文章目录
- 目的
- 导入包的相关公开原则
- 当前进程的挂载信息
- defer
- `for scanner.Scan()`
- 判断字符串包含
- 新建的cgroup的默认文件
- cpu相关配置
- 对应到ubuntu 22.04版本的cpu相关配置
- top
- 注意
- 查看你可使用的cpu
- 注意
- 坑
- 启动后的top查看
- 显示进程使用的cpu序号
- 代码
- 结果
目的
启动容器时通过-mem、-cpu 等 flag 相关命令行参数来实现容器 cpu、内存资源限制
导入包的相关公开原则
在Go语言中,导入包中的结构体(struct)和接口(interface)内的字段、方法也同样遵循导出规则:
- 结构体(struct):
- 结构体内的字段如果是公开(导出)的,也需要以大写字母开头。公开的字段可以在包外部访问和修改。
- 结构体内的方法(不论接收者是谁)如果是公开的,方法名也需要以大写字母开头,这样才能在包外部调用。
// 在 mypackage 包中
package mypackage
type ExportedStruct struct {
PublicField string // 可以在其他包中访问
privateField string // 不能在其他包中访问
}
func (s ExportedStruct) PublicMethod() {} // 可以在其他包中调用
func (s ExportedStruct) privateMethod() {} // 不能在其他包中调用
- 接口(interface):
- 接口内的方法全部都是公开的,因为接口本身就是一种契约,定义了一组方法签名,无论接口本身还是其内的方法,都需要以大写字母开头才能在包外部看到和使用。
// 在 mypackage 包中
package mypackage
type ExportedInterface interface {
PublicMethod() // 可以在其他包中实现和调用
}
总结:无论是结构体还是接口,其内部的公开字段和方法都需要以大写字母开头,以便在其他包中正常使用。对于接口而言,因为接口本身就是方法的集合,所以接口内的所有方法都会自动视为公开的。
当前进程的挂载信息
/proc/self/mountinfo 是Linux系统中的一个虚拟文件,位于 /proc 文件系统中,该文件提供了系统当前挂载点的详细信息,尤其是关于当前进程(self)的挂载点信息。
每一行内容都代表一个挂载点的详细描述,包括:
- 挂载ID(unique ID identifying the mount point across all mounts within the system)。
- 父挂载ID(the ID of the parent mount (or of self for the rootfs))。
- 主设备号和次设备号(major and minor numbers of the device mounted)。
- 挂载点路径(the mount point’s pathname)。
- 根目录的设备ID(root directory ID)。
- 挂载选项(options used when mounting the filesystem)。
- 文件系统类型(filesystem type)。
- 挂载源(where the filesystem was mounted from, e.g., device path or NFS server/share)。
- 特殊挂载标志(additional flags specific to the mount)。
通过读取 /proc/self/mountinfo 文件,可以详细了解当前进程所能看到的文件系统挂载情况,这对于系统管理和故障排查非常有用。例如,如果要检查某个目录挂载的文件系统类型、挂载来源、挂载选项等信息,可以查阅这个文件的内容。
defer
在Go语言中,defer f.Close() 是用来保证文件或资源一定会在函数执行完毕前被关闭的语句。这里的 f 是一个实现了 io.Closer 接口的对象,通常是一个文件句柄或其他需要关闭的资源对象。Close 方法用于关闭资源,释放系统资源。
defer 关键字在 Go 语言中用于延迟执行函数,即该函数会在包含它的函数执行结束(无论是正常返回还是通过 panic 导致的异常退出)前调用。defer 语句的执行顺序是 LIFO(后进先出),也就是说,最后被 defer 的函数会在其他 defer 函数之前被执行。
例如:
func processFile(filename string) error {
file, err := os.Open(filename)
if err != nil {
return err
}
defer file.Close() // 当函数返回时,file.Close()会被调用,确保文件最终会被关闭
// 对文件进行读写操作...
