样本之间的分类边界
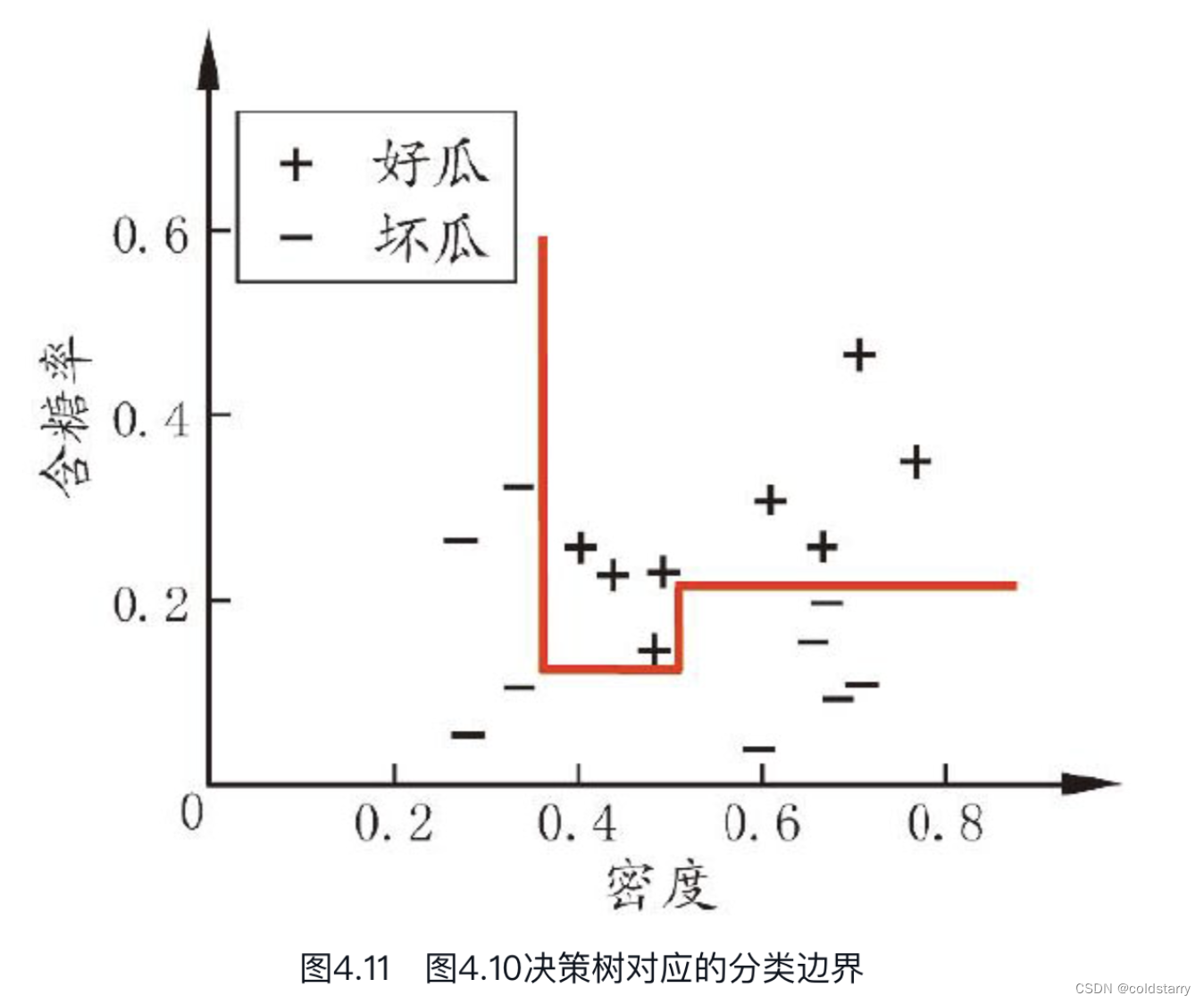
决策树所形成的分类边界有一个明显的特点:轴平行(axis-parallel),即它的分类边界由若干个与坐标轴平行的分段组成。
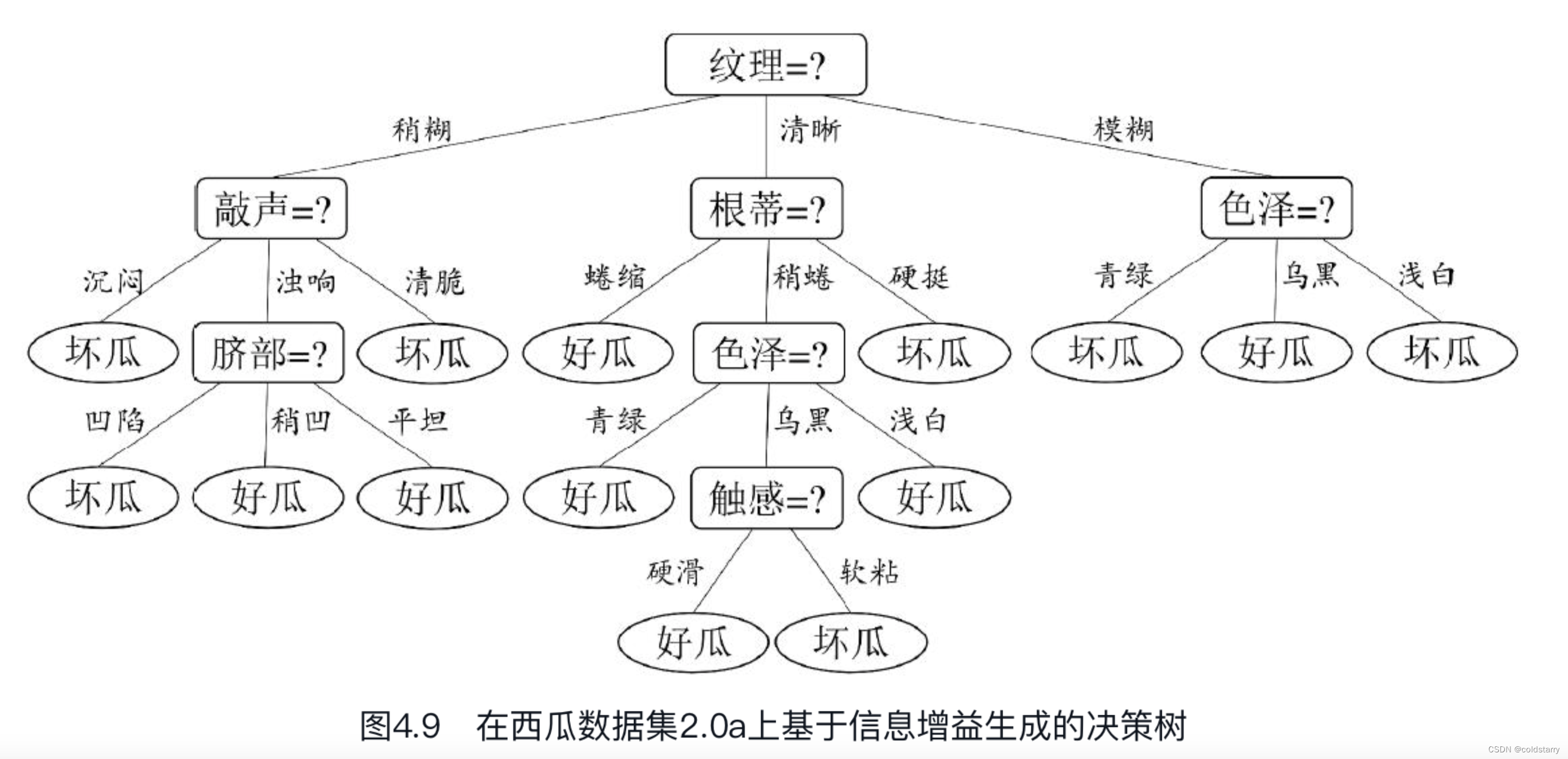
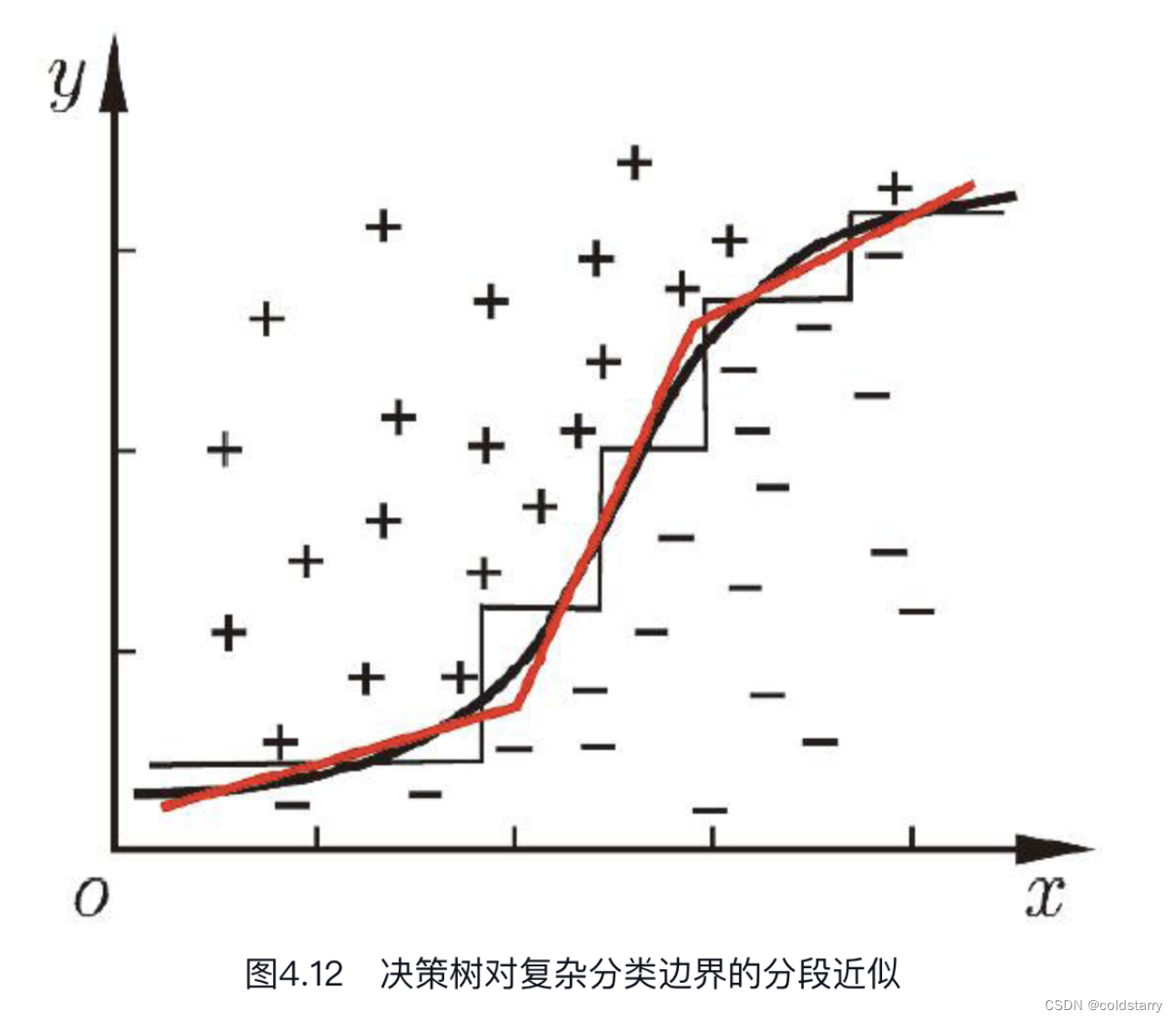
