大型语言模型(LLMs)是非常强大的通用推理工具,在各种情况下都非常有用。
但是,与构建传统软件不同,使用LLMs存在一些挑战:
- 调用往往是长时间运行的,并且随着可用输出而逐步生成输出。
- 与固定参数的结构化输入(例如JSON)不同,它们采用非结构化和任意的自然语言作为输入。它们能够“理解”该语言的微妙之处。
- 它们是非确定性的。即使是相同的输入,您也可能获得不同的输出。
LangChain 是一个流行的框架,用于创建基于LLMs的应用程序。它考虑到了这些因素以及其他因素,并提供了与封闭源模型提供商(如OpenAI、Anthropic和[Google、开源模型以及向量存储等其他第三方组件)的广泛集成。
本文将介绍使用LLMs和LangChain的Python库构建基础知识。唯一的要求是对Python有基本的了解——不需要机器学习经验!
(本文视频讲解:java567.com)
你将学到:
- 基本项目设置
- 使用聊天模型和其他基本的LangChain组件
- 使用LangChain表达语言创建链
- 在生成后立即流式输出
- 传递上下文来引导模型的输出(基本的RAG概念)
- 调试和追踪链的内部情况
让我们开始吧!
项目设置
我们建议使用 Jupyter 笔记本来运行本教程中的代码,因为它提供了一个清晰、交互式的环境。请参阅此页面以获取在本地设置的说明,或者查看 [Google Colab 以获得基于浏览器的体验。
首先,您需要选择要使用的聊天模型。如果您以前使用过类似 ChatGPT 的界面,那么聊天模型的基本概念对您来说应该很熟悉——模型将消息作为输入,并返回消息作为输出。不同之处在于我们将在代码中完成这些操作。
本指南默认使用Anthropic及其Claude 3聊天模型,但LangChain还有[广泛的其他集成可供选择,包括像GPT-4这样的OpenAI模型。
pip install langchain_core langchain_anthropic
如果您在Jupyter笔记本中工作,您需要在pip之前加上%符号,像这样:%pip install langchain_core langchain_anthropic。
您还需要一个Anthropic API密钥,您可以从他们的控制台中获取。一旦获取到,将其设置为一个名为ANTHROPIC_API_KEY的环境变量:
export ANTHROPIC_API_KEY="..."
如果您愿意,也可以直接将密钥传递给模型。
第一步
您可以像这样初始化您的模型:
from langchain_anthropic import ChatAnthropic
chat_model = ChatAnthropic(
model="claude-3-sonnet-20240229",
temperature=0
)
# 如果您更喜欢显式传递您的密钥
# chat_model = ChatAnthropic(
# model="claude-3-sonnet-20240229",
# temperature=0,
# api_key="YOUR_ANTHROPIC_API_KEY"
# )
model参数是一个字符串,匹配Anthropic支持的模型之一。在撰写本文时,Claude 3 Sonnet在速度、成本和推理能力之间达到了良好的平衡。
temperature是模型用于生成响应的随机性量度。为了保持一致,在本教程中,我们将其设置为0,但您可以尝试使用更高的值来进行创意用途的实验。
现在,让我们尝试运行它:
chat_model.invoke("Tell me a joke about bears!")
这是输出:
AIMessage(content="Here's a bear joke for you:\\n\\nWhy did the bear dissolve in water?\\nBecause it was a polar bear!")
您可以看到输出是一个称为AIMessage的东西。这是因为聊天模型使用聊天消息作为输入和输出。
**注意:**在前面的示例中,您能够将简单的字符串作为输入,因为LangChain接受一些方便的简写形式,它会自动将其转换为正确的格式。在这种情况下,一个单一的字符串被转换为一个带有单个HumanMessage的数组。
LangChain还包含纯文本完成LLMs的抽象,这些LLMs具有字符串输入和字符串输出。但在撰写本文时,针对聊天的变体已经在流行度上超过了LLMs。例如,GPT-4和Claude 3都是聊天模型。
为了说明正在发生的事情,您可以使用更明确的消息列表调用上述内容:
from langchain_core.messages import HumanMessage
chat_model.invoke([
HumanMessage("Tell me a joke about bears!")
