前言
在当今迅猛发展的软件开发领域,微服务架构已经成为构建灵活、可扩展系统的关键方法之一。本文将带领读者深入了解微服务架构的核心思想,并介绍构建这一架构所需的常用组件,为各位开发者提供全面的指导和洞察力。
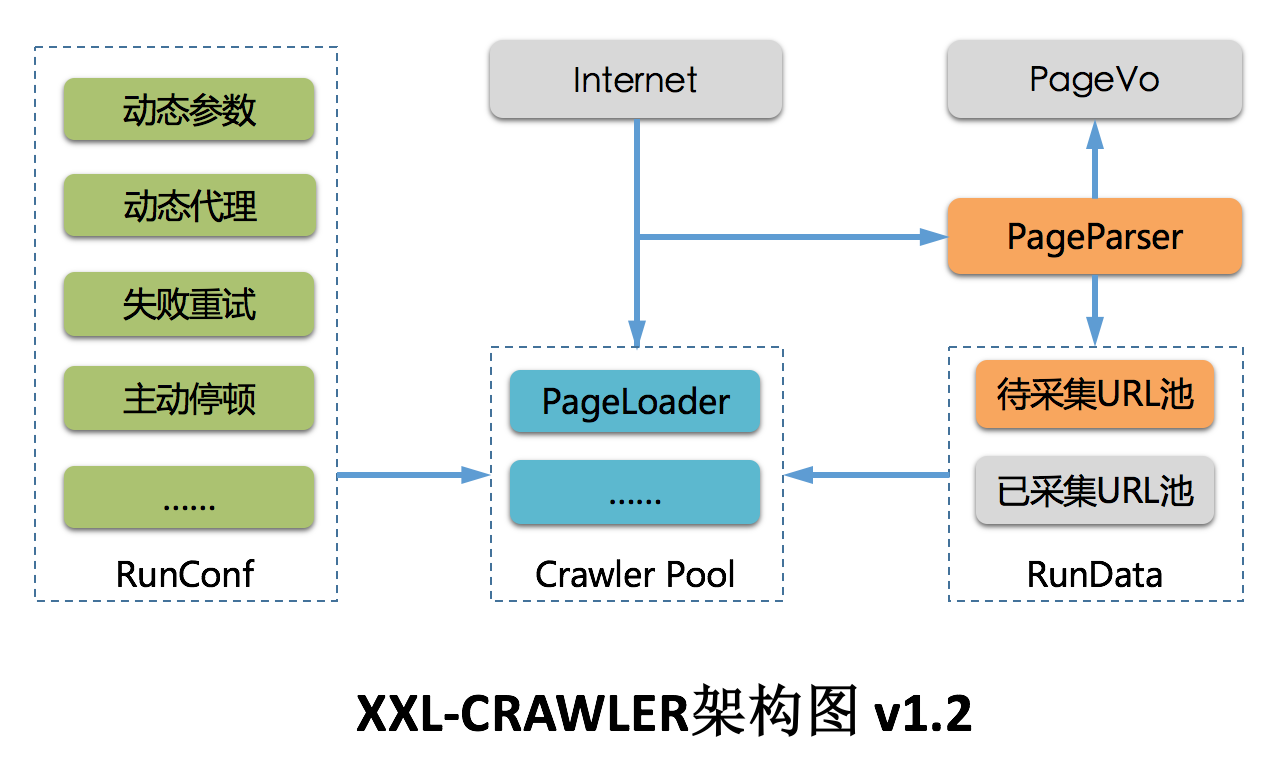
BigDiagram
我们从一张大图来展示微服务架构的全貌
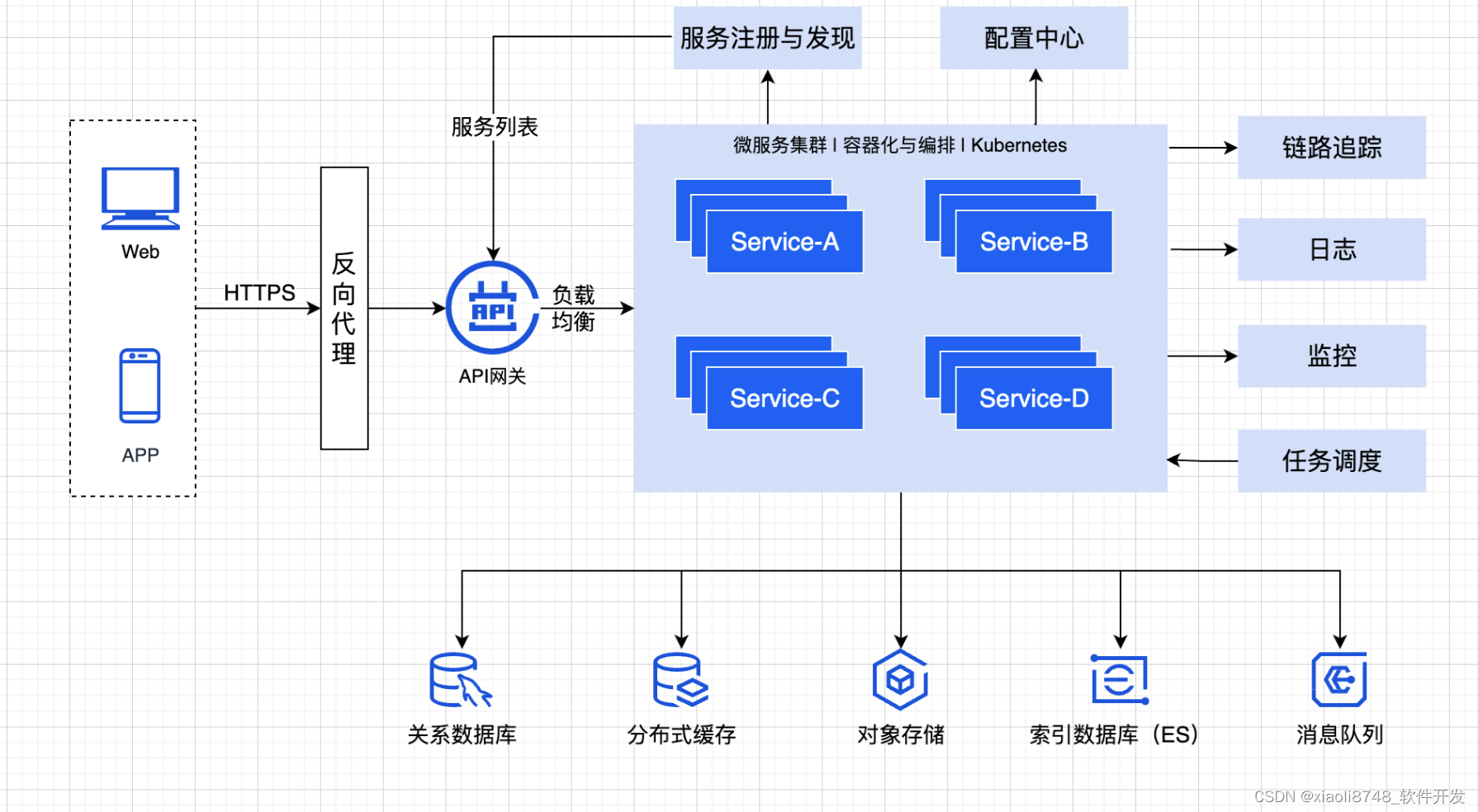
首先,需要一个反向代理(如Nginx)来作为流量入口。
反向代理经过API网关控制,分发到微服务集群中的各个微服务。
API网关分发流量是基于路由的,路由根据服务列表来进行配置,通常会有一个服务发现与注册系统来帮助维护集群中的微服务状态信息。
微服务运行时通常需要获取服务配置,在微服务架构中一般会有一个远程配置中心来集中管理配置。
为了更好的进行服务治理,链路追踪、日志系统、监控系统在微服务架构中也是少不了的。
有些微服务系统中还需要一个任务调度系统来维护需要定期执行的任务。
另外,系统的运行常常还需要存储、检索数据,在微服务架构中,经常需要用到关系数据库、分布式缓存、对象存储、索引数据库、消息队列的组件/中间件
流量入口 | 反向代理
微服务架构中,经常使用反向代理(如Nginx)来作为流量的入口。 反向代理可以起到以下作用:
- 负载均衡: 反向代理可以将请求分发到多个后端微服务实例,实现负载均衡,提高系统的可伸缩性和性能。
- SSL终结: 反向代理可以处理传入的HTTPS流量,负责SSL/TLS终结,解密和加密数据,减轻后端微服务的负担。
- 安全性增强: 反向代理可以充当安全屏障,执行身份验证、授权和访问控制,保护微服务免受恶意攻击。
- 请求路由: 反向代理可以根据请求的内容、路径或其他规则将流量路由到不同的微服务实例,实现请求的定制化处理。
- 静态资源服务: 反向代理可以用于提供静态文件服务,如图片、CSS和JavaScript文件,减轻后端服务的负载。
下面是常见的反向代理:
- Nginx: Nginx是一个高性能的反向代理服务器,广泛用于负载均衡、SSL终结、静态资源服务等。它支持灵活的配置和高度并发的请求处理。
- HAProxy: HAProxy是一款高性能的负载均衡器和反向代理工具,适用于处理大规模的并发连接。它支持多种负载均衡算法和健康检查机制。