但在学习任务的真实分类边界比较复杂时,必须使用很多段划分才能获得较好的近似,如图4.12所示;此时的决策树会相当复杂,由于要进行大量的属性测试,预测时间开销会很大。
“斜决策树”(obliquedecision tree)

这样的多变量决策树亦称“斜决策树”(obliquedecision tree)。
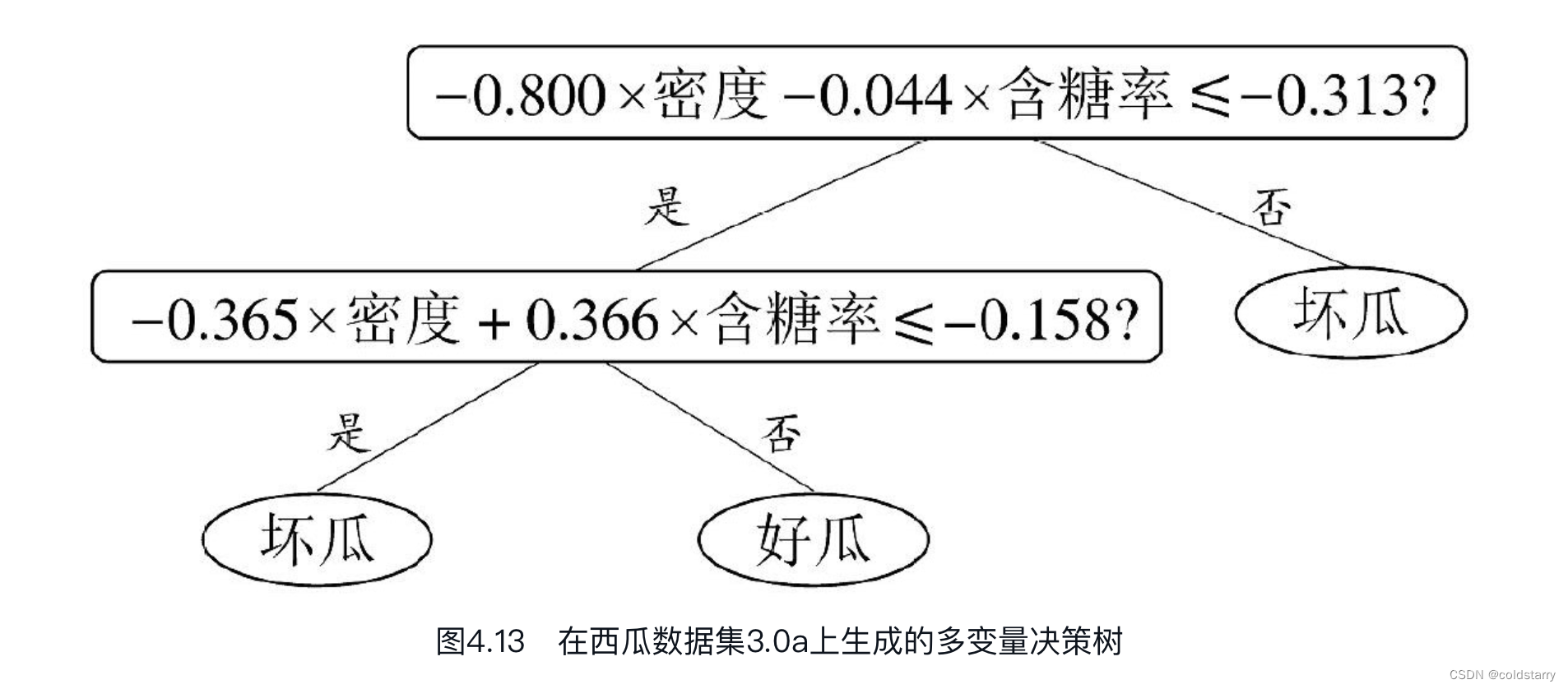
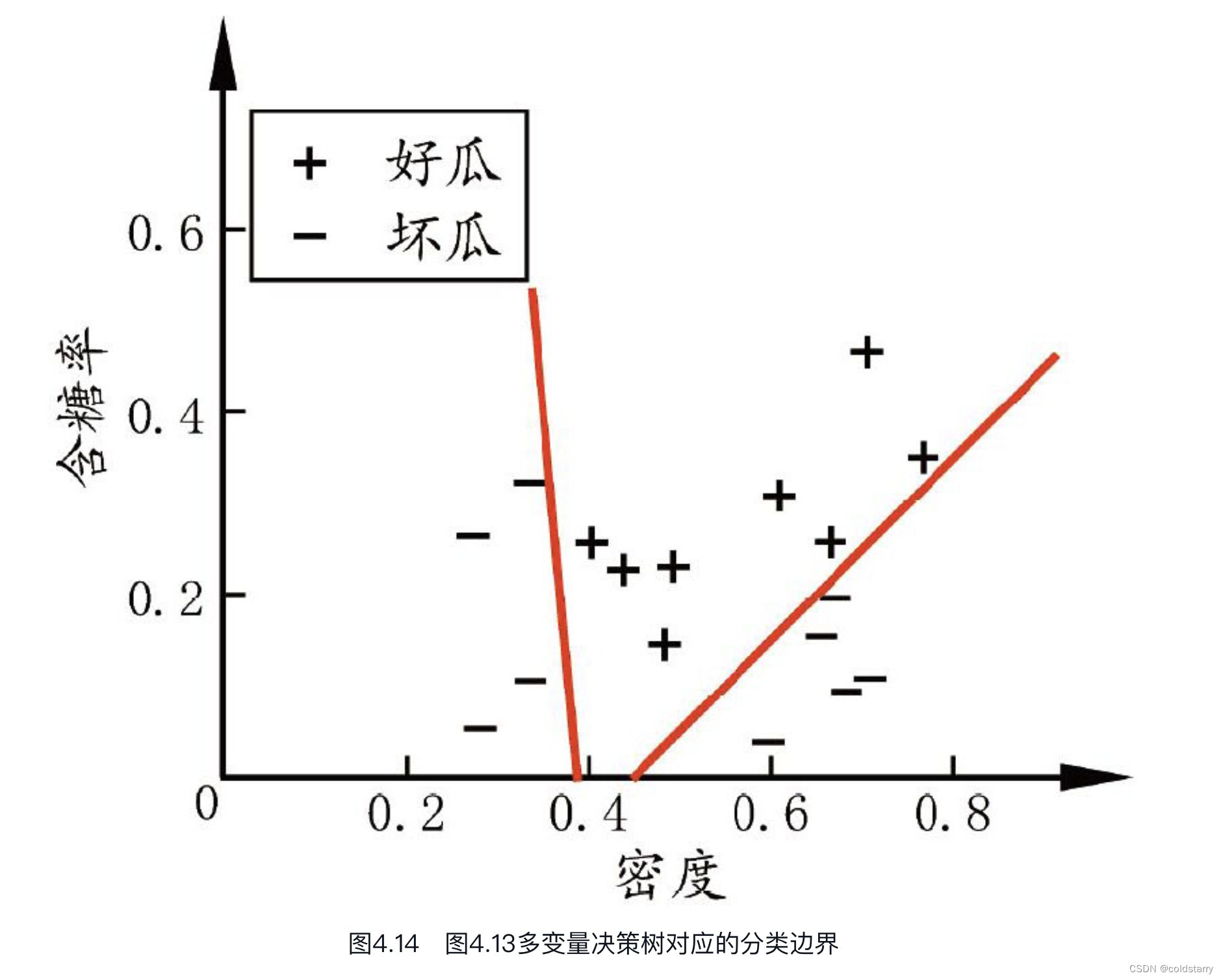
若能使用斜的划分边界,如图4.12中红色线段所示,则决策树模型将大为简化。“多变量决策树”(multivariate decision tree)就是能实现这样的“斜划分”甚至更复杂划分的决策树。以实现斜划分的多变量决策树为例,在此类决策树中,非叶结点不再是仅对某个属性,而是对属性的线性组合进行测试;换言之,每个非叶结点是一个形如[插图]的线性分类器,其中wi是属性ai的权重,wi和t可在该结点所含的样本集和属性集上学得。于是,与传统的“单变量决策树”(univariate decision tree)不同,在多变量决策树的学习过程中,不是为每个非叶结点寻找一个最优划分属性,而是试图建立一个合适的线性分类器.例如对西瓜数据3.0a,我们可学得图4.13这样的多变量决策树,其分类边界如图4.14所示。
参考文章
书:机器学习 周志华老师的作品,本篇学习笔记大部分来源于书的内容
机器学习方法(四):决策树Decision Tree原理与实现技巧-CSDN博客
决策树 - 知乎
机器学习——决策树之连续值处理_决策树如何处理连续值的特征-CSDN博客