Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境,它使得 JavaScript 可以脱离浏览器在服务器端运行。由于 Node.js 采用单线程异步非阻塞 I/O 模型,它的并发处理能力也是非常强大的。本文将详细介绍 Node.js 的并发原理、概念、图解、解决方案以及实际例子,并在最后进行总结。
并发原理与概念
事件循环与回调队列
Node.js 使用事件循环(Event Loop)模型来处理 I/O 操作和执行回调函数。事件循环模型中,所有任务被分为两类:同步任务和异步任务。同步任务在单个线程中执行,而异步任务则注册到回调队列中,等待事件循环处理。
非阻塞 I/O
Node.js 的 I/O 操作是非阻塞的,这意味着当一个 I/O 操作开始时,控制权会立即返回给 Node.js,允许它处理其他任务。一旦 I/O 操作完成,相应的回调函数会被放入回调队列,并在下一个事件循环迭代中执行。
并发控制图解
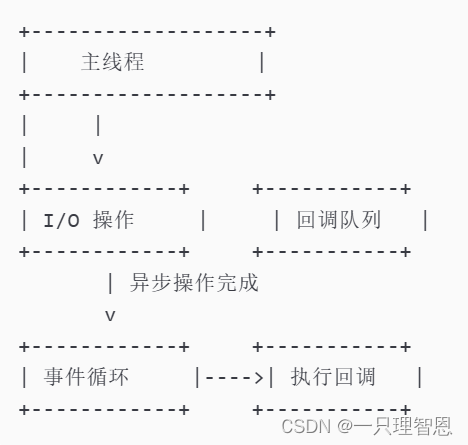
Node.js 并发解决方案
1. 使用 Promises
Promise 是异步编程的一种解决方案,它代表了一个可能还没有完成计算的值。在 Node.js 中,你可以使用 Promise 来处理异步操作的并发。
2. async/await
async/await 是基于 Promise 的另一种编写异步代码的方式,它可以让异步代码看起来像同步代码,使得逻辑更加清晰。
3. 子线程(Worker Threads)
Node.js 10 版本开始引入了 worker_threads 模块,允许创建子线程来执行 CPU 密集型任务,从而提高并发性能。
实际例子
以下是一个使用 async/await 处理并发的简单例子:
const http = require('http');
async function fetchData(urls) {
const results = [];
for (const url of urls) {
const data = await new Promise((resolve, reject) => {
const req = http.get(url, (res) => {
let body = '';
res.on('data', (chunk) => body += chunk);
res.on('end', () => resolve(body));
});
req.on('error', reject);
});
results.push(data);
}
return results;
}
fetchData(['http://example.com', 'http://another.com'])
.then((results) => {
console.log(results);
})
.catch((error) => {
console.error(error);
});4.集群(Cluster)模块来提高并发处理能力
在 Node.js 中,cluster 模块是一个基于内置的 HTTP 服务器的简单抽象,允许你创建多个工作进程来处理客户端请求。通过使用 cluster 模块,你可以利用服务器的多核 CPU 来提高应用程序的并发处理能力。每个工作进程都是 Node.js 运行时的一个独立实例,并且它们之间不会共享任何状态。
集群模块的工作原理
cluster 模块通过创建多个工作进程来实现并行处理。每个工作进程都会监听同一个端口,但是操作系统会确保每个请求只会被一个工作进程处理。当一个请求到达时,它会根据操作系统的调度分配给一个工作进程。这样,每个工作进程可以独立地处理请求,从而提高了应用程序的并发处理能力。
使用集群模块提高并发处理能力的步骤
-
引入
cluster模块: 首先,你需要在代码中引入cluster模块。
const cluster = require('cluster');2.检查是否为主进程: 接下来,你需要检查当前进程是否为主进程。如果是,那么你可以创建工作进程;如果不是,那么代码将作为工作进程运行。
if (cluster.isMaster) {
// 主进程代码
} else {
// 工作进程代码
} 3. 创建工作进程: 在主进程中,你可以使用 cluster.fork() 方法来创建工作进程。每个新创建的工作进程都会自动监听服务器端口。
for (let i = 0; i < require('os').cpus().length; i++) {
cluster.fork();