- Envoy: Envoy是由CNCF维护的开源反向代理和边缘代理,设计用于支持微服务架构。它提供高度的可扩展性、灵活性和性能优化。
API网关
在微服务架构中,API网关充当着系统的入口点,常常与反向代理合并为一个组件,负责管理和处理外部请求。其主要作用包括:
- 统一入口: 提供统一的API入口,使客户端只需与API网关通信,而无需直接与各个微服务进行交互,简化了客户端和微服务之间的通信。
- 路由与负载均衡: 根据请求的路径、参数或标头将流量路由到相应的微服务实例,实现请求的分发和负载均衡,确保系统的稳定性和性能。
- 协议转换: 处理不同协议之间的转换,使得系统能够支持多种通信协议,如HTTP、WebSocket等。
- 身份验证与授权: 管理用户身份验证和授权,确保只有经过授权的用户才能访问特定的微服务,提升系统的安全性。
- 请求转换: 对请求进行转换和修改,使其符合后端微服务的期望格式和协议,从而降低微服务之间的耦合度。
常见的API网关:
- Zuul: Netflix开发的API网关,与Spring Cloud集成,提供路由、负载均衡、安全性等功能。
- Kong: 开源的API网关和微服务管理层,支持插件化的架构,可用于流量控制、认证、日志记录等。
- Apigee: Google推出的云端API管理平台,提供全面的API管理、分析和安全性功能,适用于大规模的API管理需求。
- AWS API Gateway: 亚马逊提供的托管服务,支持构建、发布和管理API,集成AWS生态系统中的其他服务。
- Spring Cloud Gateway: 基于Spring Cloud的API网关,具有轻量级和灵活的特点,适用于微服务架构。
这些API网关工具帮助简化了微服务系统的复杂性,提供了一种集中式的方式来管理和控制微服务的流量和访问。
服务注册与发现
服务注册与发现组件的作用:
在微服务架构中,服务注册与发现是一种关键的机制,用于管理和维护微服务实例的动态变化。其主要作用包括:
- 服务注册: 微服务实例启动时,将自身的信息(如IP地址、端口号、健康状态等)注册到服务注册中心,使得服务注册中心能够感知到该服务的存在。
- 服务发现: 客户端通过查询服务注册中心,获取可用的服务实例列表,从而能够动态地发现并与需要的微服务进行通信。