return nil // 或者返回其他错误
}
在上面的代码中,无论 processFile 函数的执行是否成功,也不论函数是如何结束的(正常返回或抛出错误),file.Close() 都会在函数返回前被调用,确保了文件资源的正确释放。
for scanner.Scan()
在Go语言中,bufio.NewScanner(f) 创建了一个新的扫描器(Scanner),它可以从给定的输入流(在这里是 f)逐行读取数据。f 应该是一个实现了 io.Reader 接口的对象,如文件、网络连接或类似的数据流。
接着的 for scanner.Scan() 是一个循环,它会一直执行直到扫描器不再有可读的行为止:
scanner.Scan()是一个方法调用,它尝试从输入流中读取下一行数据。如果成功读取到一行数据,则返回true,并将读取到的数据存储在scanner.Text()或scanner.Bytes()等方法可以访问的地方。- 如果
scanner.Scan()读取到流的末尾,或者在读取过程中遇到了错误,它将返回false并且可以通过scanner.Err()检查发生的错误。
循环体内部就是对每一行数据进行处理的地方,例如:
f, err := os.Open("example.txt")
if err != nil {
// 处理错误
}
defer f.Close()
scanner := bufio.NewScanner(f)
for scanner.Scan() {
line := scanner.Text() // 获取当前行的内容
// 对line进行处理,如打印、解析或存入数据库等操作
fmt.Println(line)
}
if err := scanner.Err(); err != nil {
// 在循环结束后检查是否有读取错误
fmt.Fprintln(os.Stderr, "Reading standard input:", err)
}
这样,for scanner.Scan() 循环就完成了一个从输入流中逐行读取数据并进行处理的过程。
判断字符串包含
在Go语言中,判断一个字符串(子串)是否存在于另一个字符串中,可以使用 strings.Contains 函数。以下是一个示例:
package main
import (
"fmt"
"strings"
)
func main() {
// 主字符串
mainStr := "Hello, world! This is a test string."
// 要查找的子字符串
subStr := "test"
// 判断子字符串是否存在于主字符串中
isFound := strings.Contains(mainStr, subStr)
if isFound {
fmt.Printf("Substring '%s' found in the main string.\n", subStr)
} else {
fmt.Printf("Substring '%s' not found in the main string.\n", subStr)
}
}
在上述代码中,strings.Contains(mainStr, subStr) 会返回一个布尔值,如果 subStr 存在于 mainStr 中,则返回 true,否则返回 false。
