在本文中,我们将学习如何使用Scikit-Learn实现分层抽样。
什么是分层抽样?
分层抽样是一种抽样方法,首先将总体的单位按某种特征分为若干次级总体(层),然后再从每一层内进行单纯随机抽样,组成一个样本。可以提高总体指标估计值的精确度。在抽样时,将总体分成互不交叉的层,然后按一定的比例,从各层次独立地抽取一定数量的个体,将各层次取出的个体合在一起作为样本,这种抽样方法是一种分层抽样。
分层抽样的特点是将科学分组法与抽样法结合在一起,分组减小了各抽样层变异性的影响,抽样保证了所抽取的样本具有足够的代表性。
如何进行分层抽样?
要执行分层抽样,您需要遵循以下讨论的步骤:
- 定义层:根据种族、性别、收入、教育水平、年龄组等相关特征,确定和定义人口中的子群体状态。
- 样本量:确定总体样本量和单个亚组样本量,确保所选每个亚组的比例在总体中具有比例代表性。
- 选择抽样:通过应用随机抽样技术,如简单随机抽样或系统随机抽样,从每个确定的分层中随机选择样本。
- 最终抽样:将来自不同层的所有样品组合成统一的代表性样品。
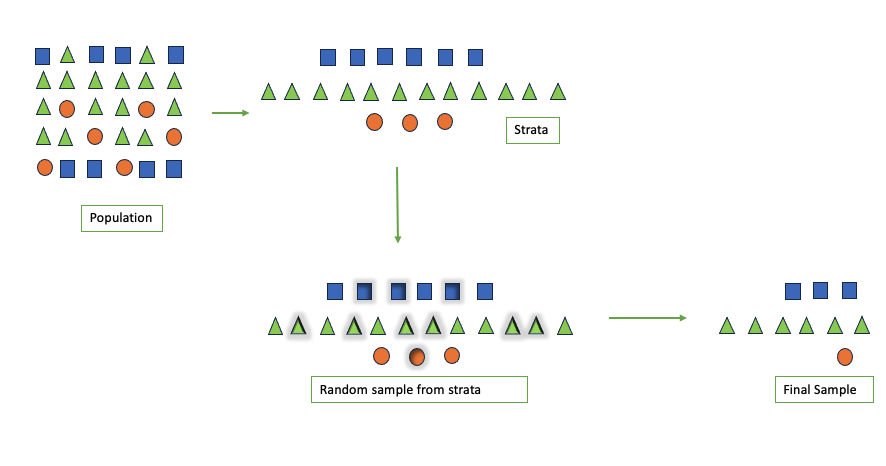
什么时候使用分层抽样?
- 群体异质性:当群体可以根据特定特征分为相互排斥的亚组时。
- 平等代表性:当我们想要确保一个特定的特征或一组特征在最终样本中得到充分代表时。
- 资源限制:当您想将研究结果推广到整个人群并确保估计值对每个阶层都有效,但资源有限时。
例如,在市场调研中,如果需要调查不同年龄、性别、职业等人群的消费习惯,可以将总体按照这些特征进行分层,然后在每个层内随机抽样,从而得到更具代表性的样本。
需要注意的是,分层抽样并不是一种简单地将总体分成几份然后随机抽样的方法,而是需要考虑到各层之间的差异和相似性,以及抽样比例等因素。因此,在使用分层抽样时,需要根据具体情况进行设计和操作。
分层抽样的优点
分层抽样的优点包括:
-
提高样本的代表性:分层抽样能够根据总体中不同层次的比例来抽取样本,从而使得样本更加具有代表性,提高由样本推断总体的精确性。
-
便于组织:分层抽样可以根据不同的层次进行抽样,因此可以灵活地选择不同的抽样方法和组织方式,便于组织和管理。
-
节省经费:由于分层抽样可以针对不同层次进行抽样,因此可以更加有效地利用资源,节省经费。
需要注意的是,分层抽样需要考虑到各层之间的差异和相似性,以及抽样比例等因素,因此需要更加精细的设计和操作。
与其他采样技术进行比较
分层抽样只是研究中使用的几种抽样技术之一。让我们将分层抽样与其他几种常见的抽样技术进行比较:
分层抽样:
- 确保所有分组的代表性。当群体中存在显著变异时有用。
- 需要了解有效分层的人群特征。
简单随机抽样:
- 简单随机抽样很容易实现,特别是当总体是同质的时候。
- 可能无法捕获群体内的变异性,某些亚组可能代表性不足。
整群抽样:
- 在整群抽样中,人口被自然地分组为群组,这可能不一定基于感兴趣的特征。
- 整个集群成为采样单位。
- 聚类是随机选择的,并且所选聚类中的所有个体都包括在样本中。
- 适用于地理上分散的人群,降低成本和时间。
配额抽样:
- 随机抽样涉及根据某些特征将人口划分为亚组或配额。
- 主要区别在于,在分层抽样中,我们从每个子组中抽取随机样本(概率抽样)。在配额抽样中,我们根据我们的知识为特定特征设定预定配额。此外,所选择的样本是非随机的,这意味着研究人员可以使用方便或判断抽样来满足预定的配额。
系统抽样:
- 系统抽样(Systematic sampling)是一种抽样方法,在第一个成员被随机选择后,每第n个成员被选择纳入样本。这是通过选择一个随机的起点,然后从总体中挑选每第k个元素来完成的。“k”的值通过将总体的总大小除以期望的样本大小来确定。
分层抽样的实现
让我们加载 iris 数据集来实现分层采样。
import pandas as pd
from sklearn import datasets
iris = datasets.load_iris()
iris_df=pd.DataFrame(iris.data)
iris_df['class']=iris.target
iris_df.columns=['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid', 'class']
iris_df['class'].value_counts()
让我们看看当分层stratify设置为None时的类分布。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test= train_test_split(X,y, train_size=0.8,
