目录
1.串的定义
2.串的基本操作
3.串的存储结构
(1)串的定义
•顺序存储
•链式存储
(2)求串长
(3)求子串
(4)比较串的大小
(5)定位操作
4.字符串的模式匹配
(1)朴素模式匹配算法
(2)KMP算法
•求模式串中的next数组(重点)
•练习:
(3)KMP算法的进一步优化
•求nextval数组的方法(重点)
1.串的定义
串,即字符串(String)是由零个或多个字符组成的有限序列。一般记为 S=''。其中,S是串名,单引号括起来的字符序列是串的值(有的地方用双引号(如Java,C),有的地方用单引号(如Python));ai可以是字母、数字或其他字符;串中字符的个数n称为串的长度。n=0时的串称为空串(用
表示)。
几个专业术语:
子串:串中任意个连续的字符组成的子序列(空串也是字符串的子串)。
主串:包含子串的串。
字符在主串中的位置:字符在串中的序号(从1开始)。
子串在主串中的位置:子串的第一个字符在主串中的位置(从1开始)。
空串与空格串:
空串:单引号之间没有任何字符,如下面的M。
空格串:有多个空格字符组成的字符串,每个空格字符占1B,如下面 的N。
是一种特殊的线性表,数据元素之间呈线性关系。线性表中存放的数据对象可以是各种类型的,但是串的数据对象限定为字符集(如中文字符、英文字符、数字字符、标点字符等),串的基本操作,如增删改查等通常以子串(多个数据对象)为操作对象。
2.串的基本操作
StrAssign(&T,chars):赋值操作。把串T赋值为chars。
StrCopy(&T,S):复制操作。由串S复制得到串T。
StrEmpty(S):判空操作。若S为空串,则返回TRUE,否则返回FALSE
StrLength(S):求串长。返回串S的元素个数。
ClearString(&S):清空操作。将S清为空串。
DestroyString(&S):销毁串。将串S销毁(回收存储空间)。
Concat(&T,S1,S2):串联接。用T返回由S1和S2联接而成的新串
SubString(&Sub,S,pos,len):求子串。用Sub返回串S的第pos个字符起长度为len的子串。
Index(S,T):定位操作。若主串S中存在与串T值相同的子串,则返回它在主串S中第一次出现的位置;否则函数值为0。
StrCompare(S,T):比较操作。若S>T,则返回值>0;若S=T,则返回值=0;若S<T,则返回值<0。
比较规则:
计算机只能存储二进制数,需要确定一个编码的规则,使得各个字符与二进制数能够一一对应起来,比较字符就是在比较二进制数的大小,例如'a'的Ascll码是97,对应的二进制就是
0110 0001,'A'的Ascll码是65,对应的二进制为0100 0001。
Ascll码表可以看:ASCII 表 | 菜鸟教程 (runoob.com)
Ascll字符集只是英文字符的集合。但是,除了英文字符外,还有很多其他字符(例如:中文,法语等),Ascll字符集中无法包含所有的字符,因为Ascll字符集中,每个字符占用的空间为1B(8bit的二进制数),只能表示2的8次方,即256个状态。
所以出现了其他字符集,如Unicode字符集,包含了中英文字符的集合。这些字符通过一个编码方案映射为二进制数(一个字符集可以有多个编码方案,例如UTF-8和UTF-16就是两种不同的Unicode编码方案)。
注:采用不同的编码方式,每个字符所占空间不同,考研中只需默认每个字符占1B即可。
1.从第一个字符开始往后依次对比,先出现更大字符的串就更大 。
2.长串的前缀与短串相同时,长串更大。
3.只有两个串完全相同时,才相等。
3.串的存储结构
(1)串的定义
•顺序存储
//定长顺序存储
#define MAXLEN 255 //预定义最大串长为255
typedef struct{
char ch[MAXLEN]; //每个分量存储一个字符
int length; //串的实际长度
}SString;
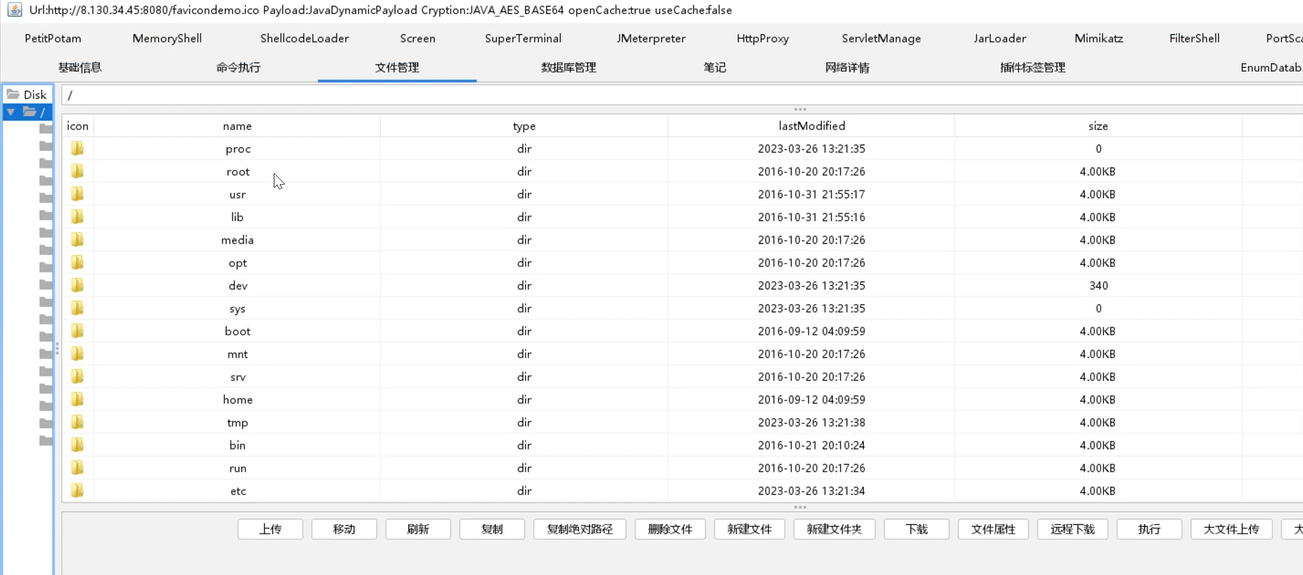
//堆分配存储(用malloc函数申请的内存空间属于内存的堆区)
typedef struct{
char *ch; //按串长分配存储区,ch指向串的基地址
int length; //串的长度
}HString;
HString S;
S.ch=(char *)malloc(MAXLEN * sizeof(char));
S.length=0;
//由malloc申请的内存空间需要手动free回收,而用静态数组申请的空间是由系统自动回收的。顺序存储的实现:

在方案一中,专门声明一个int型变量length表示字符串的长度。
在方案二中,若用ch[0]来存储字符串的长度,那么字符的位序和数组下标相同。但是一个字符只占8bit,其所能表示的数字范围为0~255。

在方案三中没有Length变量,以字符’\0'表示结尾(对应ASCIl码的 0),采用这种方式,若想知道字符串的长度,需要从头到尾扫描,扫描到‘\0’才能得到字符串的长度。若经常访问字符串的长度,那么这种方案就是不太可取的。

方案四中采用了方案1与方案2的结合,即舍弃ch[0]不用,并且专门声明一个int型的变量length表示字符串的长度。下面顺序存储的代码编写都是以方案四为存储结构的。
•链式存储
typedef struct StringNode{
char ch; //每个结点存1个字符
struct StringNode * next;
}StringNode,* String;

一个char的大小为1B,但是在32位计算机中,指针大小为4B,这就表示我们在存储一个字符时,只用了1B存储实际需要存储的信息,用了4B存储了辅助信息。这样存储密度就太低了。
如何解决?
typedef struct StringNode{
char ch[4]; //每个结点存多个字符
struct StringNode * next;
}StringNode,* String;
注:若最后一个结点的字符存不满,那么可以用一些特殊的字符填充进去,如'#'或'\0'。
(2)求串长
int StringLength(SString S){
return S.length;
}(3)求子串
SubString(&Sub,S,pos,len):求子串。用Sub返回串S的第pos个字符起长度为len的子串。