新建的cgroup的默认文件

- cgroup.controllers:显示当前cgroup所使用的控制器。
- cgroup.events:显示与cgroup相关的事件。
- cgroup.freeze:用于冻结或解冻cgroup。
- cgroup.kill:用于杀死cgroup中的所有进程。
- cgroup.max.depth:显示cgroup的最大深度。
- cgroup.max.descendants:显示cgroup的最大后代数。
- cgroup.pressure:显示cgroup的压力状况。
- cgroup.procs:显示属于cgroup的进程列表。
- cgroup.stat:显示有关cgroup的统计信息。
- cgroup.subtree_control:用于控制cgroup的子树。
- cgroup.threads:显示属于cgroup的线程数。
- cgroup.type:显示cgroup的类型。
接下来是与CPU和内存资源控制相关的文件:
- cpuset.cpus:显示cpuset分配的CPU的列表。
- cpuset.cpus.effective:显示实际生效的cpuset分配的CPU的列表。
- cpuset.cpus.partition:显示cpuset的CPU分区。
- cpuset.mems:显示cpuset分配的内存节点的列表。
- cpuset.mems.effective:显示实际生效的cpuset分配的内存节点的列表。
- cpu.idle:显示CPU处于空闲状态的时间。
- cpu.max:显示CPU可用的最大频率。
- cpu.stat:显示CPU的统计信息。
- cpu.pressure:显示CPU的压力状况。
- cpu.max.burst:显示CPU的最大突发频率。
- cpu.uclamp.max:显示CPU的最大utilization clamp值。
- cpu.uclamp.min:显示CPU的最小utilization clamp值。
- cpu.weight:显示CPU权重。
- cpu.weight.nice:显示CPU权重的“nice”值。
- io.max:显示I/O最大限制。
- io.pressure:显示I/O的压力状况。
- io.prio.class:显示I/O的优先级类别。
- io.stat:显示I/O的统计信息。
接着是与内存资源控制相关的文件:
- memory.events:显示内存事件的统计信息。
- memory.peak:显示内存使用量的峰值。
- memory.swap.peak:显示交换空间使用量的峰值。
- memory.events.local:显示本地内存事件的统计信息。
- memory.pressure:显示内存的压力状况。
- memory.reclaim:显示内存的回收情况。
- memory.zswap.current:显示zswap的当前状态。
- memory.high:显示内存的高阈值。
- memory.low:显示内存的低阈值。
- memory.max:显示内存的最大限制。
- memory.min:显示内存的最小限制。
- memory.numa_stat:显示NUMA节点的内存统计信息。