- 动态负载均衡: 通过服务发现,可以实现动态负载均衡,将请求分发到多个可用的微服务实例,提高系统的可伸缩性和性能。
- 故障处理: 服务注册与发现组件能够监测微服务实例的健康状态,当某个实例发生故障或下线时,自动更新服务注册中心,确保客户端不会访问不可用的服务。
- 适应性扩展: 支持微服务实例的动态扩展和缩减,使得系统能够根据需求自适应地调整服务的规模。
常见的服务注册与发现组件:
- Consul: 由HashiCorp提供的服务注册与发现工具,支持多数据中心、健康检查等功能,是一个高度可靠的分布式系统组件。
- Eureka: Netflix开源的服务注册与发现组件,通过简单的配置即可实现微服务的自动注册与发现,是Spring Cloud生态系统的一部分。
- etcd: CoreOS团队维护的开源分布式键值存储系统,除了用于服务注册与发现,还可作为分布式配置中心和分布式锁的基础。
- Zookeeper: Apache开源的分布式协调服务,提供了高可用性和一致性,广泛应用于服务注册、配置管理等场景。
- Nacos: 阿里巴巴开源的服务发现、配置中心和动态DNS系统,支持多环境配置、服务健康检查等功能,是一体化的解决方案。
这些组件使得微服务架构中的服务能够自动注册、发现和协调,为系统的弹性和可靠性提供了关键的支持。
配置中心
在微服务架构中,配置中心是一种集中管理和动态更新应用程序配置信息的机制。其主要作用包括:
- 集中管理配置: 提供集中式的位置来管理微服务系统的配置信息,避免配置散布在各个微服务中,使得配置更加可维护和一致。
- 动态更新配置: 支持动态更新配置,无需重新启动服务即可应用新的配置,提高系统的灵活性和可维护性。
- 版本控制: 支持配置的版本控制,能够追踪配置的变更历史,方便进行回滚和版本管理。
- 安全性管理: 提供安全的配置管理机制,确保敏感信息如数据库密码等得到保护,并允许对不同环境的配置进行适当的控制。
- 实时监控: 提供实时监控和统计,可以了解各个微服务当前使用的配置信息,便于系统运维和性能优化。
常见的配置中心组件:
- Spring Cloud Config: 基于Spring Cloud的配置中心,支持多种后端存储,提供集中式配置管理和版本控制。