bool SubString(String &Sub,SString S,int pos,int len){
if(pos+len-1>S.length)
return false; //子串范围越界
for(int i=pos;i<pos+len;i++)
Sub.ch[i-pos+1]=S.ch[i];
Sub.length=len;
return true;
}(4)比较串的大小
StrCompare(S,T):比较操作。若S>T,则返回值>0;若S=T,则返回值=0;若S<T,则返回值<0。

int StrCompare(SString S,SString T){
for(int i=1;i<=S.length && i<T.length;i++){
if(S.ch[i]!=T.ch[i])
return S.ch[i]-T.ch[i];
}
//扫描过的所有字符都相同,则长度长的串更大
return S.length-T.length;
}
(5)定位操作
Index(S,T):定位操作。若主串S中存在与串T值相同的子串,则返回它在主串s中第一次出现的
位置;否则函数值为0。

int StringLength(SString S){
return S.length;
}
bool SubString(String &Sub,SString S,int pos,int len){
if(pos+len-1>S.length)
return false; //子串范围越界
for(int i=pos;i<pos+len;i++)
Sub.ch[i-pos+1]=S.ch[i];
Sub.length=len;
return true;
}
int StrCompare(SString S,SString T){
for(int i=1;i<=S.length && i<T.length;i++){
if(S.ch[i]!=T.ch[i])
return S.ch[i]-T.ch[i];
}
//扫描过的所有字符都相同,则长度长的串更大
return S.length-T.length;
}
int Index(SString S,SString T){
int i=1,n=StrLength(S),m=StrLength(T);
SString sub; //用于暂存子串
while(i<=n-m+1){
SubString(sub,S,i,m);
if(StrCompare(sub,T)!=0) ++i;
else return i; //返回子串在主串中的位置
}
return 0; //S中不存在与T相等的子串
}4.字符串的模式匹配
字符串模式匹配就是在主串(被查找串)中找到与模式串(想要查找的字符串)相同的子串,并返回其所在位置。
子串:主串的一部分,一定存在
模式串:不一定在主串中找到
(1)朴素模式匹配算法
若主串长度为n,模式串长度为 m,将主串中所有长度为m的子串依次与模式串对比,直到找到一个完全匹配的子串或所有的子串都不匹配为止。
长度为n的主串中,最多有n-m+1个子串
上面说的定位操作,即Index(S,T),就是一种朴素模式匹配算法:
int Index(SString S,SString T){
int i=1,n=StrLength(S),m=StrLength(T);
SString sub; //用于暂存子串
while(i<=n-m+1){
SubString(sub,S,i,m);
if(StrCompare(sub,T)!=0) ++i;
else return i; //返回子串在主串中的位置
}
return 0; //S中不存在与T相等的子串
}也可以直接通过数组下标实现朴素模式匹配算法:
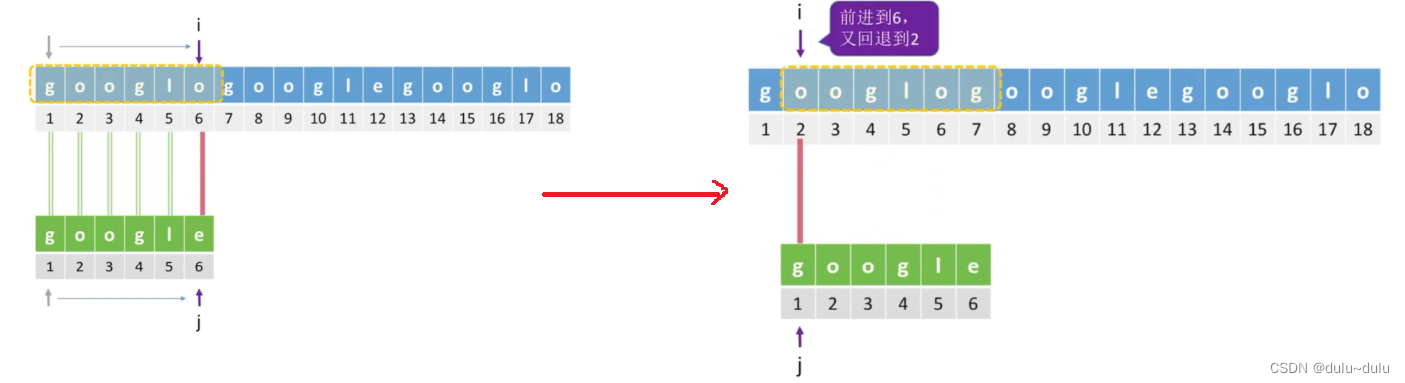
设置两个扫描指针i,j,将两个指针指向的字符依次对比,若指针指向的字符相同,就将指针一起后移。

