关注公众号【AI论文解读】回复: 论文解读 获取本文论文

引言:NLP模型的高置信错误与脆弱性问题
在自然语言处理(NLP)领域,模型的预测性能优化往往伴随着高置信错误(high confidence errors)的产生,以及对对抗性和分布外置信数据的脆弱性问题。这些问题的存在对于NLP模型的可靠性和鲁棒性构成了严峻挑战。高置信错误指的是模型对其错误预测具有极高的置信,这类错误在模型的特征空间中往往会聚集形成盲点(blind spots),导致模型在这些区域产生错误预测。例如,通过文本扰动,如同义词替换,NLP模型容易产生高置信的错误分类。
在高风险的NLP任务中,如自杀预测模型和刑事司法中的量刑决策,盲点的存在可能导致不良后果。因此,发现和缓解盲点对于提高模型在现实世界中的应用至关重要。尽管已有研究广泛探讨了如何识别高置信错误,但如何有效地利用人类或自动化方法来缓解这些错误,仍是一个开放性问题。
本研究探索了利用大型语言模型(LLMs)进行数据增强,以减少NLP模型在分类任务中高置信错误的数量。通过比较LLMs生成的合成数据与通过相同程序获得的人类数据的有效性,我们发现LLMs在成本上远远低于人类,并且在可扩展性方面具有类似人类的性能。我们的方法在减少高置信错误的数量方面表现出色,同时保持了相同的准确性水平。
1. 论文标题、机构、论文链接
论文标题:Illuminating Blind Spots: Exploring LLMs as a Source of Targeted Synthetic Textual Data to Minimize High Confidence Misclassifications
机构:Delft University of Technology
论文链接:https://arxiv.org/pdf/2403.17860.pdf
本章节的内容基于上述论文,旨在概述NLP模型在处理高置信错误和脆弱性问题时面临的挑战,并介绍了利用LLMs进行数据增强作为一种可能的解决方案。
未知未知数(UUs)与盲点:NLP模型的挑战
1. UUs的定义与影响
未知未知数(Unknown Unknowns,简称UUs)是指在分类任务中,NLP模型非常自信地做出了错误预测的情况。这些UUs往往会聚集形成盲点,即模型在特征空间的某些区域会产生高置信度的错误分类。例如,文本中相关同义词的替换就可能导致模型产生UUs。在一项研究中,通过对原始样本进行微小的文本扰动,成功改变了预测标签,从而产生了UUs。这些盲点的存在在高风险的NLP任务中可能导致不良后果,例如不可靠的自杀预测模型和刑事司法中的有偏见的量刑决定。
2. 盲点的形成与发现
盲点的形成与NLP模型对文本扰动的敏感性有关。例如,将文本中的“haphazard”替换为“thoughtless”可能会改变对导演技能和使用素材的看法,从而导致分类结果的改变。盲点的发现是通过人工或自动化方法进行的,其中包括利用人类或大型语言模型(LLMs)来描述高置信度错误分类的自然语言特征,以生成合成数据,进而扩展训练集。这种方法在减少模型中高置信度错误分类的数量方面显示出了有效性。

利用大型语言模型(LLMs)进行数据增强
1. 数据增强的目的与方法
数据增强的目的是通过生成合成数据来扩展训练集,以减少NLP模型中的高置信度错误分类。在这项研究中,人类或LLMs提供了描述高置信度错误分类的自然语言假设,基于这些假设生成了合成数据。这些数据被用于扩展训练集,以减少模型中存在的UUs数量,同时保持相同的准确性水平。
2. LLMs与人类数据的比较