- Consul: 由HashiCorp提供的开源工具,除了服务注册与发现,还提供了配置中心的功能,支持动态更新配置。
- Nacos: 阿里巴巴开源的配置中心和服务发现组件,支持多语言、多环境配置以及动态配置更新。
- etcd: CoreOS团队维护的分布式键值存储系统,可以用作配置中心,支持版本管理和动态更新。
- Apollo: 携程开源的配置中心,支持分布式配置管理、灰度发布和规范的权限控制。
这些配置中心组件帮助简化了微服务系统的配置管理,提供了集中式、动态化的配置管理解决方案,使得系统能够更加灵活、可维护和安全。
链路追踪
链路追踪是一种用于监测和分析分布式系统中请求在不同服务之间的流转路径的技术,其作用包括:
- 故障排查: 可帮助迅速定位分布式系统中的故障和性能问题,减少故障排查的时间。
- 性能优化: 提供对请求执行路径的可视化,有助于优化系统性能和识别潜在的性能瓶颈。
- 事务追踪: 能够追溯分布式事务的整个执行过程,确保事务的一致性和可靠性。
- 监控分析: 通过链路追踪数据进行监控和分析,为系统提供实时的性能指标和可视化的分析报告。
- 用户体验: 改善终端用户体验,通过了解请求路径,确保系统对用户请求的快速响应。
常用的链路追踪组件及简介:
- Zipkin: 开源的分布式链路追踪系统,通过跟踪和收集请求的执行路径,提供了可视化的调用图和时序数据。
- Jaeger: 由Uber Technologies开源的链路追踪工具,支持多语言和多种存储后端,提供分布式系统中的实时监控和故障排查。
- SkyWalking: Apache基金会孵化的开源分布式APM(应用性能管理)系统,提供端到端的性能监控和链路追踪。
这些链路追踪组件帮助开发人员和运维团队更好地理解和管理分布式系统,从而提高系统的稳定性和性能。
日志
日志系统在微服务架构中扮演着关键角色,通过记录分布式系统中各个微服务的运行状态和交互信息,为故障排查提供了必要的实时数据。
同时,通过对微服务日志的集中管理和分析,可以实现全局性能监控和系统优化,帮助开发人员迅速定位问题、优化服务,并提高整个微服务体系的稳定性和可维护性。
日志系统还能记录用户请求路径、异常情况等信息,为行为分析和安全审计提供支持,确保微服务架构的合规性和安全性。
当前交流性的日志系统是ELK:
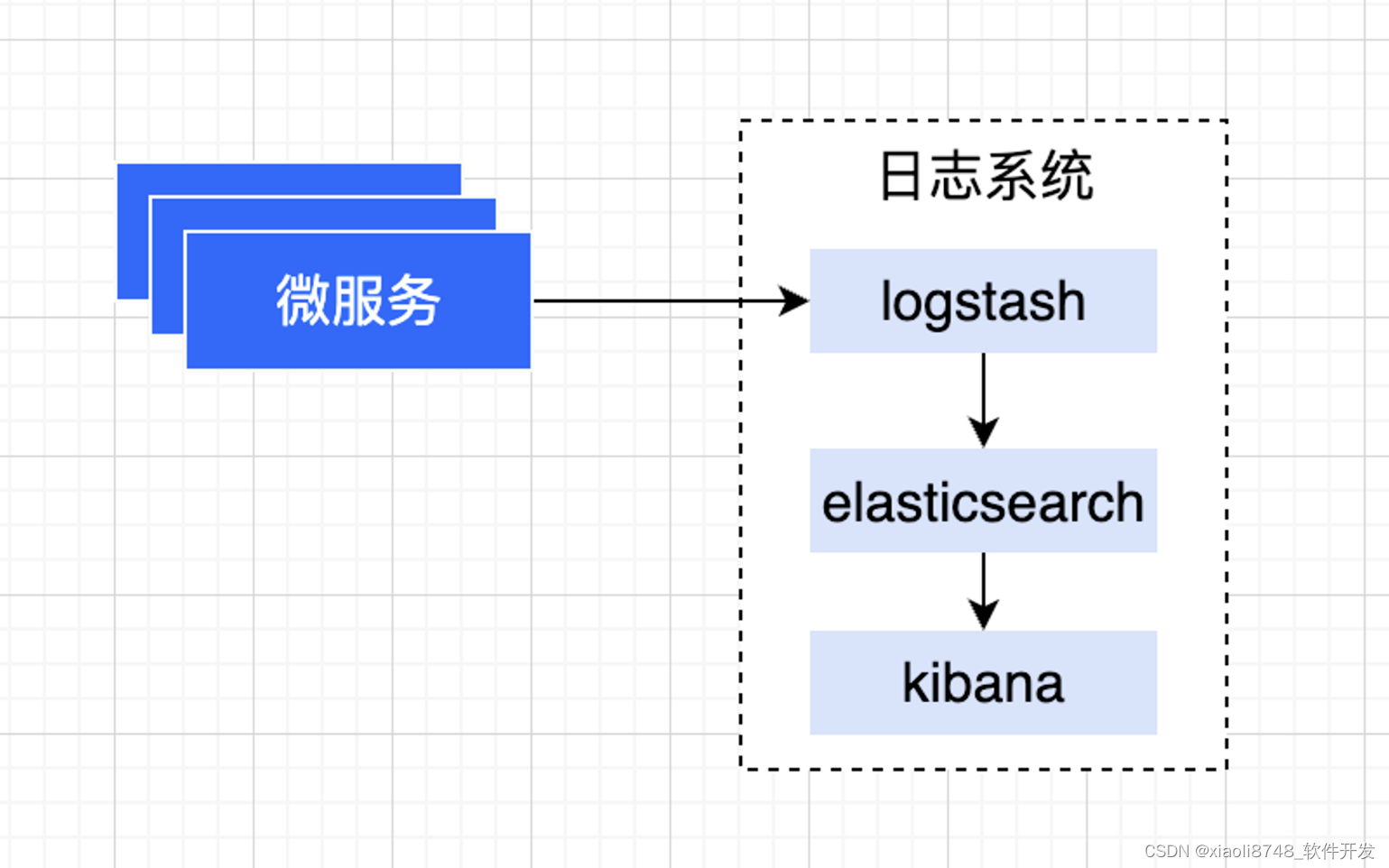