- memory.oom.group:显示内存OOM的组信息。
- memory.swap.current:显示交换空间的当前状态。
- memory.swap.events:显示交换空间事件的统计信息。
- memory.swap.high:显示交换空间的高阈值。
- memory.swap.max:显示交换空间的最大限制。
- memory.swap.events:显示交换空间事件的统计信息。
最后是与进程控制相关的文件:
- pids.current:显示当前进程数。
- pids.events:显示与进程相关的事件。
- pids.max:显示最大进程数限制。
- pids.peak:显示进程数的峰值。
cpu相关配置
让我们通过一些例子来解释 cpu.cfs_period_us、cpu.cfs_quota_us 和 cpu.shares 之间的关系以及它们如何共同控制 CPU 资源分配:
假设我们有一个系统,其中 CPU 时间可以分配给不同的控制组(cgroup):
-
cpu.shares 示例:
- 假设我们有两个 cgroup,即“A”和“B”,并且我们希望“A”获得两倍于“B”的 CPU 时间。
- 我们将“A”的 cpu.shares 设置为 1024,将“B”的 cpu.shares 设置为 512。
- 在这种情况下,cgroup“A”将获得两倍于 cgroup“B”的 CPU 时间。如果“A”和“B”都在积极使用 CPU,则“A”将获得 2/3 的 CPU 时间,“B”将获得 1/3。
-
cpu.cfs_period_us 和 cpu.cfs_quota_us 示例:
- 现在,让我们使用 cpu.cfs_period_us 和 cpu.cfs_quota_us 来实现更细粒度的控制。
- 假设我们有一个 cgroup“C”,我们希望限制它在 1 秒内只能使用 500 毫秒的 CPU 时间。
- 我们将“C”的 cpu.cfs_period_us 设置为 1,000,000(表示 1 秒),并将 cpu.cfs_quota_us 设置为 500,000(表示 500 毫秒)。
- 在这种情况下,“C”中的进程在 1 秒的周期内将仅获得 500 毫秒的 CPU 时间。一旦它们达到配额,它们将在该周期的剩余时间内被暂停。
-
结合使用 cpu.shares、cpu.cfs_period_us 和 cpu.cfs_quota_us:
-
现在,让我们将这三个设置结合起来。
-
假设我们有两个 cgroup,“D”和“E”,我们希望“D”获得三倍于“E”的 CPU 时间,但我们还希望限制“D”在 2 秒内只能使用 1 秒的 CPU 时间。
-
我们将“D”的 cpu.shares 设置为 1536,将“E”的 cpu.shares 设置为 512。
-
对于“D”,我们将 cpu.cfs_period_us 设置为 2,000,000(2 秒),并将 cpu.cfs_quota_us 设置为 1,000,000(1 秒)。
-
对于“E”,我们将 cpu.cfs_period_us 设置为 2,000,000(2 秒),并将 cpu.cfs_quota_us 设置为 2,000,000(2 秒)。
-