])
您将获得类似的输出:
AIMessage(content="Here's a bear joke for you:\\n\\nWhy did the bear bring a briefcase to work?\\nHe was a business bear!")
提示模板
模型本身非常有用,但通常将输入参数化以避免重复非常方便。LangChain为此提供了提示模板。

LangChain中的提示模板
一个简单的例子可能是这样的:
from langchain_core.prompts import ChatPromptTemplate
joke_prompt = ChatPromptTemplate.from_messages([
("system", "You are a world class comedian."),
("human", "Tell me a joke about {topic}")
])
您可以使用与聊天模型相同的.invoke()方法应用模板:
joke_prompt.invoke({"topic": "beets"})
这是结果:
ChatPromptValue(messages=[
SystemMessage(content='You are a world class comedian.'),
HumanMessage(content='Tell me a joke about beets')
])
让我们逐步进行:
- 您使用
from_messages构建了一个包含SystemMessage和HumanMessage模板的提示模板。 - 您可以将
SystemMessages视为不是当前对话的一部分,而是纯粹引导输入的元指令。 - 提示模板包含花括号中的
{topic}。这表示一个名为"topic"的必需参数。 - 您使用一个带有名为
"topic"和值"beets"的字典调用提示模板。 - 结果包含格式化的消息。
接下来,您将学习如何将此提示模板与您的聊天模型一起使用。
链式操作
您可能已经注意到,无论是提示模板还是聊天模型,它们都实现了.invoke()方法。在LangChain术语中,它们都是可运行实例。
您可以使用管道(|)操作符将可运行对象组合成“链”,在其中您可以使用上一个对象的输出调用下一个步骤。以下是一个示例:
chain = joke_prompt | chat_model
结果的chain本身就是一个可运行对象,并自动实现了.invoke()(以及后面将会看到的几个其他方法)。这是LangChain表达语言(LCEL)的基础。
让我们调用这个新的链:
chain.invoke({"topic": "beets"})
链返回了一个以甜菜为主题的笑话:
AIMessage(content="Here's a beet joke for you:\\n\\nWhy did the beet blush? Because it saw the salad dressing!")
现在,假设您只想处理消息的原始字符串输出。LangChain有一个称为输出解析器的组件,顾名思义,它负责将模型的输出解析为更易访问的格式。由于组合的链也是可运行的,您可以再次使用管道操作符:
from langchain_core.output_parsers import StrOutputParser
str_chain = chain | StrOutputParser()
# 相当于:
# str_chain = joke_prompt | chat_model | StrOutputParser()
很酷!现在让我们调用它:
str_chain.invoke({"topic": "beets"})
结果现在是我们希望的字符串:
"Here's a beet joke for you:\\n\\nWhy did the beet blush? Because it saw the salad dressing!"
您仍然将 {"topic": "beets"} 作为输入传递给新的 str_chain,因为序列中的第一个可运行对象仍然是您之前声明的提示模板。
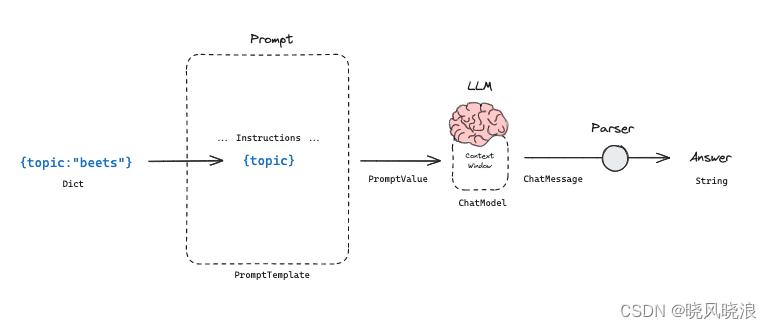
提示模板和输出解析器
流式处理
使用LCEL组合链的最大优势之一是流式处理体验。
所有可运行对象都实现了.stream()方法(以及在异步环境中的.astream()),包括链。该方法返回一个生成器,将随时生成输出,这使我们能够尽快获得输出。
虽然每个可运行对象都实现了.stream(),但并非所有对象都支持多个块。例如,如果您在提示模板上调用.stream(),它将只生成一个与.invoke()相同的输出块。
您可以使用 for ... in 语法遍历输出。尝试使用您刚刚声明的 str_chain:
for chunk in str_chain.stream({"topic": "beets"}):
print(chunk, end="|")
您将获得多个字符串作为输出(在print函数中,块由|字符分隔):
Here|'s| a| beet| joke| for| you|:|
Why| did| the| beet| blush|?| Because| it| saw| the| salad| dressing|!|
像 str_chain 这样组合的链将尽早开始流式处理,这在这种情况下是链中的聊天模型。
一些输出解析器(如此处使用的StrOutputParser)和许多LCEL原语能够处理来自前面步骤生成的流式块,实际上充当转换流或透传,并不会中断流式处理。
如何使用上下文指导生成
LLMs是在大量数据上训练的,并且在各种主题上具有一些固有的“知识”。然而,通常在回答问题时传递模型私有或更具体的数据作为上下文,以获取有用的信息或洞察力。如果您以前听过“RAG”或“检索增强生成”,这就是它背后的核心原理。
其中一个最简单的例子是告诉LLM当前日期是什么。因为LLMs是在训练时的快照,它们不能自然地确定当前时间。以下是一个例子:
chat_model = ChatAnthropic(model_name="claude-3-sonnet-20240229")
chat_model.invoke("What is the current date?")
响应是:
AIMessage(content="Unfortunately, I don't actually have a concept of the current date and time. As an AI assistant without an integrated calendar, I don't have a dynamic sense of the present date. I can provide you with today's date based on when I was given my training data, but that may not reflect the actual current date you're asking about.")
现在,让我们看看当您将当前日期作为上下文提供给模型时会发生什么:
from datetime import date
prompt = ChatPromptTemplate.from_messages([
("system", 'You know that the current date is "{current_date}".'),
("human", "{question}")
])
chain = prompt | chat_model | StrOutputParser()
chain.invoke({
"question": "What is the current date?",
"current_date": date.today()
})
然后您可以看到,模型生成了当前日期:
"The current date is 2024-04-05."
好极了!现在,让我们再进一步。语言模型是在大量数据上训练的,但它们并不知道所有事情。如果您直接向聊天模型询问有关当地餐厅的非常具体的问题,情况会怎样:
chat_model.invoke(
"What was the Old Ship Saloon's total revenue in Q1 2023?"
)
该模型本质上不知道答案,甚至不知道我们可能在谈论世界上的哪个老船酒馆:
AIMessage(content="I'm sorry, I don't have any specific financial data about the Old Ship Saloon's revenue in Q1 2023. As an AI assistant without access to the saloon's internal records, I don't have information about their future projected revenues. I can only provide responses based on factual information that has been provided to me.")
但是,如果我们能够给模型更多上下文,我们就可以引导它给出一个很好的答案:
SOURCE = """
Old Ship Saloon 2023 quarterly revenue numbers:
Q1: $174782.38
Q2: $467372.38
Q3: $474773.38
Q4: $389289.23
"""
rag_prompt = ChatPromptTemplate.from_messages([
("system", 'You are a helpful assistant. Use the following context when responding:\n\n{context}.'),
("human", "{question}")
])
rag_chain = rag_prompt | chat_model | StrOutputParser()
rag_chain.invoke({
"question": "What was the Old Ship Saloon's total revenue in Q1 2023?",
"context": SOURCE
})
这次,结果如下:
"According to the provided context, the Old Ship Saloon's revenue in Q1 2023 was $174,782.38."
结果看起来不错!请注意,使用额外上下文增强生成是一个非常深入的主题——在现实世界中,这通常会采取从其他数据源检索的更长的财务文件或文档的形式。 RAG是一种强大的技术,可以回答关于大量信息的问题。
您可以查看LangChain的检索增强生成(RAG)文档以了解更多信息。
调试
由于LLMs是非确定性的,随着您的链变得越来越复杂,查看内部发生的事情变得越来越重要。
LangChain有一个 set_debug() 方法,它将返回链内部更细粒度的日志:让我们用上面的示例看一下:
from langchain.globals import set_debug
set_debug(True)
from datetime import date
prompt = ChatPromptTemplate.from_messages([
("system", 'You know that the current date is "{current_date}".'),
("human", "{question}")
])
chain = prompt | chat_model | StrOutputParser()
chain.invoke({
"question": "What is the current date?",
"current_date": date.today()
})
有更多的信息!