- Logstash: Logstash负责日志的收集、过滤和转发。它可以从各种来源收集日志数据,如文件、消息队列、数据库等,然后对数据进行过滤和处理,最终输出到Elasticsearch进行存储和索引。
- Elasticsearch: Elasticsearch是一个分布式搜索引擎,用于存储、索引和搜索日志数据。Logstash将处理后的日志数据发送到Elasticsearch集群,其中数据被分散存储在多个节点上,以实现横向扩展和高性能搜索。
- Kibana: Kibana是用于可视化和分析日志数据的界面。它连接到Elasticsearch,允许用户通过图形化界面创建仪表板、查询日志数据,并生成各种图表和报表,以便更直观地监控和分析日志信息。
监控
微服务架构中的监控系统是关键的组成部分,用于实时监测和评估系统的运行状态。通过收集和分析微服务的性能指标、错误率和日志数据,监控系统能够及时发现潜在问题,实现快速故障定位和响应。这使得团队能够保持对整个微服务生态系统的洞察,优化性能,确保系统稳定性和可靠性。
常见的监控系统包括:
- Prometheus: 一个开源的监控和警报工具,特别适用于容器化环境,支持多维度的数据模型和强大的查询语言。
- Zabbix: 开源的网络监控软件,支持多种监控方式,包括SNMP、JMX、IPMI等,具有强大的报警和通知功能。
- ELK Stack: 由Elasticsearch、Logstash和Kibana组成,主要用于日志监控和分析,在微服务环境中也可用于监控应用程序性能。
任务调度
当业务需求不断增长时,应用经常需要执行一些定时任务来实现业务逻辑或系统功能。
任务调度系统可以确保系统中的重复、定时性任务得以按时、有序地执行。通过调度和执行定时任务,系统能够实现自动化的数据处理、报告生成或清理任务,提高系统效率、减轻人工负担,并确保任务的准确性和及时性。这对于周期性数据处理、定时报表生成、日志清理等常见场景是不可或缺的,有助于系统的稳定运行和高效管理。
关于定时任务调度的更多内容,可以参考**分布式定时任务介绍**
持久化存储 | 关系数据库
大部分系统都有持久化存储、存储关系型数据的需求。
常见的关系型数据库包括MySQL、MSSQL、OracleDB等。
分布式缓存 | Cache