在这种情况下,“D”将获得三倍于“E”的 CPU 时间,但受到 1 秒 CPU 时间配额的限制。一旦“D”达到了 1 秒的配额,它在当前周期的剩余时间内将被暂停。
-
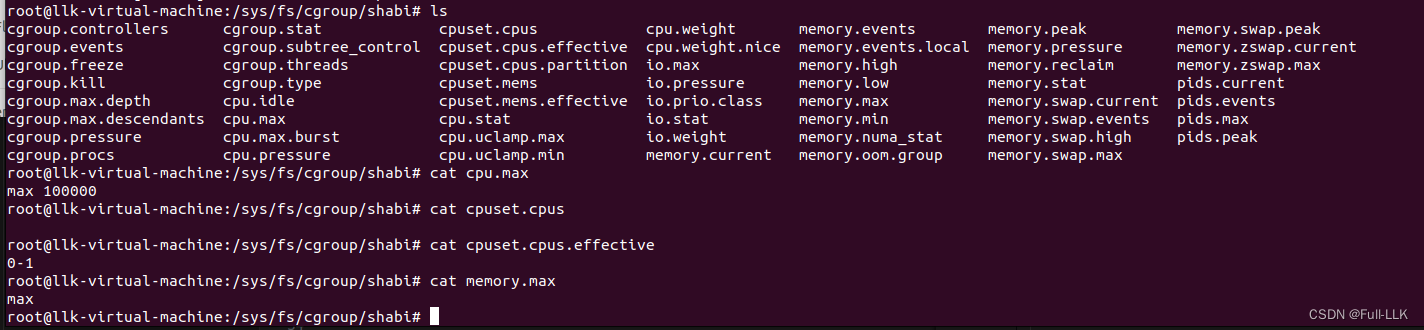
对应到ubuntu 22.04版本的cpu相关配置
-
cpuset.cpus:
这个文件显示了当前 cgroup 可以使用的 CPU 列表。如果这个文件是空的,表示当前 cgroup 可以使用所有 CPU 资源。 -
cpuset.cpus.effective:
这个文件显示了当前 cgroup 实际可以使用的 CPU 列表。这个列表可能会比cpuset.cpus更加精确,因为它考虑了父 cgroup 的 CPU 分配情况。
在 cgroup 系统中,每个 cgroup 都可以设置自己的 CPU 分配策略。当一个子 cgroup 被创建时,它会继承父 cgroup 的 CPU 分配策略。
cpuset.cpus 文件表示当前 cgroup 可以使用的 CPU 列表。但是,这个列表可能并不完全准确,因为它没有考虑父 cgroup 的 CPU 分配。
而 cpuset.cpus.effective 文件则考虑了父 cgroup 的 CPU 分配情况,因此它显示的 CPU 列表更加精确。它实际上是根据当前 cgroup 和它的父 cgroup 的 CPU 分配策略计算出来的。
例如,如果父 cgroup 只允许使用 CPU 0 和 CPU 1,那么即使子 cgroup 可以使用所有 CPU,但 cpuset.cpus.effective 也只会显示 CPU 0 和 CPU 1。
cpuset.cpus是空的,表示当前 cgroup 可以使用所有 CPU 资源。cpuset.cpus.effective显示0-1,表示当前 cgroup 实际可以使用 CPU 0 和 CPU 1。
这意味着,即使当前 cgroup 可以使用所有 CPU 资源,但由于父 cgroup 的限制,它实际只能使用 CPU 0 和 CPU 1。
通过查看这两个文件,可以了解当前 cgroup 的 CPU 使用情况,并根据需要进行调整。如果需要更改 CPU 分配,可以修改这些文件的内容。
- cpu.max
会根据前一个和后一个的比值来决定cpu的使用率,max代表最大,就是百分之百 - memory.max
max代表最大
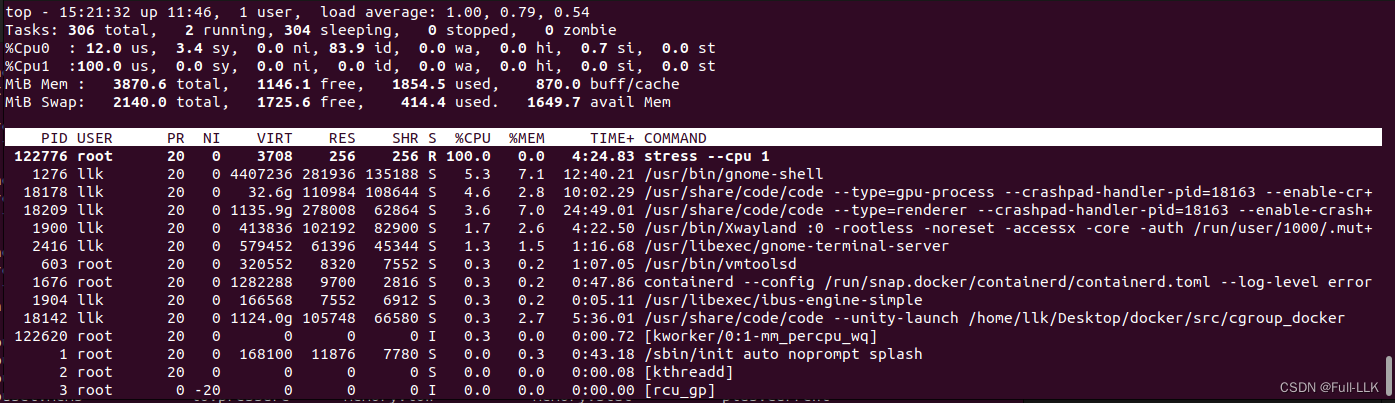
top
使用 top 命令可以查看进程使用的 CPU 情况。具体步骤如下:
- 运行
top命令:
top
-
按下
1键切换到 CPU 信息视图。这时你会看到每个 CPU 核心的使用情况。 -
要查看进程使用的 CPU 信息,可以按下
c键切换到显示命令行模式。这样可以看到每个进程使用的 CPU 核心。
注意
如果父 cgroup 的 cpuset.cpus.effective 设置小于子 cgroup 的 cpuset.cpus.effective 设置,那么子 cgroup 中的进程实际上只能使用父 cgroup 允许的 CPU 范围。
具体来说:
-
当父 cgroup 的
cpuset.cpus.effective被设置为某个范围(比如0-1)时,所有子 cgroup 都会继承这个 CPU 范围。 -
即使子 cgroup 将