在比较LLMs生成的合成数据与人类数据的有效性方面,研究发现LLMs在描述盲点方面的能力超过了人类,这表现在通过LLM方法平均减少的UUs数量(19.54%)比人类方法(16.80%)更多。此外,人类生成数据与LLM生成数据的成本差异显著,LLM生成的数据在成本效益上更具优势。研究还发现,LLMs能够以更可扩展的方式达到类似人类的性能。

实验设置:任务、数据集与模型
1. 选择的任务与数据集概述
在本研究中,我们关注的任务是自然语言处理(NLP)中的分类任务,特别是情感分析(SA)、语义等价性(SE)和自然语言推理(NLI)。为了评估我们的方法,我们选择了三个流行的数据集:IMDB(情感分析任务)、MRPC(语义等价性任务)和QNLI(自然语言推理任务)。这些数据集在训练样本大小、任务复杂度和领域特定性方面存在显著差异,为我们提供了一个全面评估方法适应性的机会。
2. BERT模型的微调与评估
我们使用BERT(Bidirectional Encoder Representations from Transformers)模型作为我们的分类器。BERT模型是一种预训练的深度双向变换器模型,已经在多种NLP任务中取得了显著的性能。在我们的实验中,我们使用了由Wolf等人(2020)提供的bert-base-uncased实现,并对其进行了微调,以适应我们的特定任务。微调过程包括使用学习率为2×10^-4和批大小为64进行10个时期的训练。
为了减少模型在高置信下的错误分类,我们限制了基于抽象和探索得出的假设数量为训练集大小的1%,并且每个生成的样本对应一个假设。我们使用每个假设,导致新样本的数量等于训练集大小的2%。这些值可以被有效地视为预算依赖的超参数。
实验结果:LLMs在减少UUs中的表现
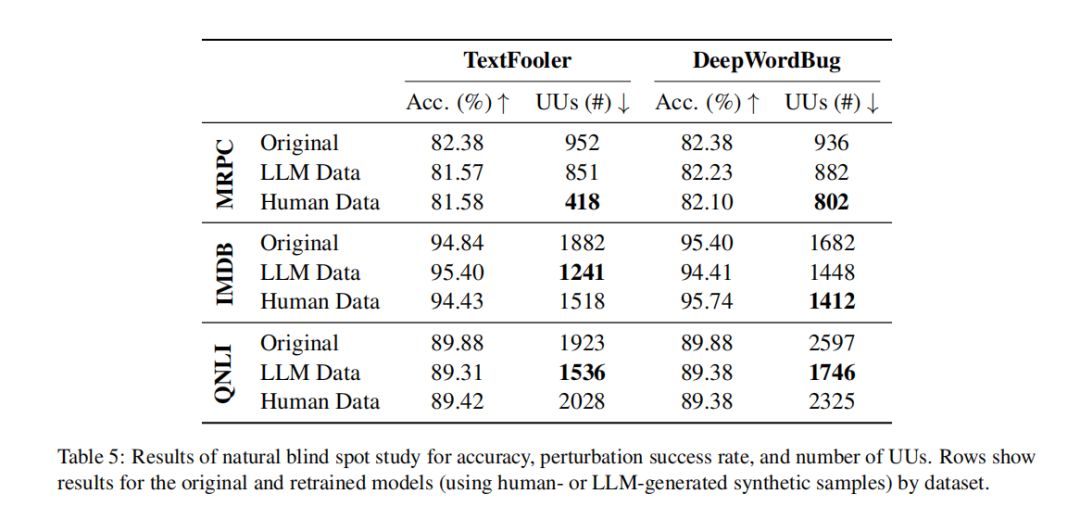
1. 减少高置信错误的有效性
我们的方法在不降低准确性的情况下显著减少了高置信错误(UUs)。在使用TextFooler攻击的MRPC数据集上,人类基于重训练的最大减少率为56.09%。平均而言,通过LLM基于方法的重训练,UUs的减少率为19.54%,而通过人类基于方法的重训练,UUs的减少率为16.80%。
2. LLMs与人类在成本效益上的对比
在成本效益方面,LLMs与人类的差距超过一个数量级。LLMs在模拟人类表现的同时,成本更低,更具可扩展性。例如,在我们的研究中,人类研究涉及168名参与者,成本为1072美元,而LLM实验的成本仅为46美元,用于生成相同数量的概括和样本。此外,从人类通过调查收集数据的时间显著长于从LLM收集数据的时间。这强调了LLM基于方法在可扩展性方面的显著优势,因为它不仅成本更低,而且几乎可以即时提供数据,而从人类获取数据则伴随着显著的延迟。尽管LLM基于方法显然是最具可扩展性的,但在某些高风险或专业应用中,可能最有用的是基于人类的或混合方法。
讨论:LLMs在盲点特征化中的潜力与局限
1. LLMs与人类在特定任务中的表现差异
在探索NLP模型的盲点特征化过程中,LLMs(大型语言模型)与人类在特定任务中的表现存在显著差异。研究表明,LLMs在描述盲点时的能力超过了人类,这体现在通过LLM方法平均减少了19.54%的高置信误分类(UUs),而人类方法则减少了16.80%。然而,这并不意味着LLMs在所有情况下都优于人类。例如,在一个复杂的NLP任务中,人类可能因为更好的理解和创造性思维而提供更高质量的假设和样本。在一个涉及将日期“June 15”错误地更改为“John 15”的样本中,一个表现出色的人类参与者能够识别出这可能与圣经经文有关,这是导致UUs的原因,而LLM没有做到这一点。尽管这样的高质量回答数量不多,但它们在减少UUs方面的影响可能是显著的。