分布式缓存在系统中的作用是提高数据访问性能和降低数据库负载,通过将热点数据存储在内存中,实现快速的读取和响应,从而提升系统的性能和扩展性。常见的分布式缓存组件包括:
- Redis: 开源的高性能键值存储系统,支持丰富的数据结构和强大的缓存能力,常用于缓存、会话存储和消息队列等场景。
- Memcached: 分布式内存对象缓存系统,通过将数据存储在内存中,提供快速的键值对存储和检索功能,适用于高并发读取的场景。
文件、对象存储
复杂一点的业务系统经常会涉及文件、图片等素材的存储。 文件、对象存储组件主要用于持久性地存储大量的文件和数据,适用于文件系统的组织和检索。
- Hadoop Distributed File System (HDFS): 用于文件存储的分布式文件系统,支持大规模的数据存储和处理。
- Amazon S3: 亚马逊提供的对象存储服务,通过简单的RESTful接口,支持存储和检索海量数据。
- Google Cloud Storage: 谷歌云提供的对象存储服务,具备高可用性和耐久性,适用于多种数据存储需求。
- 腾讯云COS: 腾讯云上提供的对象存储服务。
索引仓库 | Elasticsearch
索引仓库在业务系统中的作用是提供高效的数据检索和查询功能,通过构建索引结构,加速对数据的搜索操作,提升系统的查询性能。常见的索引仓库包括:
- Elasticsearch: 开源搜索引擎,支持实时的全文搜索、分布式搜索和复杂查询,广泛应用于日志分析、全文检索等场景。
- Apache Solr: 另一款开源搜索平台,基于Lucene构建,提供强大的搜索和分析功能,适用于企业级搜索和信息检索。
这些索引仓库为业务系统提供了快速而可靠的数据搜索和检索功能,满足了大规模数据集的高效查询需求。
消息队列
消息队列在业务系统中的作用是实现异步通信和解耦,通过将消息发送到队列中,不同组件或服务能够独立进行工作,提升系统的可伸缩性和可靠性。常见的消息队列包括:
- Apache Kafka: 高吞吐、分布式的消息队列系统,广泛应用于实时数据流处理和事件驱动架构。
- RabbitMQ: 开源的消息代理软件,提供灵活的消息传递模式,支持可靠的消息传递和多种消息协议。
这些消息队列系统为业务系统提供了可靠的消息传递机制,使得不同部分的系统能够协同工作,提高整体系统的可扩展性和可维护性。