} 4.处理工作进程消息: 你可以使用 cluster.on('online', ...) 事件来知道何时工作进程已经准备好处理请求。你还可以监听其他事件,比如 exit 事件,以便在工作进程退出时进行清理工作。
cluster.on('online', (worker) => {
console.log(`Worker ${worker.process.pid} is online`);
});
cluster.on('exit', (worker, code, signal) => {
console.log(`Worker ${worker.process.pid} died`);
// 可以在这里创建新的工作进程来替代已退出的工作进程
}); 5.工作进程中的处理逻辑: 在工作进程中,你需要设置自己的 HTTP 服务器或其他服务来处理请求。这通常涉及到使用 http 模块或其他第三方模块
if (cluster.isWorker) {
const http = require('http');
const server = http.createServer((req, res) => {
// 处理请求
res.end('Hello from worker ' + cluster.worker.id);
});
server.listen(port, () => {
console.log(`Worker ${cluster.worker.id} started`);
});
}除了使用 Node.js 的集群(Cluster)模块,还有多种方法可以提高应用程序的并发处理能力,以下是整理的相关解决方案,就不再一一举例讲解了:
-
使用异步编程模型10:Node.js 利用事件循环和回调函数的机制,可以在等待 I/O 操作的同时处理其他请求,从而提高系统的并发处理能力。通过使用
async/await或 Promise 来处理异步操作,可以确保代码的简洁性和效率。 -
采用事件驱动的框架10:使用事件驱动的框架(如 Express 或 Koa)可以更好地管理和处理高并发的请求。这些框架提供了丰富的中间件和路由处理功能,使得开发者能够构建可扩展的应用程序。
-
使用缓存技术10:利用缓存技术(如 Redis)存储经常访问的数据,减少对数据库的访问次数,提高系统的响应速度和并发处理能力。缓存可以显著减少数据库的负载,从而提高整体的并发处理速度。
-
流式处理10:Node.js 的流式处理能力可以有效地处理大规模数据的并发处理。通过使用流(Streams),可以逐步处理数据,减少内存占用,提高系统的并发处理能力。
-
使用连接池10:在与数据库或其他外部服务进行交互时,使用连接池可以管理和复用连接,避免频繁地创建和销毁连接,提高系统的并发处理能力。
-
采用分布式架构10:将系统拆分为多个独立的服务,每个服务可以独立运行并处理自己的请求。使用分布式架构可以提高系统的可伸缩性和容错性。
-
使用限流和熔断机制10:通过限制请求的速率或在系统压力过大时停止接收请求,可以保护系统不被过多的请求压垮。这有助于维持系统的稳定性和可靠性。
-
利用多线程(Worker Threads)15:Node.js 提供了
worker_threads模块,允许创建子线程来执行 CPU 密集型任务,从而提高并发性能。这可以充分利用多核处理器的性能。 -
使用进程管理工具611:工具如 PM2 提供了进程管理、负载均衡和自动重启等功能,可以帮助提高 Node.js 应用程序的稳定性和并发处理能力。
通过上述方法的组合使用,开发者可以根据具体的业务需求和系统架构来选择合适的解决方案,以提高 Node.js 应用程序的并发处理能力。
总结
Node.js 的并发控制主要依赖于事件循环和非阻塞 I/O,通过使用 Promises、async/await 以及子线程等技术,可以有效地处理高并发场景。开发者应根据实际需求选择合适的并发解决方案,以提高应用程序的性能和响应速度。随着 Node.js 的不断发展,未来可能会出现更多高效的并发处理方案。
扩展:使用 cluster 模块可以显著提高 Node.js 应用程序的并发处理能力,特别是在多核 CPU 服务器上。通过创建多个工作进程,你可以让每个核心都参与到请求处理中,从而提高整体的处理速度和效率。然而,需要注意的是,cluster 模块并不适用于所有场景,特别是对于 I/O 密集型应用,它的效益可能不如使用异步 I/O 和事件循环模型。在使用 cluster 模块时,还需要考虑到进程间通信和状态共享的问题,因为每个工作进程都是独立的。
整理分享不易,如果对客官有帮助还请点点赞!下一篇介绍node中的rsa加密