cpuset.cpus设置为一个更大的范围(比如0-3),但实际可用的 CPU 范围仍然被限制在父 cgroup 的cpuset.cpus.effective中(即0-1)。 -
子 cgroup 进程只能使用父 cgroup 允许的 CPU 范围,即使子 cgroup 自己的设置允许使用更多 CPU。
-
如果父 cgroup 的
cpuset.cpus.effective被修改,子 cgroup 的可用 CPU 范围也会相应地更新。
并且最开始的/sys/fs/cgroup没有 cpuset.cpus,只有 cpuset.cpus.effective ,但把当前可用的都包括到cpuset.cpus.effective里面去了,后面新建的cgroup中就有cpuset.cpus和 cpuset.cpus.effective 了,而且在父cgroup cpuset.cpus.effective 的允许范围内和cpuset.cpu的双重限制后cpuset.cpus.effective会自动变化(当cpuset.cpus`变化后)
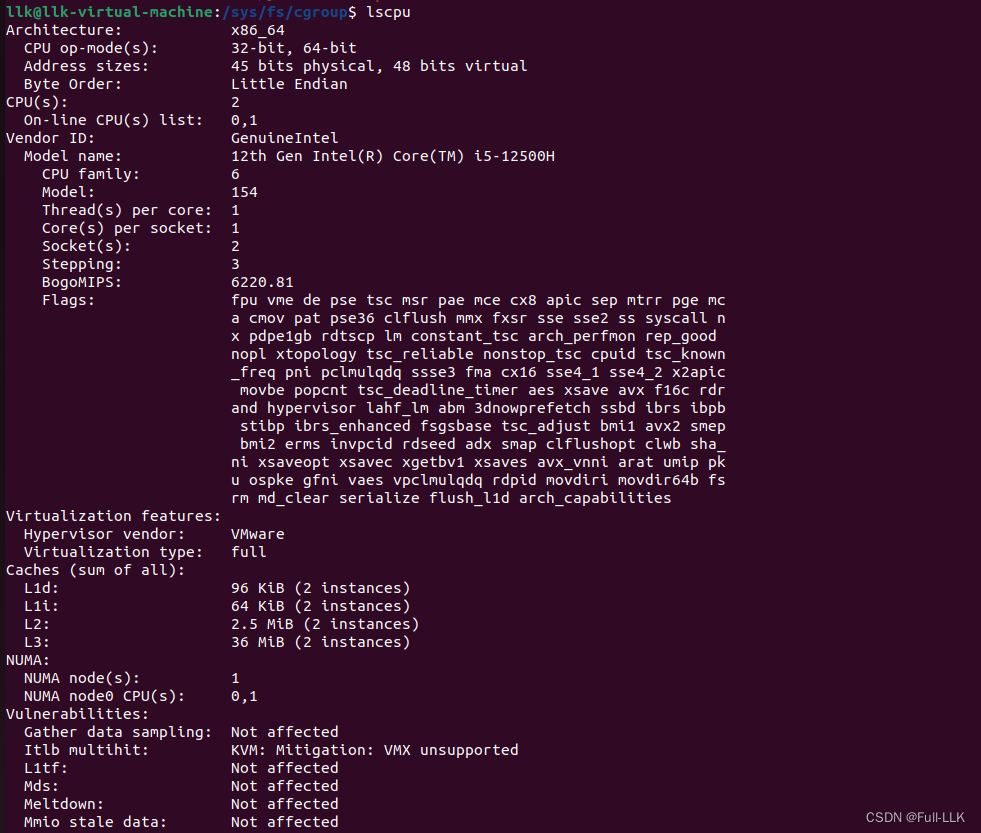
查看你可使用的cpu
要查看当前可使用的 CPU 序号,您可以使用以下方法:
- 使用
lscpu命令:
lscpu
这个命令会显示系统中 CPU 的详细信息,包括 CPU 数量和 CPU 序号。
- 使用
cat /proc/cpuinfo命令:
cat /proc/cpuinfo
这个命令会输出系统中所有 CPU 的详细信息,包括 CPU 序号。
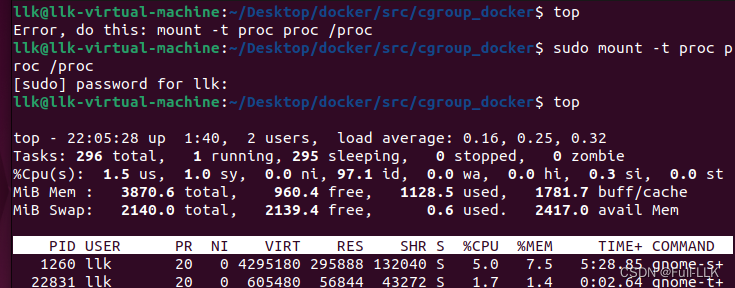
注意
发现运行一次后,第二次运行失败,原因是挂载的文件系统/proc没有卸载掉,卸载或者重新挂载到当前/proc即可
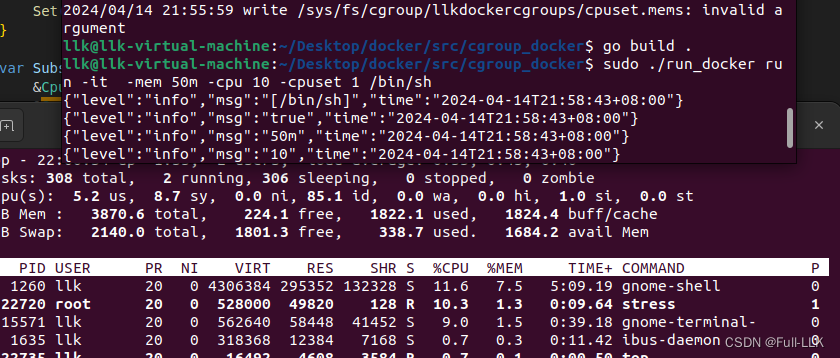
坑
context.Args():所有flag识别后剩余的就是Args()的
context.Bool():只要有-it就行,不会识别后面的一个参数
context.String():会识别后面的一个参数,将其作为标签对应的字符串
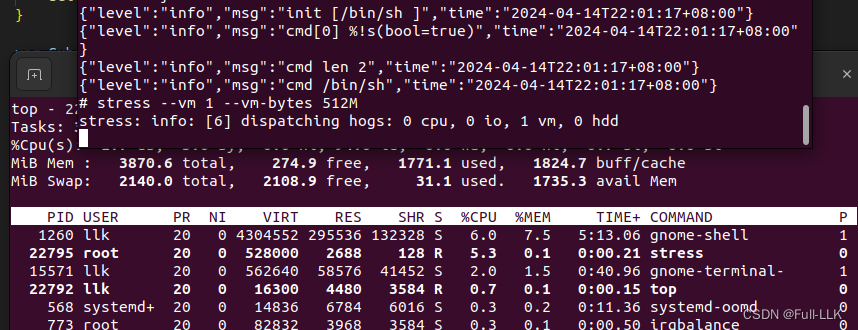
启动后的top查看
由于启动后将/proc文件系统挂载到运行的地方去了,本地使用top时发现不行,此时再挂载回来即可
显示进程使用的cpu序号
要查看当前进程使用哪个 CPU,可以在 top 命令中使用一些额外的选项。
步骤如下:
-
首先确保
/proc文件系统已经正确挂载,如果没有挂载可以使用以下命令进行挂载:sudo mount -t proc proc /proc -
运行
top命令,并按下1键查看每个 CPU 的使用情况。 -
要查看进程使用的具体 CPU 核心,可以按下
f键进入配置模式,然后选择%CPU和P两个字段。%CPU显示进程使用的 CPU 百分比P显示进程使用的 CPU 编号
-
按下
d键可以设置刷新频率,然后按下Enter键确认。 -
现在
top界面上就会显示每个进程使用的具体 CPU 编号了。
代码
https://github.com/FULLK/llkdocker/tree/main/cgroup_docker
结果