2. 高质量回答的影响与人类的优势
人类在特定情况下提供的高质量回答可能对减少UUs有显著影响,这补偿了许多低质量回答的存在。人类的质量上限被认为是更高的,尽管LLMs更一致地提供可接受的假设和样本。导致人类回答质量较差的主要原因可能是对任务的理解不足或参与者缺乏动机。此外,人类在执行任务时的直觉和日常经验可能使他们在某些NLP任务(如情感分析或语义等价性)中表现得更加直观和有效,而这些任务与个人的日常体验更为一致,相比之下,复杂的自然语言推理(NLI)任务则对非专家的人类能力提出了更高的要求。
结论与未来工作:提升NLP模型鲁棒性的新途径
我们的研究提出了一种通过人类或LLMs的概括性描述,随后生成针对性的合成样本来识别和缓解NLP模型盲点的方法。这种方法在减少UUs方面取得了显著成效,同时保持了模型的准确性。LLMs在特征化盲点方面的表现优于人类,但在某些情况下,人类生成的样本可能更有效。这突显了LLM和人类方法的优势和局限性,以及它们在提高模型性能和鲁棒性方面的潜在协同作用。
未来的工作可以探索如何更有效地结合人类的直觉和LLMs的规模优势,以及如何优化这种方法以适应不同复杂性的NLP任务。此外,研究应该考虑到人类和LLMs在生成假设和样本时可能存在的偏见,并探索如何通过验证步骤来解决这些问题。最后,随着LLMs在众包平台上的广泛使用,我们需要更好地理解和区分人类和机器生成的内容,以确保研究的完整性和有效性。
限制与挑战:研究方法的局限性及其对结果的影响
在探索大型语言模型(LLMs)用于数据增强以减少自然语言处理(NLP)模型在分类任务中的高置信度错误时,我们的研究方法遇到了一系列限制和挑战。这些局限性不仅影响了我们的研究结果,而且对于理解和改进未来研究方法至关重要。
1. 研究方法的局限性
首先,我们的方法依赖于已知的高置信度错误(UUs)来生成假设和合成样本。这意味着我们的方法可能无法识别或缓解那些尚未被发现的未知未知(UUs)。此外,我们的方法主要关注文本扰动导致的错误,如同义词替换,这可能导致我们忽略了其他类型的错误来源。
其次,我们的研究依赖于人类参与者和LLMs的能力来生成描述盲点的假设。尽管我们的研究表明LLMs在生成这些假设方面表现出色,但我们也注意到人类参与者在某些情况下能够提供更高质量的响应。例如,当需要更高阶的思维技能时,人类参与者能够识别出导致UUs的复杂关系,而LLMs则无法做到这一点。
2. 对结果的影响
这些局限性对我们的研究结果产生了显著影响。尽管我们的方法在减少高置信度错误方面取得了成功,但我们也发现了一些关键的挑战。例如,在使用TextFooler攻击QNLI数据集时,我们观察到人类生成的样本实际上导致了UUs数量的增加。这表明我们的方法在处理复杂任务时可能不如预期的有效。
此外,我们的研究还揭示了人类与LLMs在生成假设和样本时的性能差异。LLMs在生成一致质量的假设和样本方面表现更为稳定,而人类参与者的表现则在不同任务之间波动较大。这种波动可能与任务的直观性和参与者的个人经验有关。
3. 未来研究的方向
鉴于这些挑战,未来的研究需要探索更多样化的方法来识别和缓解NLP模型中的盲点。这可能包括开发新的技术来发现那些尚未被识别的UUs,或者改进现有方法以更好地利用人类和LLMs的优势。此外,未来的研究还应该考虑如何在不同类型的NLP任务中平衡准确性和鲁棒性,以及如何在不同的数据分布中有效地应用我们的方法。
总之,尽管我们的方法在一定程度上成功地减少了高置信度错误,但我们的研究也揭示了NLP模型中盲点缓解的复杂性和挑战性。通过深入理解这些局限性及其对结果的影响,我们可以为未来的研究提供宝贵的见解和改进建议。