若匹配失败,如上图所示,则主串指针 i 指向下一个子串的第一个位置,模式串指针 j 回到模式串的第一个位置。

只需要改变i,j指针的指向,就可以完成以上操作。
i=i-j+2; //i-(j-1)相当于i回到开始的位置,再加1就是下一个字符串
j=1; //j-(j-1)就相当于回到了1在下一个串中匹配失败,i-j+2 指向下一个串,j继续重新指回1

若j>T.length(j指向的位置超出了模式串的长度),则当前子串匹配成功,返回当前子串第一个字符的位置 ---- i-T.length

int Index(SString S,SString T){
int i=1,j=1;
while(i<=S.length && j<=T.length){
if(S.ch[i]==T.ch[i]){
++i;++j; //继续比较后继字符
}
else{
i=i-j+2;
j=1; //指针回退重新开始匹配
}
}
if(j>T.length)
return i-T.length;
else
return 0;
}设主串长度为n,模式串长度为m,那么最坏时间复杂度=O(nm)
若主串和模式串如下图所示, 最坏的情况,每个子串都要对比 m 个字符,共 n-m+1 个子串,复杂度=O((n-m+1)m) = O(nm-m^2+m) = O(nm),通常情况下n>>m

(2)KMP算法
在朴素模式匹配算法中,若主串与模式串不匹配,那么i就要回退到2,j回退到1。换个角度也可以理解为,将模式串往右移动了一步。
匹配失败,模式串继续右移。朴素模式匹配算法的缺点就是,当某些子串与模式串能部分匹配时,主串的扫描指针 i 经常回溯,导致时间开销增加。

所以KMP算法针对这一点进行了改进,即主串指针不回溯,只有模式串指针回溯。
若扫描到不匹配的字符,那么就将这个字符与模式串的第一个字符进行比较,即 i 指向的位置不变,j指回1。也可以理解为模式串往后移动了5步,相比于朴素匹配算法中模式串一步一步右移,这个算法的效率提高了很多。
1.若这个字符也为g,那么就让i++,j++,也就是继续匹配后一个字符。
2.若这个字符不为j,那么就 i++,j依然保持1
3.若扫描到 j =5,才发现匹配失败,也就是 i指向的字符不是“l”。
也就是以“g”开头的字符串与模式串是不匹配的,同理,因为之前扫描过的“o”“o”,都匹配上了(不匹配的字符之前,主串的字符一定是和模式串一致的),那么以“o”开头的字符串肯定也匹配不上。
但是以g开头的子串是可能与模式串进行匹配的,但是在代码中只是判断了i指向的字符与“l”是不匹配的,所以我们可以间接判断,i指向的字符是不是“o”,因为“g”后面是“o”。
所以若j=5 时发生不匹配,则应让 j 回到 2。
4.若 j=4 时发生不匹配,则应让 j 回到1。但是其实这里 i 指向字符一定不是 “g” 了
那么让j回到1,继续重新匹配,就会在开头进行一次没有必要的对比
但是相比于朴素匹配算法而言,他已经少对比了2次了。改进方法在KMP算法的改进中会讲。
5.若 j=3 时发生不匹配,则应让j回到1
相比于朴素算法而言,少进行了一次对比
6.若j=2时发生不匹配,则应让 j 回到1
总结:
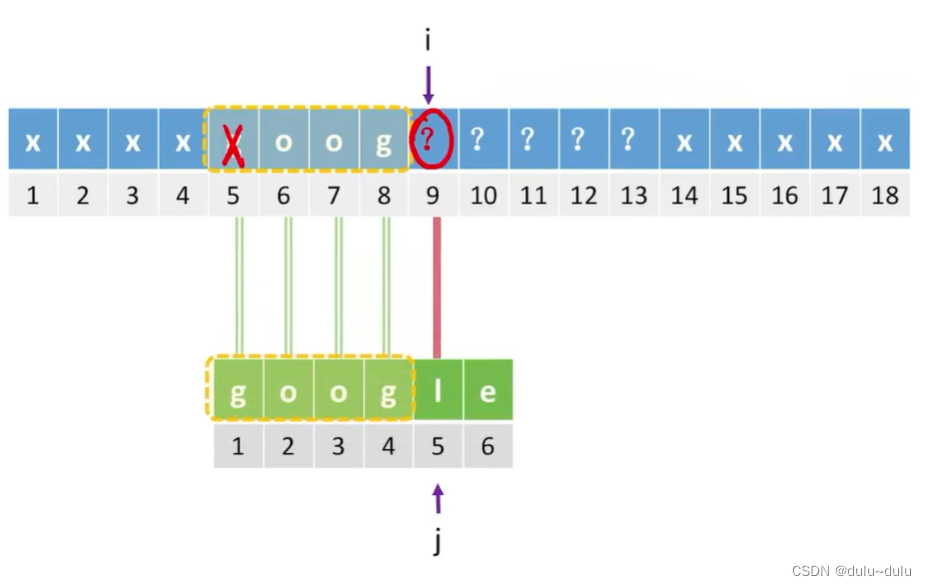
当j=k且发现字符不匹配时,令j=next[k]。例如,当j=5发现不匹配时,那么就让j=next[5],即2。
注:当j=1,即第1个字符匹配失败时,先令j=0,再进行i++,j++,就可以使i往后扫描字符,而j保持1。看代码应该能更好理解。
所以KMP算法的关键根据模式串的内容设计出合适的数组next。next数组只和模式串有关,和主串没有关系,也就是说只要模式串不变,不管主串是什么,next数组都是一样的。