random_state=None,
shuffle=True, stratify=None)
print("Class distribution of train set")
print(y_train.value_counts())
print()
print("Class distribution of test set")
print(y_test.value_counts())
输出
Class distribution of train set
0 43
2 40
1 37
Name: class, dtype: int64
Class distribution of test set
1 13
2 10
0 7
Name: class, dtype: int64
让我们看看当分层stratify设置为True时的类分布。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test= train_test_split(X,y, train_size=0.8,
random_state=None,
shuffle=True, stratify=y)
print(y_train.value_counts())
print(y_test.value_counts())
输出
Class distribution of train set
0 40
2 40
1 40
Name: class, dtype: int64
Class distribution of test set
2 10
1 10
0 10
Name: class, dtype: int64
如果我们想使用k倍的分层采样,我们可以使用Scikit Learn中的StratifiedShuffleSplit类,如下所示。
- StratifiedShuffleSplit是scikit-learn中的一个类,它提供了一种生成用于交叉验证的训练/测试数据的方法。它是专门为以下场景而设计的:您希望在将数据拆分为训练集和测试集时,确保数据集中的类分布得到维护。
- n_splits:重新拆分迭代的次数。在示例中,n_splits=2意味着数据集将被分成2个不同的训练集/测试集。
- test_size:要包含在测试拆分中的数据集的比例。它可以是浮点数(例如,0.2表示20%)或整数(例如,2表示2个样本)。
- random_state:随机数生成器的种子,以确保可重复性。如果设置为整数,则每次将生成相同的随机拆分。
import numpy as np
from sklearn.model_selection import StratifiedShuffleSplit
skf = StratifiedShuffleSplit(n_splits=2, train_size = .8)
X = iris_df.iloc[:,:-1]
y = iris_df.iloc[:,-1]
for i, (train_index, test_index) in enumerate(skf.split(X, y)):
print(f"Fold {i}:")
print(f" {iris_df.iloc[train_index]['class'].value_counts()}")
print("-"*10)
print(f" {iris_df.iloc[test_index]['class'].value_counts()}")
print("*" * 60)
输出
Fold 0:
2 40
1 40
0 40
Name: class, dtype: int64
----------
2 10
1 10
0 10
Name: class, dtype: int64
************************************************************
Fold 1:
2 40
1 40
0 40
Name: class, dtype: int64
----------
2 10
0 10
1 10
Name: class, dtype: int64
************************************************************
总结
在本文中,我们看到了如何使用分层抽样来确保最终样本代表总体,确保感兴趣的特征既不代表不足,也不代表过度。





![[尚硅谷flink] 检查点笔记](https://img-blog.csdnimg.cn/img_convert/88b730e4882d6a9c23fe17eeaa312791.png)