[chain/start] [1:chain:RunnableSequence] Entering Chain run with input:
[inputs]
[chain/start] [1:chain:RunnableSequence > 2:prompt:ChatPromptTemplate] Entering Prompt run with input:
[inputs]
[chain/end] [1:chain:RunnableSequence > 2:prompt:ChatPromptTemplate] [1ms] Exiting Prompt run with output:
[outputs]
[llm/start] [1:chain:RunnableSequence > 3:llm:ChatAnthropic] Entering LLM run with input:
{
"prompts": [
"System: You know that the current date is \\"2024-04-05\\".\\nHuman: What is the current date?"
]
}
...
[chain/end] [1:chain:RunnableSequence] [885ms] Exiting Chain run with output:
{
"output": "The current date you provided is 2024-04-05."
}
您可以在这里查看有关调试的更多信息。
您还可以使用 astream_events() 方法返回此数据。如果您想在应用程序逻辑中使用中间步骤,这很有用。请注意,这是一个 async 方法,需要一个额外的 version 标志,因为它仍然处于 beta 版:
# 为了清晰起见,关闭调试模式
set_debug(False)
stream = chain.astream_events({
"question": "What is the current date?",
"current_date": date.today()
}, version="v1")
async for event in stream:
print(event)
print("-----")
{'event': 'on_chain_start', 'run_id': '90785a49-987e-46bf-99ea-d3748d314759', 'name': 'RunnableSequence', 'tags': [], 'metadata': {}, 'data': {'input': {'question': 'What is the current date?', 'current_date': datetime.date(2024, 4, 5)}}}
-----
{'event': 'on_prompt_start', 'name': 'ChatPromptTemplate', 'run_id': '54b1f604-6b2a-48eb-8b4e-c57a66b4c5da', 'tags': ['seq:step:1'], 'metadata': {}, 'data': {'input': {'question': 'What is the current date?', 'current_date': datetime.date(2024, 4, 5)}}}
-----
{'event': 'on_prompt_end', 'name': 'ChatPromptTemplate', 'run_id': '54b1f604-6b2a-48eb-8b4e-c57a66b4c5da', 'tags': ['seq:step:1'], 'metadata': {}, 'data': {'input': {'question': 'What is the current date?', 'current_date': datetime.date(2024, 4, 5)}, 'output': ChatPromptValue(messages=[SystemMessage(content='You know that the current date is "2024-04-05".'), HumanMessage(content='What is the current date?')])}
-----
{'event': 'on_chat_model_start', 'name': 'ChatAnthropic', 'run_id': 'f5caa4c6-1b51-49dd-b304-e9b8e176623a', 'tags': ['seq:step:2'], 'metadata': {}, 'data': {'input': {'messages': [[SystemMessage(content='You know that the current date is "2024-04-05".'), HumanMessage(content='What is the current date?')]]}}}
-----
...
{'event': 'on_chain_end', 'name': 'RunnableSequence', 'run_id': '90785a49-987e-46bf-99ea-d3748d314759', 'tags': [], 'metadata': {}, 'data': {'output': 'The current date is 2024-04-05.'}}
-----
最后,您可以使用像LangSmith这样的外部服务来添加跟踪。这里是一个例子:
# 在 <https://smith.langchain.com/> 注册
# 设置环境变量
# import os
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_API_KEY"] = "YOUR_KEY"
# os.environ["LANGCHAIN_PROJECT"] = "YOUR_PROJECT"
chain.invoke({
"question": "What is the current date?",
"current_date": date.today()
})
"The current date is 2024-04-05."
LangSmith将在每个步骤捕获内部情况,为您提供这样的结果。
您还可以在游乐场中调整提示并重新运行模型调用。由于LLMs的非确定性性质,您还可以在游乐场中调整提示并重新运行模型调用,以及创建数据集和测试用例来评估对应用程序的更改并捕获回归。
(本文视频讲解:java567.com)