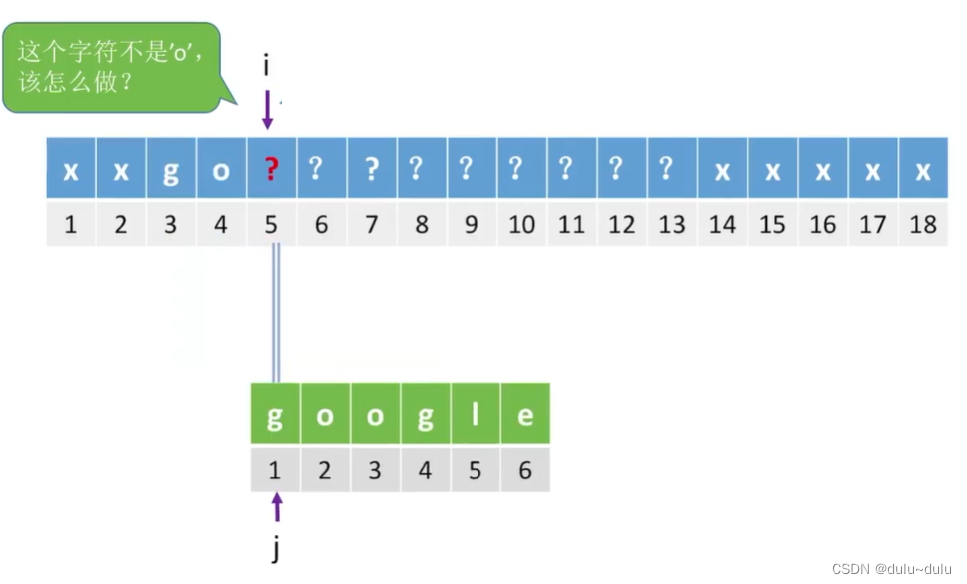



代码如下:

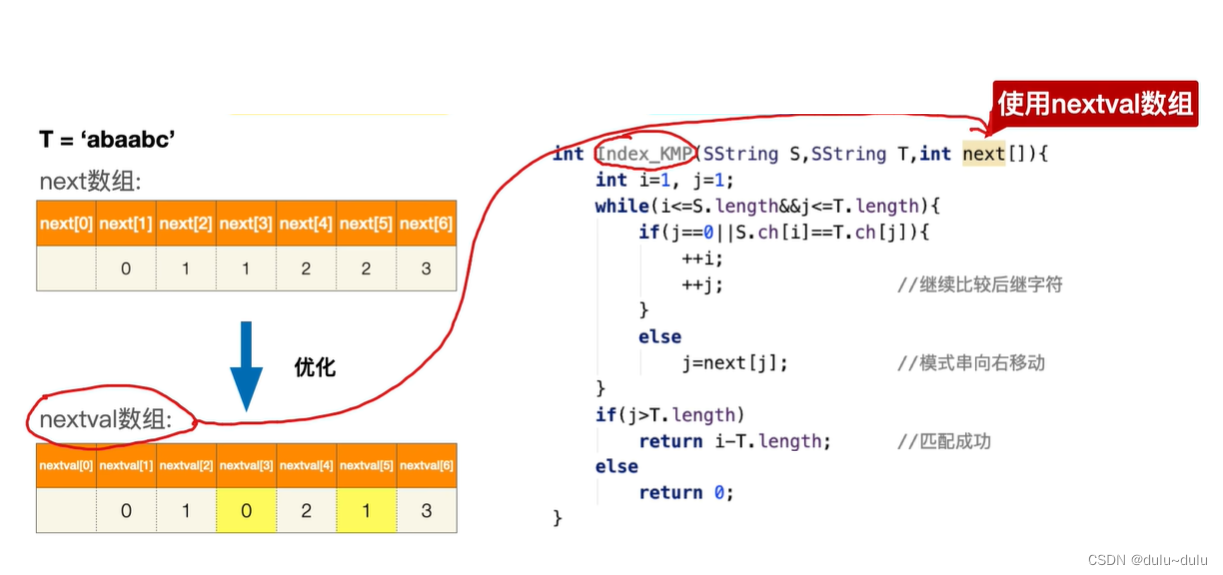
int Index_KMP(SString S,SString T,int next[]){
int i=1,j=1;
while(i<=S.length && j<=T.length){
if(j==0 || S.ch[i]==T.ch[j])
//刚开始j=1,若j=1时,两个字符不匹配,那么跳转到else
//else中,j=next[j],j=next[1]=0,若j=0,那么++i,让i指针向后扫描,并且让j指针保持1
{
++i;
++j; //继续比较后继字符
}
else
j=next[j]; //模式串向右移动
}
if(j>T.length)
return i-T.length; //匹配成功
else
return 0;
}相比于朴素模式匹配,KMP算法修改了两个部分,当主串和模式串不匹配时,不需要主串指针i回溯,只需要修改模式串中指针 j 即可。

•求模式串中的next数组(重点)
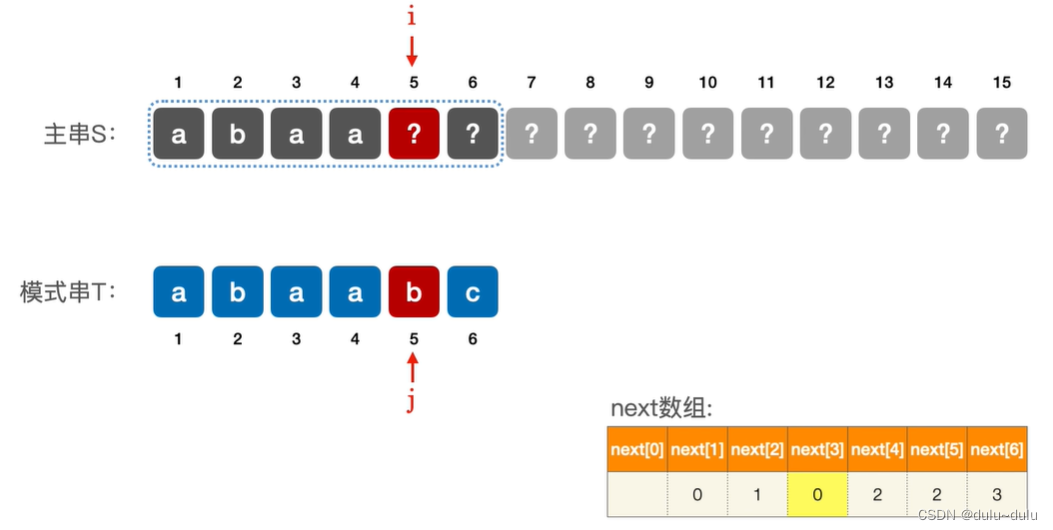
当模式串的第 j 个字符匹配失败时,令模式串跳到 next[j] 再继续匹配。
如下图所示,若j=6时不匹配,应该让next[6]=3,即让 j 指向3,或者说模式串向右移动3位。对比主串中i指向的字符和c是否能匹配。

同理,当j=7时,匹配失败,将模式串往右移动2位,让j=5,看i指向的字符能否与"a"匹配(next[7]=5)。

若刚开始i指向的字符“a”与“c”不匹配,并且将模式串直接向右移动了4位,即next[7]=3,如下图所示:

那么继续往后检查,当i指向字符“c”时,发现a,c并不匹配。
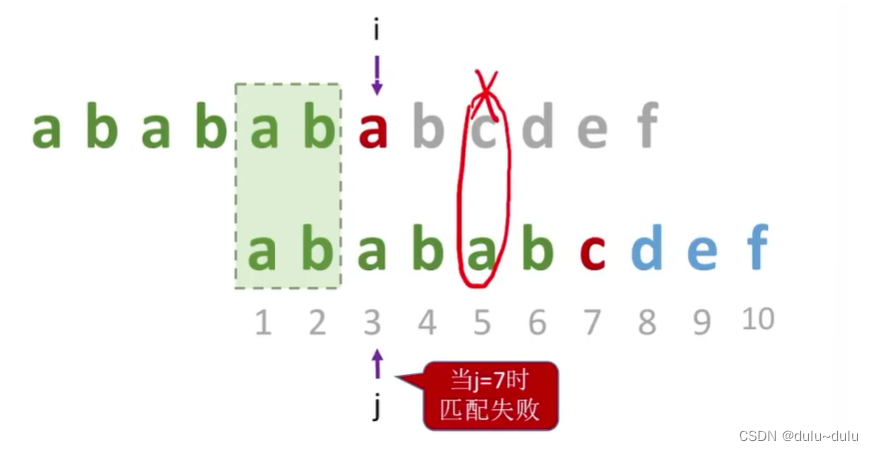
但是按照刚开始的方案,即符号串往右移动2位,那么字符应该是匹配的。

所以只要模式串中有更长的部分能匹配,那么就只考虑更长的情况:

特殊的情况上面已经说过了,即j=1时匹配失败,那么只能紧接着匹配下一个子串,先令j=0,然后让i++,j++,i向后继续扫描,而j=1。所以对任何一个字符串而言,next[1]都为0。

我们将以下红框部分称为串的前缀:包含第一个字符,且不包含最后一个字符的子串。
串的后缀:包含最后一个字符,且不包含第一个字符的子串。
得出结论:当第 j 个字符匹配失败,由前1~j-1个字符组成的串记为S,则:next[j]= S的最长相等前后缀长度+1。并且next[1]是固定为0的。
例如上图,最长相等前后缀=4,那么next[j]=4+1=5。


•练习:
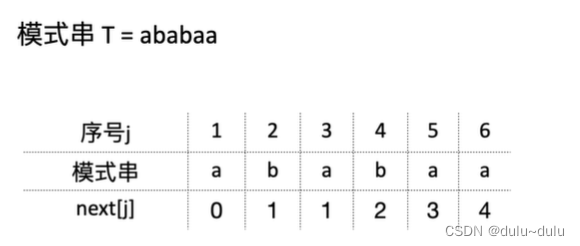
模式串:‘ababaa’
1.next[1]=0
2.next[2]表示当匹配到第2个字符时匹配失败,在第2个字符之前组成的串'a'。'a'不存在前缀和后缀,所以其最长前后缀长度=0,所以也可以总结next[2]一定是1
3.next[3]表示当匹配到第3个字符时匹配失败,第3个字符之前组成的串是'ab',其最长相等前后缀长度也为0,所以next[3]=1
4.同理第4个字符前面的字符串“aba",其最长相等前后缀长度为1,所以next[4]=1+1=2
5.第5个字符前面的字符串“abab”,所以next[5]=2+1=3
6.第6个字符前面的字符串为“ababa”,所以next[6]=3+1=4
所以模式串“ababaa”的next数组如下:



代码实现如下:
//求模式串T的next数组
void get_next(SString T,int next[]){ T为模式串
int i=1,j=0;
next[1]=0;
while(i< T.length){
if(j==0 || T.ch[i]=T.ch[j]){
++i; ++j;
//若pi=pj,则next[j+1]=next[j]+1
next[i]=j;
}
else
//否则令j=next[j],循环继续
j=next[j];
}
}
//while循环中i<T.length,也就是i的范围是1~m,所以可以认为这个函数的时间复杂度为O(m)
//KMP算法
int Index_KMP(SString S,SString T){
int i=1,j=1;
int next[T.length+1];
get_next(T,next); //求模式串的next数组
while(i<=S.length && j<=T.length){
if(j==0 || S.ch[i]==T.ch[j])
{
++i;
++j; //继续比较后继字符
}
else
j=next[j]; //模式串向右移动
}
if(j>T.length)
return i-T.length; //匹配成功
else
return 0;
}
//在KMP算法中,i由1~n,再加上调用的get_next函数,所以KMP算法的时间复杂度为O(n+m)朴素模式匹配算法中,当某些子串与模式串能部分匹配时,主串的扫描指针 i 经常回溯,导致时间开销增加。最坏时间复杂度O(nm)。而KMP算法中,根据模式串T求出next数组,当子串和模式串不匹配时,利用next数组进行匹配,主串指针 i 不回溯,模式串指针 j=next[j] 。算法最坏时间复杂度:O(n+m),其中,求 next 数组时间复杂度O(m),模式匹配过程最坏时间复杂度 O(n)。
如果不会经常出现子串与模式串部分匹配问题,那么KMP算法就显先不出很大的优势。
(3)KMP算法的进一步优化
KMP算法是通过next数组进行匹配的。下面例子中,j指向的字符是a,那么说明主串中的第3个字符一定不是a。

当j=3的字符与主串不匹配时,让j指针指向1,那么j指向的字符a与主串中第3个字符肯定是不匹配的。

所以当j=1的字符与匹配失败的字符相等时,直接让next[3]=0,跳过中间next[3]--->next[1]--->0这一步。

同理:
当j=5时,模式串与主串的值不匹配,即主串的第5个字符不是"b",那么让next[5]=2。
但是由于第2个字符与匹配失败的这一字符相等,所以让 j 指向第2个位置后,接下来的匹配一定是不成功的。这次匹配失败后,next[2]=1,让j=1。

所以可以直接跳过注定匹配失败的那一步,直接让next[5]=1,这样就能少做一次对比。

所以总结下来,如果next数组所指的字符与原本失配的字符相等的话,就可以对next数组优化,如果不等的话,则next数组的值是不变的。
在KMP算法的优化中,我们只优化了next数组,所以在进行KMP算法中,将nextval[]数组替换next[]数组即可。
•求nextval数组的方法(重点)
若模式串ababaa的next数组如下图所示:
nextval[1]=0; //nextval[1]的值直接写0
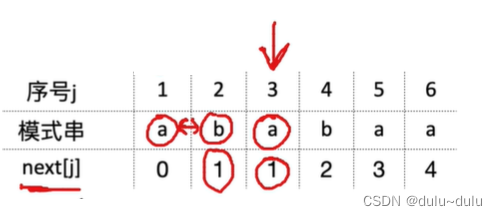
如果next[j]所指的字符,与j所指的字符不相同,就让nextval[j]=next[j],例如下图,当前j所指的字符是b,而其next[2]所指的字符是a,两者不同,那么nextval[2]=1 不变。
如果j指向的字符与next[j]所指的字符相同,例如下图,j=3时,j所指的字符是a,其next[3]所指的字符也是a,那么就让nextval的值优化为next[1]的值0。
nextval[j]=nextval[next[j]]; //nextval[3]=nextval[next[3]]
以此类推:
j=5时指向的是a,next[5]也是a,那么其nextval[5]等于0,不再等于1了,根据已经优化的数组来。
最后得到:



代码如下:
nextval[i]=0;
for (int j=2;i<=T.length;j++){
if(T.ch[next[j]]==T.ch[j])
nextval[j]=nextval[next[j]];
else
nextval[j]=next[j];
}